1389
Automatic vascular segmentation of neck TOF MRA images based on 3D CNN model1Department of Medicine, CBIR, Tsinghua University, Beijing, China
Synopsis
Accurate and fast automatic Carotid artery segmentation of time of flight(TOF) MRA plays an important role in the auxiliary diagnosis of carotid artery disease. Considering the complexity and uncertainty of doctors’ manual segmentation of neck vessels, automatic segmentation algorithms are required in clinical practice. A segmentation model based on 3D Convolutional neural network (CNN) was proposed to segment carotid arteries from TOF MRA images. With innovative adjustment of the network architecture and parameters for carotid application, our model showed better performance than other baseline models on private dataset.
Introduction
Carotid artery disease such as atherosclerosis is one of the main causes of ischemic stroke[1-3]. Using neck TOF MRA to extract vascular morphology and perform quantitative analysis is helpful for the prevention of stroke. However, tedious manual operations on segmentation are not convenient enough. To date, 3D CNN models are rarely used for vascular segmentation of neck TOF MRA images. It is of significance to investigate the segmentation performance of optimized 3D CNN model on neck TOF MRA.Methods
Dataset and MR Acquisition: A total of 160 3D neck TOF MRA images were selected from the Cardiovascular Risk of Old Population(CROP) study. MRI acquisitions were performed on a 3T MRI scanner (Achieva 3T TX, Philips, Netherlands). The imaging parameters: FFE sequence, TR=25ms, TE=3.453ms, flip angle=20, imaging FOV:130(AP)×168(RL)×140(FH) , spatial resolution: 0.7×0.9×1.8 mm3 .Data Labeling: Vessel segmentation labels were pixel-level manually delineated by vascular imaging professionals in 3D TOF images (Materialise Mimics, Mimics Medical 17.0), and were subsequently examined by advanced imaging experts. Data Splitting: The dataset was randomly divided into training, validating and test dataset according to a ratio of 8∶1∶1.
Random Patch Extraction: Cropping images into patch is a common trick to reduce computing burden and therefore more efficient. To investigate and minimize the effect of the patch tricks, three typical patch sizes in pixel level (Large: 256×256×64, Medium: 192×192×64 and Small: 192×192×32) of 3D patch randomly cropped from our TOF MRA images were selected for model training and predicting. Each patch was regularized before training.
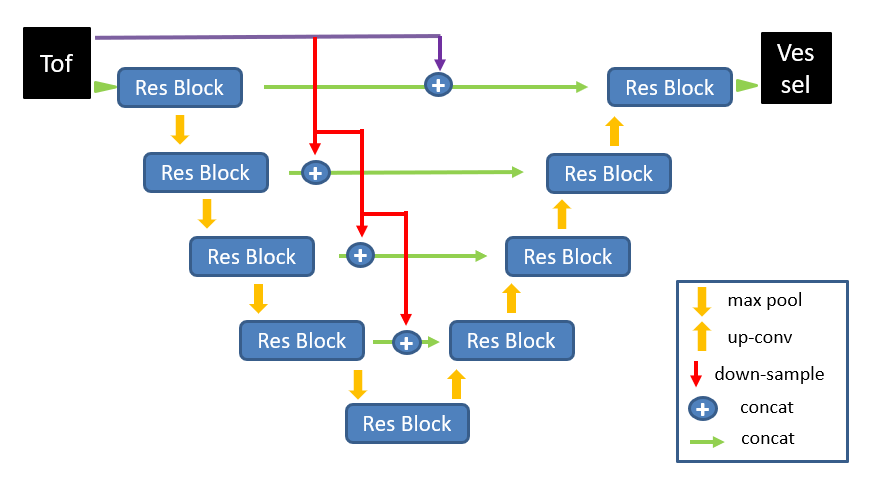
The CNN model: Architecture of the CNN model in this study is shown in Figure 1. The model contains 4 steps down-sampling and 4 steps up-sampling, which realizes the end-to-end neural network structure from the input 3D MRA image to the output predicted label image. Each step is a Res Block that consists of two convolutional layers, one max-pooling or up-sampling layer and residual-net[4] module. To preserve more details on image in up-sampling part, the TOF data down-sampled in equal proportions is innovatively added to the skip connection structure of each layer, and fed into the up-sampling convolution operation by concatenation.
Model Training: The 3D patches and the corresponding manual annotation labels were used to train the CNN model with 10-fold cross-validation using the Dice coefficients as loss function.
Method Comparison: The traditional method of Statistical model[5](an adaptive segmentation method using mixed distribution model based on expectation maximum(EM) algorithm), the 3D U-Net[6], 3D Res U-Net, 3D SE U-Net(Squeeze-and-Excitation Networks)[7] and our model were applied on our dataset with the same hyperparameters.
Performance Assessment: The model performance was assessed based on these quantitative measures: Average Dice index, Dice standard deviation(10-fold), Sensitivity and Specificity. The results were visualized by Maximum Intensity Projections. One-way ANOVA was used for the comparative test of results of different patch sizes. All assessment were performed on in-home Python scripts.
Experimental Environment: Processor: Inter Core i7-9800X. GPU: GeForce GTX 2080Ti, memory: 11G. Programming environment: Python = 3.7. Deep learning framework: Tensorflow = 1.14.0.
Results
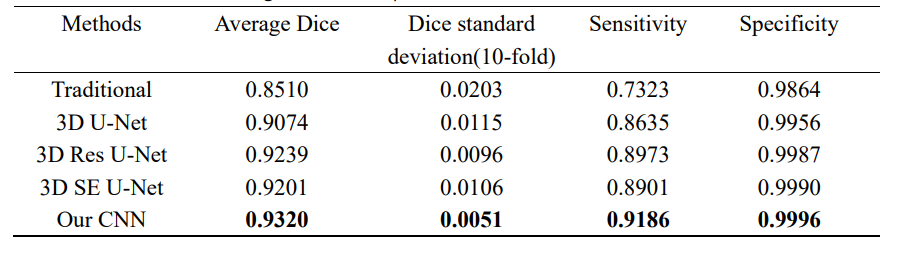
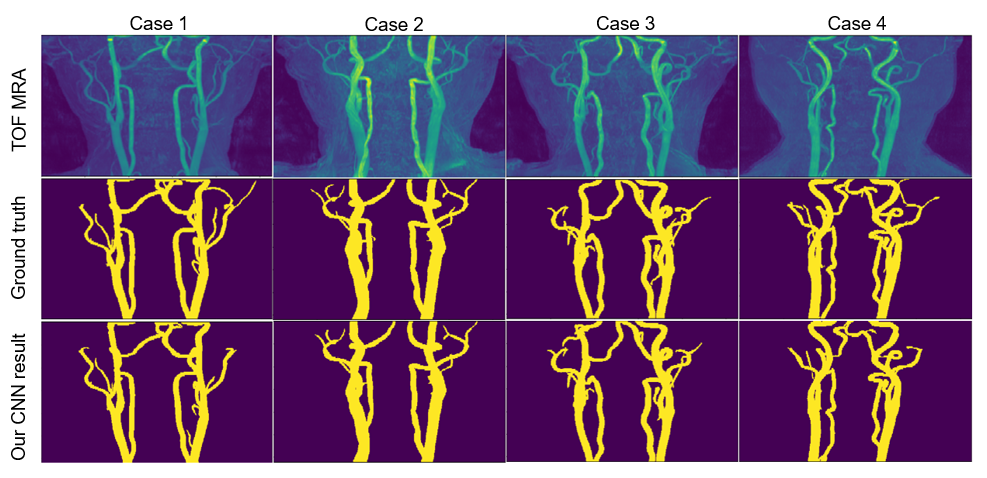
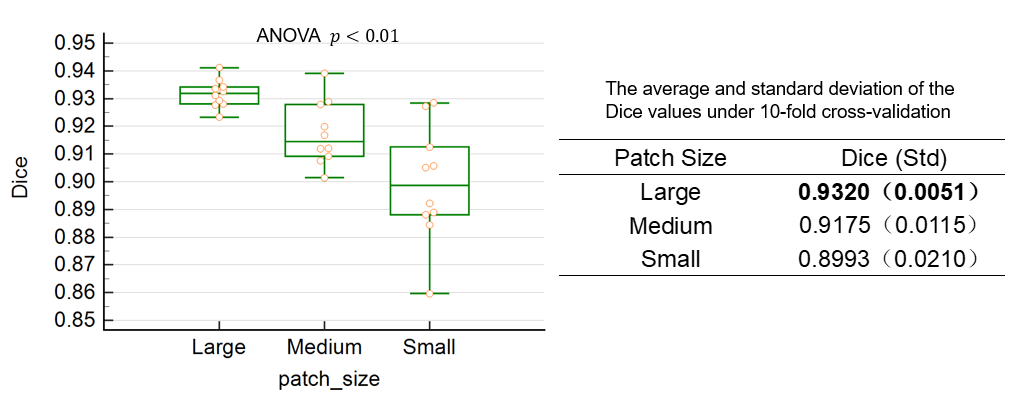
Quantitative test results for all models mentioned above are shown in the table 1. Our CNN model obtained the highest segmentation Dice coefficient value(0.9320), sensitivity and specificity(0.92,1.00), and the smallest standard deviation (0.0051). Four test results processed by our CNN model were randomly selected for qualitative visualization as shown in Figure 2. Our optimized 3D CNN model obtained the best segmentation performance when selecting large-size patch with best Dice value. In the results of One-way ANOVA, significant(p<0.01) difference was among varied patch sizes. Statistical results and distribution are shown in Figure 3.Discussion and Conclusion
Because of the integrity of the blood vessels, we need to make full use of global image features to obtain better segmentation results. The larger the size of the input patch, the more vascular information it contains, and therefore better consistency is maintained. The proposed 3D CNN model with larger-size crop patch has better performance in neck vascular segmentation, which provides a reference to optimize the hyper-parameter. Our CNN model innovatively adds multi-level resolution data of the TOF MRA on each skip-connection layer. The sparsity of the TOF MRA and the brightness of the vascular area, plays the role of region-of-interest. More original image features are fed into decoder layer to make the network have better generalization of data. These help our model obtain the best segmentation performance among baseline algorithms. For pros & cons, since our dataset came from asymptomatic healthy people, the transferred performance of our model on patient data needs further research. In summary, the experimental results showed that the proposed model can automatically segment the neck vascular from TOF-MRA volumes and outperformed the state of the art.Acknowledgements
No acknowledgement found.References
[1] G. WHO, “Global health estimates 2016: deaths by cause, age, sex, by country and by region, 2000–2016,” 2018.
[2] S. Wu, B. Wu, M. Liu, Z. Chen, W. Wang, C. S. Anderson, P. Sandercock, Y. Wang, Y. Huang, L. Cuiet al., “Stroke in china: advances and challenges in epidemiology, prevention, and management, ”The Lancet Neurol-ogy, vol. 18, no. 4, pp. 394–405, 2019.
[3] Liu L, Wang D, Wong KS, et al. Stroke and stroke care inChina:huge burden, significant workload, and a national priority[J]. Stroke, 2011, 42(12):3651‑3654.
[4] He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (2016), pp. 770–778.
[5] D. L. Wilson and J. A. Noble, “Segmentation of cerebral vessels and aneurysms from MR angiography data,” in Proc. 15th Int. Conf. Information Processing Medical Imaging (Lecture Notes in Computer Science). Berlin, Germany: Springer-Verlag, 1997, vol. 1230, pp. 423–428.
[6] Ozgun Cicek, Ahmed Abdulkadir, Soeren S. Lienkamp, Thomas Brox, and Olaf Ronneberger, “3D U-Net: learning dense volumetric segmentation from sparse annotation,” in MICCAI. Springer, 2016, pp.424–432.
[7] Jie, H. , et al. "Squeeze-and-Excitation Networks." IEEE Transactions on Pattern Analysis and Machine Intelligence PP.99(2017).
[8] Gudmundsson E, Straus CM, Armato SG. Deep convolutional neural networks for the automated segmentation of malignant pleural mesothelioma on computed tomography scans[J]. J Med Imaging, 2018, 5(3): 034503.
Figures