1386
Accelerated volumetric vocal tract MRI using model based deep learning1Roy J. Carver Department of Biomedical Engineering, University of Iowa, Iowa city, IA, United States, 2Department of Radiology, University of Iowa, Iowa city, IA, United States
Synopsis
3D MRI is a powerful tool to safely visualize the various vocal-tract configurations during voice production [1-3]. Current accelerated 3D vocal-tract MRI schemes based on spatial total variation transform (SPTV) regularization are susceptible to non-trivial artifacts (e.g., blurring at air-tissue boundaries, patchy representation of small structures such as the epiglottis, glottis). In this work, we apply a model based deep learning reconstruction scheme that can significantly accelerate 3D vocal-tract imaging. We demonstrate it to produce images with high-spatial fidelity, natural-looking like contrast, and significantly robust to artifacts seen with current SPTV based schemes.
PURPOSE:
The human vocal tract is a complex instrument consisting of various articulators (e.g., lips, soft-palate, tongue, pharynx, glottis, epiglottis), which coordinate intricately to produce voice. 3D MRI is a powerful tool to safely visualize the various vocal tract configurations while it is producing a variety of sounds [1-3]. Accelerated 3D imaging based on sparse sampling and constrained reconstruction have been a key to shorten scan times and allow for fast imaging of the vocal tract during sustained production of sounds (e.g., of the order of 5-7 secs) [3-5]. Current methods are based on exploiting sparsity under pre-determined transforms such as the spatial total variation transform (SPTV) [3-5]. These methods tend to produce non-trivial artifacts and can corrupt the visualization of several boundaries and structures (e.g., blurring at air-tissue boundaries, patchy representation of small structures such as the epiglottis, glottis). In this work, we apply a model based deep learning reconstruction scheme [6] that can significantly accelerate 3D vocal tract imaging. We demonstrate it to produce images with high spatial fidelity, natural looking contrast, and significantly robust to artifacts seen with current SPTV based schemes.METHODS:
Data used in this study were collected from 5 subjects from 4 different scanning sessions. All the data collection was done on a 3T GE Premier scanner using three different receive coils: 16 channel custom airway coil [7], 21 channel head/neck coil, and a 48 channel head only coil. Imaging was done using a 3D fast GRE sequence while the subjects were in a resting posture. Fully sampled datasets were acquired using the following parameters: flip angle: 5 degrees, frequency x phase x slice partitions = 128 x 128 x 32; FOV = 24cm x 24 cm x 6.4 cm; 2 mm isotropic resolution; BW: 488.3 Hz/pixel; scan time= 20 secs. Of these 5 subjects, 4 subjects (scanned during 3 different sessions) were used for training and one subject scanned in another session was used for testing. To maintain the same coil dimension across all the datasets acquired with different receive coil arrays, we performed a PCA based coil compression on the original raw k-space data to 13 virtual coils. Next, we have decoupled the slices for each dataset and performed retrospective under-sampling using a variable-density 2D Cartesian random sampling masks at undersampling factors of 7, 10, 12 and 16 [8]. The same sampling mask was used for both training and testing for a given undersampling factor. The virtual coil sensitivities were estimated from the central 20x20 size window of the k-space region using ESPIRiT [9]. The MoDL network maps the under-sampled multi coil k-space to the reconstruction via 10 (user-defined) unrolled iterations between data consistency and deep learning based denoising. The denoiser had 5 layers with convolution layers, followed by batch normalization and ReLU; the layer-5 does not have ReLU to avoid cancelling the negative parts of learned noise and aliasing pattern. A total of 340 slices from the first 4 subjects were used for training, and 32 slices from the last subject was used for testing. MoDL was implemented in TensorFlow [10] on backend NVDIA 2080 GPU; training time was approximately 3 hours and 40 mins with 100 epochs and batch size of 1. MoDL reconstructions were compared against a sparse SENSE based spatial total variation regularization scheme, which was implemented in the BART computing environment [11].RESULTS:
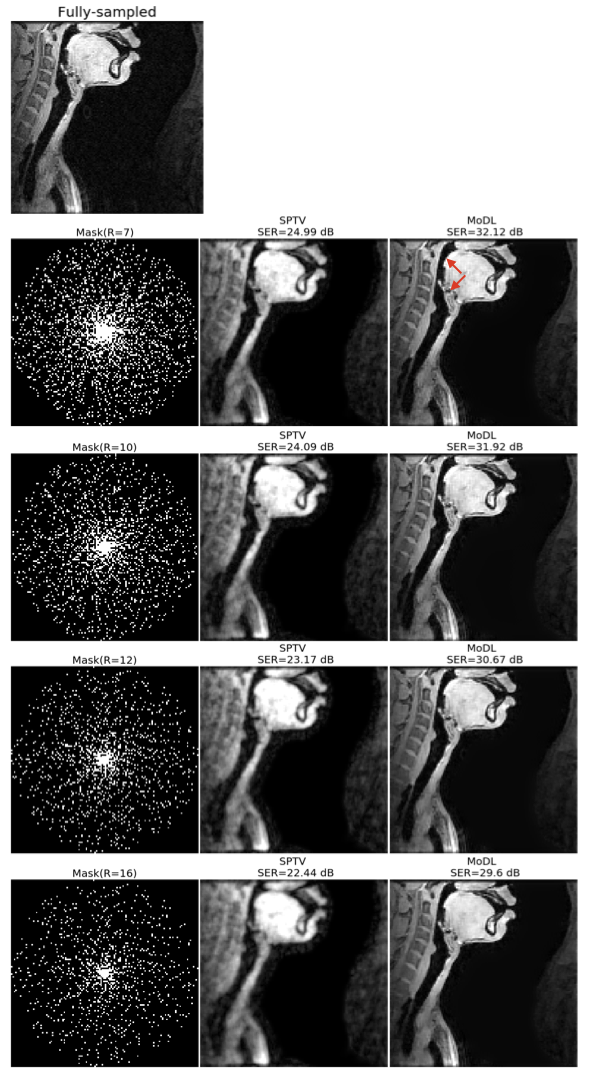
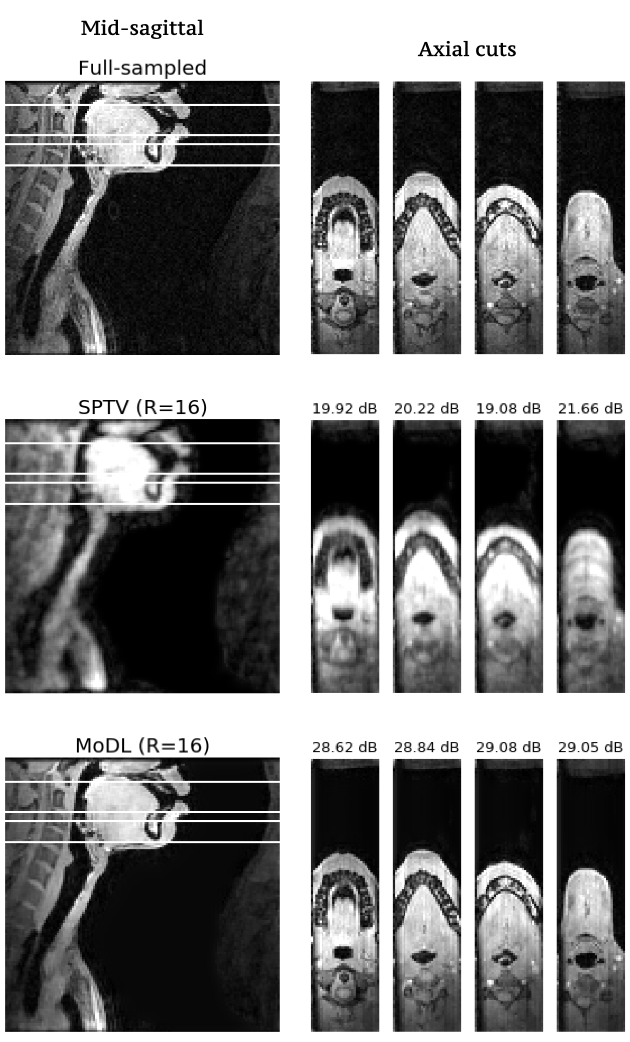
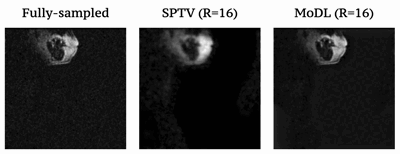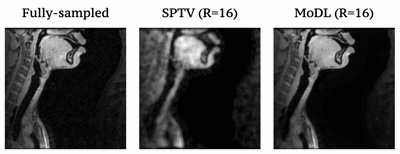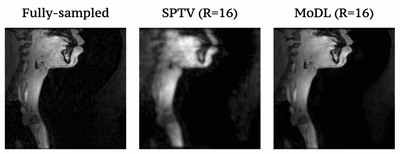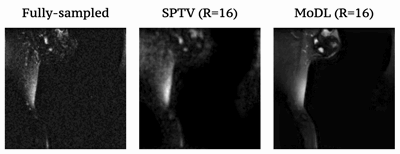
Fig1 shows the reconstructed slices in the mid-sagittal orientation from both MoDL and SPTV at R=7, 10, 12, 16 on the test dataset from a single subject. The signal to error ratio of the reconstruction with respect to the fully-sampled ground-truth is also shown. We observe MoDL to provide naturally looking contrast, robust spatial fidelity in terms of preserving subtle structures such as glottis, epi-glottis. In contrast, SPTV shows significant blurring, and patchy artifacts especially for R>10 (see arrows). This is also consistently reflected in the higher SER with MoDL compared to SPTV. Fig2 shows several axial cuts reconstructed at R=16 from both the schemes. We observe sharp edges and natural texture of the soft-tissues with MoDL, and patchy looking like artifacts with SPTV. Finally, Fig3 shows an animation of the sweep of sagittal slices for the ground-truth, SPTV (reconstructed at R=16), and MoDL (reconstructed at R=16) to demonstrate the improved image quality of MoDL across all the slices.CONCLUSION:
We have successfully demonstrated highly accelerated (upto 16 fold) volumetric imaging of the vocal tract using a model based deep learning (MoDL) scheme. The results show MoDL outperforms existing spatial total variation based regularization schemes in terms of better spatial fidelity, especially in depicting fine structures, and air-tissue boundaries. Future work will include extensions to prospectively under-sampled acquisitions to enable very short (eg. 1-2 secs) 3D scans of sustained speech.Acknowledgements
This work was conducted on an MRI instrument funded by NIH-1S10OD025025-01.References
[1] Scott, A. D., Wylezinska, M., Birch, M. J., & Miquel, M. E. (2014). Speech MRI: morphology and function. Physica Medica, 30(6), 604-618.
[2] Sorensen, T., Skordilis, Z. I., Toutios, A., Kim, Y. C., Zhu, Y., Kim, J., ... & Narayanan, S. S. (2017). Database of Volumetric and Real-Time Vocal Tract MRI for Speech Science. In Interspeech (pp. 645-649).
[3] Lim, Y., Toutios, A., Bliesener, Y. et al. A multispeaker dataset of raw and reconstructed speech production real-time MRI video and 3D volumetric images. Sci Data 8, 187 (2021). https://doi.org/10.1038/s41597-021-00976-x
[4] Lingala, S. G., Toutios, A., Töger, J., Lim, Y., Zhu, Y., Kim, Y. C., ... & Nayak, K. S. (2016, September). State-of-the-Art MRI Protocol for Comprehensive Assessment of Vocal Tract Structure and Function. In Interspeech (pp. 475-479).
[5] Kim, Y. C., Narayanan, S. S., & Nayak, K. S. (2009, April). Accelerated 3D MRI of vocal tract shaping using compressed sensing and parallel imaging. In 2009 IEEE International Conference on Acoustics, Speech and Signal Processing (pp. 389-392). IEEE
[6] Aggarwal, Hemant K., et al. “MoDL: Model-Based Deep Learning Architecture for Inverse Problems.” IEEE Transactions on Medical Imaging, vol. 38, no. 2, IEEE, 2018, pp. 394–405.
[7] W. Alam, R.Z. Rusho, S. Reineke, M. Raja, S. Kruger, J.M. Reinhardt, J. Liu, D.V.Daele, S.G. Lingala, A novel 16 channel flexible coil for highly accelerated upper-airway MRI, annual meeting of ISMRM, May 2021
[8] Y. Cheng et al., “Comprehensive motion-compensated highly accelerated 4D flow MRI with ferumoxytol enhancement for pediatric congenital heart disease,” J. Magn. Reson. Imaging, 2016.
[9] Uecker, Martin, et al. “ESPIRiT—an Eigenvalue Approach to Autocalibrating Parallel MRI: Where SENSE Meets GRAPPA.” Magnetic Resonance in Medicine, vol. 71, no. 3, Wiley Online Library, 2014, pp. 990–1001.
[10] Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., Corrado, G.S., Davis, A., Dean, J., Devin, M., et al. (2016). TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems.
[11] M. Uecker, J. I. Tamir, F. Ong, and M. Lustig, “The BART Toolbox for Computational Magnetic Resonance Imaging,” Ismrm, 2016.
Figures