1242
Motion Correction of Contrast-enhanced Pediatric Brain MRI with Optional Non-contrast-enhanced Synthesis within a Single Neural Network
Jaeuk Yi1, Sewook Kim1, Seul Lee1, Mohammed A. Al-Masni1, Sung-Min Gho2, Young Hun Choi3, and Dong-Hyun Kim1
1Department of Electrical and Electronic Engineering, Yonsei University, Seoul, Korea, Republic of, 2Collaboration & Development, GE Healthcare, Seoul, Korea, Republic of, 3Department of Radiology, Seoul National University Hospital, Seoul, Korea, Republic of
1Department of Electrical and Electronic Engineering, Yonsei University, Seoul, Korea, Republic of, 2Collaboration & Development, GE Healthcare, Seoul, Korea, Republic of, 3Department of Radiology, Seoul National University Hospital, Seoul, Korea, Republic of
Synopsis
Based on the observation that motion corruption and contrast pairs do not exist in a separable way in clinically obtained pediatric contrast-enhanced scans, we developed a neural network for both motion correction and optional non-contrast-enhanced image synthesis for contrast-enhanced pediatric brain MRI. We designed a neural network architecture and training schema specific to this task. We found that motion correction performance was not degraded by doing contrast synthesis simultaneously.
Introduction
Pediatric brain MRI suffers from motion artifacts due to the uncooperativeness of children. There have been several strategies for these motion artifacts with their disadvantages: Sedation is costly and might put children at risk, and prospective motion correction using extra markers requires additional setup, making retrospective correction more desirable for clinical settings. Recent advance in deep learning makes retrospective motion correction an even more viable and attractive choice1,2.Also, acquiring different contrasts diversifies diagnostic information in exchange for the increased exam time3. Recent deep learning-based MR contrast synthesis3,4 shows the possibility to reduce the exam time roughly by half by obtaining one contrast and synthesizing another.
Hence, the ability to perform motion correction while providing additional contrast conversion can be beneficial in the actual pediatric study. In this study, we investigate the possibility of simultaneous motion correction with optional contrast conversion by carefully designing network architecture and training process. Specifically, we focus on providing motion-clean T1 contrast-enhanced (CE) and T1 non-contrast-enhanced (non-CE). This is because CE and non-CE share more common features due to their identical imaging parameters. In addition, CE exams are routinely performed in pediatric imaging yet are susceptible to motion effects. While most of the current approaches focus on CE image synthesis both to eliminate the need for contrast agents and to reduce exam time, we focus on synthesizing non-CE images from CE scans only to reduce exam time as it is impossible to unveil information provided by contrasts agents from only non-CE images3.
Methods
[Data Acquisition]3D T1-weighted sagittal scans were acquired from Seoul National University Children’s Hospital (Seoul, Korea) using inversion recovery prepped fast spoiled gradient-recalled (IR-SPGR) sequence from 3T SIGNA Premier (GE Healthcare, United States) with a 48-channel head coil. The detailed parameters are TE=2.8ms, TR=6.9ms, prep time=450ms, flip angle=10°, voxel resolution=1mm3, matrix size=256×256x100, acceleration factor=1.65. The sampling trajectory is illustrated in Fig.1, which is likely to cause motion artifacts in the form of blurring rather than ghosting5. These scans only exist as coil-combined magnitude images. Of the total 243 scans without motion artifacts, 210 scans are used for training, 33 scans are used for testing on simulated motion artifacts. 10 scans with motion artifacts are used for testing on in-vivo motion artifacts. Among 210 scans for training, 136 scans are paired with CE and non-CE while the rest 74 scans only exist in CE form.
[Motion Simulation]
We simulated 3D rigid body motion artifacts based on random motion trajectory and fixed sampling trajectory as shown in Fig.1. Random motion trajectories are generated from a simple Wiener-like random process.
[Network Architecture]
Inspired by recent style-based generative adversarial networks (GAN)6,7, we treat MR contrasts as styles. Conditional instance normalization8,9 shows that a style of an image can be effectively represented as channel-wise mean and variance while the structure can be represented as a normalized vector in high dimensional feature space. In this manner, we generate a style vector based on a target output contrast and create affine parameters (mean and variance) of normalization layers based on that style vector. Each contrast-specific style vector is generated by selecting the corresponding contrast-specific layer from the multiplexer (MUX) as illustrated in Fig.2a. The conditional discriminator is also informed by the target contrast7,10.
Also, to cope with the 3D nature of motion artifacts in the 3D volumetric imaging1,11, we compose the input of the network by taking multiple adjacent slices from 3D volume as shown in Fig.2a.
[Training]
Fig.2b shows the training schema for our network. All motion-no motion pairs of CE contrast generated by the motion simulation are used to learn motion correction tasks by selecting the CE-specific layers. If a non-CE counterpart of that CE scan exists without motion artifacts, it is used to learn simultaneous motion correction and contrast conversion tasks by selecting the non-CE-specific layers.
The loss formulation is adopted from Pix2Pix12 with the addition of R1 regularization10. We employed Adam optimizer13 with a learning rate of 0.001.
Results
Fig.3 shows in-vivo results of motion correction with optional contrast conversion with the proposed network. Our network can effectively correct in-vivo motion artifacts ranging from weak to severe ones. For the simultaneous contrast conversion task, non-CE images synthesized by our network faithfully follow the structure of ground truth images.Fig.4 shows evaluation of motion correction performance on simulated motion artifacts. Even though our network (“Both”) was trained for two different tasks simultaneously, there was no significant performance difference from the network trained for motion correction only.
Discussion and Conclusion
In this study, we investigated the possibility of simultaneous motion correction with optional contrast conversion. We found that motion correction performance was not degraded by doing contrast conversion simultaneously. While being able to provide other contrast conversions (such as T1 to T2) might be foreseeable, we focused on the conversion from T1 CE to T1 non-CE, which would be more clinically applicable.From Fig.4b, the largest source of error was the error in complex structures outside of the brain, resulting in relatively low SSIM/PSNR values compared to contemporary works1,2. It might be more desirable to train and evaluate in axial view excluding complex structures below the brain than in sagittal view.
Acknowledgements
This study is supported in part by GE Healthcare research funds.References
1. P. M. Johnson and M. Drangova, “Conditional generative adversarial network for 3D rigid-body motion correction in MRI,” Magnetic resonance in medicine, vol. 82, no. 3, pp. 901–910, 2019.2. K. Pawar, Z. Chen, N. J. Shah, and G. F. Egan, “Motion correction in MRI using deep convolutional neural network,” in Proceedings of the ISMRM Scientific Meeting & Exhibition, Paris, 2018, vol. 1174.
3. D. Lee, W.-J. Moon, and J. C. Ye, “Assessing the importance of magnetic resonance contrasts using collaborative generative adversarial networks,” Nature Machine Intelligence, vol. 2, no. 1, pp. 34–42, 2020.
4. S. U. Dar, M. Yurt, L. Karacan, A. Erdem, E. Erdem, and T. Çukur, “Image synthesis in multi-contrast MRI with conditional generative adversarial networks,” IEEE transactions on medical imaging, vol. 38, no. 10, pp. 2375–2388, 2019.
5. A. L Alexander, “Basic Theory of Motion Artifacts in MRI,” ISMRM, 2021.
6. T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4401–4410.
7. Y. Choi, Y. Uh, J. Yoo, and J.-W. Ha, “Stargan v2: Diverse image synthesis for multiple domains,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 8188–8197.
8. V. Dumoulin, J. Shlens, and M. Kudlur, “A learned representation for artistic style,” arXiv preprint arXiv:1610.07629, 2016.
9. X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1501–1510.
10. L. Mescheder, A. Geiger, and S. Nowozin, “Which training methods for GANs do actually converge?,” in International conference on machine learning, 2018, pp. 3481–3490.
11. F. Godenschweger et al., “Motion correction in MRI of the brain,” Physics in Medicine & Biology, vol. 61, no. 5, p. R32, 2016.
12. P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125–1134.
13. D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
Figures
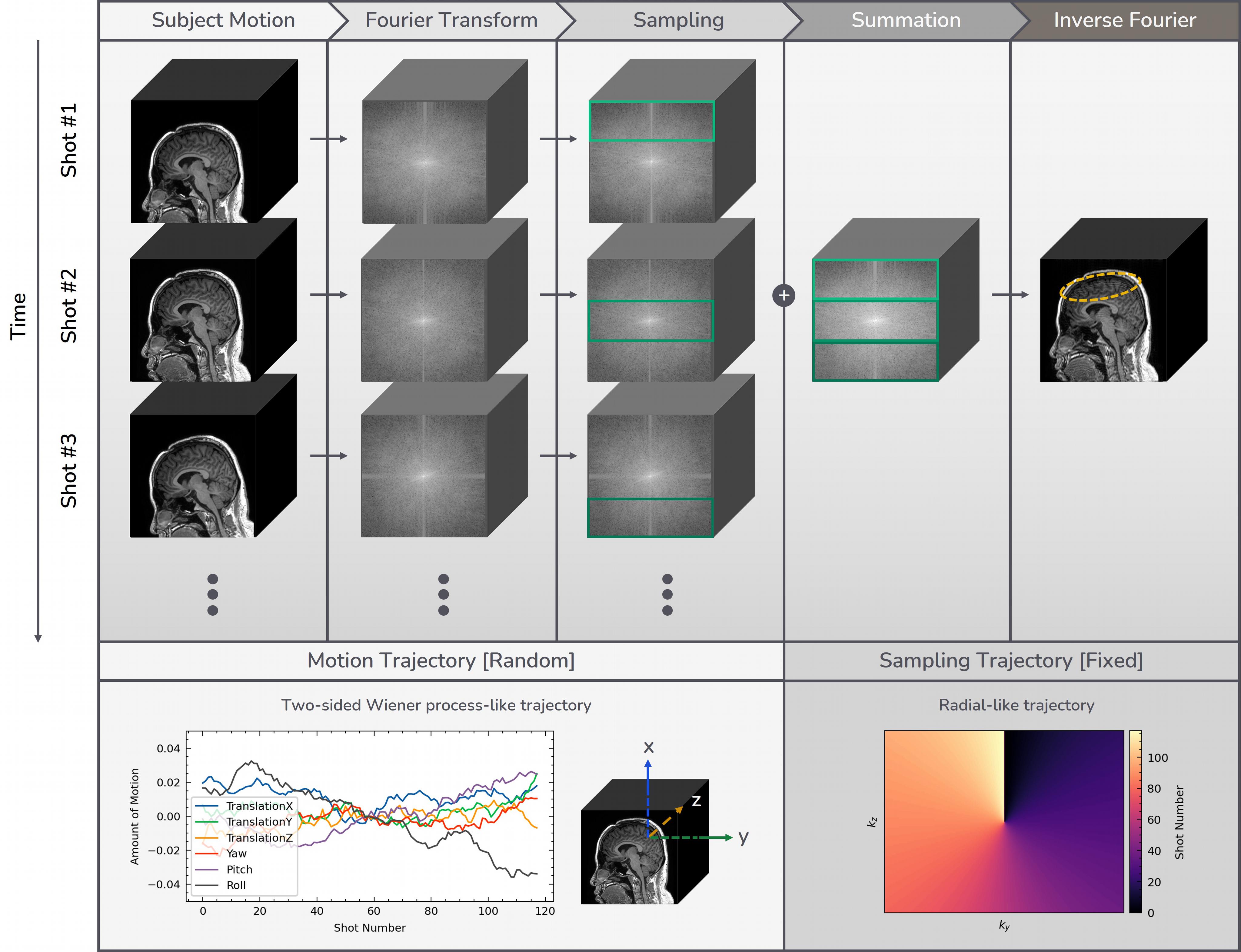
Figure 1. Motion artifact simulation process and design parameters.
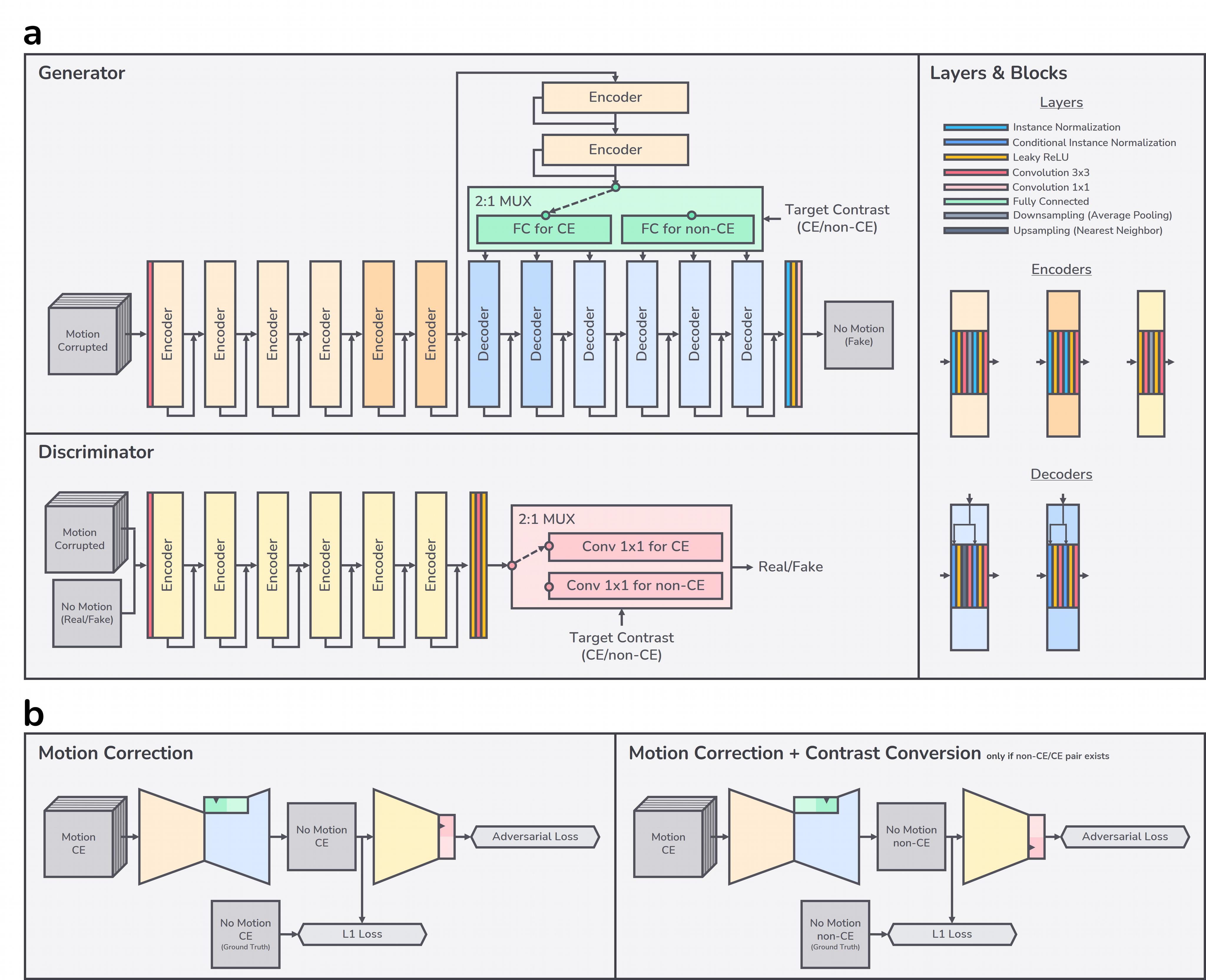
Figure 2. a) Network architecture: skip connections may have appropriate 1x1 convolution or up/downsampling to match with output tensor shape of accompanying blocks. b) Training schema: our network outputs a motion-corrected CE or non-CE image from input motion-corrupted multi-slice CE images.
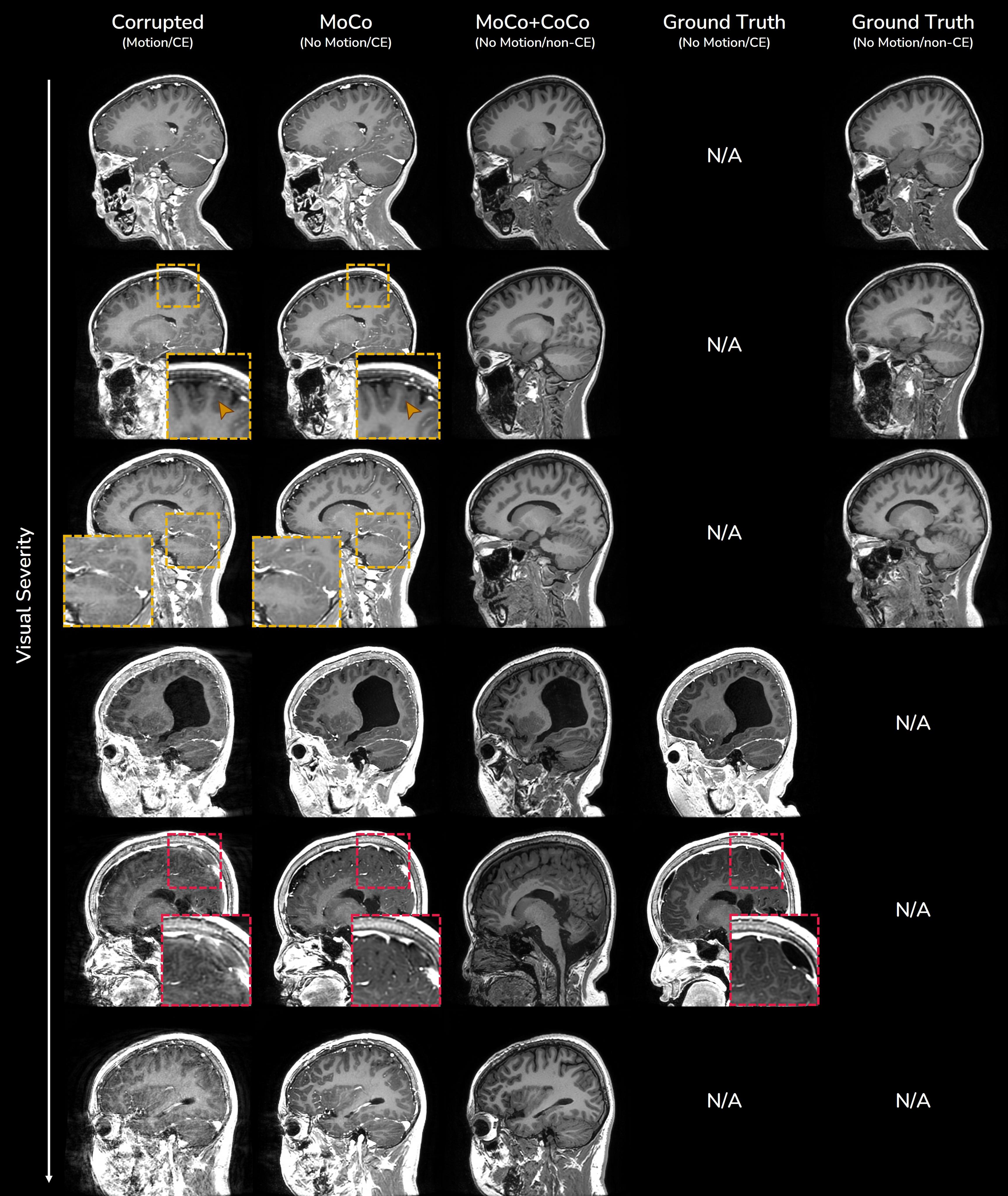
Figure 3. In-vivo results of motion correction (MoCo) with optional contrast conversion (CoCo) within a single network. Ground truth images are obtained either from rescans of severely degraded CE scans or from motion-clean non-CE counterpart scans of CE scans. Some incorrect corrections might happen when the image is severely degraded (red boxes).
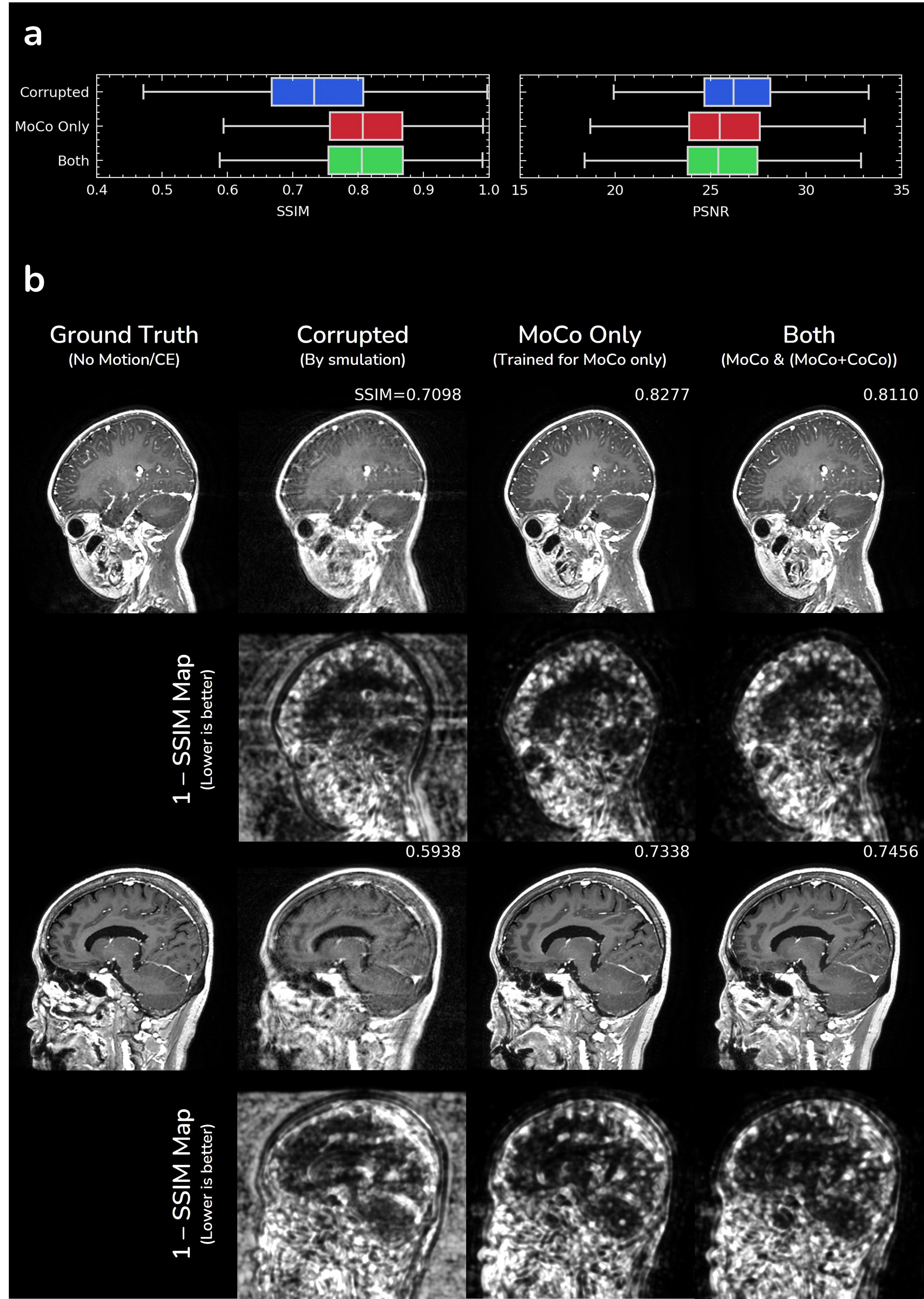
Figure 4. Evaluation of motion correction performance on simulated motion artifacts: a) quantitative evaluation and b) qualitative evaluation. We trained another network with the same architecture but without contrast conversion task in Fig.2b and annotated it as “MoCo Only”.
DOI: https://doi.org/10.58530/2022/1242