1054
Data scarcity mitigation approaches in deep learning reconstruction of undersampled low field MR images1Department of Biomedical Engineering, University of Basel, Allschwil, Switzerland
Synopsis
Low magnetic field (LF) MRI is gaining popularity as a flexible and cost-effective complement to conventional MRI. However, LF-MRI suffers from a low signal-to-noise ratio per unit time which calls for signal averaging and hence prolonged acquisition times, challenging the clinical value of LF MRI.
In this study, we show that Deep Learning (DL) can reconstruct artifact-free heavily undersampled 2D LF MR images (34% sampling) with great success, both retrospectively and prospectively. Our results also highlight that a transfer learning approach combined with data augmentation improves the overall reconstruction performances, even when only small LF training datasets are available.
Introduction
Low magnetic field (LF) MRI is gaining popularity as a flexible and cost-effective complement to conventional MRI1. However, lower magnetic field strengths also mean reduced Signal-to-Noise Ratio (SNR), generally compensated with an increased number of signal averaging (NA). This translates in longer acquisition times, impacting the clinical relevance of LF-MRI.One effective way to accelerate the acquisitions consists in heavily undersampling k-space. Although faster, undersampled acquisitions can lead to artifacts (such as blurring and/or aliasing) in the image space after Fourier Transform (FT). Recently, deep learning (DL) models have been successfully used to remove such artifacts in high field undersampled MR images2,3,4,5.
To avoid overfitting, DL approaches usually require large training dataset that do not currently exist at LF. Methods such as data augmentation and transfer learning (TL) exist that have proven useful to overcome data scarcity4,6. To the best of our knowledge, such approaches were never compared nor combined for potentially greater efficiency.
In this study, we perform a systematic comparison between the following approaches: data augmentation alone, TL alone, and the combination of the two for low-field MR datasets acquired at 0.1T. Performance of the different approaches was evaluated retrospectively, and the best model was then used with prospectively undersampled 2D MR images of the wrist.
Methods
The database used for training was composed of 113 fully sampled images of the human wrist acquired at 0.1 T. Forty-two of those images were acquired with a 2D spoiled gradient echo (GRE) sequence which imaging parameters were: matrix size = [128x85], voxel size = [1.5x1.5x10] mm3, TE/TR = 10.6/22 ms, NA = 125. To increase the amount of available LF images in our database, 71 individual slices originating from various 3D spoiled GRE LF wrist scans were added to the training set.Matrix size was first homogenized across acquisitions to [128x85], before applying a binary mask to k-space and retrospectively simulate undersampled data. Here, 34% of the center of k-space was retained and the DL U-Net7 architecture built using tensorflow8 and keras9 was adopted. For convenience with the selected reconstruction pipeline, k-spaces were further zero-padded to a square matrix ([128x128]) before Fourier transform. The U-Net model was then trained using the RMSProp optimizer and an adaptive learning rate.
The impact of the LF database size was assessed using [5, 10, 15, 20, 25, 30, 40, 50, 75, 100] randomly chosen images from the training set, along with the three following approaches:
1. Data augmentation: LF images were augmented during training using the KerasImageDataGenerator (KIG)9.
2. TL: the model was first trained using 10k images of the ImageNet dataset10 as a source domain, then fine-tuned to the target domain (LF-MRI dataset).
3. KIG + TL: the fine-tuning step of the TL approach was done using KIG.
Additionally, a training using only existing data from the training set (no KIG, no TL), called Vanilla, was performed as a reference. All four approaches were trained and evaluated ten times to assess repeatability.
Additional images were subsequently acquired for validation purposes. Two sets of eleven 2D GRE wrist images were acquired, one fully-sampled and the second undersampled. Both sets were used for the prospective analysis, whereas only the fully-sampled set was needed for the retrospective study (both as reference and simulated undersampled data).
Structure Similarity (SSIM), Mean Squared Error (MSE), and Peak SNR (PSNR) were chosen as comparison metrics, with their mean and standard deviation reported over ten identical trainings to evaluate the method performances.
Results
Figure 1 summarizes the results of the retrospective study. An improvement of up to 1.4%, 8.1%, and 1.4% for the SSIM, MSE and PSNR, respectively, was observed when using KIG+TL compared to vanilla. We notice consistent trends (SSIM,PSNR: increase, MSE: decrease) in the reported metrics with increasing training set size, yet with different slopes depending on the training approach.Figure 2 shows examples of reconstructions of the same simulated undersampled image using models trained on 100 original images with the different approaches. Qualitatively, one can see that the models trained with TL are also able to recover some detail lost due to undersampling.
Figure 3 shows a reconstruction of a prospectively acquired, undersampled LF image using a DL model trained with combined TL and KIG for fine-tuning. Quantitatively and qualitatively, there is a significant improvement compared to the FT reconstruction.
Discussion & Conclusion
We show that DL models can successfully reconstruct heavily undersampled (~3-fold acceleration factor) LF images in spite of a small training dataset. The overall reconstruction performances are improved when using combined TL and KIG, with DL performing consistently better than standard FT.In general, the smaller the size of the LF training set, the greater the gain of using combined TL+KIG compared to Vanilla.
Further development will include DL reconstruction of 3D acquisitions which could benefit from overall higher SNR and more efficient undersampling schemes. If validated, the combined TL and KIG approach may be a significant leap toward clinical relevance for LF MRI.
Acknowledgements
-
The University of Basel,
Faculty of Medicine
References
1 Sarracanie, M. et al. (2020). Low-Field MRI: How Low Can We Go? A Fresh View on an Old Debate. Frontiers in Physics, 8, 172. https://doi.org/10.3389/FPHY.2020.001722 Hyun, C. M. et al. (2018). Deep learning for undersampled MRI reconstruction. Physics in Medicine & Biology, 63(13), 135007. https://doi.org/10.1088/1361-6560/AAC71A
3 Hammernik et al. (2018). Learning a Variational Network for Reconstruction of Accelerated MRI Data. Magnetic Resonance in Medicine, 79(6), 3055. https://doi.org/10.1002/MRM.26977
4 Dar, S. U. H et al. (2020). A Transfer-Learning Approach for Accelerated MRI Using Deep Neural Networks. Magnetic Resonance in Medicine, 84(2), 663–685. https://doi.org/10.1002/MRM.28148
5 Knoll, F. et al. (2019). Assessment of the generalization of learned image reconstruction and the potential for transfer learning. Magnetic Resonance in Medicine, 81(1), 116–128. https://doi.org/10.1002/MRM.27355
6 Shorten, C. et al. (2019). A survey on Image Data Augmentation for Deep Learning. Journal of Big Data 2019 6:1, 6(1), 1–48. https://doi.org/10.1186/S40537-019-0197-0
7 Ronneberger, O. et al.(2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. Lecture Notes in Computer Science, 9351, 234–241. https://doi.org/10.1007/978-3-319-24574-4_28
8 https://www.tensorflow.org/
9 https://keras.io/
10 Deng, J. et al. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248–255).
Figures
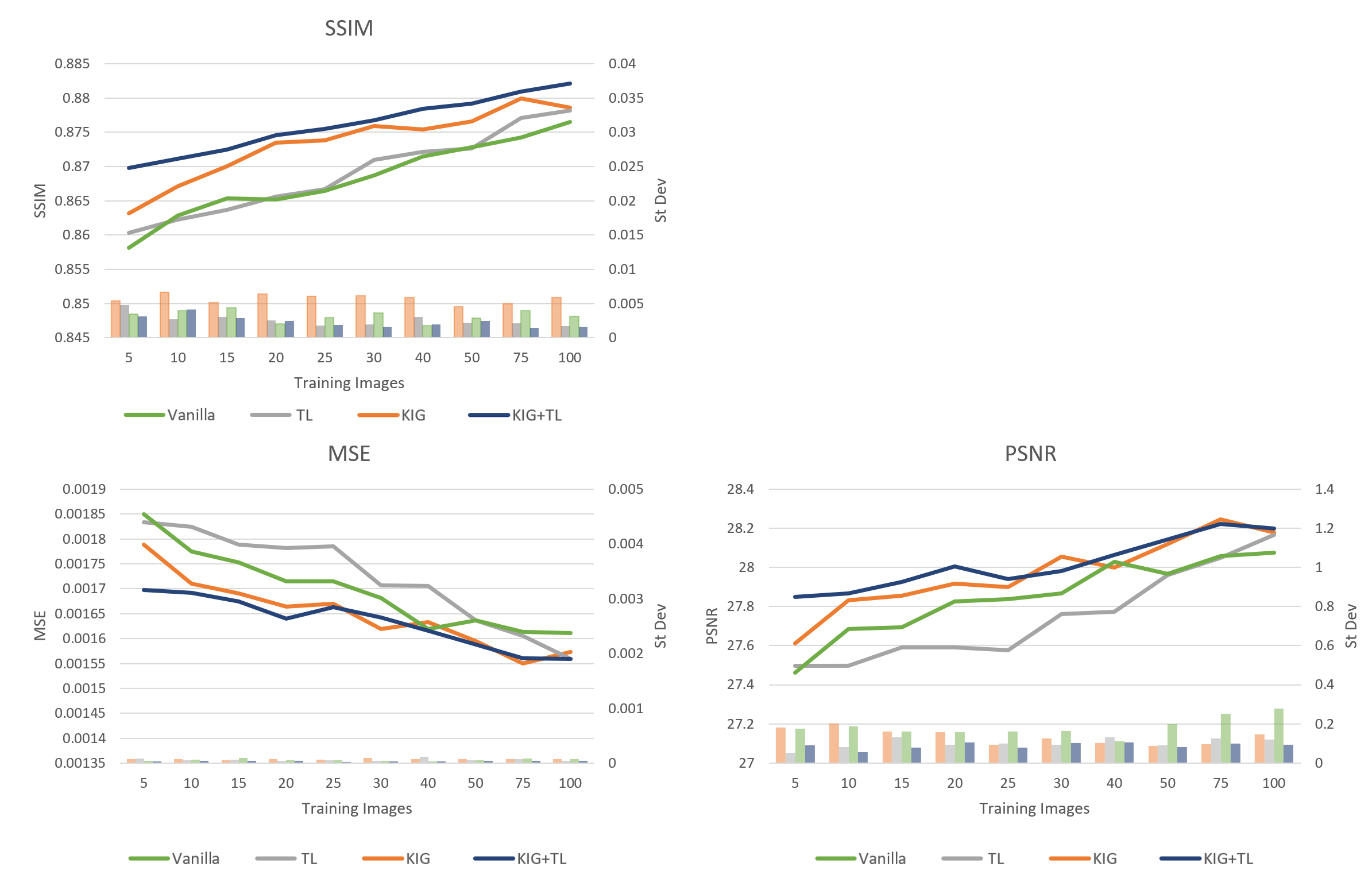
Figure 1: Mean and standard deviations of the 3 comparison metrics (SSIM, MSE, PSNR) for different training approaches and different LF dataset sizes. While there is an expected improvement in all cases when using more original images for training, it can be observed, that there is a clear gain over vanilla training when using TL-only or TL and KIG combined.
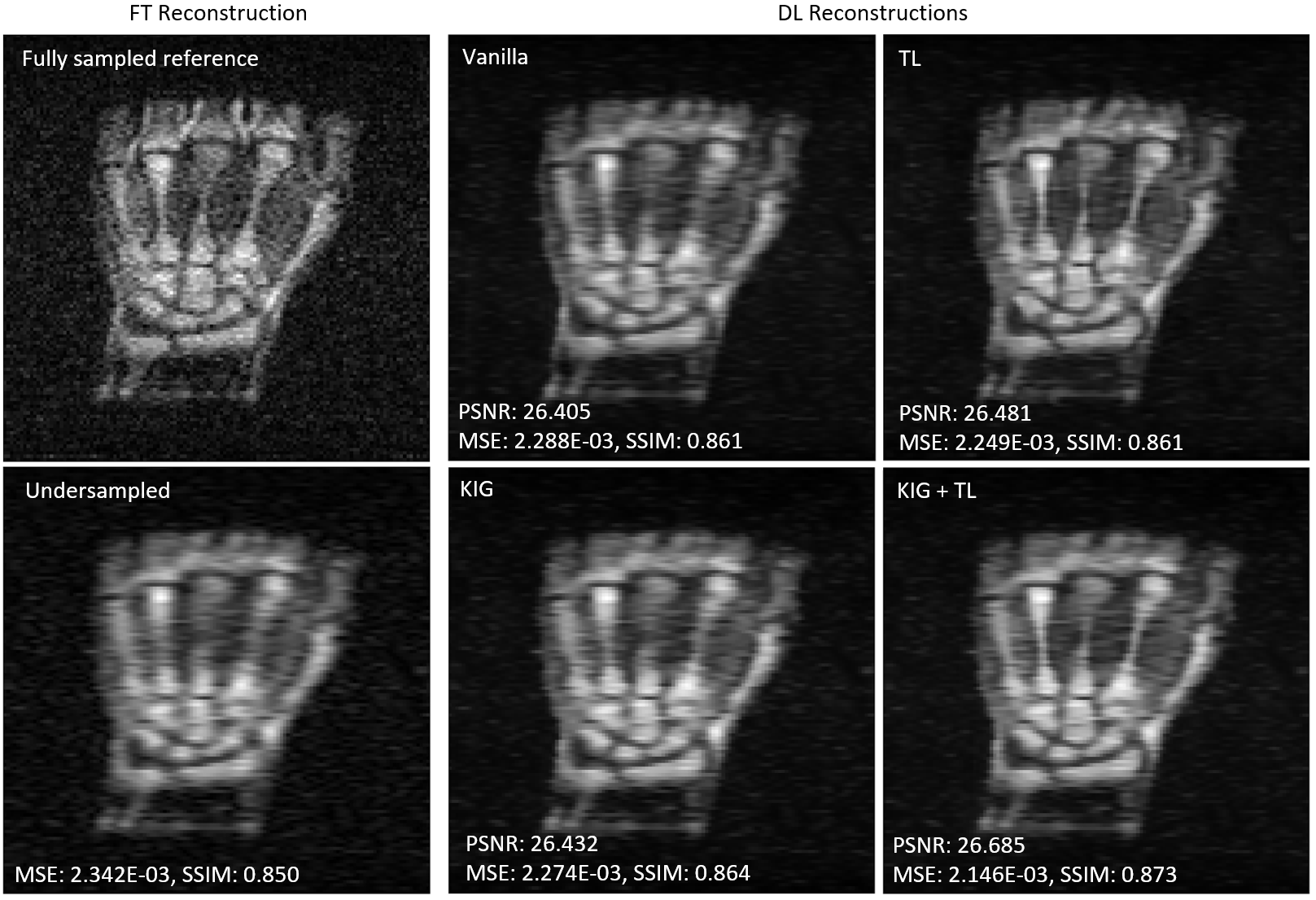
Figure 2: Retrospective example – reconstructions of a simulated undersampled image. All models were trained using 100 original images and the indicated method. It is clear, both qualitatively and quantitatively, that especially the TL approaches are more capable of reconstructing the image and recover detail from the undersampled acquisition, with TL in combination with KIG giving the best outcome.
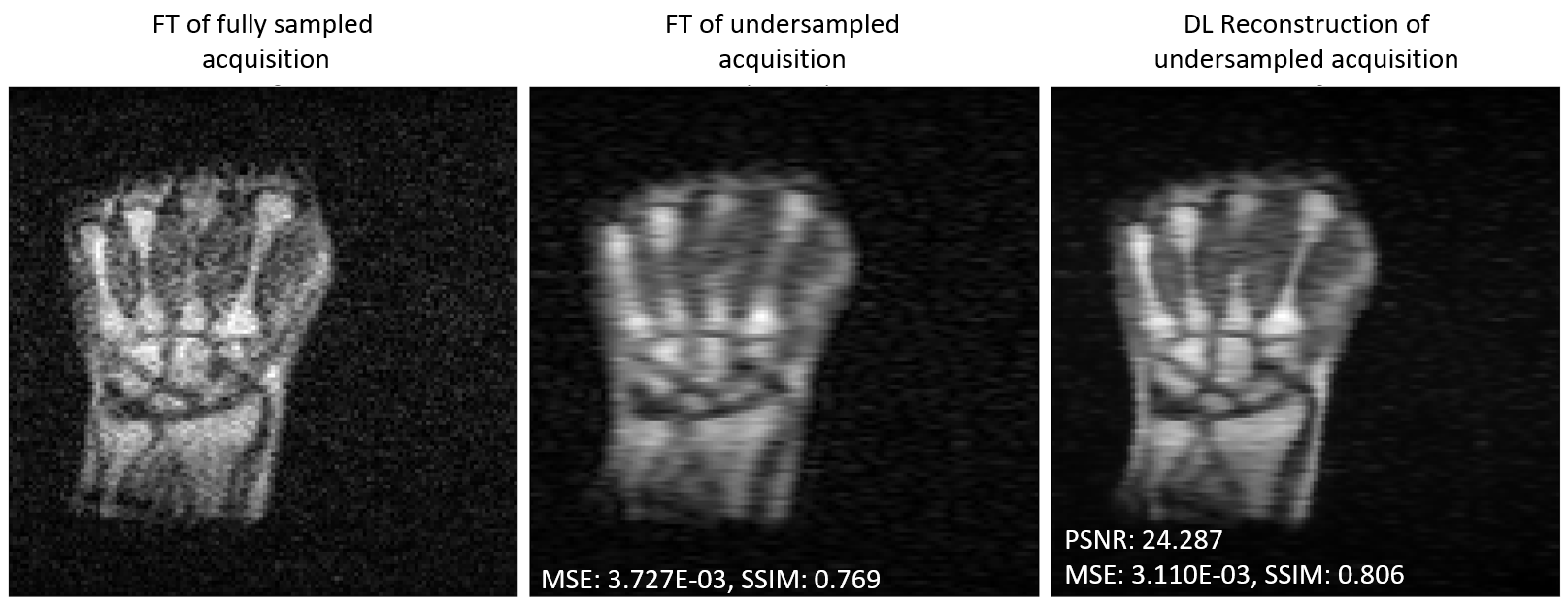
Figure 3: Prospective example – reconstruction of an acquired undersampled image. The metrics as well as the qualitative quality assessment by eye show better results with DL compared to the simple FT reconstruction.