0865
Deep Learning-Based Respiratory Motion Correction in Free-Breathing Abdominal Diffusion-Weighted Imaging
Jinho Kim1,2,3, Fasil Gadjimuradov2,3, Thomas Benkert3, Thomas Vahle3, and Andreas Maier2
1Artificial Intelligence in Biomedical Engineering, Friedrich-Alexander Universität Erlangen-Nürnberg, Erlangen, Germany, 2Pattern Recognition Lab, Department of Computer Science, Friedrich-Alexander Universität Erlangen-Nürnberg, Erlangen, Germany, 3MR Application Pre-development, Siemens Healthcare GmbH, Erlangen, Germany
1Artificial Intelligence in Biomedical Engineering, Friedrich-Alexander Universität Erlangen-Nürnberg, Erlangen, Germany, 2Pattern Recognition Lab, Department of Computer Science, Friedrich-Alexander Universität Erlangen-Nürnberg, Erlangen, Germany, 3MR Application Pre-development, Siemens Healthcare GmbH, Erlangen, Germany
Synopsis
Since a single diffusion-weighted image can suffer from low SNR, multiple DWI repetitions can be averaged to improve SNR, which, however, can introduce blurring due to respiratory motion between different repetitions. Consequently, retrospective gating can be performed to overcome this problem. However, conventional retrospective gating has low SNR efficiency as it discards parts of the data and may result in certain slices to be missing for the desired motion state. This work proposes an efficient Deep Learning-based motion-correction method to improve conventional retrospective gating in free-breathing DWI, resulting in sharper images while maintaining image information from all acquired repetitions.
Introduction
Diffusion-weighted imaging (DWI) is a valuable MRI technique in oncological imaging due to its ability to capture the microscopic motion of water molecules within tissues, which allows visualizing areas of restricted diffusions, such as lesions. However, DWI can suffer from inherently low SNR1. As a remedy against that, multiple repetitions can be averaged, which, however, causes image blurring due to respiratory motion between the repetitions2. To overcome this, retrospective gating can be used to alleviate motion blur by classifying all repetitions into discrete motion states, having advantages of patient comfort and/or predictable scan time in contrast to breath-held or triggered acquisitions3,4. However, inaccuracies of the gating signal can hinder the proper synchronization of image contents. Additionally, the slice stack of images in each motion state can suffer from low SNR and missing slices due to a lower sampling rate per motion state. To tackle these problems, this work proposes an efficient Deep Learning-based motion correction (MoCo) method which synchronizes images properly with an additional process, reduces motion blur, and enhances SNR with no slice voids in the result.Methods
Liver DWI was acquired in 65 volunteers using a prototypical single-shot EPI sequence on 1.5T and 3T MR scanners (MAGNETOM, Siemens Healthcare, Erlangen, Germany). Employed b-values were [50, 800] s/mm2. The numbers of repetitions were [15, 60] at each b-value, respectively, which were three times more than in standard clinical protocols so that the risk of missing slices in individual motion states was reduced. The respiratory signal was measured using table-embedded sensors during the MR scan.Retrospective gating was performed by classifying repetitions into five motion states based on the respiratory signal. After this initial sorting, repetitions dissimilar to others in the same motion state could occur due to unreliable respiratory signals. Since these outliers could induce blurring in the final averaged image for each motion state, they were reclassified by k-means clustering performed on the PCA-transformed image contents.
After sorting, missing slices in motion states could occur. To solve this, an interpolation network was trained with a ResUNet architecture, the combination of ResNet5 and UNet6. For ground-truth data formation, only slices were selected which provided full slice coverage for all motion states. This was the case for almost all slices acquired at the higher b-value with 60 repetitions. Corresponding under-sampled input images were generated by randomly zeroing individual slices in certain motion states. Additionally, interpolated slices of the network output were merged with the available slices of the input to maximize the network's performance.
After filling missing slices with the interpolation network, the MoCo network was applied to correct motion differences and to let all acquired repetitions contribute to better SNR. The MoCo network was also based on the ResUNet architecture. However, unlike the interpolation network, a global residual connection from the last motion state of the input to the output was used to facilitate the task for the network (Figure 1). The average of all N repetitions in the last motion state was set as the target for the MoCo network. To generate the network input for training, N repetitions were randomly selected among all repetitions and then assigned to their proper motion states. This process was repeated for all slices.
The network's performance was evaluated by comparing the resulting images to the input and target and measuring SSIM.
Results
The effect of the reassignment of outliers by k-means clustering is shown in Figure 2. There are some outliers in the fourth and fifth motion states (red squares in (a)). However, outliers are correctly reassigned to their visually appropriate motion states (red squares in (b)). Since the output of the interpolation network is merged with available input slices, the network only provides valid results for void slices (Figure 3). Orange circles and lines in Figure 4 indicate how motion blur is alleviated, and Figure 5 represents that image quality improves in the result for all participant cases but one.Discussion and Conclusion
Applying k-means clustering improves the weak reliability of the respiratory signal so that the MoCo network can predict a sharper output. Additionally, since the interpolation network updates weights based on the merged output, the network predicts plausible image contents where slices are missing but produces ambiguous outputs for available slices. As a result, the merged output shows close agreement with the ground truth. Furthermore, the position of the liver tip of the output along the superior-inferior direction is comparable to the ground truth (orange lines, Figure 4), meaning that the motion blur in the output is reduced compared to the input. Moreover, since all acquired repetitions contribute to predicting the output, the output shows better SNR than the input and no slice voids.However, although outliers are reclassified by k-means clustering, they might still exist. Therefore, a more reliable signal source for retrospective gating, such as PilotTone giving more precise breathing information, can be an alternative7.
As a result, this study proposes a method that effectively reduces motion blurring and, in contrast to conventional retrospective gating, maintains SNR while avoiding the risk of introducing missing slices.
Acknowledgements
No acknowledgement found.References
- J. V. Manjón, P. Coupé, L. Concha, A. Buades, D. L. Collins, and M. Robles, “Diffusion Weighted Image Denoising Using Overcomplete Local PCA,” PLoS One, vol. 8, no. 9, pp. 1–12, 2013
- C. David, T. Vahle, R. Grimm, B. Kiefer, P. Bachert, and M. Kachelries, “Motion Compensation for Free-Breathing Diffusion-Weighted Imaging (MoCo DWI) in Whole Body Integrated PET-MRI,” 2018 IEEE Nucl. Sci. Symp. Med. Imaging Conf.
- H. Kandpal, R. Sharma, K. S. Madhusudhan, and K. S. Kapoor, “Respiratory-triggered versus breath-hold diffusion-weighted MRI of liver lesions: Comparison of image quality and apparent diffusion coefficient values,” Am. J. Roentgenol., vol. 192, no. 4, pp. 915–922, 2009, doi: 10.2214/AJR.08.1260.
- Y. Wang and R. L. Ehman, “Retrospective adaptive motion correction for navigator-gated 3D coronary MR angiography,” J. Magn. Reson. Imaging, vol. 11, no. 2, pp. 208–214, 2000, doi: 10.1002/(SICI)1522-2586(200002)11:2<208::AID-JMRI20>3.0.CO;2-9.
- K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., vol. 2016-Decem, pp. 770–778, 2016, doi: 10.1109/CVPR.2016.90.
- O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” Lect. Notes Comput. Sci. (including Subser. Lect. Notes Artif. Intell. Lect. Notes ioinformatics), vol. 9351, pp. 234–241, 2015, doi: 10.1007/978-3-319-24574-4_28.
- T. Vahle et al., “Respiratory Motion Detection and Correction for MR Using the Pilot Tone: Applications for MR and Simultaneous PET/MR Examinations,” Invest. Radiol., vol. 55, no. 3, pp. 153–159, 2020, doi: 10.1097/RLI.0000000000000619.
Figures
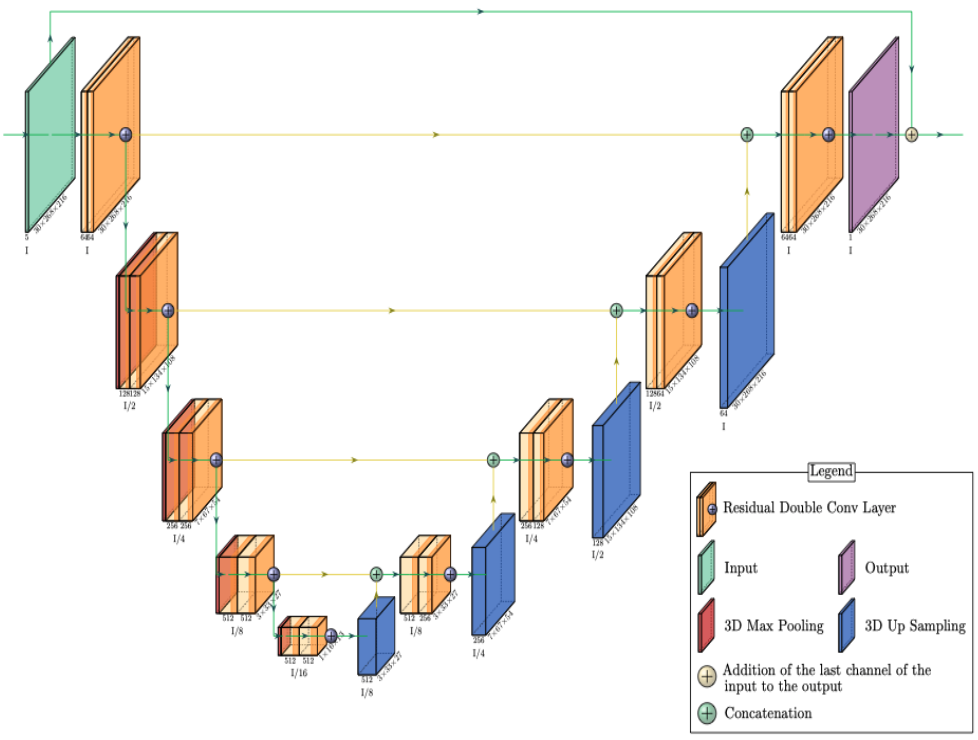
Figure 1: A ResUNet architecture of the MoCo network. The interpolation network does not include a global residual connection that connects the last motion state of the input to the output. Encoder and decoder consist of five levels, respectively. The skip connection connects the encoder to the decoder in the corresponding level.
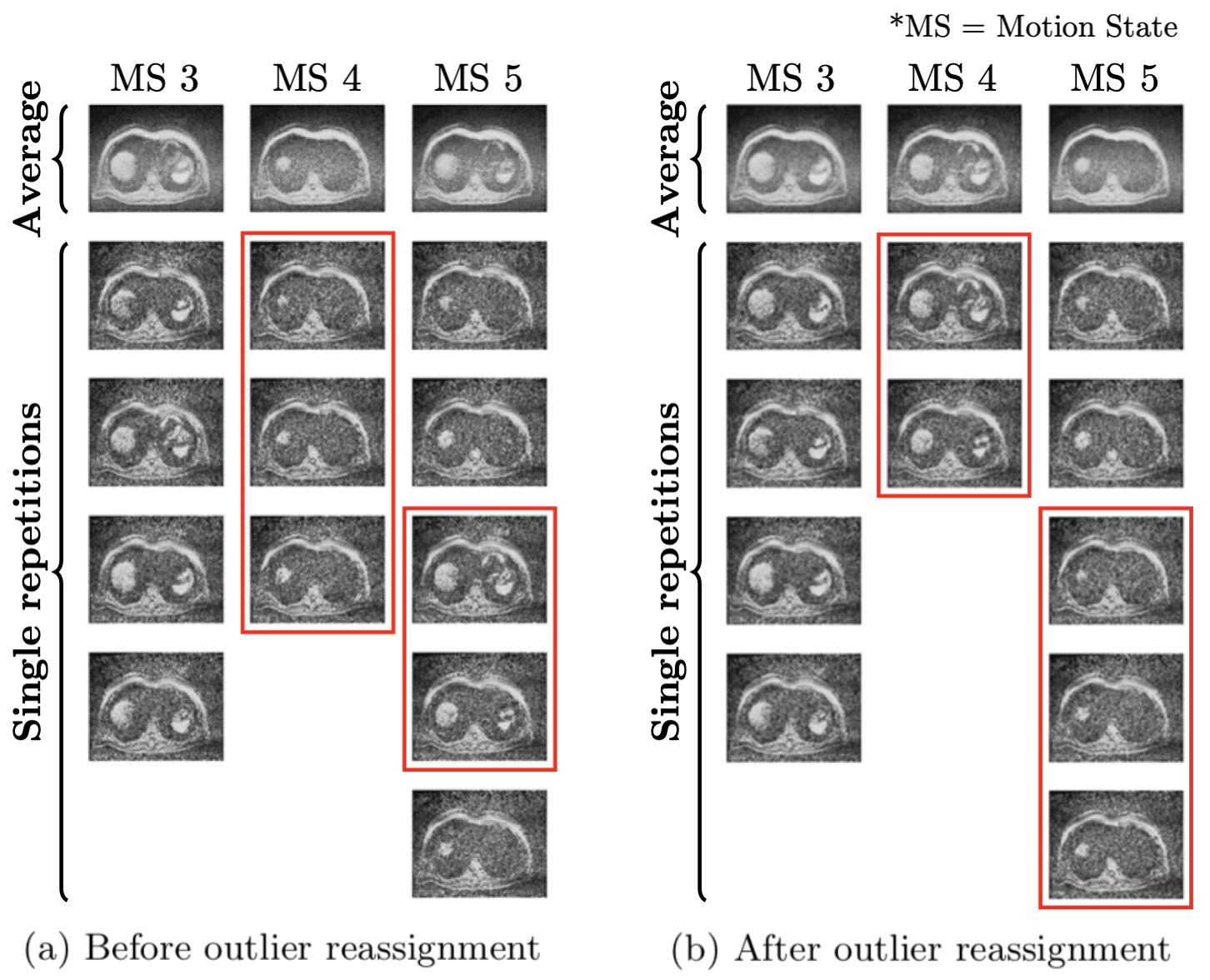
Figure 2: Retrospective gating results for three representative motion states (MS) before (a) and after (b) applying k-means clustering. The first row represents average images over all single repetitions in the corresponding motion state, and others single repetitions. Images inside the red boxes are inconsistent with their respective motion state in (a) and correctly reassigned in (b) after applying outlier reassignment by k-means clustering.

Figure 3: Resulting images of the interpolation network shown for two different volunteers. Each row represents axial, sagittal, and coronal images, respectively. Since retrospective gating is performed, image information is partially missed in the input. This is simulated for network training by randomly zeroing individual slices in some motion states of the ground truth, and the output is the result of the network. The final output is merged with the interpolated part of the output and the available part of the input.
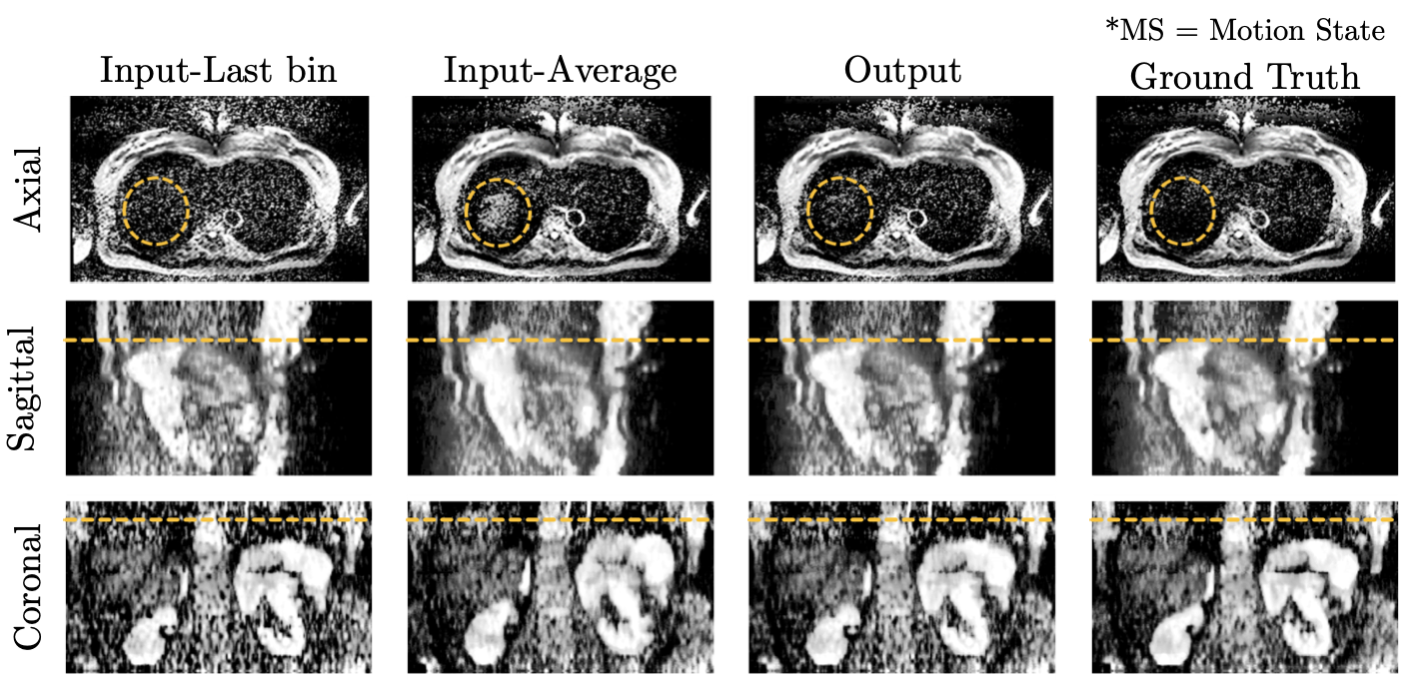
Figure 4: Resulting images of the MoCo network. The input-Last MS represents the averaged repetitions in the last motion state, and the input-Average is the average of all repetitions irrespective of their motion state. Since the input is interpolated by the pre-trained network from the preprocessing stage, void slices do not appear in the input. In addition, the output represents reduced motion blur compared to the input-Average, improved SNR compared to the input-Last MS, and comparable image quality to the ground truth.
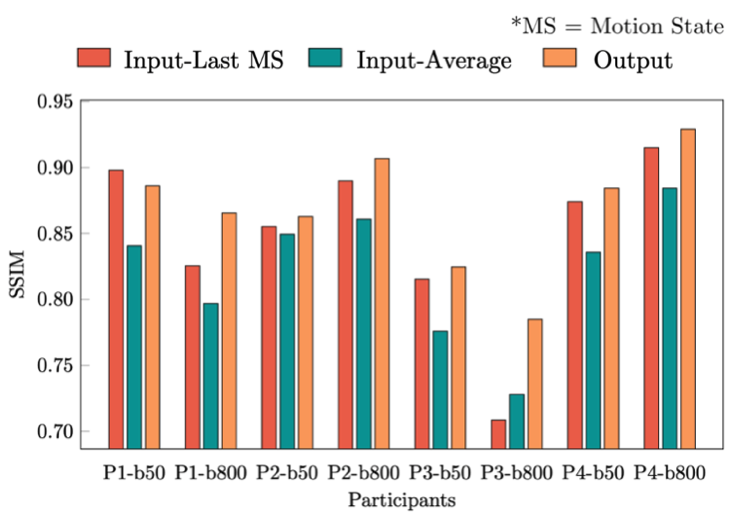
Figure 5: Quantitative measurements in SSIM shown for four volunteers with two different b-values (P1~4-b50/800). MS stands for “motion state.” The input-Last MS (red), the input-Average (green), and the output (orange) are compared to the ground truth, respectively. Since the output shows reduced motion blur significantly compared to the input-Average and improved SNR keeping the same level of motion blur to the input-Last MS, SSIM of the output is superior to both the input-Last MS and the input-Average (exception in P1-b50).
DOI: https://doi.org/10.58530/2022/0865