0864
Unsupervised Deep Learning using modified Cycle Generative Adversarial Network for rigid motion correction in pediatric brain MRI1Department of Electrical and Electronic Engineering, Yonsei University, Seoul, Korea, Republic of, 2GE Healthcare, Seoul, Korea, Republic of, 3Department of Radiology, Seoul National University Hospital, Seoul, Korea, Republic of
Synopsis
Motion artifact that appears due to patient movement in MRI scans is a major obstacle in pediatric imaging. Since acquiring paired motion-clean and motion-corrupted dataset is difficult, unsupervised deep learning such as Cycle Generative Adversarial Network (Cycle-GAN) has been used in motion correction tasks these days. In this study, we propose a rigid motion artifact reducing strategy with modified Cycle-GAN by replacing generator that converts motion-free to motion-corrupted domain with a motion simulator. Our proposed model outperforms in contrast preservation and reducing artifacts compared to the original Cycle-GAN as well as reduces training parameters.
INTRODUCTION
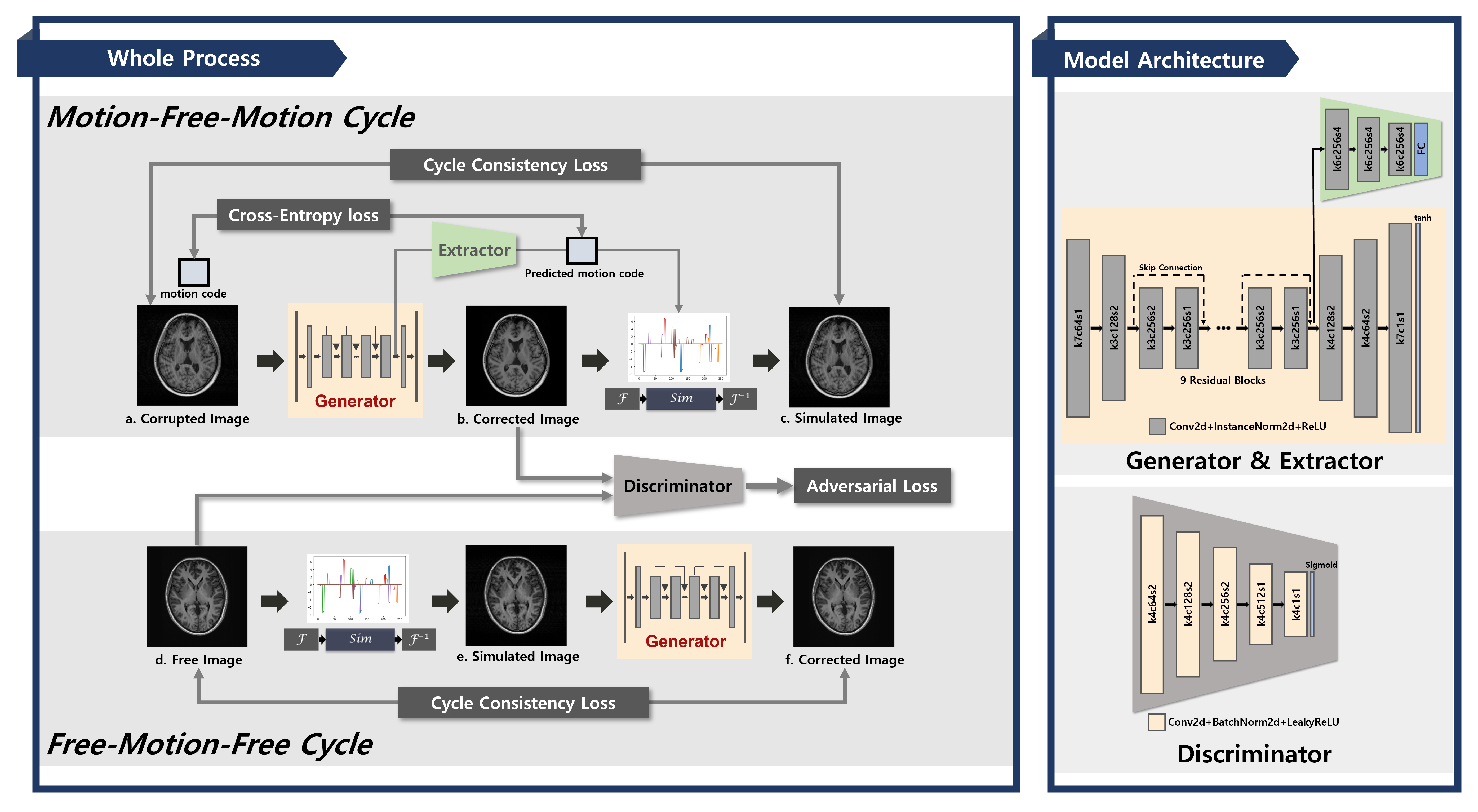
Since children often move during a long MR scan time, motion artifact is a major obstacle in pediatric imaging.1 Conventional motion artifact removal methods that require additional data acquisition time or device setup are not suitable for children, so recently various deep learning-based motion artifact correction methods that do not require additional cost have emerged4. Especially, unsupervised deep learning has been tried for motion correction tasks because of the difficulty on acquiring paired motion-clean and motion-corrupted dataset.Cycle Generative Adversarial Network (Cycle-GAN)5 is one of the unsupervised frameworks that allows bi-directional conversion between motion-corrupted domain and motion-free domain. We have noticed that generator that converts motion-free domain to motion-corrupted domain don't generate realistic motion artifacts properly. Therefore, we propose a motion artifact reducing strategy with Cycle-GAN by replacing this generator with a physics-based motion simulator (Figure. 1). With this, it is possible to produce realistic motion artifacts in training process. Furthermore, a motion level extractor which extracts motion severity from the motion-corrupted images was included in the generator.
METHODS
[Data acquisition]To train our network, we used 3D T1-weighted brain MRI data (BRAVO) obtained from Seoul National University Hospital (SNUH). 5264 slices from 57 pediatric patients were included in the training and validation set, and 470 slices from 6 pediatric patients were used in the evaluation set. The 3D T1-weighted gradient echoes were acquired on a 3T MRI scanner (SIGNA Premier, GE Healthcare, United States) with echo time (TE) of 2.77ms, repetition time (TR) of 6.86ms.
[Motion simulation]
To generate training dataset, motion simulation proceeded in rotation and translation motion considering rigid motion. Based on property of Fourier transform, translation motion was simulated by multiplying phase shift in k-space domain, and rotation motion was simulated in image domain. Especially, 3 severities of motion (e.g., Level 1, 2, 3) were adapted to motion-free image, and the results are shown in Figure 2.
[Training process]
The overall training process and model architectures are shown in Fig 1. We replaced the generator that converts motion-free domain to motion-corrupted domain with a motion simulator unlike original Cycle-GAN structure with two generators and two discriminators. In addition, motion extractor was included in the generator in order to effectively reduce the cycle-consistency loss. In more detail, we designed to extract the severity of motion and forward the results to the simulator to generate motion-corrupted image similar to input at every iteration.
In the Motion-Free-Motion cycle, a generator produces motion-corrected image (Fig 1.b.) from motion-corrupted image (Fig 1.a.) and the motion extractor predicts motion severity of motion-corrupted image simultaneously. Then the motion simulator generates the motion-simulated image (Fig 1.c.) using this predicted motion severity. In particular, we used VGG19-Perceptual loss as the cycle consistency loss for structure preservation. In the Free-Motion-Free cycle, the process was performed in reverse, and L1 loss was calculated as the cycle consistency loss to preserve fine details. The total loss function of our model is shown as below:
$$L_{total}=\lambda_{1}L_{adversarial}+\lambda_{2}L_{cycle-consistency}+\lambda_{3}L_{cross-entropy}$$
RESULTS
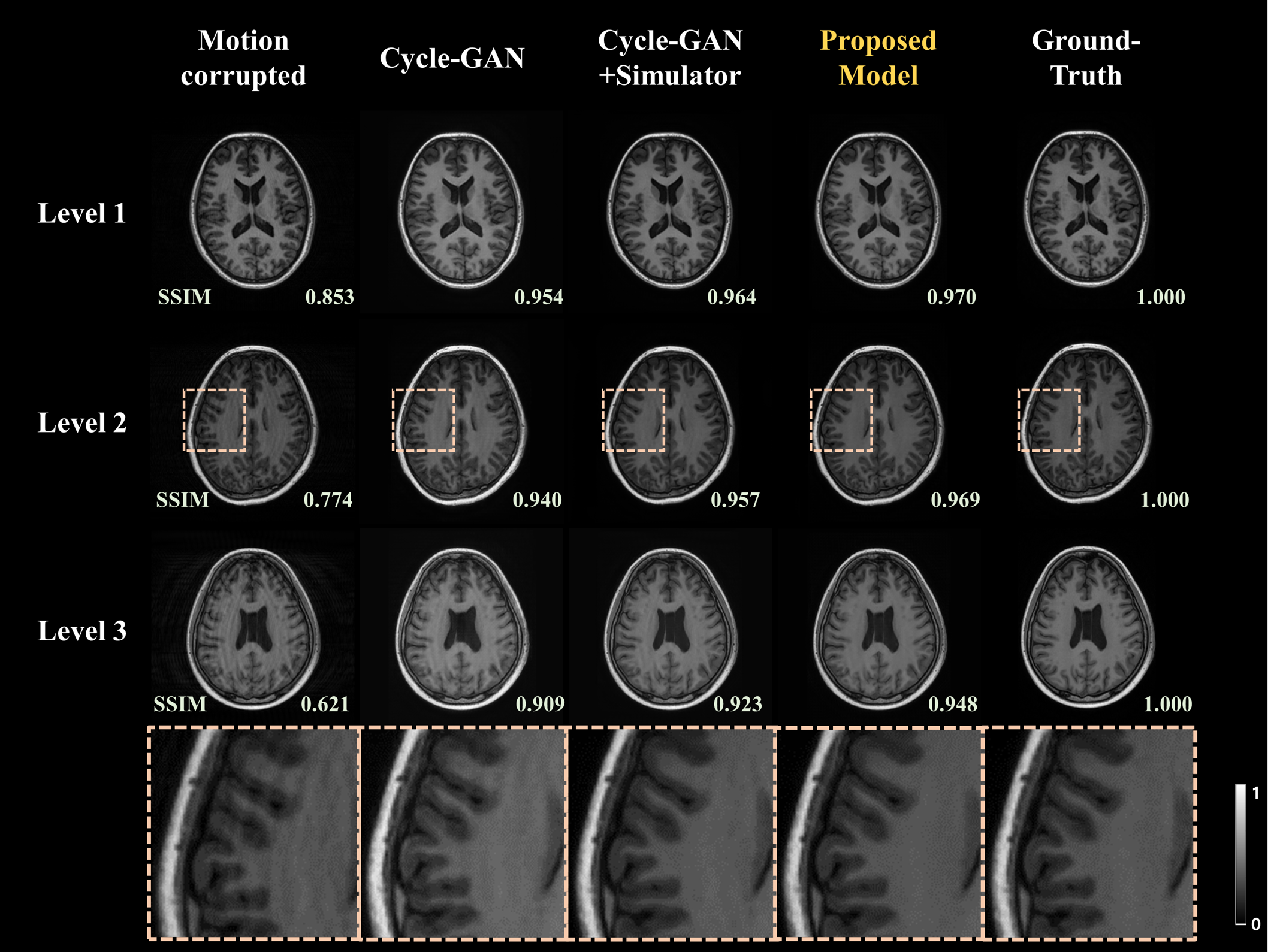
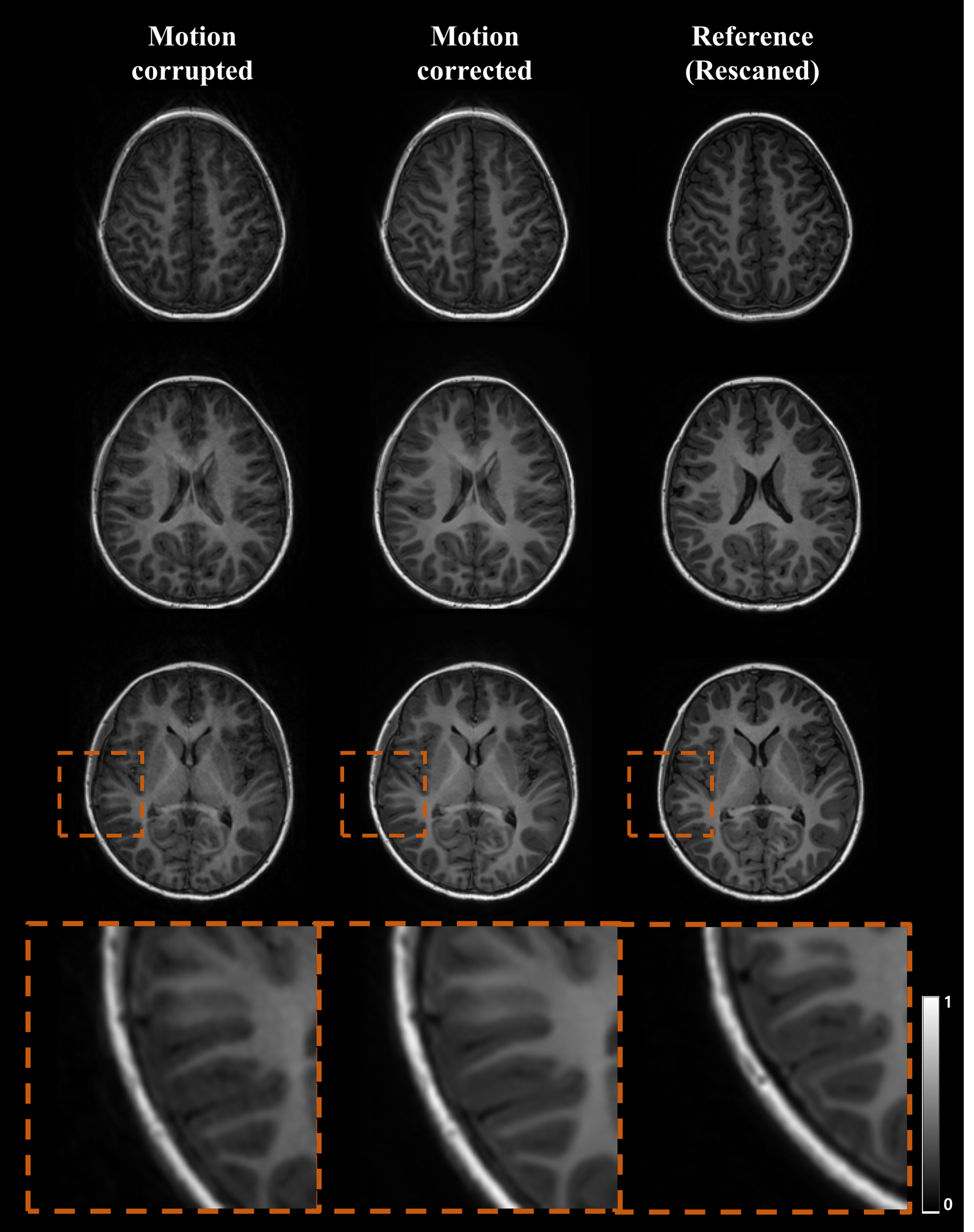
To evaluate the proposed model, we compared it with other models: original Cycle-GAN and proposed model without motion extractor. Figure 3 shows results of each mentioned model for motion artifacts correction. The most significant problem of original Cycle-GAN is contrast conversion in results and even it does not properly remove motion artifacts. Also, the model only with the motion simulator preserves the image contrast but some motion artifacts remain. On the other hand, the proposed model which contains motion extractor successfully removes artifacts as well as preserves the image contrast.Figure 4.a. shows the quantitative metric values of each model. The proposed method achieved highest SSIM and PSNR value among other models. In addition, we compared the pixel intensities of each model based on ground-truth as shown in Figure 4.b. It shows that the proposed model changes image contrast less than the original Cycle-GAN. Also, the results of the proposed model for real motion data are shown in Figure 5. Although the real motion data had slightly more blurring than the simulated data, the artifacts were appropriately removed with the proposed model.
Discussion and Conclusion
We propose a new motion artifact correction strategy that adjusts the modified Cycle-GAN based on unsupervised deep learning. Traditional Cycle-GAN has many network parameters since it contains two generators and two discriminators. However, the proposed model can reduce the number of parameters as well as outperform the original model. Also, unlike the original Cycle-GAN, where the image undergoes two generators when calculating the cycle consistency loss, our proposed model includes motion simulator which only corrupts a few lines in k-space. So image contrast of the propsed model's output can be preserved better than the other model.In the future work, we will include not only motion-simulated data but real motion data as a training dataset by using a motion extractor and it is expected that the network can learn more features of real motion image to compensate the motion artifact.
Acknowledgements
This study is supported in part by GE Healthcare research funds.
References
1. Heiland S. et al. “From A as in Aliasing to Z as in Zipper: Artifacts in MRI.” Clin Neuroradiol 2008; 18: 25-36.
2. Bosak E, et al. “Navigator motion correction of diffusion weighted 3D SSFP imaging.” MAGMA 2001; 12(2-3): 167-76.
3. White NS, et al. “PROMO: realtime prospective motion correction in MRI using image-based tracking.” Magn Reson Med 2010; 63:91–105.
4. Haskell MW, et al. “Network Accelerated Motion Estimation and Reduction (NAMER): Convolutional neural network guided retrospective motion correction using a separable motion model.” Magn Reson Med. 2019; 82: 1452-1461.
5. J. Zhu et al. “Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks.” IEEE International Conference on Computer Vision (ICCV), 2017; 2242-2251.
Figures