0843
Systematic Standardization of Deep Learning Based Accelerated MRI Reconstruction Pipelines1Electrical Engineering, Stanford University, Stanford, CA, United States, 2Equal contribution, Stanford University, Stanford, CA, United States, 3Radiology, Stanford University, Stanford, CA, United States, 4Biomedical Data Science, Stanford University, Stanford, CA, United States
Synopsis
Deep learning based accelerated MRI reconstruction pipelines have potential to enable higher acceleration factors compared to traditional methods with fast reconstruction times and improved image quality. Although there have been studies regarding model architecture, loss function, and k-space undersampling patterns; the effect of scanner parameters, variations in sensitivity map estimation, training data requirement, and engineering decisions during model optimization and evaluation on the reconstruction performance remain largely unexplored. We systematically study the impact of such and show that such data extent, re-processing, and metric computation impact performance to the same or at larger extents than new architectures and loss functions.
Introduction
Deep learning (DL) based accelerated MRI reconstruction [1,2] has gained popularity over traditional methods [3,4] as it may enable higher accelerations with fast reconstruction times and improved image quality. Prior DL reconstruction work has explored (i) image domain methods vs. unrolled variational regularization approaches, (ii) pixel-based vs. adversarial vs. feature-based loss functions, (iii) complex-valued compatibility, (iv) varying methods for data consistency and regularization, (v) varying k-space undersampling paradigms, and (vi) unsupervised reconstruction methods. [1,5,6,7]In contrast to model-based advances, there have been limited investigations that explore DL performance based on the nature of the underlying data and metrics for reconstruction evaluation. Thus, here we systematically study the impact of (i) sequence contrasts, (ii) sensitivity maps, (iii) calibration regions, (iv) training data extent, (v) optimal checkpointing during training, and (vi) methods for computing quantitative metrics. We argue that these data-centric approaches impact the reconstruction performance as much, if not more, as the prior model-centric DL reconstruction approaches.
Methods and Results
Dataset: We use the fastMRI proton-density-weighted multi-coil knee MRI scans with and without fat saturation; and fastMRI axial multi-coil brain MRI scans that include T1 weighting with and without contrast, T2-weighted and FLAIR images [10]. We split the knee dataset into 778 training, 195 validation, and 199 test volumes; and the brain dataset into 757 training, 207 validation, and 414 test volumes. Both anatomies include volumes acquired with 1.5T and 3T field strength scanners. We compute 320x320 complex reference images from the fully-sampled k-space data using ESPIRiT [9], except for the sensitivity map variation experiment where we benchmark JSENSE [8] that jointly estimates the sensitivities and a SENSE reconstruction.Calibration Region: We use fully-sampled calibration regions of 8% for 4x and 4% for 8x acceleration experiments, except for the experiment where we benchmark the impact of the size of the auto-calibration signal (ACS) region.
Model Architecture: We benchmark two different model architectures: (1) U-Net implemented in the fastMRI challenge [10,13] (4 pooling layers, two convolutional blocks per layer where the first convolution has 32 output channels). (2) unrolled neural network [1] inspired by the classical variational regularization approaches with 8 unrolled iterations, 2 residual blocks of 128-dimensional features, and data consistency blocks with learnable weight initialized to -2. We use two channels to represent the real and imaginary components, and normalize the inputs by the 95th percentile of the image magnitude. We train all models for 200 epochs, checkpointing every 10 epochs using complex L1 loss, and report structural similarity (SSIM) [14], and peak signal-to-noise ratio (PSNR, dB) results. Our code and experimental configurations are publicly available at https://github.com/ad12/meddlr.
Data Extent: We investigate training data requirements for the reconstruction models at 4x and 8x acceleration on knee and brain anatomies (Figure 1). We demonstrate that reconstruction performance saturates after including a fraction of the training data in all settings. Progressively increasing training data leads to small performance gains, and even using 5% of the training data recovers ~98% performance, particularly at 4x.
Model selection: We show the impact of choosing different metrics for selecting the best-performing DL-model based on L1 loss, PSNR, and SSIM (Figure 2). We show the variations induced by computing the same metrics either slice-wise or volume-wise or with magnitude versus complex images. We observe up to 4.81dB (PSNR volume, magnitude vs. PSNR slice, complex) and 0.086 SSIM differences (SSIM volume, magnitude vs. SSIM slice, magnitude). Furthermore, we demonstrate that choosing the best model based on PSNR or L1 loss provides comparable results while longer training improves validation PSNR but degrades SSIM.
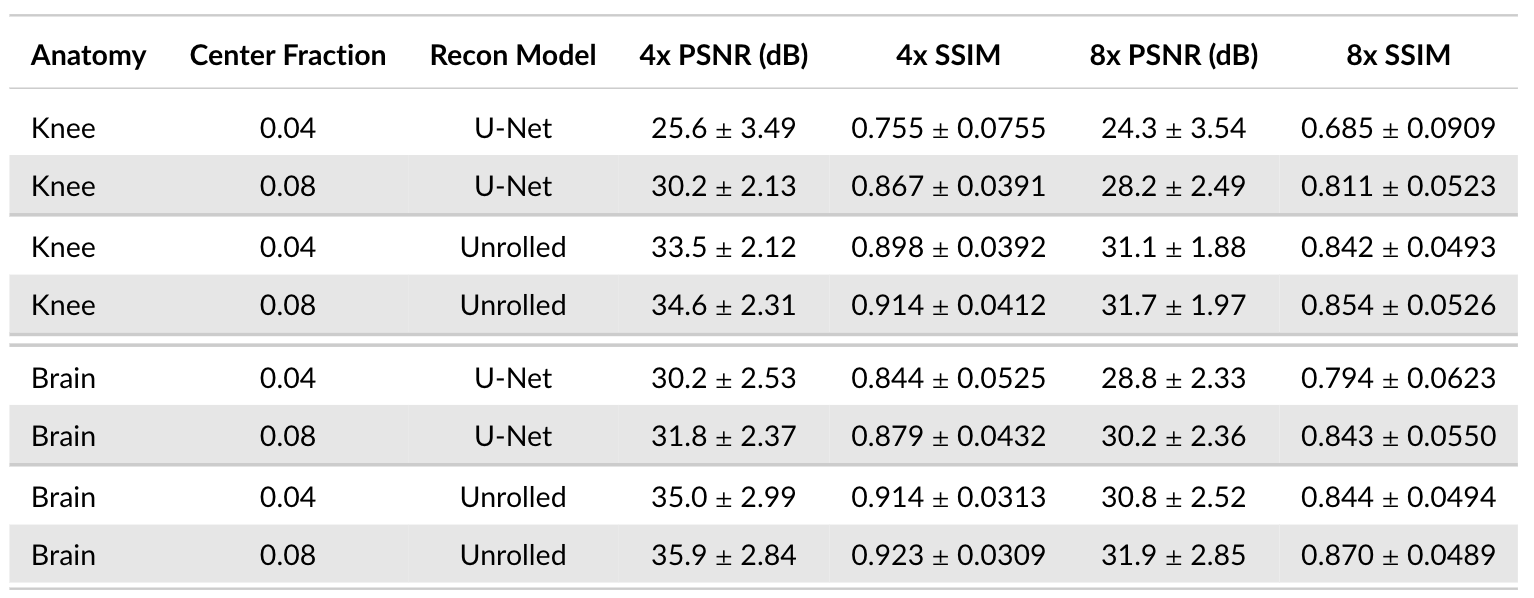
Calibration Region Size: We study the impact of the ACS region size on reconstruction performance across brain and knee anatomies at 4x and 8x acceleration for the U-Net and unrolled DL models using ESPIRiT [9] sensitivity maps. Although both DL models are considerably impacted, we demonstrate that U-Net architecture is particularly sensitive to ACS size changes, leading to 3.9dB PSNR and 0.126 SSIM differences for 8x acceleration on knee data (Figure 3). Increasing ACS from 4% to 8% impacts PSNR more than SSIM, likely because PSNR is more sensitive to the addition of low frequency energy.
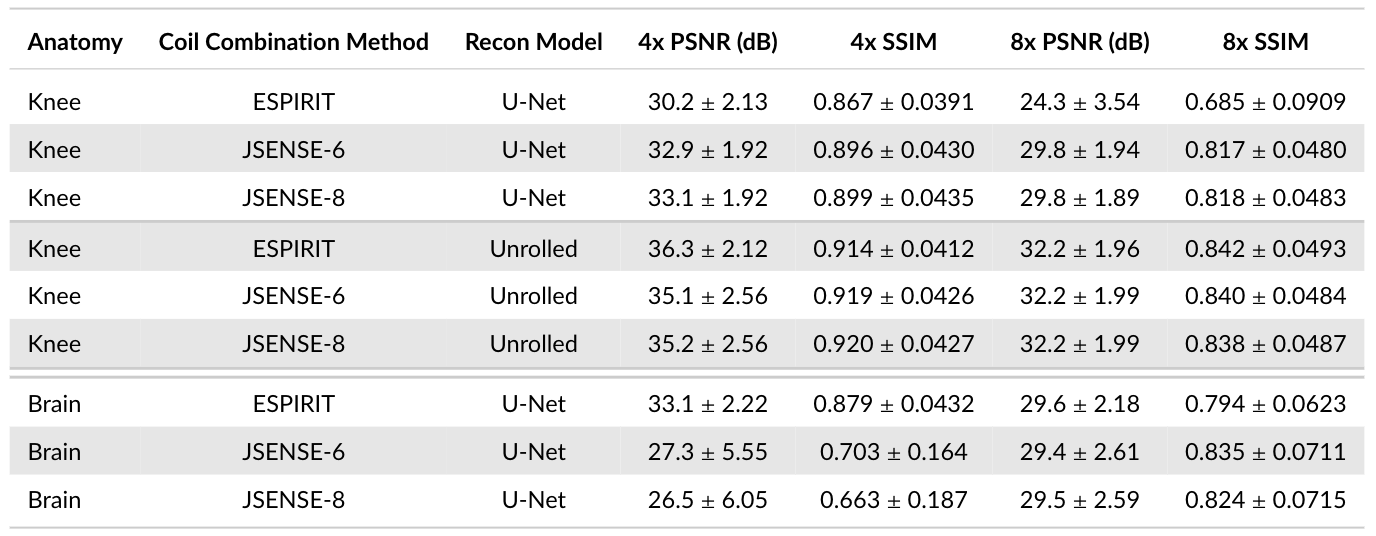
Sensitivity Maps: Comparing JSENSE [8] (kernel widths 6 and 8) and ESPIRiT [9] sensitivity maps (Figure 4) shows that sensitivity maps can induce 6.6dB PSNR and 0.216 SSIM differences (Brain, U-Net) on the same pipeline otherwise. Different sensitivity maps lead to larger performance differences for the U-Net model than the unrolled model.
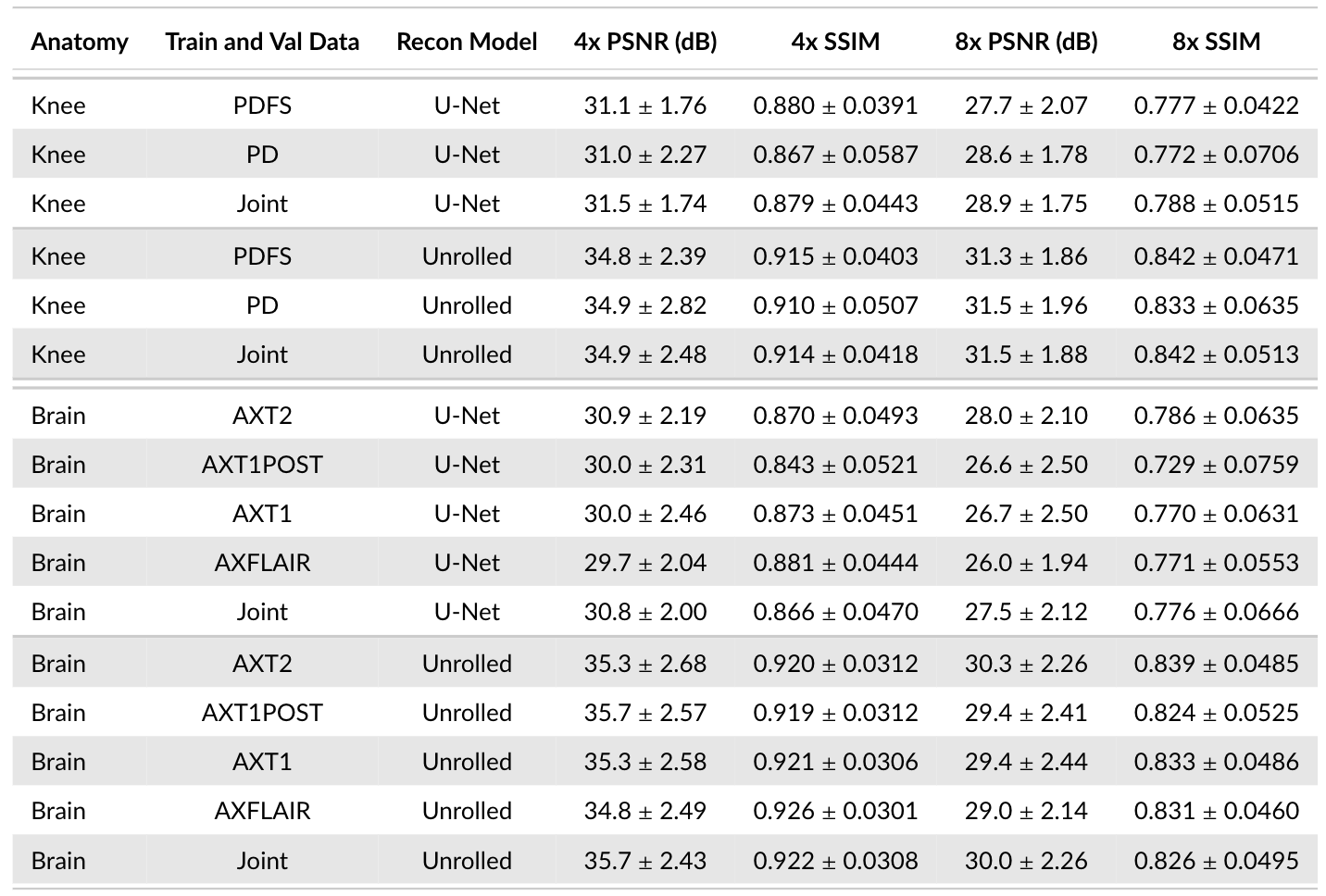
Sequences: Comparing different contrasts for training and validation demonstrates a considerable impact on performance, regardless of model architecture, acceleration, and anatomy (Figure 5). This causes up to 1.4dB PSNR and 0.057 SSIM differences (Brain, U-Net, 8x).
Conclusion
We study the impact of data-centric approaches (sequence contrast, sensitivity maps, ACS region size, training data extent, model selection, and metric calculation) on the reconstruction performance across different anatomies, acceleration factors, and model architectures. We demonstrate that their impact on reconstruction performance is the same or larger than model-centric approaches. We hope that this systematic study contextualizes new DL publications and model comparisons [12], and encourages standardized and open-source engineering practices, open-sourcing code repositories.Acknowledgements
We would like to acknowledge support from NIH U01-EB029427-01, R01EB009690R01, R01EB026136, R01AR077604, R01EB002524, K24AR062068, and from Radiological Sciences Laboratory Seed Grant from Stanford University.References
- Sandino, C.M., Cheng, J., Chen, F., Mardani, M., Pauly, J.M., & Vasanawala, S.S. (2020). Compressed Sensing: From Research to Clinical Practice With Deep Neural Networks: Shortening Scan Times for Magnetic Resonance Imaging. IEEE Signal Processing Magazine, 37, 117-127.
- Hammernik, K., Klatzer, T., Kobler, E., Recht, M.P., Sodickson, D.K., Pock, T., & Knoll, F. (2018). Learning a variational network for reconstruction of accelerated MRI data. Magnetic Resonance in Medicine, 79.
- Murphy, M.J., Alley, M.T., Demmel, J., Keutzer, K., Vasanawala, S.S., & Lustig, M. (2012). Fast $\ell_1$ -SPIRiT Compressed Sensing Parallel Imaging MRI: Scalable Parallel Implementation and Clinically Feasible Runtime. IEEE Transactions on Medical Imaging, 31, 1250-1262.
- Lustig, M., Donoho, D.L., & Pauly, J.M. (2007). Sparse MRI: The application of compressed sensing for rapid MR imaging. Magnetic Resonance in Medicine, 58.
- Chaudhari, A.S., Sandino, C.M., Cole, E., Larson, D.B., Gold, G.E., Vasanawala, S.S., Lungren, M.P., Hargreaves, B.A., & Langlotz, C. (2020). Prospective Deployment of Deep Learning in MRI: A Framework for Important Considerations, Challenges, and Recommendations for Best Practices. Journal of Magnetic Resonance Imaging, 54.
- Hammernik, K., Schlemper, J., Qin, C., Duan, J., Summers, R.M., & Rueckert, D. (2021). Systematic evaluation of iterative deep neural networks for fast parallel MRI reconstruction with sensitivity‐weighted coil combination. Magnetic Resonance in Medicine, 86, 1859 - 1872.
- Ongie, G., Jalal, A., Metzler, C.A., Baraniuk, R., Dimakis, A.G., & Willett, R.M. (2020). Deep Learning Techniques for Inverse Problems in Imaging. IEEE Journal on Selected Areas in Information Theory, 1, 39-56.
- Ying, L., & Sheng, J. (2007). Joint image reconstruction and sensitivity estimation in SENSE (JSENSE). Magnetic Resonance in Medicine, 57.
- Uecker, M., Lai, P., Murphy, M.J., Virtue, P., Elad, M., Pauly, J.M., Vasanawala, S.S., & Lustig, M. (2014). ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA. Magnetic Resonance in Medicine, 71.
- Zbontar, J., Knoll, F., Sriram, A., Muckley, M., Bruno, M., Defazio, A., Parente, M., Geras, K.J., Katsnelson, J., Chandarana, H., Zhang, Z., Drozdzal, M., Romero, A., Rabbat, M.G., Vincent, P., Pinkerton, J., Wang, D., Yakubova, N., Owens, E., Zitnick, C.L., Recht, M.P., Sodickson, D.K., & Lui, Y.W. (2018). fastMRI: An Open Dataset and Benchmarks for Accelerated MRI. ArXiv, abs/1811.08839.
- Bridson, R. (2007). Fast Poisson disk sampling in arbitrary dimensions. SIGGRAPH '07.
- Muckley, M., Riemenschneider, B., Radmanesh, A., Kim, S., Jeong, G., Ko, J., Jun, Y., Shin, H., Hwang, D., Mostapha, M., Arberet, S., Nickel, D., Ramzi, Z., Ciuciu, P., Starck, J., Teuwen, J., Karkalousos, D., Zhang, C., Sriram, A., Huang, Z., Yakubova, N., Lui, Y.W., & Knoll, F. (2020). State-of-the-Art Machine Learning MRI Reconstruction in 2020: Results of the Second fastMRI Challenge. ArXiv, abs/2012.06318.
- Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI.
- Wang, Z., Bovik, A.C., Sheikh, H.R., & Simoncelli, E.P. (2004). Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13, 600-612.
Figures