0556
Registration and quantification net (RQnet) for IVIM-DKI analysis1Electrical Engineering, KAIST, Daejeon, Korea, Republic of
Synopsis
Accurate alignment of multiple diffusion-weighted images must be preceded to predict accurate diffusion parameters. A number of registration approaches have been studied (1,2). However, most of them minimize the dissimilarity between diffusion weighted image and a reference, which can cause errors because the characteristics of the images are different. In order to accurately investigate diffusion, perfusion, and kurtosis parameters using hybrid IVIM-DKI model, a deep learning network is proposed as an end-to-end fashion. This method is entirely unsupervised learning, which does not require reference image for registration and the labeled IVIM-DKI parameters for registration and quantification.
Introduction
The aim of this research is to present a novel end-to-end deep learning method which performs MR image registration and MR parameter quantification simultaneously. Image registration is one of the most critical issues to analyze characteristics of biological tissue using multiple medical images. Especially, MR diffusion imaging requires multiple MR diffusion weighted images to obtain information of diffusion coefficients. The larger number of diffusion weighted images are used, the more accurate diffusion information can be obtained. However, the subject is more likely to move because the acquisition time gets longer to get multiple diffusion weighted images. To solve this problem, subject is fixed or a registration process is used to maximize similarity between the diffusion weighted image and the reference(1,3,4). However, fixing the subject’s body for scanning is a huge burden on the subject and the method maximizing similarity between different contrast images cannot perfectly reduce the registration errors. In this study, we propose a registration and quantification network (RQnet) which performs registration and quantification simultaneously and accurately. We show that RQnet is much faster and more accurate than other comparison methods.Method
Signal modelIn this study, we used IVIM-DKI model to fit the diffusion weighted MR data. The diffusion-weighted signal with the IVIM-DKI model is given as follows.
$$S(b_{i})=S_{0}\cdot(f\cdot exp(-b_{i}D_{p}(\overrightarrow{n}))+(1-f)\cdot exp(-\frac{1}{6} b_i^2 D(\overrightarrow{n})^2 K(\overrightarrow{n})))$$
where $$$S_0$$$ is the MRI signal when b-value is zero, $$$f$$$ is the perfusion fraction, $$$\overrightarrow{n}$$$ is a diffusion gradient vector, $$$D(\overrightarrow{n})$$$ is the diffusion coefficient, $$$D_{p} (\overrightarrow{n})$$$ is the perfusion coefficient along the diffusion gradient vector, and $$$K(\overrightarrow{n})$$$ is the kurtosis along the diffusion gradient vector. We used three orthogonal diffusion gradient vectors.
Spatial transformer network
While convolutional neural network (CNN) is widely used as a powerful tool for learning patterns to recognize image data in recent deep learning studies, it is limited that it is not spatially invariant to input data. Spatial transformer network (STN) was proposed by Google DeepMind in 2015 to handle this problem (5). STN consists of localization network, grid generator and sampler. The localization network predicts parameters for creating a sampling grid. Based on the predicted parameters, sampling grid is generated. Then, sampler produces the output map sampled from the input at the grid points. Since all the processes of STN introduced above are differentiable, it can be updated at each iteration in the direction of minimizing the objective function. In this research, we used STN module for registration and quantification by designing the network in entirely unsupervised fashion.
Proposed Method
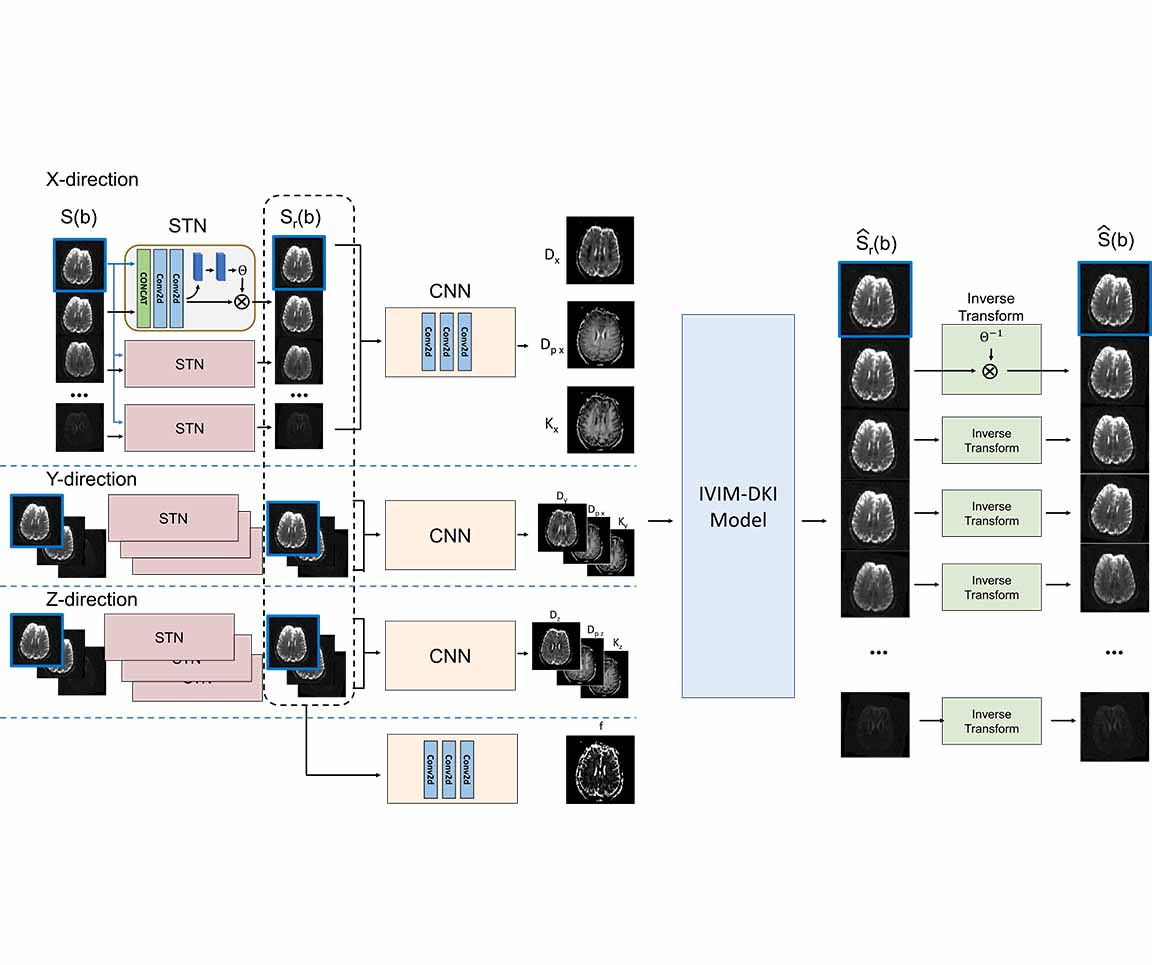
Figure 1 shows overall framework of the proposed method. The proposed method includes four parts: alignment, quantification, signal reconstruction, and inverse alignment. In the first step, mis-aligned diffusion weighted images, $$$S(b)$$$, are the inputs of the network. STN estimates affine transformation parameters between two input images and outputs the aligned images using the parameters. Then, CNN estimates IVIM-DKI parameters in the quantification part. MR signals, $$$\hat{S}_r(b)$$$, are synthesized from $$$S(b = 0)$$$ and the estimated IVIM-DKI parameters using the IVIM-DKI model in the signal reconstruction part. The synthesized MR signal data are inverse-transformed using the affine transformation parameters estimated in the first part.
STN and CNN are optimized to minimize the signal loss between the input mis-aligned diffusion weighted image $$$S(b)$$$ and the inverse-transformed reconstructed image $$$\hat{S} (b)$$$.
$$ ||S(b) - \hat{S} (b)|| $$
In this study, 5000 motion simulated MR diffusion data sets from 10 healthy volunteers were used for training and 500 motion simulated MR diffusion data sets from 3 healthy volunteers are used for test.
In-vivo experiment
MRI experiments were performed on 13 healthy volunteers on a 3 Tesla MRI scanner (Verio, Siemens Healthcare, Germany) with a 32-channel head coil. In vivo experiments were conducted with approval of the institutional review board. A twice-refocused spin-echo EPI sequence was used for the experiments with the imaging parameters as TR=3300ms; TE=107ms; FOV=230mm×230mm; and matrix size=128×128. The diffusion weighted images were acquired for 15 b-values (0, 20, 40, 60, 80, 100, 200, 400, 600, 800, 1000, 1300, 1500, 2000, 2400 s/mm2).Results
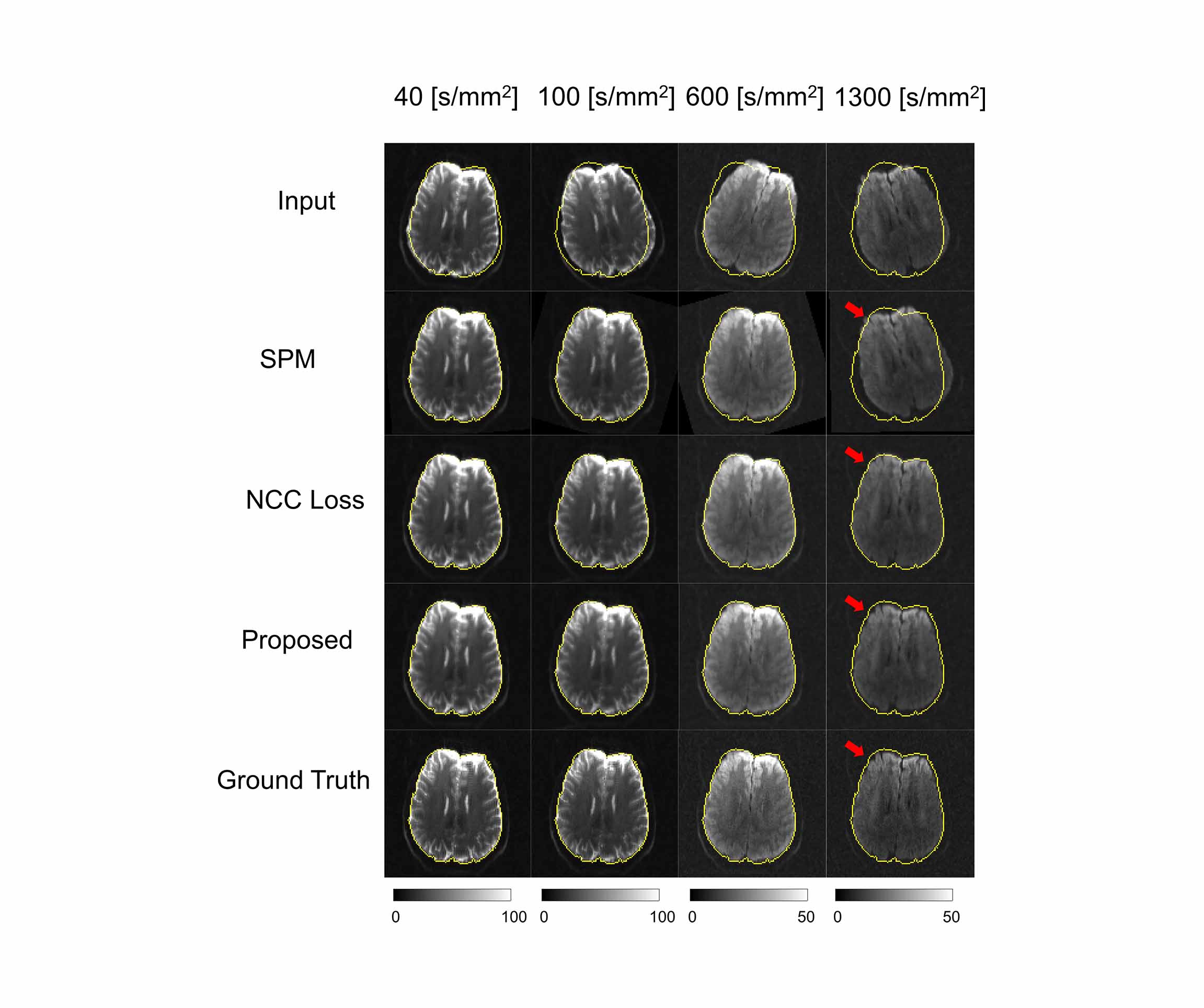
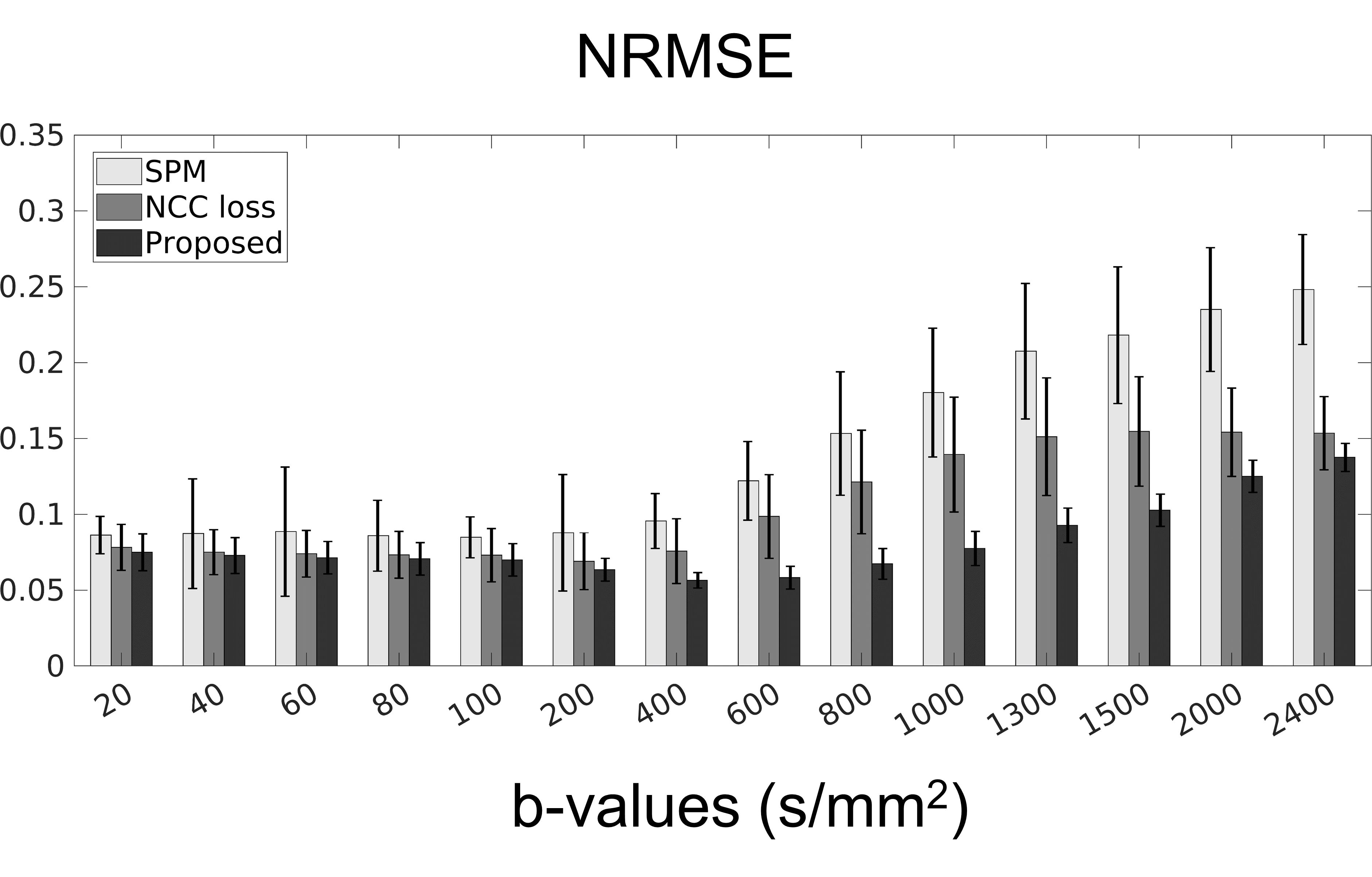
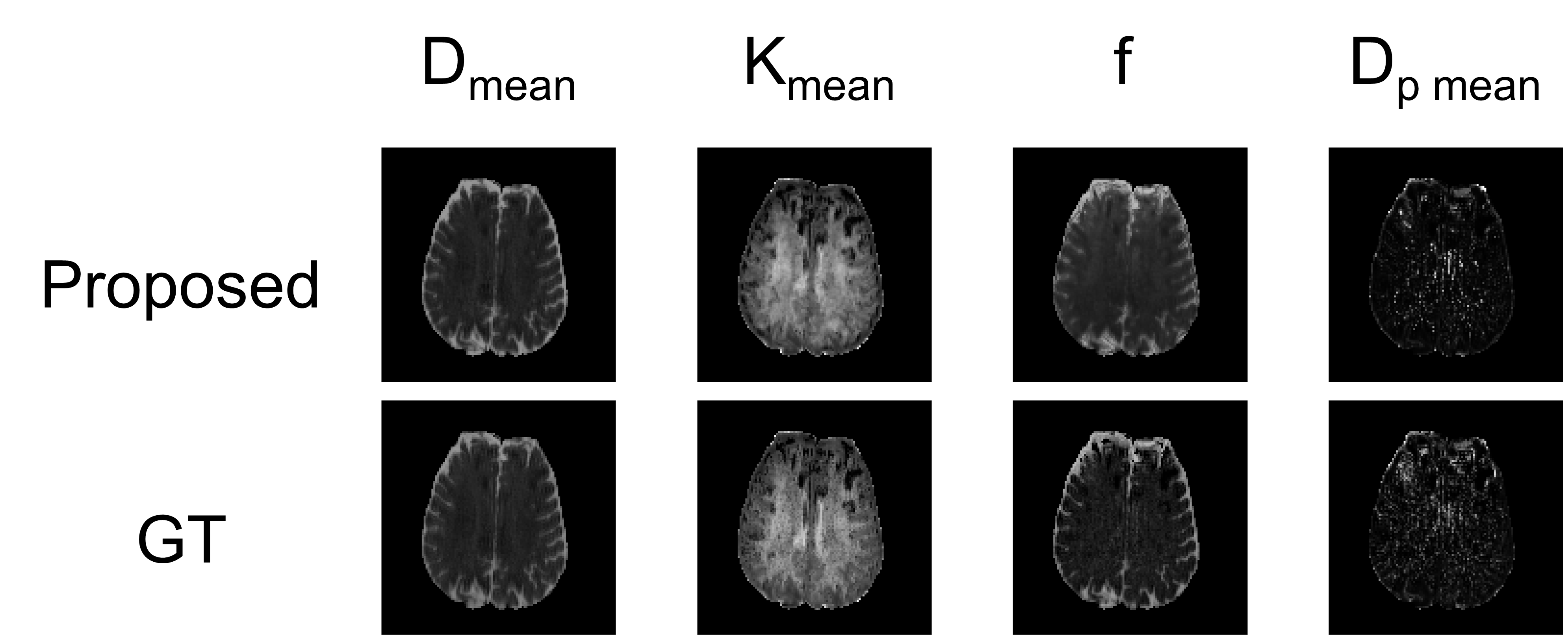
We compared the proposed method to a popular statistical analysis software, SPM. Furthermore, we compared the proposed method to a deep learning method which minimizing normalized cross correlation (NCC) between the reference and the diffusion weighted images. Fig.3 shows the quantitative results of NRMSE between the aligned diffusion weighted images and the ground truth. As shown in Fig.3, NRMSE of the proposed method is lower than the results of the comparison methods for all b-values. Fig.4 shows the quantification results of the proposed method. If quantification is performed with mis-aligned MR diffusion images, accurate IVIM-DKI analysis is impossible. The proposed method performs registration more accurately than the comparison method and performs quantification similar to ground truth. The ground truth parameter maps are estimated using deep learning method on diffusion weighted images of fixed subjects.Discussion & Conclusion
We proposed RQnet to perform accurate registration and quantification. The experiment results showed that the proposed method performed registration more accurately than the comparison methods. Since the proposed network is end-to-end unsupervised learning, the labeled data is not necessary. It is expected that it can be widely applied when it is difficult to obtain labeled data.Acknowledgements
This research was partly supported by a grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number: HI14C1135). This work was also partly supported by Institute for Information & communications Technology Planning & Evaluation(IITP) grant funded by the Korea government(MSIT) (No.2017-0-01779, A machine learning and statistical inference framework for explainable artificial intelligence).References
1. Cao X, Yang J, Wang L, Xue Z, Wang Q, Shen D. Deep learning based inter-modality image registration supervised by intra-modality similarity. 2018. Springer. p 55-63.
2. Kostelec PJ, Periaswamy S. Image registration for MRI. Modern signal processing 2003;46:161-184.
3. Ben‐Amitay S, Jones DK, Assaf Y. Motion correction and registration of high b‐value diffusion weighted images. Magnetic resonance in medicine 2012;67(6):1694-1702.
4. Zhu Y, Zhou Z, Liao G, Yuan K. A novel unsupervised learning model for diffeomorphic image registration. 2021. International Society for Optics and Photonics. p 115960M.
5. Jaderberg M, Simonyan K, Zisserman A. Spatial transformer networks. Advances in neural information processing systems 2015;28:2017-2025.
Figures