0304
Comparison of Self-Supervised Image Reconstruction Methods for Undersampled Image Reconstruction: Validation in a Realistic Setting1Signal Processing Lab 5 (LTS5), Ecole Polytechnique Fédérale de Lausanne, Lausanne, Switzerland, 2Medical Image Analysis Laboratory, Center for Biomedical Imaging (CIBM), University of Lausanne, Lausanne, Switzerland, 3Advanced Clinical Imaging Technology, Siemens Healthcare, Lausanne, Switzerland, 4Department of Radiology, Lausanne University Hospital and University of Lausanne, Lausanne, Switzerland
Synopsis
Self-supervised reconstruction methods for undersampled acquisitions are becoming increasingly used. We compare different self-supervised reconstruction methods using fully sampled and prospectively/retrospectively accelerated data; we find that prospective and retrospective reconstructions can differ significantly in quantitative metrics and perceptual quality. To test the methods’ generalizability, prospectively accelerated data from multiple field strengths is reconstructed without retraining/retuning. We find that no-reference image quality metrics can distinguish state of the art methods from the baseline, albeit with ambiguity between the state of the art methods.
Introduction
Recently, self-supervised, deep learning approaches to reconstruct undersampled MR data have been explored for sequences where acquiring ground truth, fully sampled data is challenging or infeasible1-3. However, the validation of self-supervised approaches understandably tend to be limited to quantitative evaluation on retrospectively undersampled data, i.e. artificial undersampling of a fully sampled dataset, and qualitative evaluation on prospectively undersampled data(i.e. acquired, undersampled data). This limitation may stem from commonly used datasets being fully sampled4-6. However, this neglects quantitative evaluation of reconstructions from prospectively undersampled data (which is the realistic scenario) as well as potential differences between prospective and retrospective reconstructions7. Furthermore, the generalizability of methods, i.e., inference data different from the training/tuning data(e.g. in terms of field strength, sequence parameters), is generally not explored.In this work, we implemented various self-supervised reconstruction methods, optimized to reconstruct MPRAGE images at 3T. The methods are compared on phantom data and in-vivo data at different field strengths using both full-reference and no-reference quality metrics.
Methods
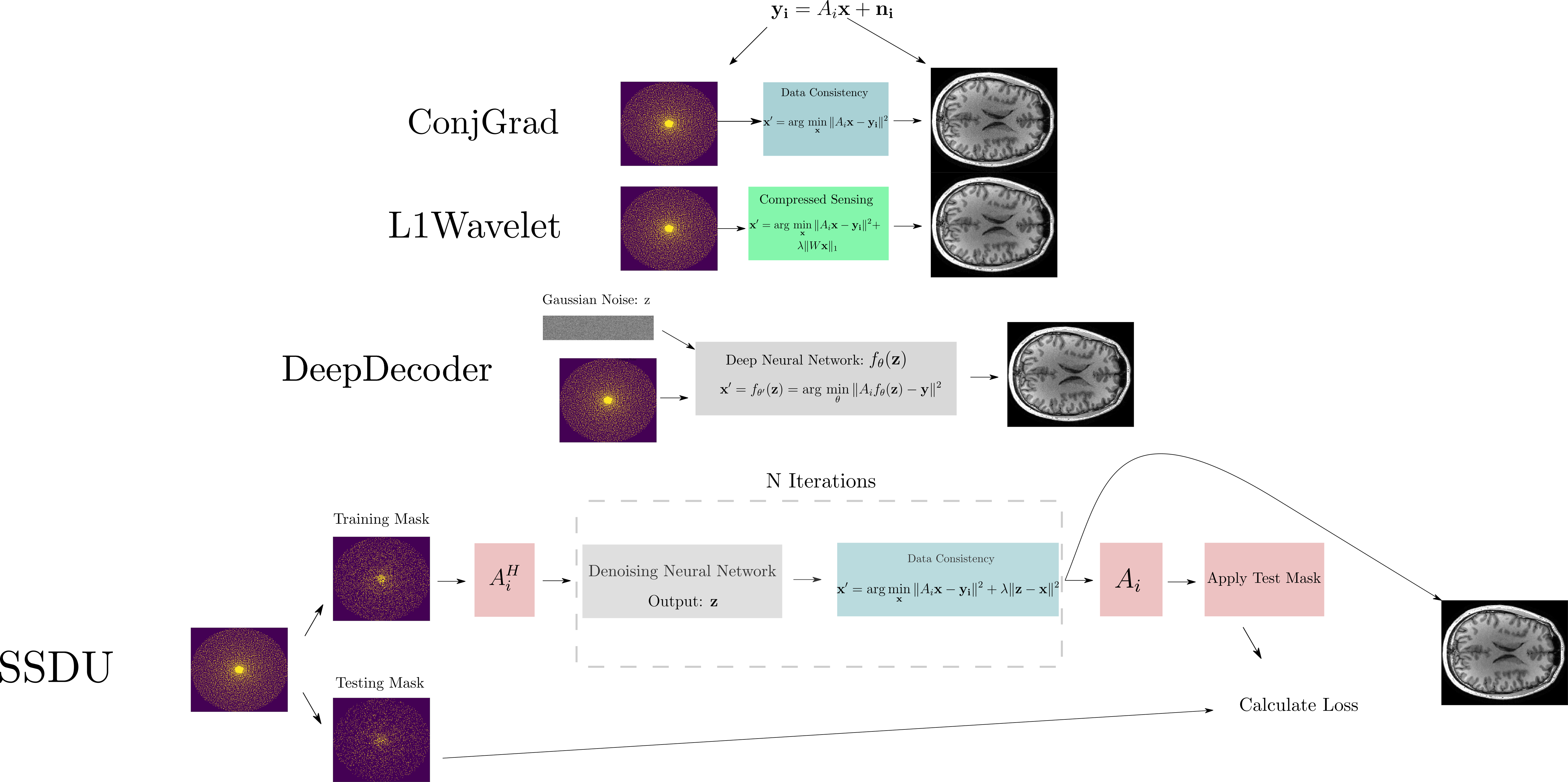
To mimic a typical training dataset, where data is limited in size and variability, we acquired a 5x accelerated MPRAGE prototype sequence of the brain in ten healthy subjects at 3T (MAGNETOM PrismaFit, Siemens Healthcare, Erlangen, Germany) using a 64Rx Head/Neck coil (see Figure 3 for sequence parameters). This incoherently undersampled data8 was used for training/tuning the hyperparameters of four reconstruction methods:1.ConjGrad, a baseline, least squares model fitting
2.L1Wavelet, a Compressed Sensing(CS) reconstruction with L1 Wavelet regularization14
3..DeepDecoder3,16, based on Deep Image Prior15 from computer vision, where a convolutional neural network(CNN) is trained to map Gaussian noise to the image using data consistency as the loss; it can be theoretically shown that restriction to the range of the CNN implicitly regularizes the reconstruction16.
4.Self-supervised learning via data undersampling (SSDU)1, where the reconstruction iteratively alternates between optimization of the data consistency term and passing through a neural network.
In Figure 1, we show an inverse problem formulation of undersampled reconstruction and the four different methods for reconstruction from k-space that we used. In SSDU, the network is trained by masking the undersampled data into two, disjoint parts; at each training step, one part is passed to the network and the other is used for calculating the loss with respect to the output reconstruction. This is a special case of a self-supervised denoising technique called Noise2Self17 which proves that this strategy approximately optimizes the noise-free error between measured and reconstructed data; hence, the neural network is acting as a denoising regularizer. To tune the regularization parameter/hyperparameters of L1Wavelet/DeepDecoder in a self-supervised manner, we also use the Noise2Self framework. All networks and training strategies were implemented as in the original papers (except replacement of the ResNet18 of SSDU with a U-Net19) in Pytorch20. We used Sigpy21 for the computation of L1Wavelet and ESPiRiT22 sensitivity maps.
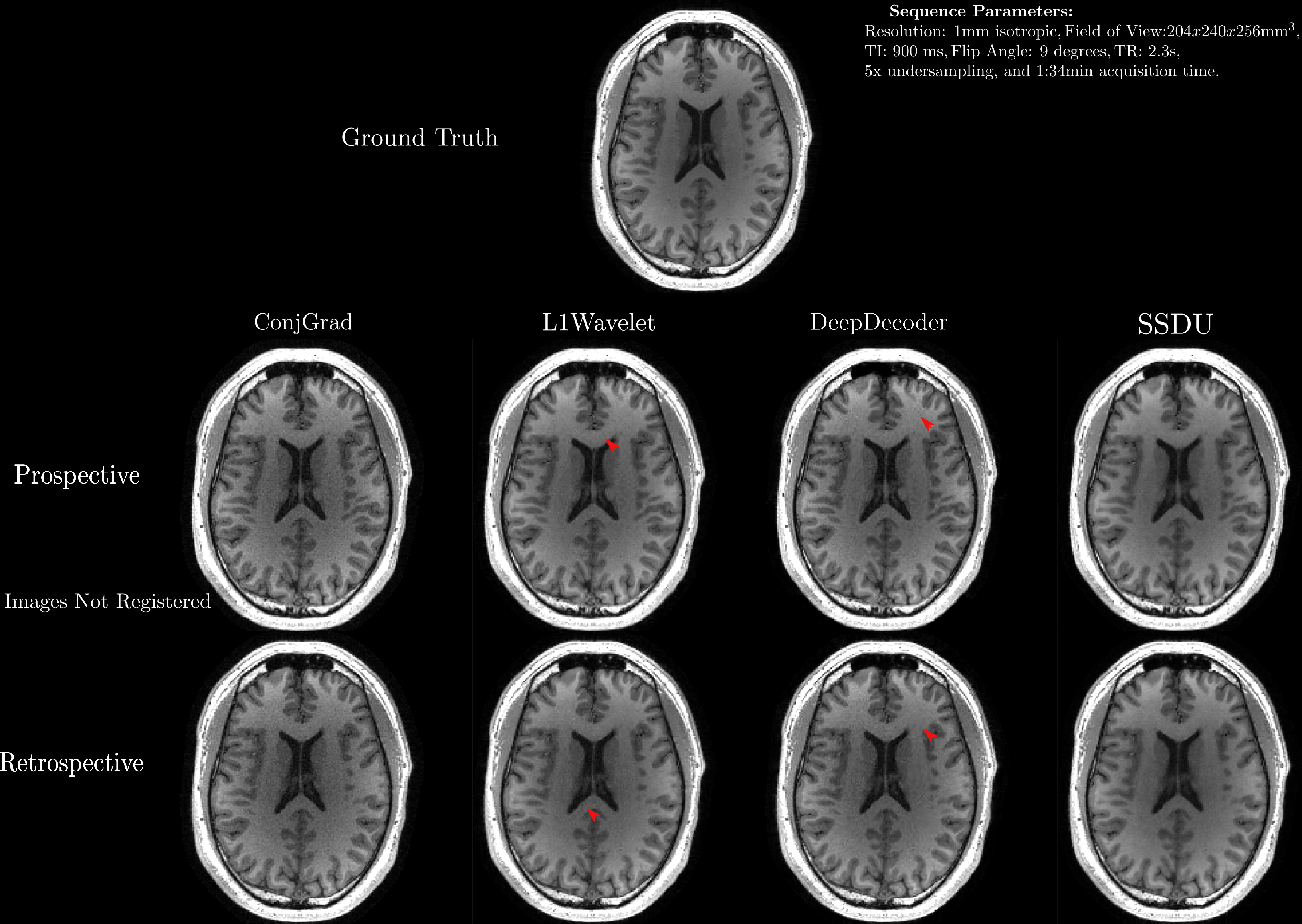
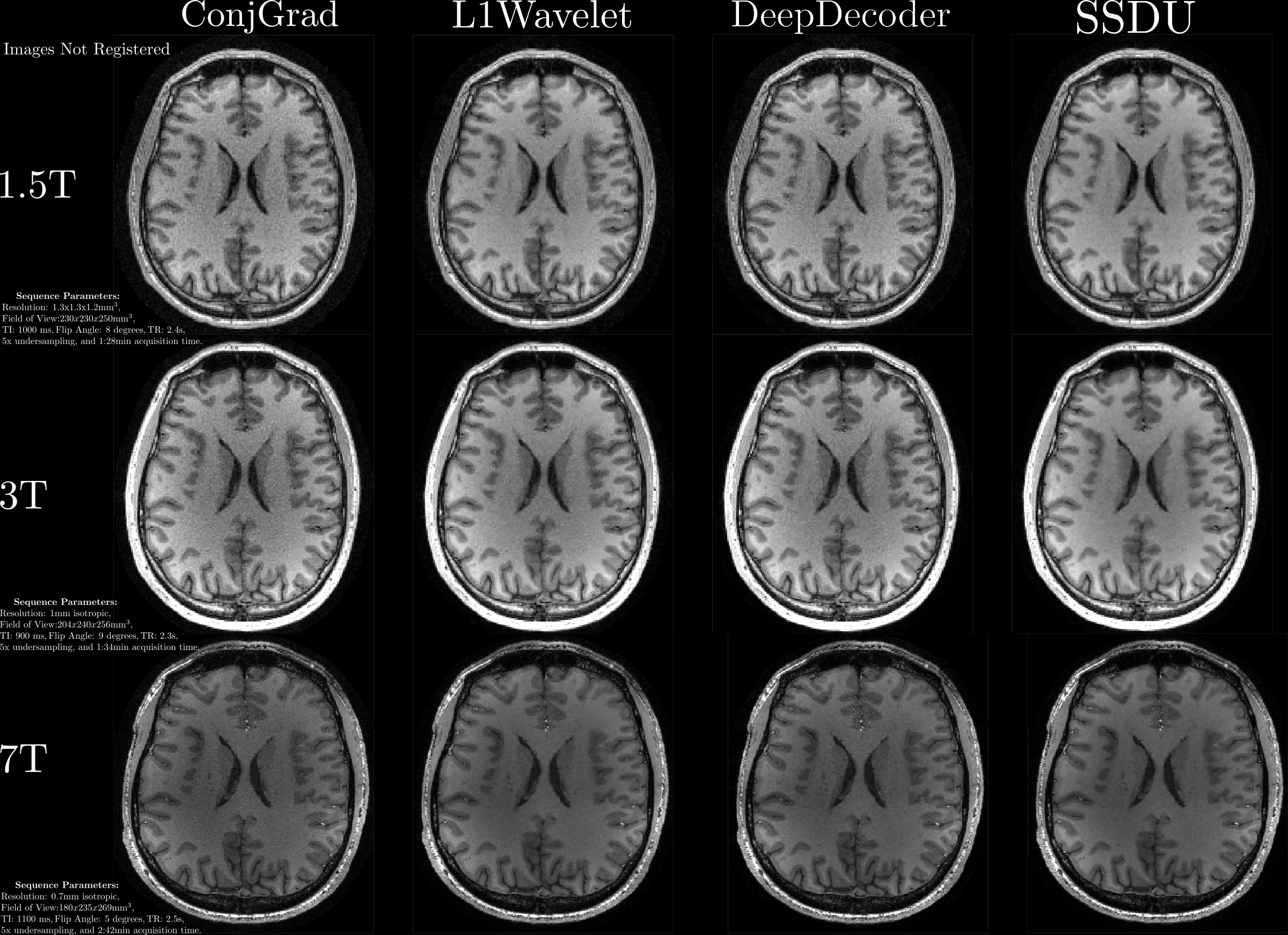
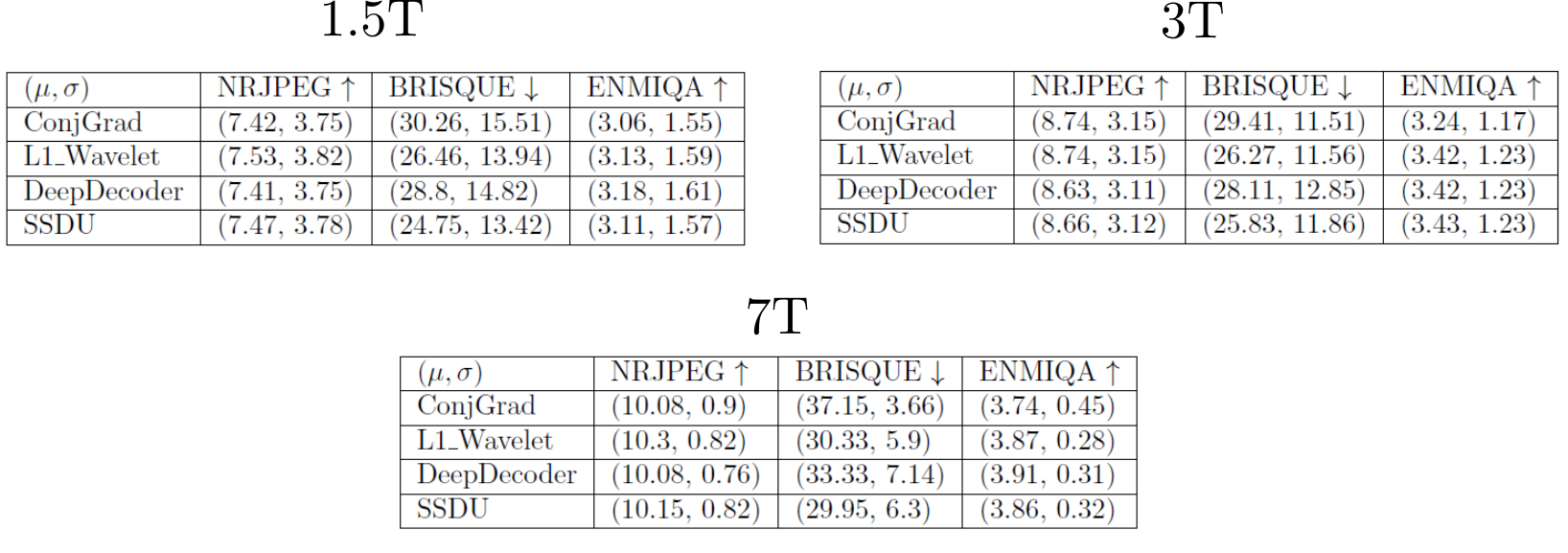
For validation, we acquired both fully sampled and 5x accelerated data of a multi-purpose phantom and one healthy subject using the same sequence parameters as in the training dataset. Thus, we quantitatively and qualitatively compare the results of the prospective reconstructions to the ground truth, as well as analyzing differences between prospective and retrospective reconstructions. To test generalizability, we acquired data from three healthy subjects at 1.5T, 3T and 7T (MAGNETOM Sola, Vida, and Terra, Siemens Healthcare, Erlangen, Germany) using a 1Tx/20Rx, 1Tx/64Rx, and 8pTx/32Rx (Nova Medical, Wilmington, MA, USA) head coil, respectively(see Figure 4 for sequence parameters). Reconstructed images were quantitatively evaluated using three no-reference image quality metrics (NRJPEG9, BRISQUE10, ENMIQA11) previously used in MR image quality studies11-13.
Results/Discussion
In Figures 2-5, we show the results of our experiments. In general, ConjGrad produces noisy but sharp images as expected. DeepDecoder produces smoother reconstructions with spatially varying noise behavior and sharpness(e.g., Figure 2-3). L1Wavelet and SSDU produce similar images, smoother than those of ConjGrad with comparable sharpness; however, L1Wavelet exhibits more artifacts(e.g., Figure 2-3). From Figures 2-3, we can see that image quality of retrospective reconstructions is better or comparable to prospective reconstructions; in particular, small features can be distorted in prospective reconstructions, potentially due to different gradient patterns used in the sequence. Quantitatively, the prospective/retrospective reconstructions of DeepDecoder have the highest fidelity to the ground truth (in terms of PSNR or SSIM); however, qualitatively, it has more spatially varying oversmoothing than those of L1Wavelet and SSDU. From Figure 4, the pattern of qualitative image quality of the methods mirrors that of Figures 2-3. However, the no-reference image quality metrics (see Table 1), while clearly ranking ConjGrad below L1Wavelet/DeepDecoder/SSDU, cannot distinguish between the latter group, with different metrics favoring different methods. NRJPEG detects increasing image quality from 1.5T-7T, in contrast to the other metrics. Qualitatively, all methods generalize well to different field strengths.Conclusion
Care should be taken when interpreting results in the literature from retrospective experiments; quantitative and perceptual fidelity to ground truth can be much greater than results from prospective reconstructions. In addition, the results further support that using PSNR and SSIM can be misleading for ranking the image quality of image reconstructions. No-reference image quality metrics can be used to quantitatively separate baseline quality reconstructions from others without ground truth; however, they are ambiguous beyond this.Acknowledgements
This project is supported by the European Union’s Horizon 2020 research and innovation program under the Marie Sklodowska-Curie project TRABIT (agreement No 765148).References
1. Yaman, Burhaneddin, Seyed Amir Hossein Hosseini, Steen Moeller, Jutta Ellermann, Kâmil Uğurbil, and Mehmet Akçakaya. "Self‐supervised learning of physics‐guided reconstruction neural networks without fully sampled reference data." Magnetic resonance in medicine 84, no. 6 (2020): 3172-3191.
2. Liu, Jiaming, Yu Sun, Cihat Eldeniz, Weijie Gan, Hongyu An, and Ulugbek S. Kamilov. "Rare: Image reconstruction using deep priors learned without groundtruth." IEEE Journal of Selected Topics in Signal Processing 14, no. 6 (2020): 1088-1099.
3. Heckel, Reinhard, and Paul Hand. "Deep decoder: Concise image representations from untrained non-convolutional networks." arXiv preprint arXiv:1810.03982 (2018).
4. K. Epperson, A. M. Sawyer, M. Lustig, M. T. Alley, M. Uecker, P. Virtue, P. Lai A, Vasanawala SS. Creation of Fully Sampled MR Data Repository for Compressed Sensing of the Knee. In: SMRT 22nd Annual Meeting. Salt Lake City, Utah, USA; 2013.
5. Knoll, Florian, Jure Zbontar, Anuroop Sriram, Matthew J. Muckley, Mary Bruno, Aaron Defazio, Marc Parente et al. "fastMRI: A publicly available raw k-space and DICOM dataset of knee images for accelerated MR image reconstruction using machine learning." Radiology: Artificial Intelligence 2, no. 1 (2020): e190007.
6. http://brain-development.org/ixi-dataset/
7. Muckley, Matthew J., Bruno Riemenschneider, Alireza Radmanesh, Sunwoo Kim, Geunu Jeong, Jingyu Ko, Yohan Jun et al. "Results of the 2020 fastmri challenge for machine learning mr image reconstruction." IEEE transactions on medical imaging 40, no. 9 (2021): 2306-2317.
8. Mussard, Emilie, et al. "Accelerated MP2RAGE imaging using Cartesian phyllotaxis readout and compressed sensing reconstruction." Magnetic resonance in medicine 84.4 (2020): 1881-1894.
9. Wang, Zhou, Hamid R. Sheikh, and Alan C. Bovik. "No-reference perceptual quality assessment of JPEG compressed images." In Proceedings. International Conference on Image Processing, vol. 1, pp. I-I. IEEE, 2002.
10. Mittal, Anish, Anush K. Moorthy, and Alan C. Bovik. "Blind/referenceless image spatial quality evaluator." In 2011 conference record of the forty fifth asilomar conference on signals, systems and computers (ASILOMAR), pp. 723-727. IEEE, 2011.
11. Obuchowicz, Rafał, Mariusz Oszust, Marzena Bielecka, Andrzej Bielecki, and Adam Piórkowski. "Magnetic resonance image quality assessment by using non-maximum suppression and entropy analysis." Entropy 22, no. 2 (2020): 220
12. Woodard, Jeffrey P., and Monica P. Carley-Spencer. "No-reference image quality metrics for structural MRI." Neuroinformatics 4, no. 3 (2006): 243-262.
13. Zhang, Zhicheng, Guangzhe Dai, Xiaokun Liang, Shaode Yu, Leida Li, and Yaoqin Xie. "Can signal-to-noise ratio perform as a baseline indicator for medical image quality assessment." IEEE Access 6 (2018): 11534-11543.
14. Lustig, Michael, David Donoho, and John M. Pauly. "Sparse MRI: The application of compressed sensing for rapid MR imaging." Magnetic Resonance in Medicine: An Official Journal of the International Society for Magnetic Resonance in Medicine 58, no. 6 (2007): 1182-1195.
15.Ulyanov, Dmitry, Andrea Vedaldi, and Victor Lempitsky. "Deep image prior." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 9446-9454. 2018.
16. Heckel, Reinhard, and Mahdi Soltanolkotabi. "Compressive sensing with un-trained neural networks: Gradient descent finds a smooth approximation." In International Conference on Machine Learning, pp. 4149-4158. PMLR, 2020.
17. Batson, Joshua, and Loic Royer. "Noise2self: Blind denoising by self-supervision." In International Conference on Machine Learning, pp. 524-533. PMLR, 2019.
18. He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep residual learning for image recognition." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770-778. 2016.
19. Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. "U-net: Convolutional networks for biomedical image segmentation." In International Conference on Medical image computing and computer-assisted intervention, pp. 234-241. Springer, Cham, 2015.
20. Paszke, Adam, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen et al. "Pytorch: An imperative style, high-performance deep learning library." Advances in neural information processing systems 32 (2019): 8026-8037.
21. Ong, Frank, and Michael Lustig. "SigPy: a python package for high performance iterative reconstruction." Proceedings of the International Society of Magnetic Resonance in Medicine, Montréal, QC 4819 (2019).
22. Uecker, Martin, Peng Lai, Mark J. Murphy, Patrick Virtue, Michael Elad, John M. Pauly, Shreyas S. Vasanawala, and Michael Lustig. "ESPIRiT—an eigenvalue approach to autocalibrating parallel MRI: where SENSE meets GRAPPA." Magnetic resonance in medicine 71, no. 3 (2014): 990-1001.
Figures