0150
Deep Learning for Triage of Normal Breast MRI Exams to an Abbreviated Interpretation Worklist1Department of Radiology, Memorial Sloan Kettering Cancer Center, New York, NY, United States
Synopsis
In this abstract, we develop and evaluate a deep learning model to identify completely normal screening breast MRIs for triage to an abbreviated interpretation worklist, a workflow that misses no cancers and markedly reduces radiologist interpretation times. In our held out test set, the algorithm triaged 20% of all screening exams to the abbreviated worklist and 80% to full interpretation worklist for radiologist without missing any cancer exams (100% sensitivity), which reduced the total projected reading time for exams from 148 hours to 119 hours.
INTRODUCTION:
Contrast-enhanced breast MRI is the most sensitive tool we have for breast cancer detection in high-risk patients1. While over 80% of breast MRI exams are negative/benign requiring no further workup and over 98% of exams are ultimately found to be cancer-free after additional workup2, the interpretation of these exams can be time-consuming, averaging ~6 minutes3. Herein we develop an artificial intelligence tool to identify negative screening exams for triage to an “abbreviated interpretation worklist.” We calculate the time savings of this AI tool and compare its performance to readers.MATERIALS AND METHODS:
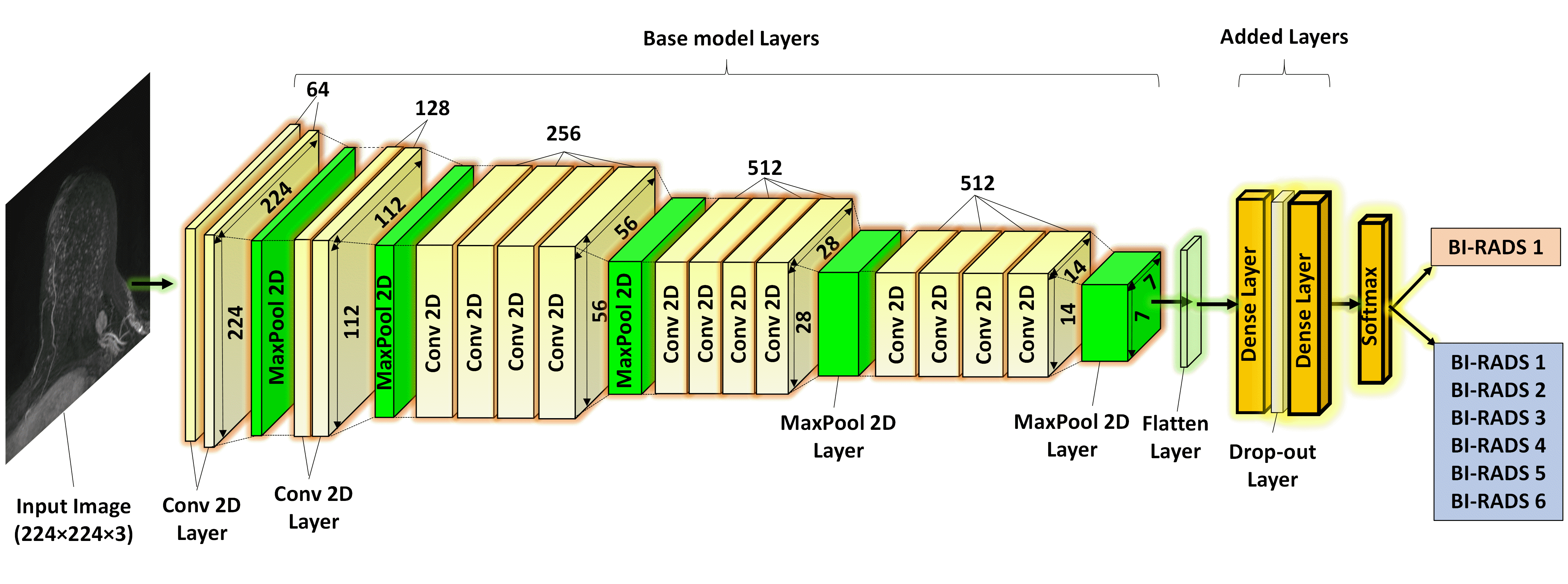
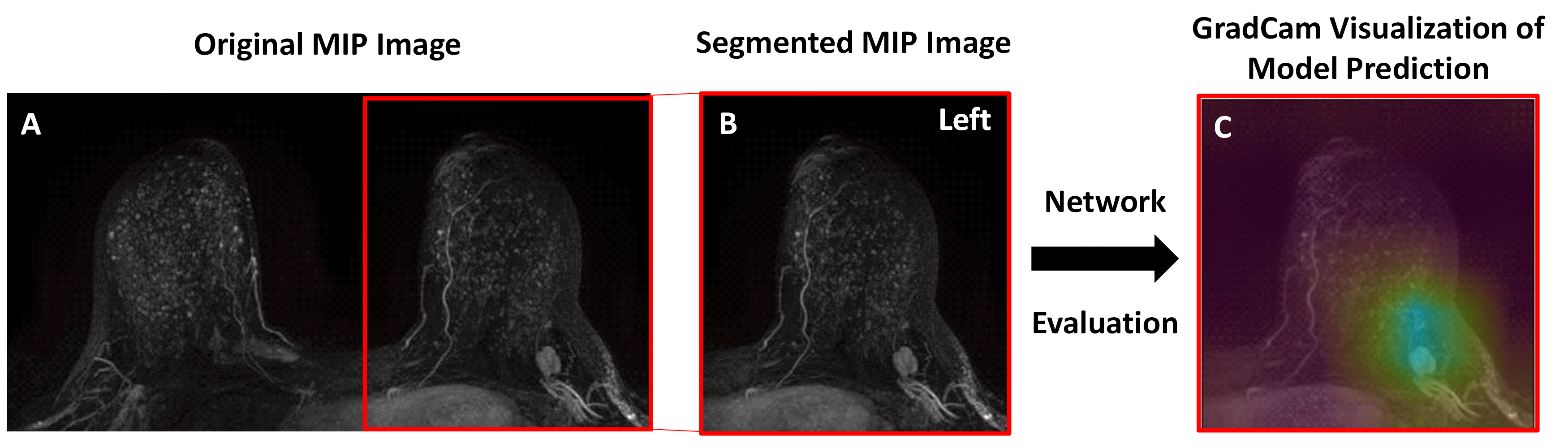
In this IRB-approved HIPPA compliant retrospective study, consecutive contrast-enhanced axial breast MRs performed at our institution from January 2013-January 2019 were included. All exams were performed on a 1.5 or 3.0 Tesla system (Discovery 750, GE Medical Systems, Waukesha, WI) using an 8- or 16- channel breast coil and a gadolinium-based contrast agent. Axial subtraction maximum intensity projections (MIPs) were calculated from the pre- and 1st post-contrast fat-saturated T1-weighted images and were segmented into left and right breast sub-images using a fully automated in-house algorithm. The entire cohort was randomly divided by patient into 80% training, 10% validation, and 10% testing sets. Only screening exams were included in the testing set. To predict normal exams, a binary classification deep learning (DL) model was developed. Breast MR exams were labeled as negative (BIRADS 1) or positive (BIRADS 2/3/4/5/6) based on the radiology report. An end-to-end model using a VGG19 architecture (Figure 1) was developed in Python with Keras API and TensorFlow backend using an NVIDIA-GTX-1080ti GPU. Initial training was performed using BIRADS 1 and BIRADS 6 cases and then fine-tuned with BIRADS 2/3/4/5. Optimal hyperparameters were: batch size=10, learning rate=1e-4, dense layer drop-rate = 0.75, epochs = 25, and number of frozen layers = 0. The validation set was used to determine the classifier threshold corresponding to 100% sensitivity for cancer detection. The held-out test set was then evaluated using this threshold. Cancer cases were defined as cases where invasive or in situ disease was diagnosed within 1 year of the MRI exam. Using this pathology reference standard, model performance on the test set was evaluated. The time savings of the AI algorithm was calculated assuming 6 minute interpretation time for the full MR protocol3 and a 3 second interpretation time for the abbreviated interpretation protocol (i.e. the radiologist looks at the 2D MIP image alone, as described in Kuhl, et al4). Gradient-weighted Class Activation Mapping (Grad-CAM) was used to identify where on the image the model was “looking” (Figure 2).Fifty cases (16% cancer, 84% not cancer) were randomly selected from the test set for a reader study. Two readers independently evaluated each breast MR and gave it a “negative” or “positive/suspicious” label. Performance was compared to the AI model.
RESULTS:
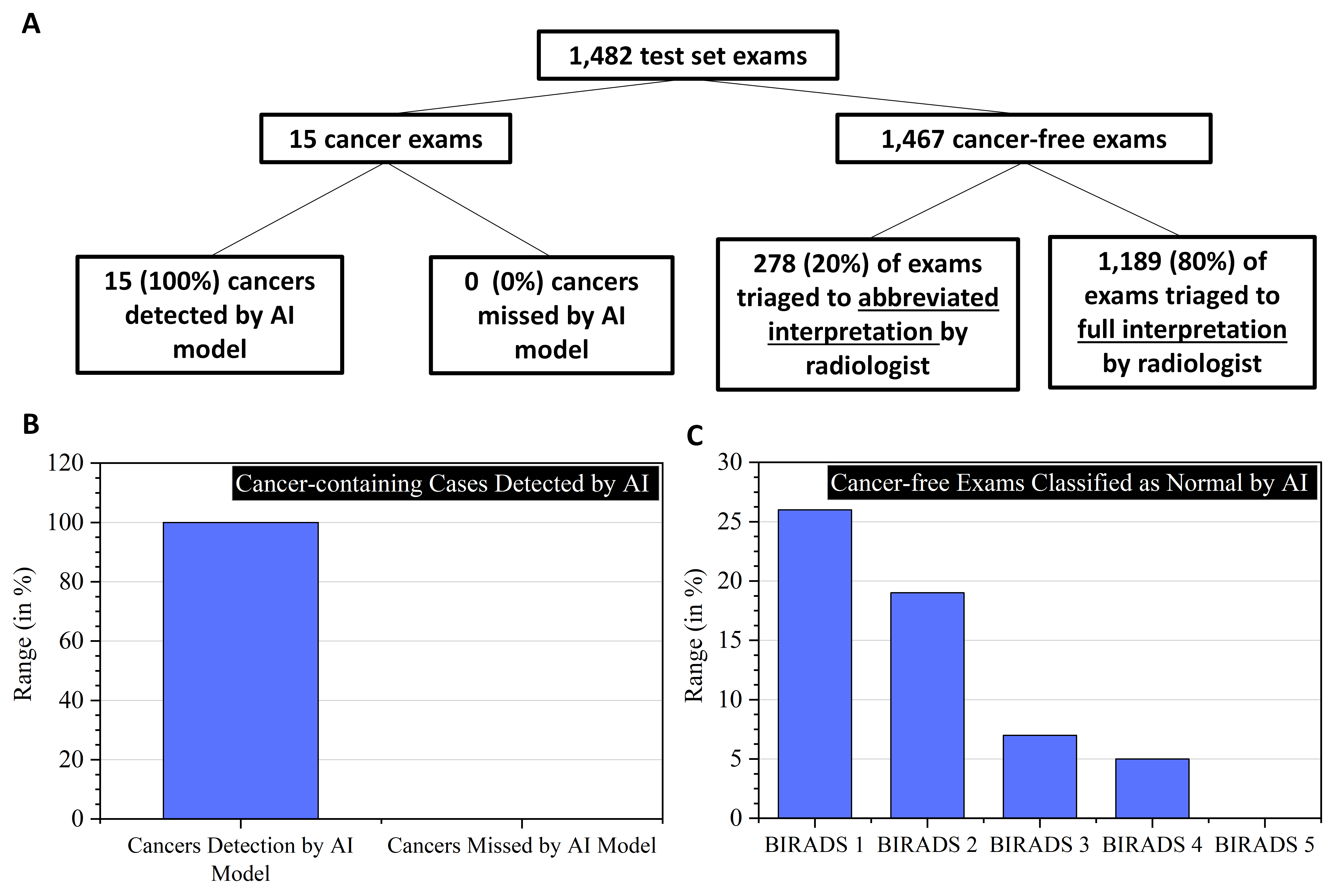
This study included 16,020 breast MR exams in 8,330 patients, with 12,911 training exams, 1,627 validation exams, and 1,482 test set exams (mean age 52 +/- 11). In the held-out test set, there were 15 exams with cancer and 1,467 exams that were cancer-free. The AI model correctly flagged all 15 cancer cases and did not miss any cancers. Of the cancer-free exams, the AI model triaged 293/1482 (20%) of all screening exams to abbreviated interpretation by a radiologist, including 88/344 (26%) BIRADS 1 exams, 197/1014 (19%) BIRADS 2 exams, 7/103 (7%) BIRADS 3 exams, 1/19 (5%) BIRADS 4 exams and 0/2 (0%) BIRADS 5 exams (see Figure 3). The AI model triaged 1189/1482 (80%) of cases to full interpretation by a radiologist. This led the projected total reading time to decrease by 20% across all screening cases (148 hours to 119 hours).Of the 50 cases in the reader study subset, there were 8 with cancer and 42 that were cancer-free. There were 11 BIRADS 1 exams and 39 BIRADS 2/3/4/5 exams. The AI model and both readers detected all 8 cancers and did not miss any cancers. Of the 42 cases without cancer, the model triaged 9 cases (21%) to abbreviated interpretation and 33 (79%) to full interpretation whereas both readers dismissed 39 cases (93%) and flagged 3 cases (7%) for unnecessary biopsy.
DISCUSSION:
We have developed a deep learning classification model that identifies a subset of negative breast MR exams for triage to an abbreviated interpretation worklist, resulting in a 20 percent reduction in interpretation time across all screening exams. Abbreviated interpretation using the MIP alone takes only ~3 seconds and has a negative predictive value of 99.8%4. This proposed workflow leverages the power of AI for significant time savings in a way that is safe and responsible to our patients (i.e. radiologists still look at all cases, albeit briefly). A similar AI tool has been developed for elimination of breast MRs from the worklist, but with a smaller dataset that required k-fold cross-validation, and for women with dense breasts rather than for a high-risk screening population, and without any time-saving analysis5.CONCLUSION:
Our fully automated end-to-end DL model detected all cancers in the 1,482 exam test set and triaged 20% of all screening cases to an abbreviated interpretation worklist, resulting in substantial time savings for the interpreting radiologist.Acknowledgements
The computation for this study was performed on the Lilac cluster hosted by the Sloan Kettering Institute, New York. This study is supported in part through the NIH/NCI Cancer Center Support Grant P30 CA008748.References
1. D’Orsi CJ SE, Mendelson EB, Morris EA. ACR BI-RADS® Atlas, Breast Imaging Reporting and Data System. Reston, VA: American College of Radiology; 2013.
2. Lee JM, Ichikawa L, Valencia E, et al. Performance Benchmarks for Screening Breast MR Imaging in Community Practice. Radiology. 2017;285(1):44-52.
3. Harvey SC, Di Carlo PA, Lee B, et al. An Abbreviated Protocol for High-Risk Screening Breast MRI Saves Time and Resources. J Am Coll Radiol. 2016;13(11s):R74-R80.
4. Kuhl CK, Schrading S, Strobel K, et al. Abbreviated breast magnetic resonance imaging (MRI): first postcontrast subtracted images and maximum-intensity projection-a novel approach to breast cancer screening with MRI. J Clin Oncol. 2014;32(22):2304-10.
5. Verburg E, van Gils CH, van der Velden BHM, et al. Deep Learning for Automated Triaging of 4581 Breast MRI Examinations from the DENSE Trial. Radiology. 2021:203960.
Figures