0102
Joint Generation of Multi-contrast Magnetic Resonance Images and Segmentation Map Using StyleGAN2-based Generative Network1Electrical and Electronic Engineering, Yonsei university, Seoul, Korea, Republic of
Synopsis
Training deep neural networks for medical imaging commonly requires large image datasets and paired label datasets. However, in the medical imaging research field, labeling costs are very expensive. To overcome this issue, we propose a data generation method which is StyleGAN2-based architecture that jointly generates multi-contrast magnetic resonance (MR) images and segmentation maps. The effectiveness of our generation model is validated in terms of segmentation performance for tumors. We demonstrate that the segmentation model only trained with the fake data generated from our method achieves comparable performance to that trained with real data.
Introduction
Training of deep neural networks for medical imaging commonly requires large image datasets and paired label datasets. However, in the medical imaging research field, labeling costs are very expensive, and the data are rarely shared publicly unlike computer vision research field6. Because it is frequent that the training datasets lack, data augmentation is often exploited to improve the performance of the model. However, conventional data augmentation schemes such as flipping and rotation cannot generate new images with different tissue structures, having limitations in improving the accuracy of predictions considerably. Although Generative Adversarial Network (GAN)-based methods which generate realistic images within data distribution of the training samples were introduced, a generation method that generates both images and label data including segmentation map has not yet appeared. In this paper, we propose a StyleGAN25-based architecture for jointly generating reliable multi-contrast magnetic resonance (MR) images and segmentation maps without severe distortion of pathological information. Because multi-contrast MR images and segmentation maps are highly correlated, the model is trained to generate the paired images/segmentation maps simultaneously. Through consecutive experiments for the tumor segmentation task on the BraTS181-3 dataset, we validate the effectiveness of our generative model in terms of data generation (or augmentation). Especially, the segmentation model only trained with the fake data which are generated from our method achieves comparable performance to that trained with the real data.Method
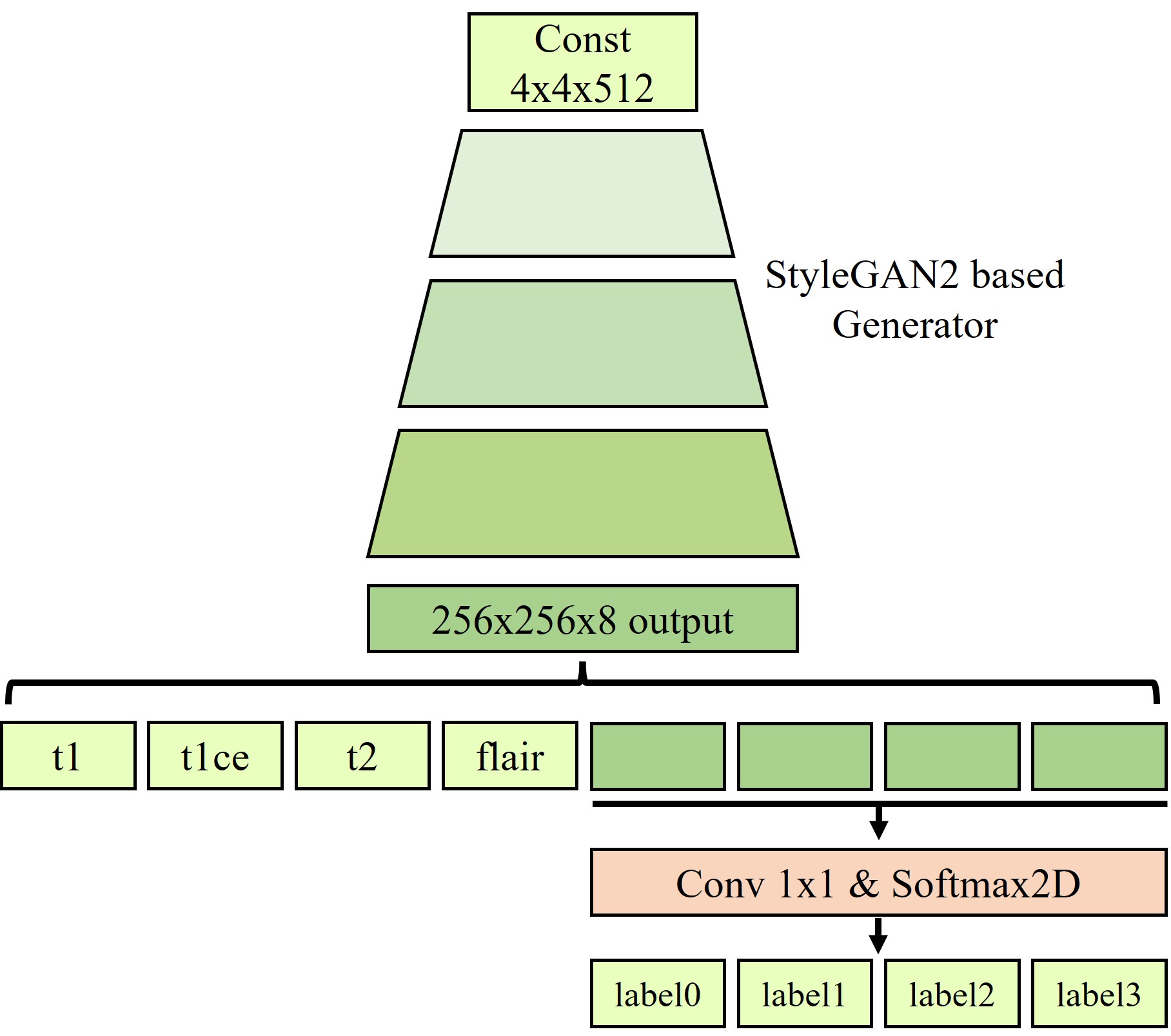
Our StyleGAN2-based joint generative model is trained to learn the joint distribution among multi-contrast images and segmentation maps. The overall architecture is presented in Fig. 1. We build our generative architecture on the top of StyleGAN2. As shown in Fig. 1, the modified generator has the output image size of 8x256x256(i.e., # of contrasts x image height x image width), and 1x1 convolution and softmax layer were added to generate segmentation map. The four contrast images including T1, contrast-enhanced T1 (i.e., T1-CE), T2, FLAIR, and segmentation maps are combined into multichannel images to generate the multi-contrast images and segmentation maps simultaneously. All other settings, including optimizers, losses, training settings, and other hyperparameters are kept unchanged except that horizontal flips are used as augmentations. After the training of the generator is finished, new datasets are generated from the trained generator. From random vectors following a normal distribution, the generator creates data that are not attributed to real patients.Experiments
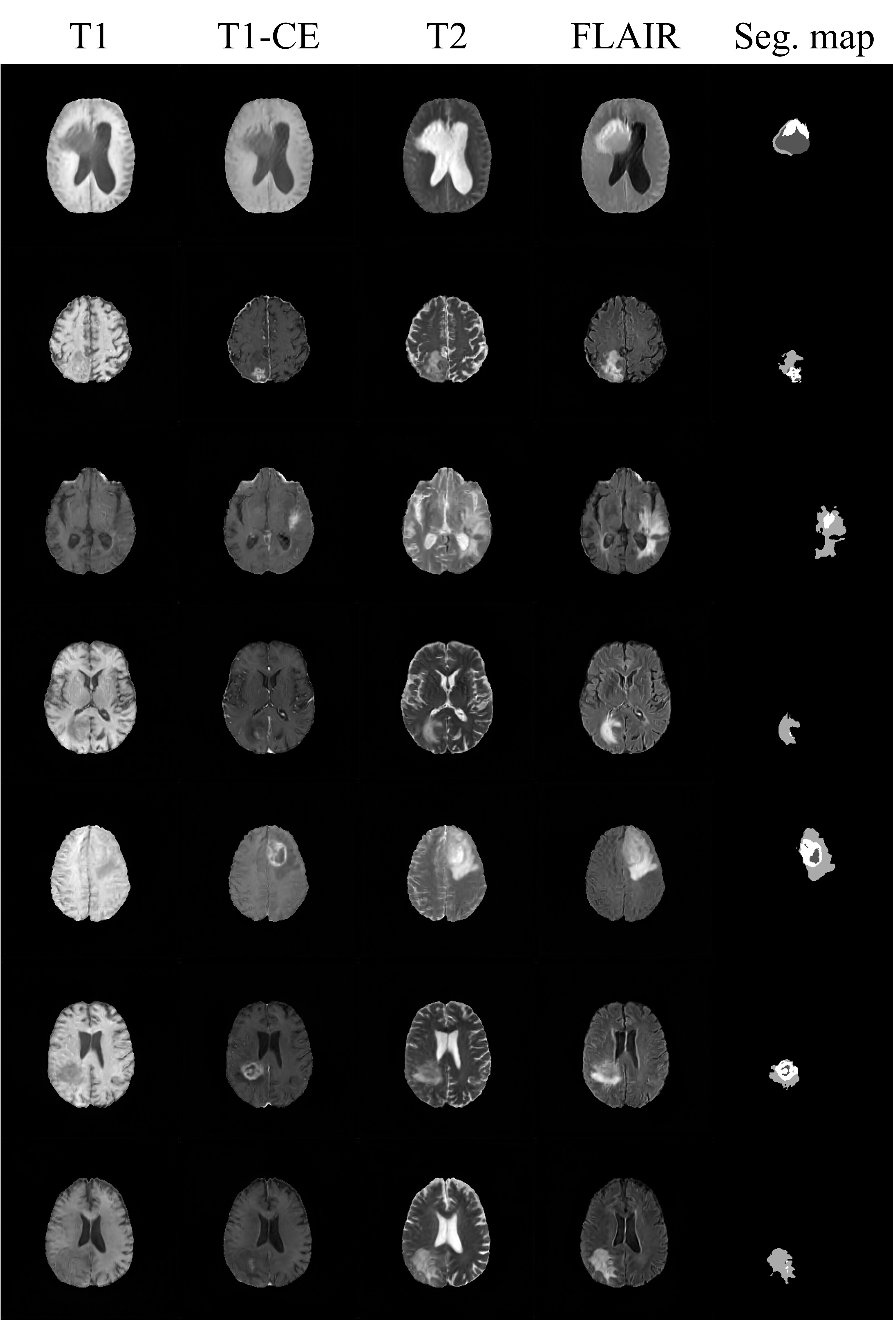
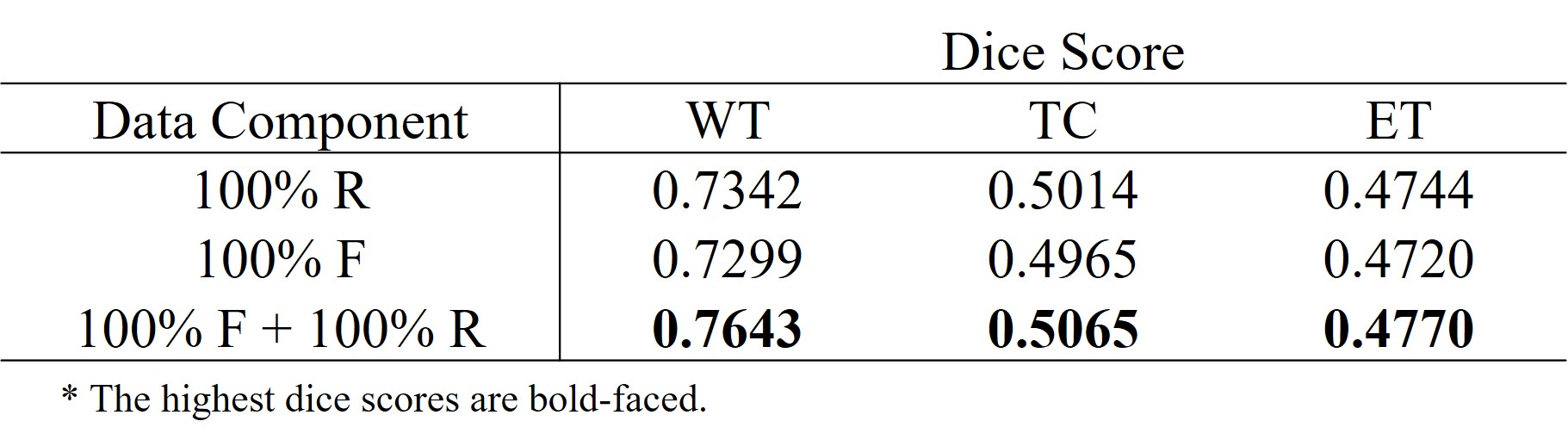
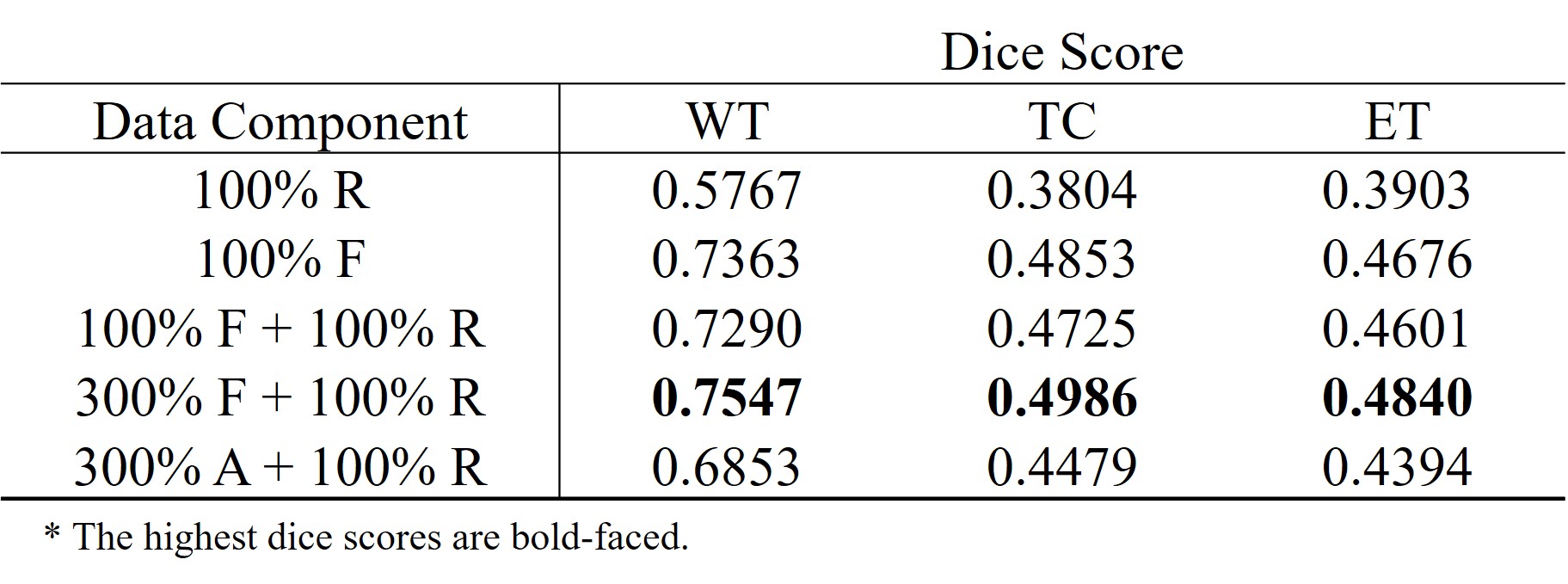
We used the BraTS18 dataset comprising of four types of contrast (i.e., T1, T1-CE, T2, and FLAIR) and corresponding segmentation maps. Tumors are labeled in three parts including necrosis/non-enhancing tumor (label_1), edema (label_2), and active/enhancing tumor (label_3), and the remaining background regions are labeled to label_0. There are 210 patient datasets, and we use 90% (199 patients) for training and 10% (21 patients) for testing. The effectiveness of our generative model was validated by the tumor segmentation task. The dataset containing the four contrasts is used to train U-Net4. Dice score was used to validate the segmentation performance. Table 1 and 2 show the segmentation results trained on different datasets. All results are obtained from the test set (21 patients). As shown in Table 1, the segmentation performance from the pure fake dataset (100% F) is comparable to that from the real dataset with the same size (100% R). Moreover, when the fake images were exploited for data augmentation (100% F + 100% R), dice scores are significantly improved. These results suggest that the generated fake data have a very similar data distribution with the real data. In Table 2, the effectiveness of the proposed method in terms of data augmentation is demonstrated when the real training dataset is small (only 1000 slices). There are six settings of the training set respectively as: (1) 100% real data (100% R), (2) 100% fake data (100% F), (3) mix of 100% fake data and 100% real data (100% F + 100% R), (4) mix of 300% fake data and 100% real data (300% F + 100% R), and (5) mix of 300% augmented data with flipping and 100% real data (300% A + 100% R). It is surprising that segmentation performance from even pure fake datasets shows better results than that from the real ones. The mix of 300% fake images and 100% real images shows the best results.Conclusion
We propose a StyleGAN2-based architecture that jointly generates multi-contrast magnetic resonance (MR) images and segmentation maps. The effectiveness of our generation model is validated in terms of segmentation performance trained on U-net. The segmentation model only trained with the fake data generated from our method achieves comparable performance to that trained with real data.Acknowledgements
This research was supported by Basic Science Research Program through the NationalResearch Foundation of Korea (NRF) funded by the Ministry of Science andICT, (2019R1A2B5B01070488, 2021R1A4A1031437, 2021R1C1C2008773 and 2022R1A2C2008983), and Y-BASE R&E Institute a Brain Korea 21, YonseiUniversity.
References
1. MENZE, Bjoern H., et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE transactions on medical imaging, 2014, 34.10: 1993-2024.
2. BAKAS, Spyridon, et al. Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Scientific data, 2017, 4.1: 1-13.
3. BAKAS, Spyridon, et al. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv preprint arXiv:1811.02629, 2018.
4. RONNEBERGER, Olaf; FISCHER, Philipp; BROX, Thomas. U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015. p. 234-241.
5. KARRAS, Tero, et al. Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. p. 8110-8119.
6. SUN, Yi; YUAN, Peisen; SUN, Yuming. MM-GAN: 3D MRI Data Augmentation for Medical Image Segmentation via Generative Adversarial Networks. In: 2020 IEEE International Conference on Knowledge Graph (ICKG). IEEE, 2020. p. 227-234.
Figures