4258
Deep learning based synthetic CT skull for transcranial MRgFUS interventions using 3D V-net–Transfer learning implications1Siemens Medical Solutions USA, Inc., Malvern, PA, United States, 2Department of Diagnostic Radiology and Nuclear Medicine, University of Maryland, School of Medicine, Baltimore, MD, United States, 3Center for Metabolic Imaging and Therapeutics (CMIT), University of Maryland Medical Center, Baltimore, MD, United States, 4Siemens Healthcare GmbH, Erlangen, Germany
Synopsis
Transcranial MRI-guided focused ultrasound (tcMRgFUS) is a promising technique for treating multiple diseases. It is desirable to simplify the clinical workflow of tcMRgFUS treatment planning. Previously, feasibility of leveraging deep learning to generate synthetic CT skull from ultra-short echo time (UTE) MRI has been demonstrated for tcMRgFUS planning. In this study, 3D V-Net was used for skull estimation, by taking advantage of 3D volumetric images. Furthermore, feasibility of applying pre-trained model in new dataset was studied, demonstrating the possibility of generalization across various sequences/protocols and scanners.
INTRODUCTION
Transcranial MRI-guided focused ultrasound (tcMRgFUS) is a promising novel technique for treating multiple disorders and diseases1-3. tcMRgFUS planning requires both a CT scan for skull density estimation and treatment planning simulation, and an MRI for target identification. It is desirable to simplify the clinical workflow of tcMRgFUS treatment planning. Previously, feasibility of leveraging deep learning to generate synthetic CT skull from ultra-short echo time (UTE) MRI has been demonstrated for tcMRgFUS planning4. However, the limitation of 2D U-Net5 is that it lacks contextual information during training, and can potentially lead to non-ideal estimation of the skull. The purpose of this study is first to leverage the 3D V-Net6 for skull estimation, by taking advantage of 3D volumetric images. Furthermore, transfer learning of the trained model on new dataset was studied to demonstrate the feasibility of applying the pre-trained model in dataset acquired using different MRI/CT sequence and protocols.METHODS
Image acquisition and data preprocessingThis study was approved by local IRB. Data was obtained from 42 subjects (65.7±11.5yo, 16F). MR images were acquired on a 3T system (MAGNETOM Trio, Siemens Healthcare, Erlangen, Germany). A prototype 3D radial UTE sequence7,8 was acquired: TE1/TE2=0.07ms/4ms, resolution=1.3x1.3x1.3mm3, TA=5min. CT images were acquired using a CT scanner (Brilliance 64, Philips, WA), resolution=0.48x0.48x1mm3. Both UTE and CT images were coregistered and resampled to MPRAGE space (resolution=1.0x1.0x1.0mm3). Preprocessing of UTE and CT images was described in Ref4.
3D V-Net
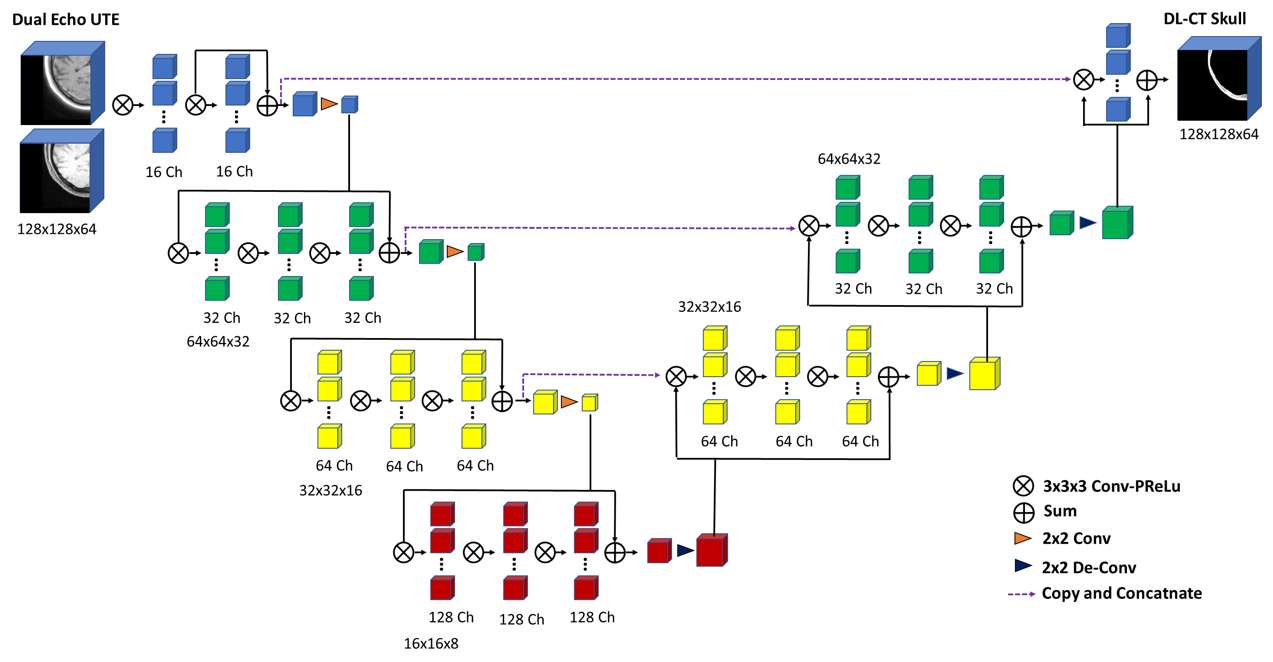
3D V-Net6 was initially proposed to perform volumetric segmentation in medical images by considering the whole volume content at once. A diagram of the model used in this study is illustrated in Figure 1. Dual-echo UTE images were used as input to the neural network, and reference CT skull images were used as the prediction target. UTE-CT image pairs from 30 subjects were used for training, 10 for validation of hyper-parameter tuning, and 2 for prospective testing. Network training was performed with Tensorflow: loss=Mean-Absolute-Error (MAE), ADAM, learning-rate=0.0001, PReLU activation, convolution filter size=3x3x3; sliding-window extraction of patches (size=192x192x64) was used for baseline training, and randomly centered patches extracted from training dataset were used for data augmentation.
Evaluation of model performance
Performance of this model was evaluated using the following four metrics to compare synthetic CT skull with reference CT skull: 1) dice-coefficient of skull masks; 2) voxel-wise correlation-coefficient; 3) average of voxel-wise absolute differences; and 4) skull-density-ratio (SDR)9,10 from 1024 locations.
Transfer learning for 0.8mm3 isotropic spiral UTE acquisition
The model trained above was based on a specific dual-echo radial UTE sequence with 1.3mm3 isotropic spatial resolution. It is desirable to have this trained model generalize to data acquired from different UTE sequences and protocols. To demonstrate the capability of transfer learning, data from two more subjects (20/37yo, F/M) scanned with a different prototype 3D UTE stack-of-spirals high resolution sequence11 on a different 3T MRI system (MAGNETOM Prisma Fit, Siemens Healthcare, Erlangen, Germany): spatial resolution=0.8x0.8x0.8mm3, TE1/TE2=0.05/3.10ms, TA=4:29min. CT images were also acquired using a different CT scanner (SOMATOM Force, Siemens Healthcare, Erlangen, Germany), spatial resolution=0.46x0.46x1mm3. Data from the first subject was used for retraining the V-Net; and data from the second subject was used for testing. For comparison, V-Net previously trained on 30 participants was directly applied to data from the second subject without any retraining.
RESULTS and DISCUSSION
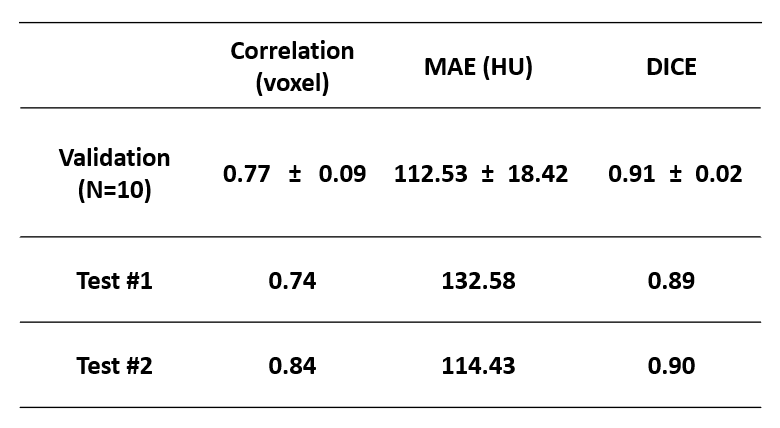
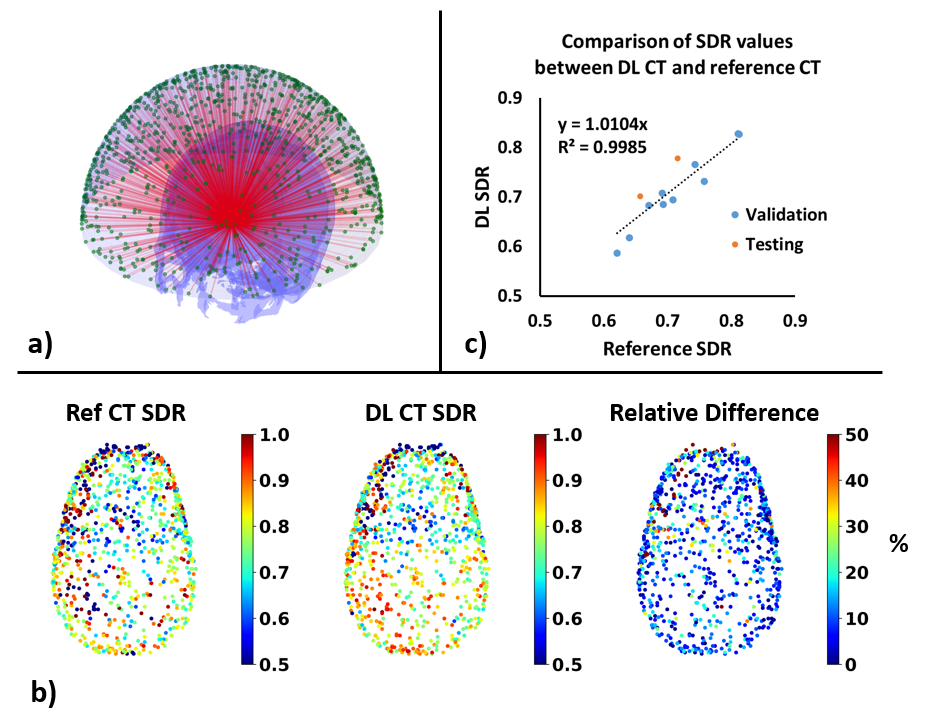
Figure 2 summarizes various metrics estimating the performance of the V-Net on 10 validation datasets and 2 prospective testing datasets. High spatial correlation, low mean-absolute-of-error, and high DICE score can be observed in the validation dataset. Two prospective testing datasets show comparable results to the validation datasets, suggesting that the model was not over-fitted to the training/validation data.Figure 3 demonstrates the skull-density-ratio results from synthetic CT skulls. Figure 3a shows the positions of 1024 transducers with respect to the skull from a prospective testing dataset. Figure 3b compares the regional SDR values between reference CT skull and synthetic CT skull: minimal spatial discrepancy can be observed between these two. Figure 3c shows the correlation between the global SDR values between the CT skull and the DL synthetic skull (R2=0.9985).
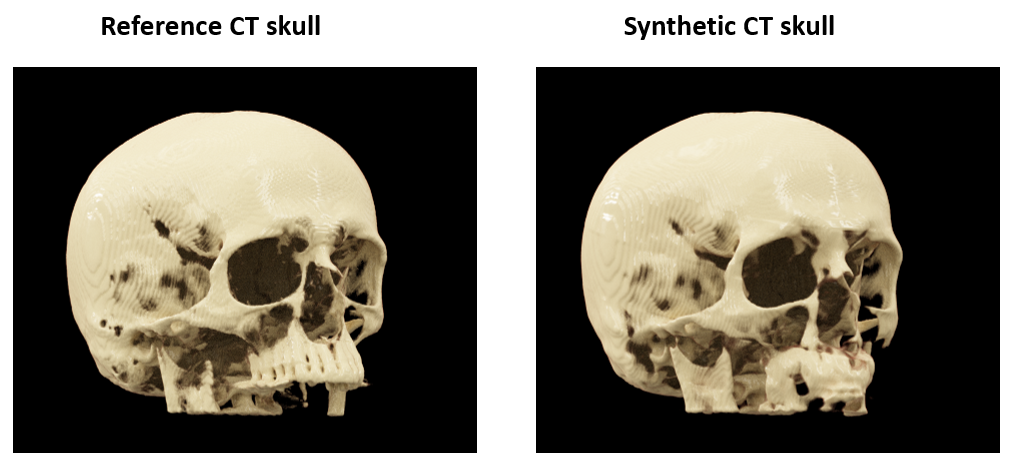
Figure 4 shows the 3D cinematic rendering of the reference CT skull and synthetic CT skull from a representative subject. The two renderings are very similar, except in the lower maxillary bone and teeth. This is likely due to lack of training as current study focuses on MRgFUS application.
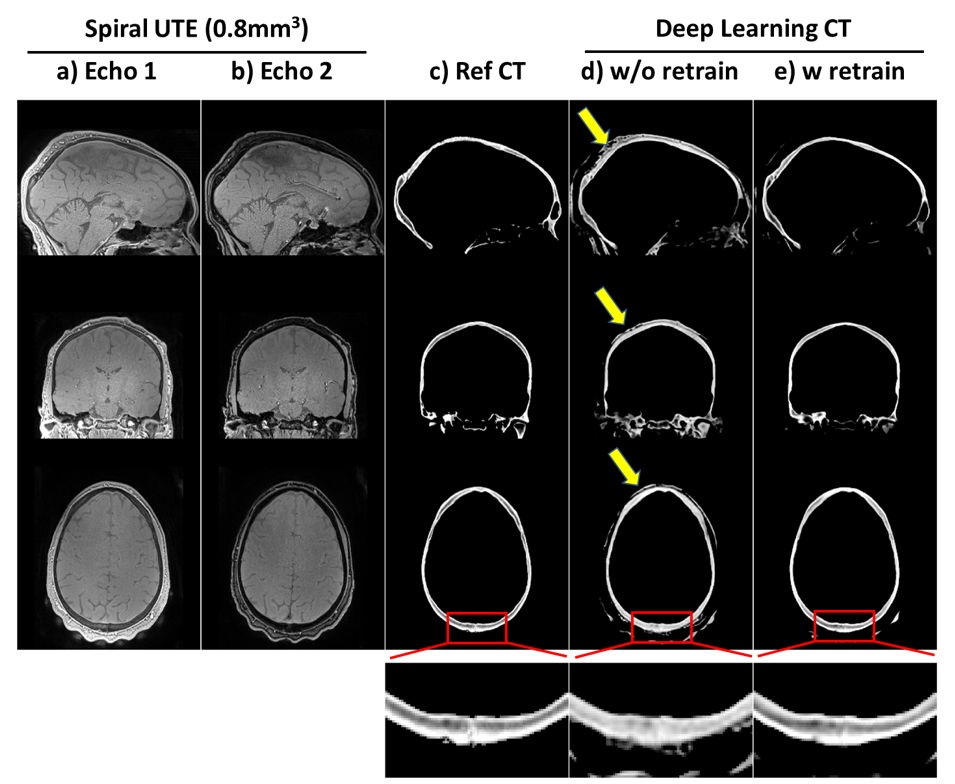
Figure 5 shows the results of applying the V-Net model (trained on radial UTE) to dual-echo high-spatial-resolution (0.8mm3 isotropic) spiral UTE data acquired on a different 3T scanner. Without any retraining, the model can approximately generalize to the new data it has never seen before (Figure 5d). However, some artifacts appear (yellow arrows), which are significantly reduced by retraining the model with a single high-spatial-resolution spiral UTE dataset (Figure 5e). Zoom-in window shows the improvement of retraining on delineation of fine details in the posterior skull.
CONCLUSION
Deep learning can be utilized to generate synthetic CT skull, thereby simplifying workflow of tcMRgFUS. 3D V-Net was utilized to take advantage of contextual information in volumetric images. Feasibility of applying pre-trained model in new dataset was studied, demonstrating the possibility of generalization across various sequences/protocols and scanners.Acknowledgements
No acknowledgement found.References
1. Elias WJ, Huss D, Voss T et al. A pilot study of focused ultrasound thalamotomy for essential tremor. N Engl J Med 2013;369:640-648.
2. Jeanmonod D, Werner B, Morel A, Michels L, Zadicario E, Schiff G, Martin E. Transcranial magnetic resonance imaging-guided focused ultrasound: noninvasive central lateral thalamotomy for chronic neuropathic pain. Neurosurg Focus 2012;32:E1.
3. Monteith S, Sheehan J, Medel R, Wintermark M, Eames M, Snell J, Kassell NF, Elias WJ. Potential intracranial applications of magnetic resonance-guided focused ultrasound surgery. J Neurosurg 2013;118:215-221.
4. Su P, Guo S, Roys F, Maier F, Bhat H, Melhem, ER, Gandhi D, Gullapalli R, Zhuo J. Transcranial MR Imaging–Guided Focused Ultrasound Interventions Using Deep Learning Synthesized CT. American Journal of Neuroradiology, 2020; 41(10), 1841-1848.
5. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention Cham, Switzerland: Springer; 2015;234–241.
6. Milletari F, Navab N, Ahmadi SA. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In2016 fourth international conference on 3D vision (3DV) 2016 Oct 25 (pp. 565-571). IEEE.
7. Speier P, Trautwein F. Robust radial imaging with predetermined isotropic gradient delay correction. Proc Int Soc Mag Reson Med 2006:2379.
8. Speier P, Trautwein F. A calibration for radial imaging with large inplane shifts. Proc Int Soc Mag Reson Med 2005:2295.
9. Boutet A, Gwun D, Gramer R, Ranjan M, Elias GJ, Tilden D, Huang Y, Li SX, Davidson B, Lu H, Tyrrell P. The relevance of skull density ratio in selecting candidates for transcranial MR-guided focused ultrasound. Journal of Neurosurgery. 2019 May 3;132(6):1785-91.
10. D’Souza M, Chen KS, Rosenberg J, Elias WJ, Eisenberg HM, Gwinn R, Taira T, Chang JW, Lipsman N, Krishna V, Igase K. Impact of skull density ratio on efficacy and safety of magnetic resonance–guided focused ultrasound treatment of essential tremor. Journal of Neurosurgery. 2019 Apr 26;132(5):1392-7.
11. Mugler JP, Fielden S, Meyer CH, Altes TA, Miller GW, Stemmer A, Pfeuffer J, Kiefer B. Breath-hold UTE Lung Imaging using a Stack-of-Spirals Acquisition. Proc Int Soc Mag Reson Med 2015:1476.
Figures