4175
Increasing three-dimensional coverage of dynamic speech magnetic resonance imaging1University of Illinois Urbana-Champaign, Champaign, IL, United States
Synopsis
We managed to increase the 3D coverage of dynamic speech magnetic resonance imaging to 32 slices with 96 mm full thickness, spatial resolution to 1.875×1.875×3mm and temporal resolution of 35 fps by applying sparsely sampling the temporal navigators with four k-space lines and and apply to a low-rank constraint Partial-Separability (PS) model for reconstruction. This enables visualization approaching isotropic resolution with the full vocal tract covered from side to side, enabling dynamic visualizations of complex motions that do not stay within a single imaging plane.
Introduction
Dynamic magnetic resonance imaging (MRI) has been widely used in the speech imaging field, especially for capturing articulatory changes in both structural and functional scales which provide opportunities to study swallowing activities, linguistics, and language variabilities. A better coverage of the vocal tract will provide more opportunities for comprehensive understanding of articulatory changes during speech, which includes complex motions outside of the typically acquired mid-sagittal plane. However, higher 3D coverage requires more coverage of k-space sampling which will raise the burden on both acquisition and reconstruction. Here, we explore the possibilities to increase 3D coverage to 96mm with 32 3-mm thickness slices. We achieve this by sparsely sampling the temporal navigator acquisition with multiple k-space lines and utilizing Partial-Separability (PS) based low-rank model for image reconstruction.Methods
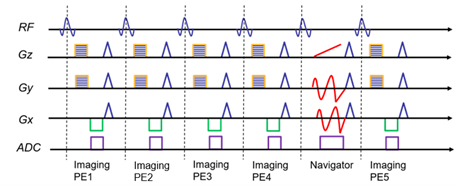
We implemented a spatially regularized partial separability (PS) model for constrainted reconstruction of the dynamic speech images.[1,2,3] The PS model assumes that strong spatiotemporal correlation exists and models the dynamic speech signal as a linear combination of a small set (low rank) of temporal and spatial basis functions. We sparsely sample two sets of (k, t)-space data in an interlaced manner: an imaging dataset (from which we estimated the spatial basis functions) and a temporal navigator dataset (which provides estimates of the temporal basis functions).1 Another novelty here is that we scanned multiple imaging lines per temporal navigator to reduce the overall scan time for acquiring model data at the expense of slightly reduced frame rate, as shown in Figure 1.Three-dimensional imaging requires significant time to fully sample all k-space, especially as the number of kz locations increases to provide more isotropic voxels. We acquired a 3D sagittal acquisition with a 128-matrix size with a 24 cm field of view and 32 kz-slices with 96 mm full thickness, for a spatial resolution of 1.875×1.875× 3mm. We also achieved a temporal resolution of 35 fps with 4 imaging lines acquired per navigator. This frame rate is still sufficiently high to visualize the articulatory motions during speech. Phase encoding in y- and z-directions were randomized. We performed 20 full-frame measurements for which the total duration of the scan was less than 10 minutes resulting in 20480 reconstructed images from the PS model at 35 frames per second.
Results
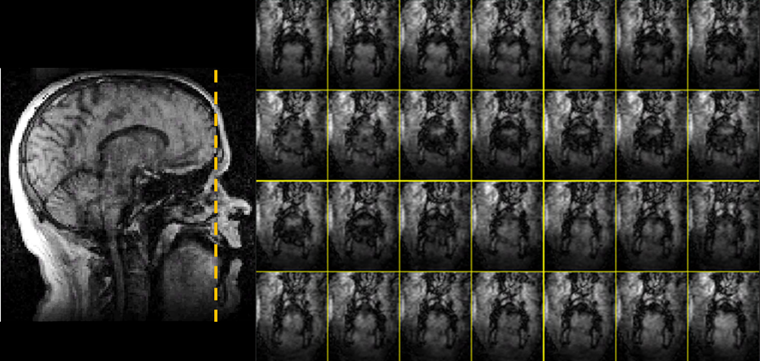
Figure 2 shows a temporal profile taken in 300 frames (about 8.6 seconds) along a vertical strip of mid-sagittal slice when the subject counting from one to four. Figure 3 shows coronal images of mid-tongue region in 28 frames (about 0.8s) of subject counting the number ‘Four’. Both figures show the motion of the tongue.The total acquisition time was about 10 minutes which is acceptable for large data demanding speech imaging. The memory requirements for reconstruction is about 60GB and the reconstruction took two weeks on an engineering workstation.
Discussion
The 96 mm thickness in 32-slices is currently the highest z-coverage in speech MRI. It can cover all the oral areas and lateral muscle for most of adults at nearly isotropic resolution. We can also utilize a spatial-temporal sparsity constraint or a deep learning prior to further improve the image quality in the future.Conclusion
By sparsly sampling (k,t)-space for acquisition of navigators and using a PS-based low-rank model for image reconstruction, we managed to increase the 3D coverage of dynamic speech MRI to 32 sices with 96 mm full thickness and spatial resolution to 1.875×1.875× 3mm and temporal resolution to 35 fps. This enables visualization that is approaching isotropic resolution with the full vocal tract covered from side to side, enabling dynamic visualizations of complex motions that do not stay within a single imaging plane.Acknowledgements
Research reported in this publication was supported by the National Institute Of Dental & Craniofacial Research of the National Institutes of Health under Award Number R01DE027989. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.References
1. Liang Z-P. Spatiotemporal imaging with partially separable functions. In Proceedings of IEEE International Symposium on Biomedical Imaging, Washington D.C., USA, 2007. pp. 988–991.
2. Fu, M. , Zhao, B. , Carignan, C. , Shosted, R. K., Perry, J. L., Kuehn, D. P., Liang, Z. and Sutton, B. P. (2015), High‐resolution dynamic speech imaging with joint low‐rank and sparsity constraints. Magn. Reson. Med., 73: 1820-1832. doi:10.1002/mrm.25302
3. Fu, M. , Barlaz, M. S., Holtrop, J. L., Perry, J. L., Kuehn, D. P., Shosted, R. K., Liang, Z. and Sutton, B. P. (2017), High‐frame‐rate full‐vocal‐tract 3D dynamic speech imaging. Magn. Reson. Med., 77: 1619-1629. doi:10.1002/mrm.26248
Figures