4055
MRI image synthesis with a conditional generative adversarial network using patch pooling
Bragi Sveinsson1,2 and Matthew S Rosen1,2,3
1Martinos Center, Massachusetts General Hospital, Boston, MA, United States, 2Harvard Medical School, Boston, MA, United States, 3Physics, Harvard University, Cambridge, MA, United States
1Martinos Center, Massachusetts General Hospital, Boston, MA, United States, 2Harvard Medical School, Boston, MA, United States, 3Physics, Harvard University, Cambridge, MA, United States
Synopsis
Deep learning networks allow the creation of new images based on a separate set of reference image data. This can be used to synthesize a specific MRI contrast from other image contrasts sharing the same anatomy. A particularly successful approach uses a conditional generative adversarial network with a patch-based discriminator, processing image patches of a fixed size. In this work, we investigate the benefits of using multiple patch sizes to improve image quality.
Introduction
The emergence of conditional generative adversarial networks (cGANs) has enabled the synthesis of a desired MRI contrast from different contrast types sharing the same anatomy1. This could potentially reduce the need to acquire the contrast through a dedicated scan and thus reduce scan time. In a successful approach, a patch-based discriminator examines if patches of the generated image are real or synthesized. In past work, a single patch size has been used. In this work, we investigate the benefits of using a combination of patches of several sizes and demonstrate a resulting improvement in image quality, both qualitatively and using quantitative error metrics.Methods
We obtained knee images from 4,600 subjects from the Osteoarthritis Initiative (OAI)2. The data set contained images from sagittal Double-Echo in Steady-State (DESS) scans, coronal Turbo Spin Echo (TSE) scans, and coronal Fast Low-Angle Shot (FLASH) scans, with the goal of synthesizing the FLASH images from the DESS and TSE images. The DESS and TSE images were resampled to have the same scan plane and resolution as the FLASH images. Each of the 3 sequences had a total of 123,000 images, which were split into training, validation, and testing datasets with the proportions 80%, 10%, and 10%.The DESS and TSE images were used as input channels to a cGAN3, based on the Pix2Pix approach4. However, instead of the discriminator examining patches of a single size (e.g., 70×70 pixels) in the resulting image, the discriminator looked at multiple patch sizes of 17×17, 33×33, 65×65, and 129×129 (Figure 1). This was achieved by applying 1, 2, 3, and 4 2-stride convolutional layers in the discriminator, respectively. The patches of the discriminator were designed to align, so that patch size N (say 33×33) would contain a 2×2 matrix of the size N-1 patches (say 17×17). Max pooling was then applied to the 2×2 matrix of the smaller patches, and the resulting value compared to the larger patch, and the maximum value of those two was kept for that region of the image. The process was then repeated again for the next patch size. This way, the discriminator was always sensitive to the patch size that performed the worst over any given region. This was performed over the whole image with a stride of 16 pixels.
This network was trained over 10 epochs, using a batch size of 6. Images were resampled to 256×256 before being processed by the network. Both the generator and the discriminator used the Adam optimizer with a learning rate of 0.0002 and a first moment decay rate of 0.5. Post-training, the network was applied to predict T2 maps in a test set of 12,000 images and the generated images compared to ground truth FLASH scans. This process was then repeated with networks using only a single discriminator patch sizes of 16×16, 34×34, 70×70, and 142×142. The L1 error, using the ground truth FLASH sequence as a reference, was computed for each network type and the results compared.
Results
Figure 2 shows a bar graph comparing the L1 error for the single-patch discriminators using patch sizes 16×16, 34×34, 70×70, and 142×142, to the L1 error from the multi-patch discriminator using the scheme in Figure 1. The multi-patch approach can be seen to achieve a lower L1 error than any of the single-discriminator approaches. Figure 3 shows sample images from the discriminator using 70×70 patches and from the multi-patch discriminator, as well as the ground truth FLASH image. Compared to the multi-patch discriminator, the single-patch discriminator can be observed to both produce structure not observable in the ground truth image, as well as losing contrast delineating other image structures.Discussion
The results indicate that using a cGAN with a discriminator that inspects images, determining if they are real or generated, over several different sized areas can provide a benefit over a simpler discriminator that only examines one image patch size. Further work can be done in investigating the best way to combine the contributions from the different patches – in our implementation, the result essentially gives a “max pooling” of the various patch sizes, but other combinations could conceivably prove beneficial. This work could potentially lead to higher-quality synthesis of medical images from images with different contrast, an approach that might allow reduced scan protocol duration.Conclusion
A conditional generative adversarial network, applying a discriminator that examines several different image patch sizes to determine if they are generated, can outperform a network that uses a conventional discriminator.Acknowledgements
We acknowledge support from the Advanced Research Projects Agency-Energy (ARPA-E), U.S. Department of Energy, under Award Number DE-AR0000823 for contributing to fund the information, data, or work presented herein. The views and opinions of authors expressed herein do not necessarily state or reflect those of the United States Government or any agency thereof.References
[1] Sveinsson et al. ISMRM 2020. [2] Peterfy et al. The osteoarthritis initiative: report on the design rationale for the magnetic resonance imaging protocol for the knee. Osteoarthritis and Cartilage, 2008; 16: 1433-1441. [3] Goodfellow et al. Generative adversarial nets. In:Advances in neural information processing systems, 2014: 2672-2680. [4] Isola et al. Image-to-image translation with conditional adversarial networks. arXiv 2017.Figures

Figure 1: (a) The presented network uses a discriminator that examines different sized patches of an image to determine if they display real or generated data. The patch sizes are designed so that a 2×2 matrix of one patch size (with an overlap of one pixel) has the same size as the next largest patch. (b) The largest discriminator value in such a 2×2 matrix is selected and compared to the corresponding next largest patch. The larger value from that comparison is stored for that region and the process then repeated for the next patch size. This is applied over the whole image, using a stride of 16.
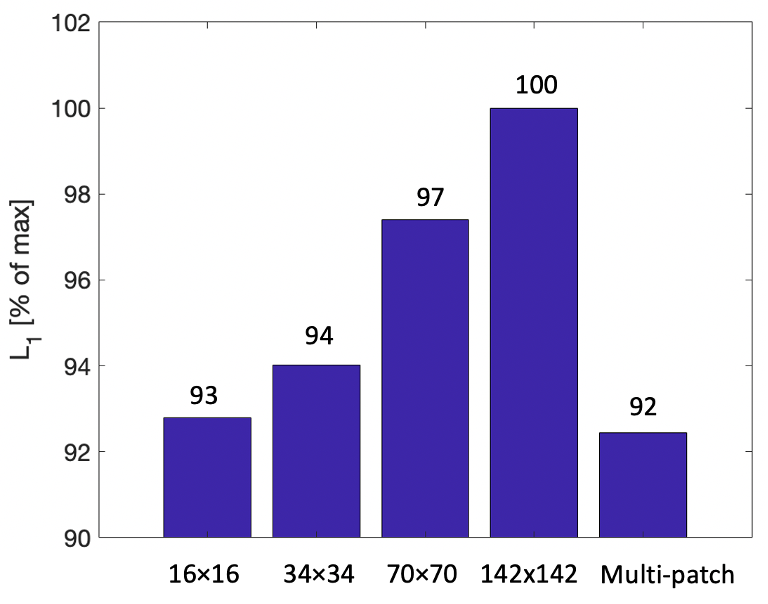
Figure 2: Bar graphs showing the L1 errors of various cGAN approaches when compared to the ground truth FLASH images. The first four bars represent networks where the discriminator only uses a single patch size, as shown at the bottom. The rightmost bar shows the result from the multi-patch approach presented here and described in Figure 1.
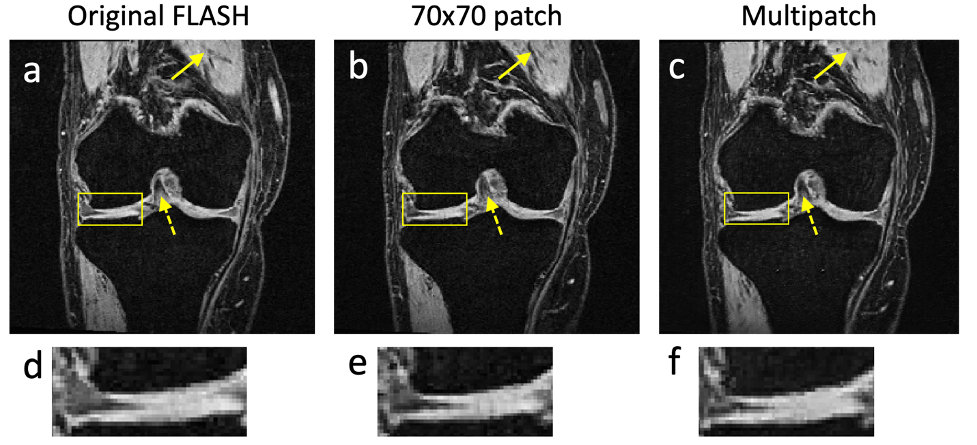
Figure 3: (a) A ground truth FLASH image. (b) An image constructed from DESS and TSE scans to synthesize the image in panel a. The network looked at single patch sizes of 70×70 pixels to determine if the image was real or generated. (c) An image constructed by using a multi-patch discriminator as shown in Figure 1. The single-patch discriminator in panel b creates new structures (solid arrow) and loses contrast (dashed arrow) compared to the multipatch discriminator in panel c. The undesirable creation of new structure is also shown in the zoomed-in panels (d)-(f).