3860
Accelerated water-fat separation based on deep learning model exploring multi-echo nature of mGRE1Weizmann Institute of Science, Rehovot, Israel, 2School of Information Engineering, Wuhan University of Technology, Wuhan, China, 3State Key Laboratory of Magnetic Resonance and Atomic and Molecular Physics, Wuhan Center for Magnetic Resonance, Wuhan Institute of Physics and Mathematics, Innovation Academy for Precision Measurement Science and Technology, Wuhan, China, 4Huazhong University of Science and Technology, Wuhan, China
Synopsis
We proposed a novel deep learning network for water-fat separation from undersampled mGRE data. The network contains three components: The first is the reconstruction module, which can effectively take advantage of the similarity between different echoes to recover the fully sampled image from the undersampled data; the second is the feature extraction module, which learns the correlations between consecutive echoes; and the third is the water-fat separation module that processes the feature information extracted from the feature extraction module. The results show that the proposed network can effectively obtain high-quality water and fat images at 6 times acceleration.
INTRODUCTION
Water-fat separation methods play an important role in numerous clinical MRI applications, such as measuring total visceral adipose tissue1, detecting brown fat2, and detecting myocardial fat infiltration3. Moreover, multi-echo water-fat separation methods allow for reliable water-fat separation in the presence of B0 field inhomogeneities. However, the acquisition of multi-echo images is time-consuming, leading to the limitations of the spatial resolution and anatomical coverage achievable while increasing the possibility of motion artifacts. An accelerated water-fat separation method from the undersampled k‐space data is desirable to reduce the scanning time.In recent years, compressed sensing4 (CS) and parallel imaging5 techniques have been applied to accelerate water-fat imaging successfully. The water, fat, and field map images are solved simultaneously using sparsity constraints on each of the images. However, the iterative algorithms combined with CS and parallel imaging in the non-linear reconstruction are time-consuming. Moreover, these iterative minimization processes based on sparsifying transforms tend to generate smaller sparse coefficient values and lead to loss of details and unwanted artifacts in the reconstruction when the acceleration rate is high6. This work aims to design a novel deep learning network architecture, which obtained high-equality water and fat images directly from the undersampled k‐space measurements by jointly learning the correlations of different echoes in mGRE and the iterative optimization characteristic of the traditional water-fat separation methods.
METHODS
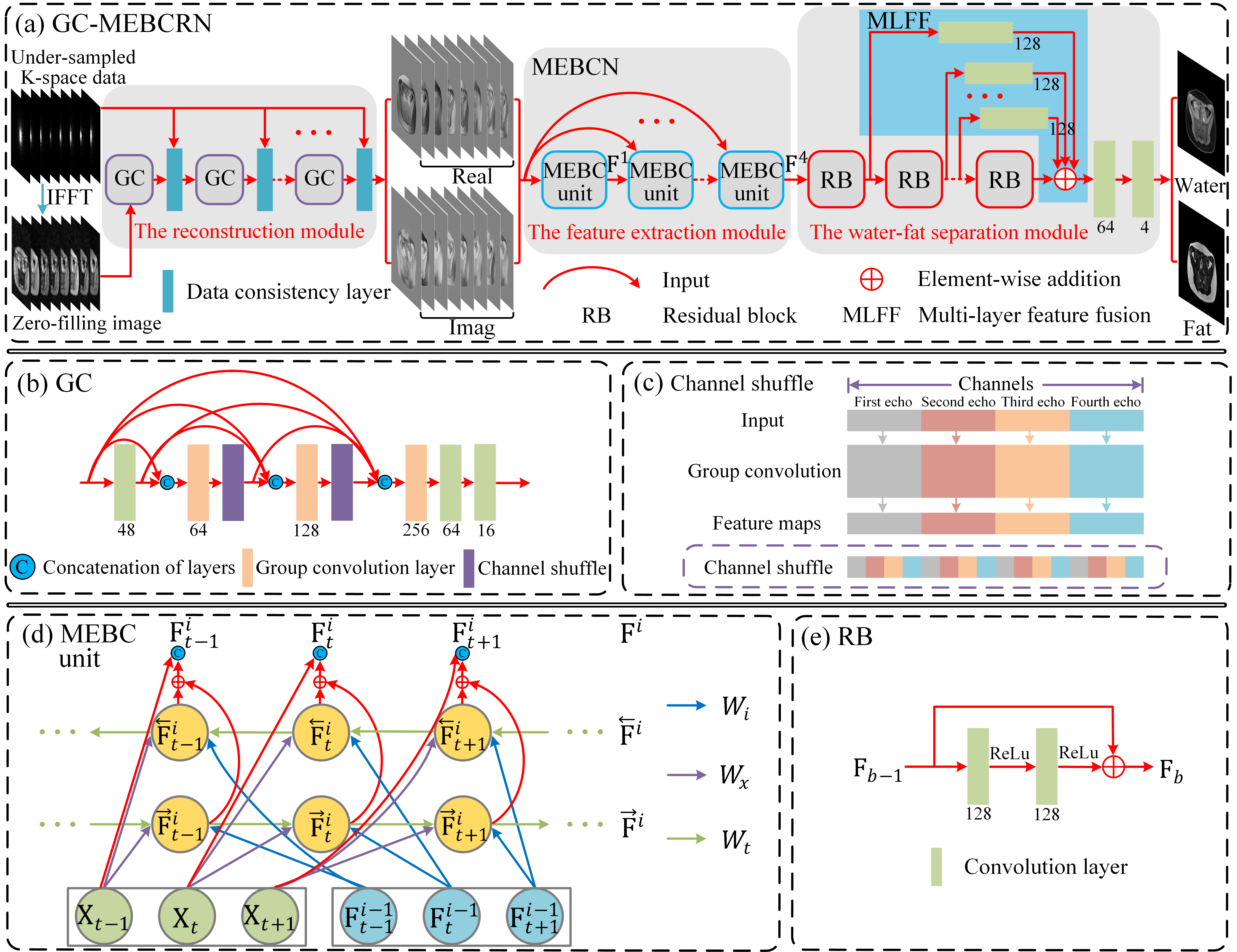
Group Convolution-Multi Echo Bidirectional Convolutional Residual Network (GC-MEBCRN) architecture is shown in Figure 1(a), which includes three main components (the second and third modules, MEBCRN, is our previous water-fat separation work7):1) The reconstruction module (Figure 1(a)), which contains several cascaded sub-networks, and every sub-network contains one group convolution (GC) block (Figure 1(b)) and one data consistency layer. The data consistency layer's main purpose is to replace some trained data with the originally acquired k-space so that the ground-truth can be further approached. The GC block can take advantage of the similarity between different echoes to recover a fully sampled image from the undersampled data through GC layer8 and channel shuffle9 (Figure 1(c)). The GC layer first divides the feature maps into eight groups (equivalent to 8 echoes). Every group will be applied the convolution independently, thus significantly reducing the computational cost and network parameters. Channel shuffle is used to shuffle all the feature maps uniformly to ensure that each group contains all the eight echoes' information.
2) The feature extraction module evolving over echoes and iterations (Multi-Echo Bidirectional Convolutional unit, MEBC unit) is shown in Figure 1(d), which learns the differences and similarities of consecutive echoes in the mGRE sequence and to propagate the contextual information across different echoes. Each echo node of the MEBC unit comprised three types of convolutions: the input convolution (purple arrows), the bidirectional convolution (pale yellow arrows), and the iteration convolution (light green arrows). We simultaneously conduct these three convolutions in the forward and backward direction of the mGRE sequence, and the summing of the features extracted from both directions as the final output of this echo node.
3) The water-fat separation module that processes the feature information extracted from the feature extraction module, which takes advantage of both stacked residual blocks (RB, Figure 1(e)) and the Multi-Layer Feature Fusion (MLFF) mechanism.
We employ different sampling patterns for different echoes, in which a golden angle increment across echoes was adopted for optimal k‐space coverage. Reference water-fat-separated images were obtained by a graph cut method10 implemented in ISMRM water-fat Toolbox11. The quality of the network's outputs was evaluated by the two quantitative metrics: peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM).
RESULTS
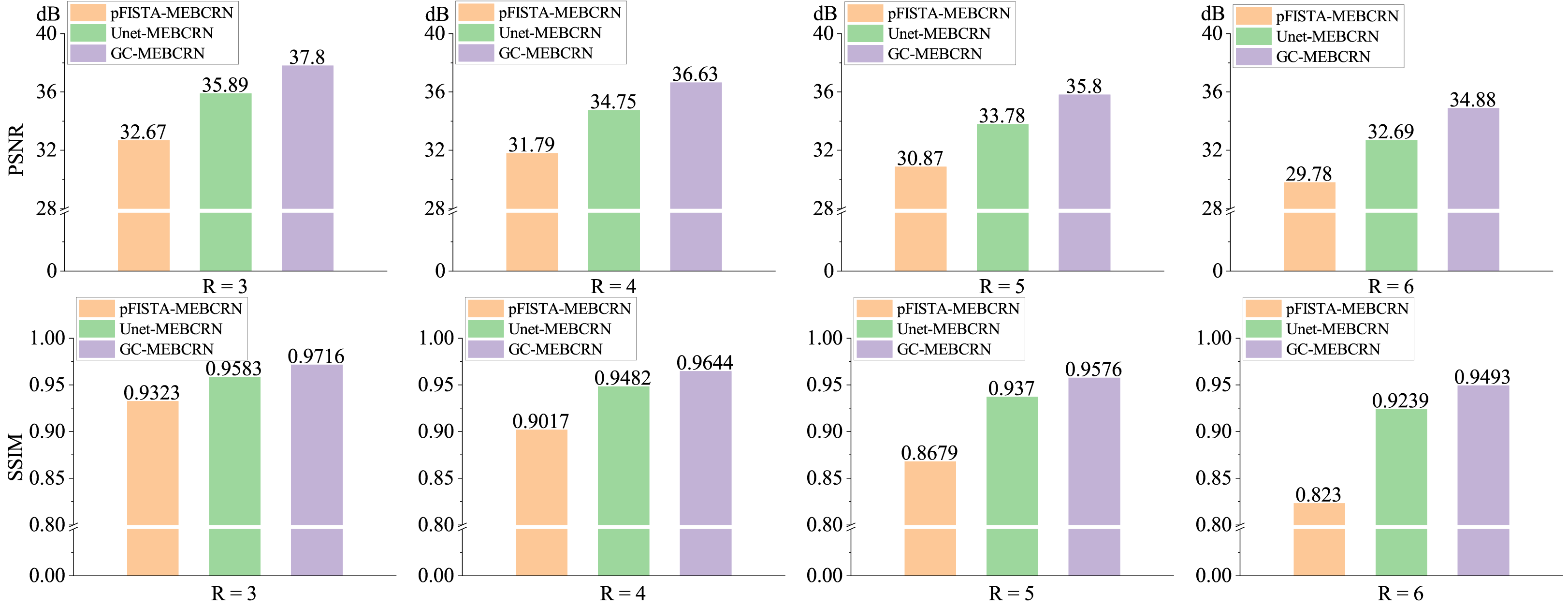
Figure 2 shows various water-fat separation methods' separation results for one representative subject (pFISTA-MEBCRN, pFISTA12 is an MRI reconstruction algorithm based on CS; Unet-MEBCRN, U-net13 is a classic deep learning network which is used here for multi-echo image reconstruction). The figure illustrates that the proposed GC-MEBCRN method can obtain better images, particularly from the zoomed regions and the error maps.Figure 3 summarizes the quantitative results obtained by various water-fat separation methods with the Radial sampling pattern on the test data at different acceleration rates. The statistical results of GC-MEBCRN under four different acceleration rates are higher than the other two methods.
Figures 4 and 5 show the generalization ability test's separation results for the unseen knee and foot data from the challenge dataset14, respectively. We can see that GC-MEBCRN still obtain a more reliable separation result at six times acceleration, while pFISTA-MEBCRN's separated images suffer from blurring.
DISCUSSION & CONCLUSION
A novel deep learning network (GC-MEBCRN) was proposed for water-fat separation from undersampled mGRE data. The proposed network could separate water and fat images by taking advantage of the multiple echoes' dependence in mGRE and outperform the pFISTA-MEBCRN and Unet-MEBCRN method in qualitative and quantitative metrics at different acceleration rates. The proposed GC-MEBCRN method offers a promising deep learning framework for scan time reduction in water-fat separation applications.Acknowledgements
We gratefully acknowledge the financial support by National Major Scientific Research Equipment Development Project of China (81627901), the National key of R&D Program of China (Grant 2018YFC0115000, 2016YFC1304702), National Natural Science Foundation of China (11575287, 11705274), and the Chinese Academy of Sciences (YZ201677).References
1. Kuk JL, Katzmarzyk PT, Nichaman MZ, et al. Visceral fat is an independent predictor of all‐cause mortality in men. Obesity, 2006, 14(2):336-341.
2. Hu HH, Smith Jr DL, Nayak KS, et al. Identification of brown adipose tissue in mice with fat-water IDEAL‐MRI. Journal of Magnetic Resonance Imaging, 2010, 31(5):1195-202.
3. Kellman P, Hernando D, Arai AE. Myocardial fat imaging. Current cardiovascular imaging reports, 2010, 3(2):83-91.
4. Lustig M, Donoho D, Pauly JM. Sparse MRI: the application of compressed sensing for rapid MR imaging. Magnetic resonance in medicine, 2007, 58(6): 1182-1195.
5. Griswold MA, Jakob PM, Heidemann RM, et al. Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magnetic resonance in medicine, 2002, 47(6):1202-1210.
6. Ravishankar S, Bresler Y. MR image reconstruction from highly undersampled k-space data by dictionary learning. IEEE transactions on medical imaging, 2010, 30(5):1028-41.
7. Liu K, Li X, Li Z, et al. Robust water-fat separation based on deep learning model exploring multi‐echo nature of mGRE. Magnetic Resonance in Medicine, 2020. https://doi.org/10.1002/mrm.28586.
8. Zhang T, Qi GJ, Xiao B, et al. Interleaved group convolutions. In Proceedings of the IEEE international conference on computer vision (ICCV), Italy, 2017. p. 4373-4382.
9. Zhang X, Zhou X, Lin M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Salt Lake City, Utah, 2018. P. 6848-6856.
10. Hernando D, Kellman P, Haldar JP, Liang ZP. Robust water/fat separation in the presence of large field inhomogeneities using a graph cut algorithm. Magnetic resonance in medicine. 2010;63:79-90.
11. Hu HH, Börnert P, Hernando D, et al. ISMRM workshop on fat-water separation: insights, applications and progress in MRI. Magnetic resonance in medicine. 2012;68:378-388.
12. Liu Y, Zhan Z, Cai JF, et al. Projected iterative soft-thresholding algorithm for tight frames in compressed sensing magnetic resonance imaging. IEEE transactions on medical imaging, 2016, 35(9):2130-40.
13. Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation. In Proceedings Part III of the 18th International Conference of MICCAI, Munich, Germany, 2015. p. 234-241.
14. The 2012 ISMRM Challenge on Water-Fat Reconstruction. http://challenge.ismrm.org/node/8. Accessed September 3, 2019.
Figures