3856
The video domain transfer deep learning network with error correction for Dixon Imaging with consistent slice-to-slice water and fat separation1Imaging Physics Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 2Diagnostic Radiology Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States, 3Cancer Systems Imaging Department, The University of Texas MD Anderson Cancer Center, Houston, TX, United States
Synopsis
We applied a video processing deep-learning neural network (originally developed to synthesize high resolution photorealistic video from a time series of dancing poses, semantically segmented street-view labels, or human face outline sketches) to Dixon imaging to present combined benefits of 2D and 3D networks. The developed Dixon Video Domain Transfer Generative Adversarial Network (DixonVDTGAN) could create slice-to-slice consistent water images with reduced demand on GPU memory. It could also successfully correct deep-learning processing errors for robust water and fat signal separation under two assumptions that the deep-learning processing errors are localized and the image phase is spatially smooth.
INTRODUCTION
The Video Domain Transfer Generative Adversarial Network(VDTGAN) can potentially combine the benefits of both 2D and 3D networks.1-2 When applied to processing 3D images, the VDTGAN approach consists of first translating “3D images” to “a time-sequence of motion pictures,” then creating temporally coherent multi-frame video outputs, and finally translating the output back to “spatially consistent volumetric MRI images.” As a result, VDTGAN can have much reduced demand on GPU memory and provide potentially better slice-to-slice consistency on 3D images. However, the performance of VDTGAN can be limited by its processing errors.1,3 In this work, we present a multi-stage VDTGAN with error correction for 3D Dixon imaging with consistent slice-to-slice water and fat separation.METHODS
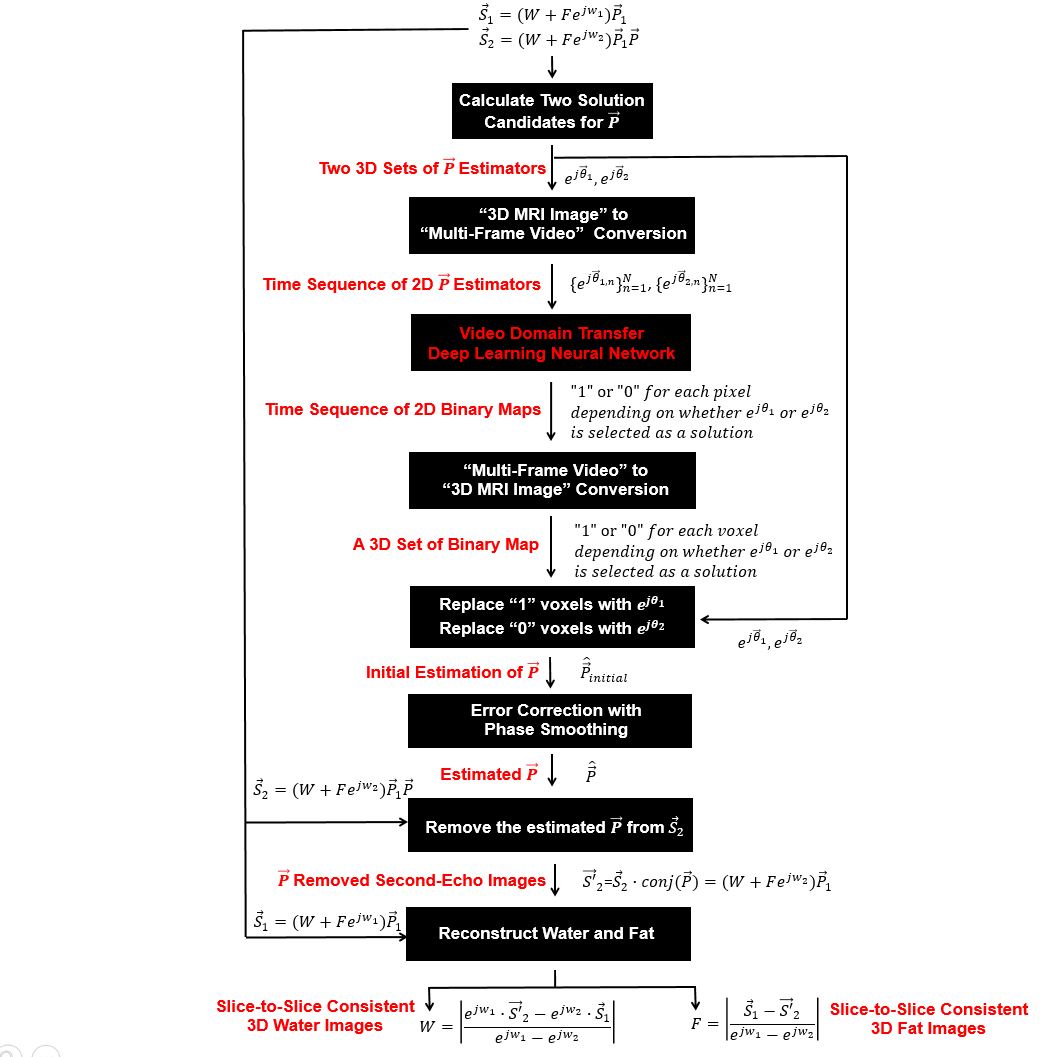
The structure and processing flow of our multi-stage VDTGAN approach(hereafter termed DixonVDTGAN) are presented in Fig.1.(1) Dual-echo Dixon image acquisitions: 3D dual-echo Dixon images($$$\overrightarrow{S_{1}}=(W+Fe^{jw_{1}})\overrightarrow{P_{1}}$$$ and $$$\overrightarrow{S_{2}}=(W+Fe^{jw_{2}})\overrightarrow{P_{1}}\overrightarrow{P}$$$) were acquired at two arbitrary echo-times. The $$$W$$$ and $$$F$$$ are 3D sets of water and fat images, $$$w_{1}$$$ and $$$w_{2}$$$ are chemical-shift induced phases determined by two selected echo-times, and $$$\overrightarrow{P_{1}}$$$ is the unknown image phase of the first-echo signals. The $$$\overrightarrow{P}$$$ represents additive phase to the second-echo images which is the key parameter to be estimated with VDTGAN for water and fat signal separation.4-5
(2) VDTGAN additive phase estimation in the second-echo images: Two 3D sets of solution candidates($$$e^{j\overrightarrow{\theta_{1}}}$$$ and $$$e^{j\overrightarrow{\theta_{2}}}$$$) for $$$\overrightarrow{P}$$$ were first calculated from $$$\overrightarrow{S_{1}}$$$ and $$$\overrightarrow{S_{2}}$$$, then provided as inputs for VDTGAN training after translating them to time-sequences of 2D multi-frame video images. Between two solution candidates, only one is a true solution and the other is false.4-6 The ground-truth output binary maps for VDTGAN training were semantically segmented as “1” or “0” depending on whether the true solution is $$$e^{j\overrightarrow{\theta_{1}}}$$$ or $$$e^{j\overrightarrow{\theta_{2}}}$$$ for each voxel. After training, a sequence of 2D binary maps was created from the VDTGAN output, then translated back to a set of 3D binary map. The final estimation for $$$\overrightarrow{P}$$$ was composed with a true solution between $$$e^{j\overrightarrow{\theta_{1}}}$$$ and $$$e^{j\overrightarrow{\theta_{2}}}$$$ for each voxel referring to the generated binary maps.
(3) VDTGAN error-correction: The binary map generated by VDTGAN may include processing errors, leading to incorrect solution choices between $$$e^{j\overrightarrow{\theta_{1}}}$$$ and $$$e^{j\overrightarrow{\theta_{2}}}$$$ for some voxels. In this work, these errors were corrected by applying 3D phase smoothing filters under two assumptions that the VDTGAN processing errors are localized and the phase of $$$\overrightarrow{P}$$$ is spatially smooth.
(4) The final 3D water and fat image separation: Once $$$\overrightarrow{P}$$$ is removed from the second-echo images, 3D water ($$$W$$$) and fat ($$$F$$$) images can be separated from $$$\overrightarrow{S_{1}}$$$ and $$$\overrightarrow{S'_{2}}$$$ with direct arithmetic operations(Fig.1).4-6 In this work, we evaluated the performance of DixonVDTGAN with the Frechet inception distance(FID) score which allows to evaluate image-quality directly in a deep-learning feature domain.7 The measured FID score and the degree of image-quality degradation have pseudo-linear relationship. Thus, smaller FID scores indicate two image groups are more similar and their statistical characteristics are more correlated with each other.
RESULTS
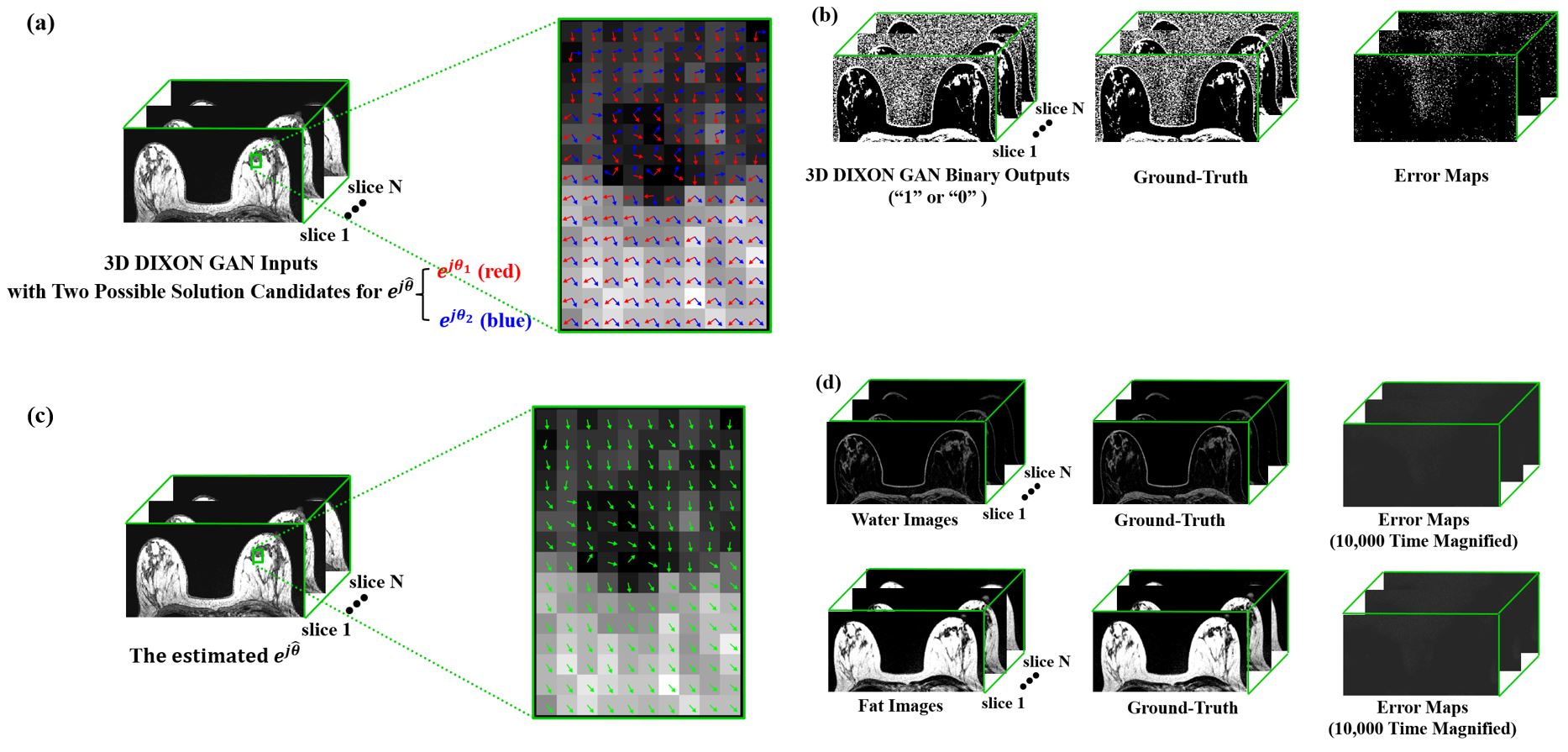
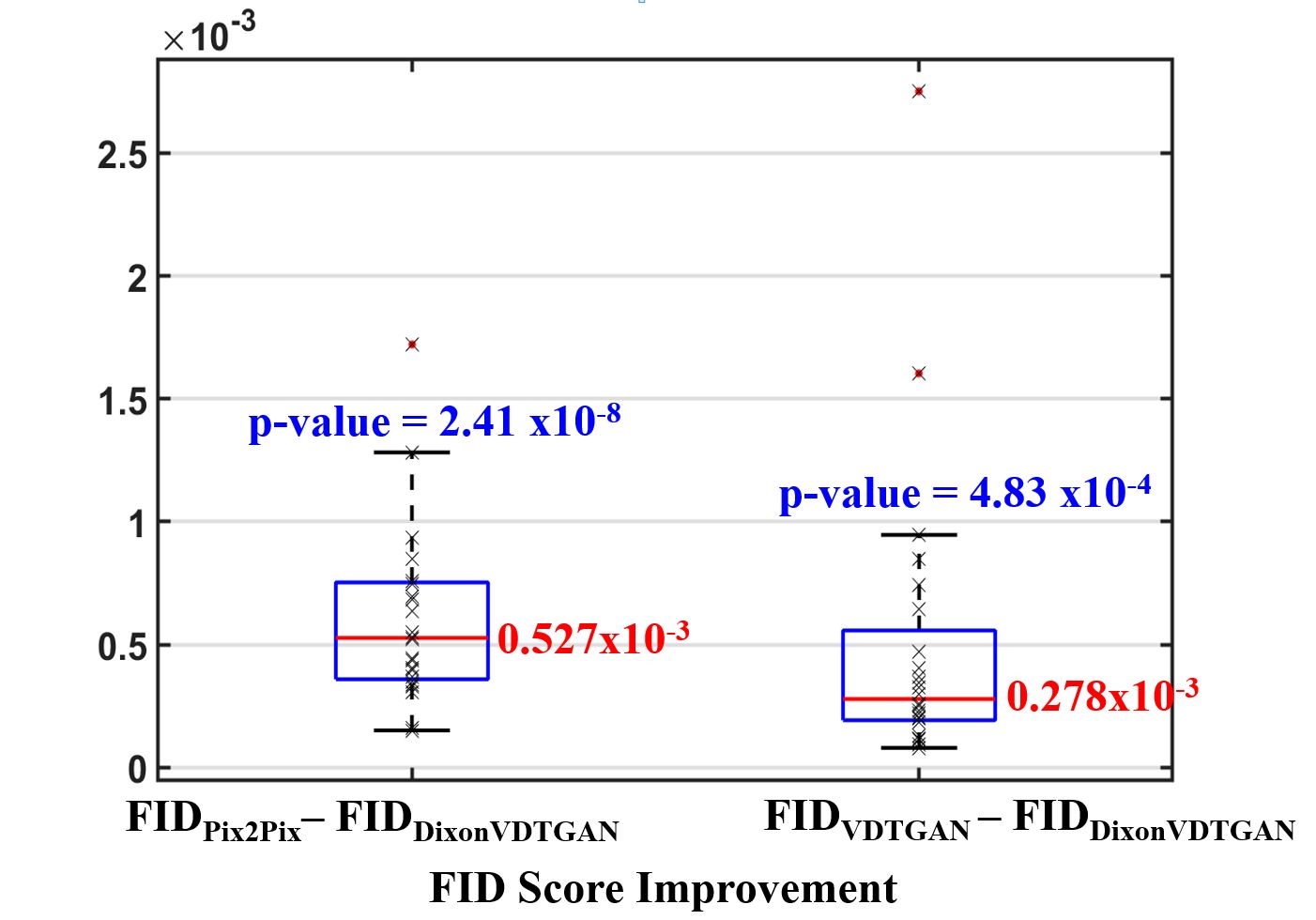
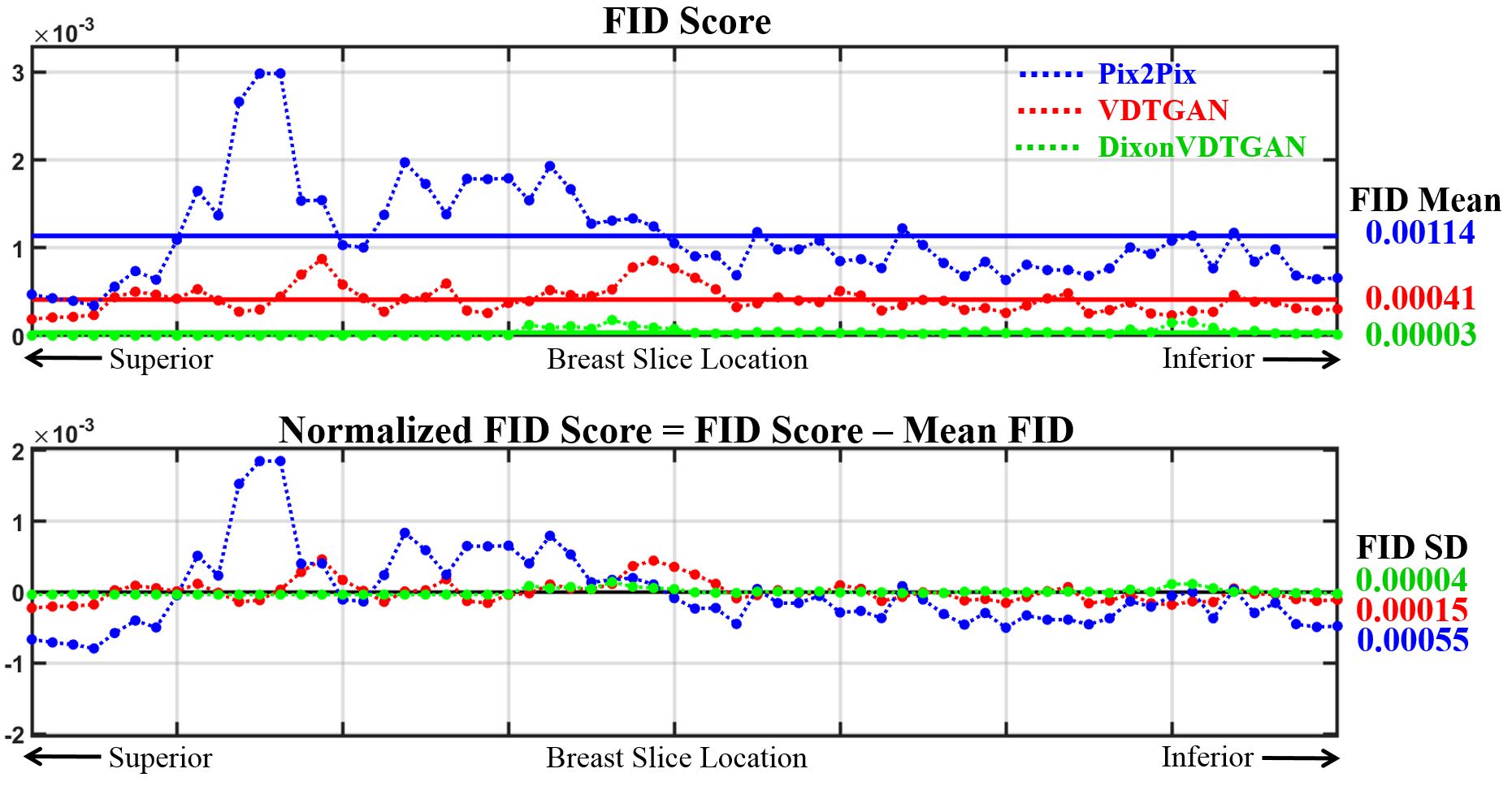
76 patients were scanned with a 3D dual-echo gradient-echo Dixon pulse-sequence, then randomly separated to three groups(50 for network training, 3 for validation, and 23 for testing). The main scan-parameters were TE1/TE2=1.7/3.3~2.1/3.9ms,TR=6.2~9.5ms,NxxNy=512x512,NFExNPE=480x384,slice-thickness/slice-gap=2/0mm,FOV=28x28~36x36cm,RBW=±250kHz,NEX=1, and scan-time=1min16secs~1min58secs. We implemented the DixonVDTGAN on a DGX1 system with a Tesla V100 32GB GPU(NVIDIA,Santa Clara,CA,USA). We trained our model for 400 epochs with a LSGAN loss model and an ADAM optimizer(mini-batch=1,initial learning-rate=0.0002,$$$\beta_{1}$$$=0.5, and $$$\beta_{2}$$$=0.999).Fig.2(a-b) show network input and processed output pairs from a 3D test dataset. Between two solution candidates notified with “red” and “blue” vector arrows(Fig.2(a)), a 3D set of selected solutions(Fig.2(c)) was composed by replacing the generated binary maps(Fig.2(b)) with corresponding real solution vectors from Fig.2(a). 3D breast water images of 23 patients were reconstructed with DixonVDTGAN, then compared to reference images from Pix2Pix and VDTGAN. Pix2Pix processes each slice image separately while ignoring their slice-to-slice correlations.8 In contrast, VDTGAN creates 3D water images directly from Dixon images using end-to-end processing without any error correction.2 DixonVDTGAN was able to reconstruct water images for all 23 patients with improved image quality and the smallest FID scores(Fig.3). Paired sample t-tests verified DixonVDTGAN could improve image-quality compared to Pix2Pix and VDTGAN. FID scores of DixonVDTGAN were plotted for an entire 3D volume with 64 slices in Fig.4. Compared to Pix2Pix and VDTGAN, DixonVDTGAN was able to handle slice-by-slice variations in image-quality by reducing the mean FID score 97% and 93% for each.
DISCUSSION AND CONCLUSION
Our work demonstrates that DixonVDTGAN can be used for Dixon imaging with consistent slice-to-slice water and fat signal separation. Instead of directly applying VDTGAN with end-to-end processing, our proposed DixonVDTGAN achieves water and fat separation in multiple stages with several important advantages. First, it explicitly preserves the phase information after deep-learning processing, allowing processing errors to be corrected in a later stage with spatially smooth-filtering. Second, the performance is maximized by simplifying output levels to a binary selection that corresponds to whether a voxel is water-dominant or fat-dominant (instead of outputting continuous water and fat contents for each voxel). Finally, the dynamic range of the final water images is not compromised due to GPU memory limitations compared to the direct VDTGAN approach.Acknowledgements
No acknowledgement found.References
[1] Wang TC, Liu MY, Zhu JY, Liu G, Tao A, Kautz J, and Catanzaro B. Video-to-video synthesis. In Advances in Neural Information Processing Systems 2018.
[2] Son JB, Pagel MD, and Ma J. 3D MRI Processing using a video domain transfer deep learning neural network. In Proceedings of the International Society of Magnetic Resonance in Medicine, Virtual Conference 2020 (Abstract 3574).
[3] Mallya A, Wang TC, Sapra K, and Liu MY. World-consistent Video-to-video synthesis. European Conference on Computer Vision 2020.
[4] Berglund J, Ahlstrom H, Johansson L, and Kullberg J. Two‐point Dixon method with flexible echo times. Magnetic Resonance in Medicine 2011;65:994-1004.
[5] Ma J, Son JB, and Hazle JD. An improved region growing algorithm for phase correction in MRI. Magnetic Resonance in Medicine 2015;76:519-529.
[6] Son JB, Hwang KP, Scoggins ME, Dogan BE, Rauch GM, Pagel MD, and Ma J. Water and fat separation with a Dixon Conditional Generative Adversarial Network (DixonCGAN). In Proceedings of the International Society of Magnetic Resonance in Medicine, Virtual Conference 2020 (Abstract 823).
[7] Heusel M, Ramsauer H, Unterthiner T, Nessler B, and Hochreiter S. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In Advances in Neural Information Processing Systems 2017:6626-6637.
[8] Isola P, Zhu J-Y, Zhou T, and Efros AA. Image-to-image translation with conditional adversarial networks. In Institute of Electrical and Electronics Engineering Conference on Computer Vision and Pattern Recognition 2017:1125-1134.
Figures