3742
Temporal Frame Alignment for Speech Atlas Construction Using High Speed Dynamic MRI1Department of Radiology, Massachusetts General Hospital, Boston, MA, United States, 2Department of Bioengineering, University of Illinois at Urbana-Champaign, Champaign, IL, United States, 3Department of Communication Sciences and Disorders, East Carolina University, Greenville, NC, United States
Synopsis
Visual assessment of articulatory motion of the vocal tract in speech has been drastically advanced by recent developments in high-speed real-time MRI. However, the variation of speaking rate among different subjects prevents quantitative analysis of data from a larger study group. We present a pipeline of methods that aligns audio and image data in the time domain and produces temporally matched image volumes for various subjects. Comparison of the cross-correlation score before and after time alignment showed an increased similarity between source and target image sequences, enabling production of preprocessed multi-subject data for the subsequent statistical atlas construction studies.
Introduction
Recent developments in dynamic speech MRI have greatly increased imaging speed, enabling visual assessment for articulatory motion in a large number of time frames during speech [1,2]. In medical imaging, to help the quantitative analysis of a specific population scanned, a statistically constructed image atlas is often sought for both to provide a common space for different subjects to be compared in and to reveal unique statistical traits of any individual subject [3]. Previously, dynamic speech atlases have been constructed using various MRI data [4]. With any multi-subject data from a study group, in order to build an appropriate spatiotemporal vocal tract atlas, various motion patterns from different subjects need to be carefully aligned both spatially and temporally [5]. Comparing to spatial alignment achieved through various image registration techniques, temporal alignment in previous tasks was achieved either using manual identification or analysis of information from neighboring image frames [5,6]. In this work, we utilize subject audio data collected simultaneously during the imaging process and match the audio waves to yield temporal frame alignment information. Comparing to visual assessment or frame-analysis-based methods, this provides a more accurate first-hand time alignment map, which is used to direct the alignment of corresponding image volumes. Intermediate image frames can be found using registration-driven volume interpolation.Methods
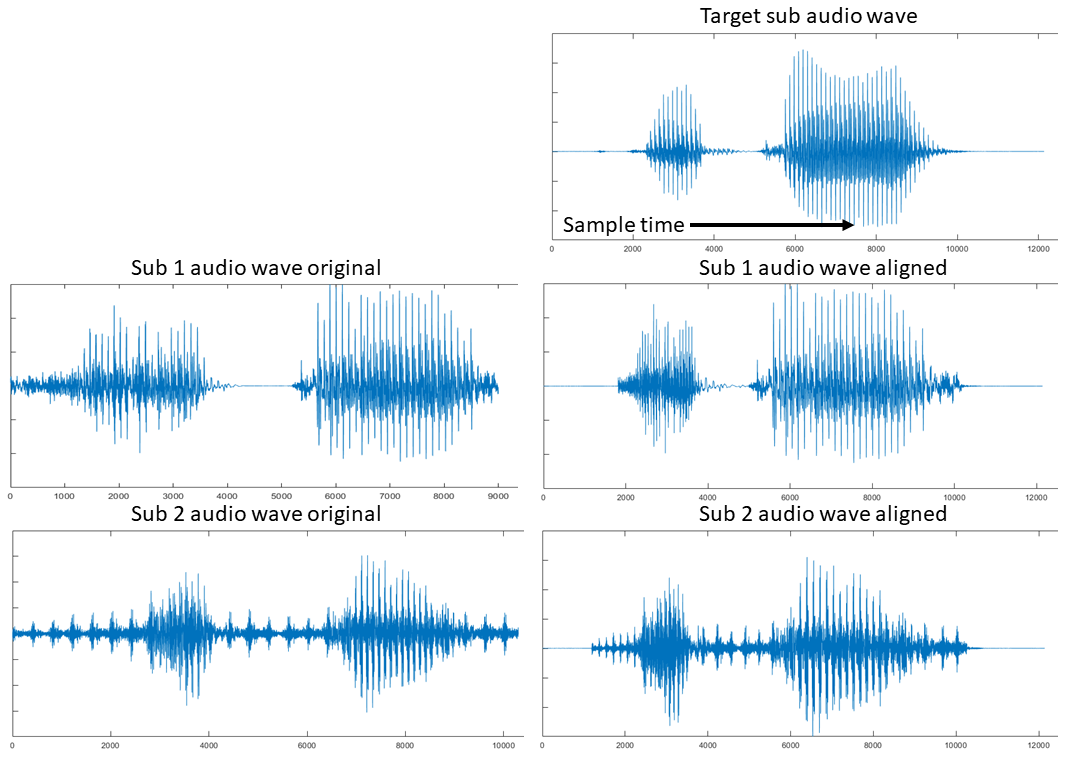
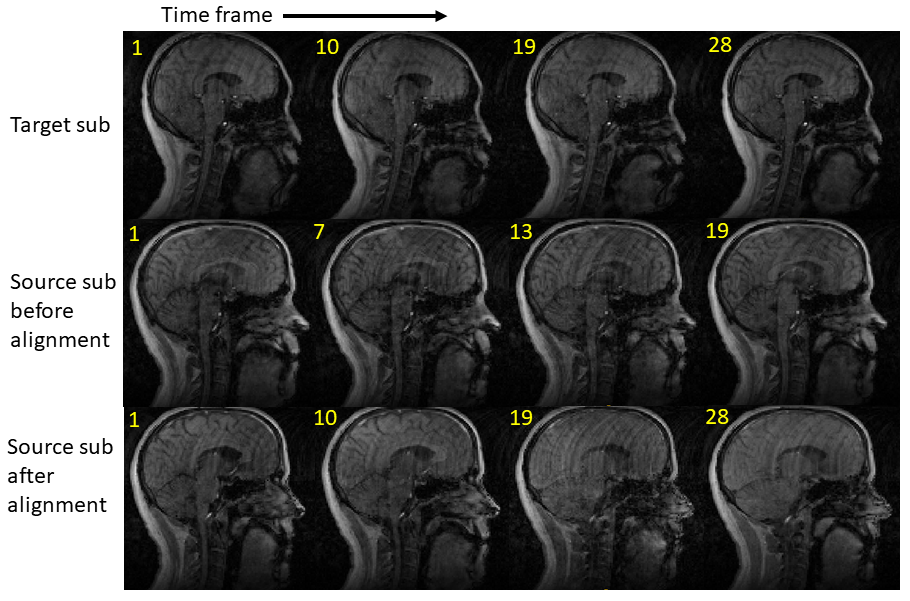
For each specific subject, its collected real-time speech MRI data usually consists of a sequence of image volumes over time during repeated pronunciation of certain designed utterances. The recording of speech audio happens simultaneously with the real-time MRI imaging scanning session. Here, we focus on one of the repetitions for each subject. The duration of the pronunciation of the utterance is expected to vary depending on subject so that a first task for time alignment is to normalize the length of the utterance duration. We hand-pick one of the subjects to be the reference with its data duration being the common time domain $$$[0,T_{REF}]$$$, where every other subject will be temporally warped into. Every subject’s denoised audio waveform [7] is read from the recordings (Fig. 1). Because they all pronounce the same utterance, their waveforms share a similar general pattern. Diffeomorphic image registration has been an effective tool in aligning images sharing similar features [8]. We apply a one-dimensional form of the registration algorithm to match each subject waveform with the reference waveform, using mutual information as the similarity measure between signals. The waveform match yields a temporal map that links time frames in each subject space to the reference domain $$$t_{ref}=T(t_s),t_{ref} \in [0,T_{REF}]$$$. Using this information, the temporal position of the corresponding images in the subject time domain can be found by the inverse mapping from the reference time domain, i.e., $$$t_{s}=T^{-1}(t_{ref}),t_{s} \in [0,T_{S}]$$$. However, the computed time position $$$t_{s}$$$ is usually not an integer, meaning that only its two neighboring integer time frames $$$t_{sf}=\mbox{floor}(t_{s})$$$ and $$$t_{sc}=\mbox{ceiling}(t_{s})$$$ in the subject time domain has an image volume. Henceforth, we apply the standard form of the diffeomorphic image registration on those two image volumes $$$I_1$$$ and $$$I_2$$$ at $$$t_{sf}$$$ and $$$t_{sc}$$$. A deformation field $$$\mathbf{u}$$$ is found between these two images and their transformation relationship is denoted by $$$I_2 \sim \phi (I_1)$$$, where $$$\phi$$$ is the warping operation realized by $$$\mathbf{u}$$$. To approximate the intermediate image between these two integer time frames, we cut the deformation field $$$\mathbf{u}$$$ by a portion, i.e., $$$\mathbf{u}_h = \mathbf{u} (t_{s}-t_{sf})/(t_{sc}-t_{sf}) $$$. Finally, we warp $$$I_1$$$ by the mid-way deformation field $$$\mathbf{u}_h$$$, yielding $$$\phi_h(I_1)$$$ as an estimation for the intermediate image volume and as the new image volume at time frame $$$t_{ref}$$$ in the reference domain. This process is repeated for every $$$t_{ref}$$$ in $$$[0,T_{REF}]$$$, eventually reconstructing the whole image sequence in the normalized time domain (Fig. 2).Results
We tested the proposed pipeline on a preliminary data group consisting of three subjects speaking the utterance “hamper” over the time span of 36, 26, and 31 image frames, respectively. The subject with the greatest number of frames (36) was used to build the reference space. Results of the audio waveform match are shown in Fig. 1. With the time maps produced, images of the other two test subjects in the reference space were found via the intermediate deformation field. A visual result of the mid-sagittal slices is shown in Fig. 2, showing an improved motion trend to the target. The cross-correlation measuring the similarity between matched images at the same time positions before and after temporal alignment was computed and results in an evenly selected grid of the 36 frames are shown in Fig. 3. For test subject 1, the average cross-correlation is 0.71±0.02 before alignment and 0.73±0.03 after alignment. For test subject 2, the average cross-correlation is 0.77±0.03 before alignment and 0.79±0.04 after alignment. Similarity to the reference sequence was generally increased after temporal alignment for both test subjects, even despite the lack of spatial warping for normalization across the subjects.Conclusion
We proposed a time alignment method combining information from real-time MRI sequences and their audio waveforms. The method produced similarly paced image sequences between different subjects, paving the way for future atlas construction.Acknowledgements
This work was supported by NIH R01DE027989.References
[1] Bae, Y., Kuehn, D. P., Conway, C. A., & Sutton, B. P. (2011). Real-time magnetic resonance imaging of velopharyngeal activities with simultaneous speech recordings. The Cleft palate-craniofacial journal, 48(6), 695-707.
[2] Lingala, S. G., Sutton, B. P., Miquel, M. E., & Nayak, K. S. (2016). Recommendations for real‐time speech MRI. Journal of Magnetic Resonance Imaging, 43(1), 28-44.
[3] Woo, J., Xing, F., Lee, J., Stone, M., & Prince, J. L. (2015, June). Construction of an unbiased spatio-temporal atlas of the tongue during speech. In International Conference on Information Processing in Medical Imaging (pp. 723-732). Springer, Cham.
[4] Woo, J., Xing, F., Lee, J., Stone, M., & Prince, J. L. (2018). A spatio-temporal atlas and statistical model of the tongue during speech from cine-MRI. Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization, 6(5), 520-531.
[5] Woo, J., Xing, F., Stone, M., Green, J., Reese, T. G., Brady, T. J., ... & El Fakhri, G. (2019). Speech map: A statistical multimodal atlas of 4D tongue motion during speech from tagged and cine MR images. Computer Methods in Biomechanics and Biomedical Engineering: Imaging & Visualization, 7(4), 361-373.
[6] Xing, F., Woo, J., Lee, J., Murano, E. Z., Stone, M., & Prince, J. L. (2016). Analysis of 3-D tongue motion from tagged and cine magnetic resonance images. Journal of Speech, Language, and Hearing Research, 59(3), 468-479.
[7] Vaz, C., Ramanarayanan, V., & Narayanan, S. (2018). Acoustic denoising using dictionary learning with spectral and temporal regularization. IEEE/ACM transactions on audio, speech, and language processing, 26(5), 967-980.
[8] Vercauteren, T., Pennec, X., Perchant, A., & Ayache, N. (2007, October). Non-parametric diffeomorphic image registration with the demons algorithm. In International Conference on Medical Image Computing and Computer-Assisted Intervention (pp. 319-326). Springer, Berlin, Heidelberg.
Figures