3502
CE-Net: multi-inputs contrast enhancement network for nasopharyngeal carcinoma contrast enhanced T1-weighted MR synthesis1Department of Health Technology and Informatics, The Hong Kong Polytechnic University, Hong Kong, China, 2Department of Clinical Oncology, Queen Elizabeth Hospital, Hong Kong, China
Synopsis
To reduce the usage of gadolinium-based contrast agents (GBCAs), we proposed a deep learning based multi-inputs network (CE-Net) for contrast enhanced T1-weighted MR image synthesis based on pre-contrast T1-weighted and T2-weighted images in nasopharyngeal carcinoma (NPC) cases. When compared with multi-channel input methods, the proposed CE-Net has the ability to extract information from each input modalities separately. Supervision and multi-scale strategies are also applied in the proposed network. Quantitative and qualitative results show that our proposed CE-Net could achieve better performance when compared with the newly proposed Hi-Net and its extensions.
Introduction
Contrast enhanced T1-weighted (ceT1w) MR images that obtained by injection of gadolinium-based contrast agents (GBCAs) are essential for daily clinical decision making, for example, detection of contrast enhancement in patients with suspected nasopharyngeal carcinoma (NPC). However, recent study shows injection of GBCAs can increase the risk of accumulation and toxicity in patients with normal renal function 1. It is also suggested that the usage of GBCAs should be minimized 2,3. In this study, taking advantage of the powerful information extraction ability of deep learning, we developed and evaluated a multi-inputs neural network (CE-Net) for ceT1w MR prediction based on pre-contrast T1-weighted (T1w) and T2-weighted (T2w) MRI images in NPC cases.Methods
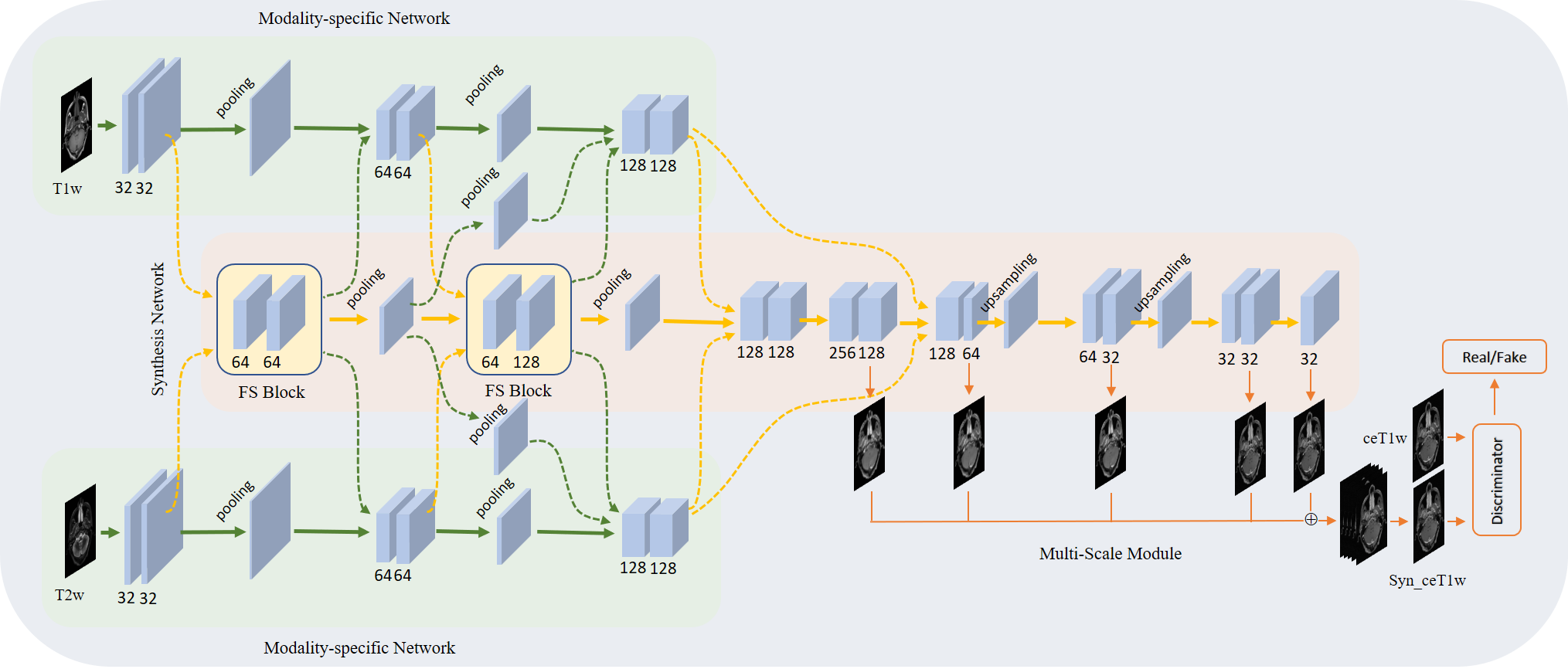
Sixty-four NPC patients are included in this retrospective study. For each patient, pre-contrast T1w and T2w MR images, and ceT1w images were collected. All images were well aligned and if necessary, rigid registration was applied to fine-tune minor alignment variations. T1w and T2w MR images were used as input data, and ceT1w images were used as target data.The proposed CE-Net, as shown in Fig. 1, learned a mapping from pre-contrast T1w and T2w MR images to ceT1w images. It consists of five modules: two modality-specific networks, a synthesis network, a multi-scale module and a discriminator. The modality-specific network was utilized to learn the representations from T1w and T2w separately. In synthesis network, fusion and supervision (FS) blocks were used to fuse individual latent representations, then feedback to latter convolution layers of the modality-specific network to guide feature extraction. In this way, individual modality-specific networks could communicate and cooperate with each other to learn complementary information from each input modality. To enlarge the reception field, the multi-scale module was utilized to upsample each side’s output feature from the synthesis network to the size of the output image, and fuse them with a concatenation operation followed by a 3×3 convolution layer to generate the final output. A discriminator was used to further improve the generation ability of the synthesis network.
We used a newly proposed Hybrid-fusion network (Hi-Net) 4 and our improved extensions as comparisons to demonstrate the effectiveness of the proposed CE-Net. Mean absolute error (MAE), mean square error (MSE), structural similarity index (SSIM), and peak signal-to-noise ratio (PSNR) were used as quantitative evaluation metrics.
Results
We used 29 NPC patients' data to evaluate our proposed CE-Net against Hi-Net, and our improved extensions, more details of Hi-Net could be seen in the reference 4. These extensions including: Hi-Net_T (take ceT1w as the target of modality-specific networks), Hi-Net_w/o-D (exclude the decoder of modality-specific networks to make the model focus on ceT1w synthesis), Hi-Net_BP (fuse output features of modality-specific networks before pooling layers to reduce information reduction). In our CE-Net, we adopted the first FS block to supervise features extraction of second and third convolution blocks in modality-specific network, CE-Net_s1 (the first FS block supervise features extraction of second convolution block only) also used as a comparison. Slice-based quantitative results and qualitative results are shown in Table 1 and Fig. 2.As shown in Table 1, Hi-Net obtained 51.19±13.74, 12088.02±6098.83, 0.862±0.041 and 31.87±1.94 for MAE, MSE, SSIM, and PSNR respectively, which was the worst result in all evaluation metrics among different models. Our proposed CE-Net achieved the best quantitative results of 47.41±13.34, 10440.35±5724.82, 0.877±0.041 and 32.55±1.99 for MAE, MSE, SSIM, and PSNR, respectively. Fig. 2 showed that the contrast enhancement effect (indicated by red and yellow arrows) was not apparent in the original Hi-Net method. Compared with other models, our proposed CE-Net generated more realistic ceT1w MR images with more anatomic details.
Discussion
In contrast to the existing Hi-Net which uses two auto-encoders to extract information from individual MR modalities, our proposed CE-Net directly uses three convolution blocks to learn the representations from each input MR, so that the model could focus on the input to output mapping. After dropping the decoder of modality-specific network, MAE decreased from 51.19±13.74 to 50.26±13.58. Supervision strategy was utilized to guide representations learning of modality-specific network, thus two separate modality-specific networks could communicate with each other through FS Block by information fusion. With that, MAE was furthered decreased from 49.03±13.58 to 47.54±13.38. To increase the reception field of the model, a multi-scale module is applied by upsampling the output features of each decoder to output size, and concatenating to generate final output, thus the reception field of the model could be enlarged and integrity of structures could be kept. From Fig. 2 (indicated by green arrows), we can see that the proposed CE-Net can predict more accurate nasal structure when comparing with no multi-scale module CE-Net_s1.Conclusion
In this work, we have demonstrated the feasibility of a novel multi-input network (CE-Net) for ceT1w MR prediction in NPC cases. Compared with the state-of-the-art method of Hi-Net, CE-Net was shown to generate more realistic ceT1w MR images with more anatomic details.Acknowledgements
This research was partly supported by funding ITS/080/19 and GRF 151022/19M.References
1. Ranga, Anju, et al. "Gadolinium based contrast agents in current practice: risks of accumulation and toxicity in patients with normal renal function." The Indian Journal of Radiology & Imaging 27.2 (2017): 141.
2. Kleesiek, Jens, et al. "Can virtual contrast enhancement in brain MRI replace gadolinium? a feasibility study." Investigative radiology 54.10 (2019): 653-660.
3. Gong, Enhao, et al. "Deep learning enables reduced gadolinium dose for contrast‐enhanced brain MRI." Journal of magnetic resonance imaging 48.2 (2018): 330-340.
4. Zhou, Tao, et al. "Hi-net: hybrid-fusion network for multi-modal MR image synthesis." IEEE transactions on medical imaging 39.9 (2020): 2772-2781.
Figures