3280
Stacked hybrid learning U-NET for segmentation of multiple articulators in speech MRI1Roy J Carver Department of Biomedical Engineering, University of Iowa, Iowa City, IA, United States, 2Government Engineering College Kozhikode, Kozhikode, India, 3Department of Neurology, University of Iowa, Iowa City, IA, United States, 4Department of Radiology, University of Iowa, Iowa City, IA, United States
Synopsis
We propose a stacked U-NET architecture to automatically segment the tongue, velum, and airway in speech MRI based on hybrid learning. Three separate U-nets are trained to learn the mapping between the input image and their specific articulator. The two U-NETs to segment the velum, and tongue are based on transfer learning, where we leverage open-source brain MRI segmentation. The third U-NET for airway segmentation is based on classical training methods. We demonstrate the utility of our approach by comparing against manual segmentations.
Purpose
Speech production involves a complex coordination of articulators such as lips, tongue, velum, pharynx, glottis, and epiglottis. Dynamic MRI allows for imaging the geometric deformation of these articulators and has potential utility in several speech science and clinical applications[1]–[3]. Previous work demonstrated that conventional neural networks can segment the deforming airway and articulators but require significant amounts of manually labeled training data (eg. of the order of a few 100’s of image frames)[4], [5]. Moreover, these warrant the need of new training data whenever the scan acquisition parameters are changed – which would significantly increase the burden for manual annotations. Here, we propose a novel fully automatic multiple articulator segmentation model based on a stackable U-NET architecture with hybrid learning. Our approach leverages a hybrid method for training. Two U-NETs are pre-trained on segmentations from open-source brain MRI database and transfers the model weights to our model. It can efficiently segment the soft-tissues: tongue and velum in our in-house speech MRI datasets from very few manually labeled images (few 10’s of images). The second U-NET model is trained on an in-house airway dataset due to the unavailability of large scale open source airway MRI databases with manual segmentations.Methods
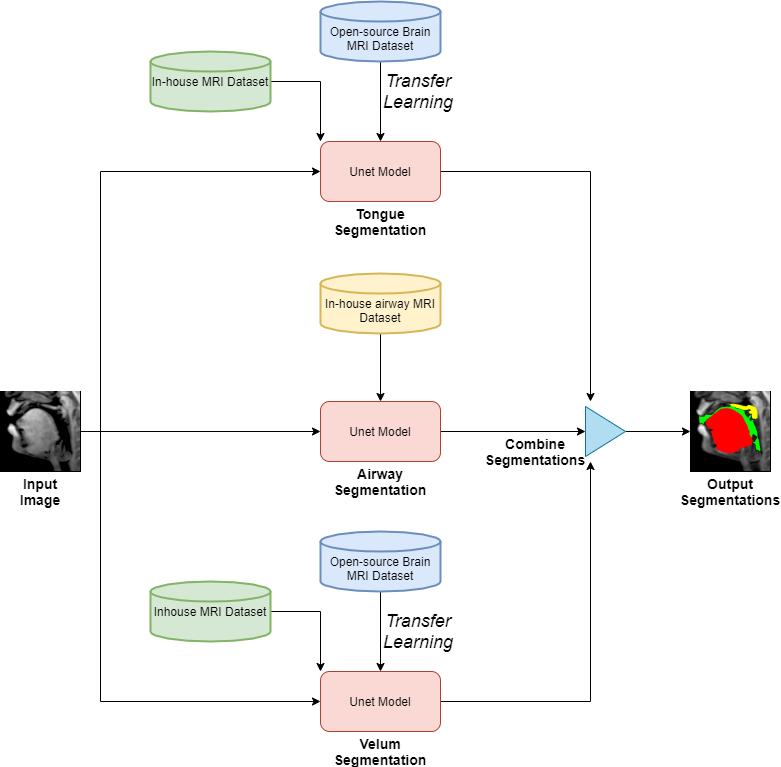
Figure 1 shows the schematic representation of our three stacked U-NETs with hybrid learning. The input to the network is an unlabeled mid-sagittal image, and the output is the labeled image with labeled masks corresponding to segmentation of the tongue, velum, and airway. The network for the tongue and velum segmentation leverage the open-source database of brain tumor MRI segmentation (BRATS)[6], which have manually annotated soft-tissue and brain tumor segmentation of 10,640 images from 274 cases; and the network for segmenting the airway leverage an in-house airway MRI dataset (sequence details below) for which we manually segmented airways in 1000 image frames from 5 volunteers performing a variety of speech tasks (eg. production of za-na-za, loo-lee-la, apa-ipi-upu, counting numbers, and speaking spontaneous speech). All our in-house datasets were acquired on a GE 3Tesla scanner with a fast GRE sequence (midsagittal plane; spatial resolution: 2.7 mm2; ~6 frames/second, FOV: 20x20 cm2). The two pretrained model weights were transferred to the individual U-NETS in figure 1 and they were further trained from 60 randomly chosen image frames with manual annotations of the tongue, velum on the in-house speech dataset. On the other hand the airway segmentation U-NET is directly trained on our in-house airway dataset with 1000 images. The base model had 39 layers and transferring was done for 35 layers. Rest of the 4 layers were made trainable and three more layers were added to that. We used 5 images for validation and 20 images for testing which had a variety of speech postures. The relevant training parameters were number of epochs = 20, batch size = 2, learning rate =0.0001, dropout rate = 0.5, and a choice of the adaptive moment estimation (ADAM) optimizer. The network architecture was implemented using Keras with TensorFlow backend on an Intel Core-i7 8700CK, 3.70 GHz 12 core CPU machine. The training time for individual U-NETS was 20 minutes. Finally, the performance of our stacked U-net is evaluated against manual annotations from user1 (termed as reference) in terms of Dice similarity(D). We also compare against manual annotations from a second user (termed as user 2). Both the users are graduate students experienced in image processing and interpreting anatomy in speech MRI datasets.Results
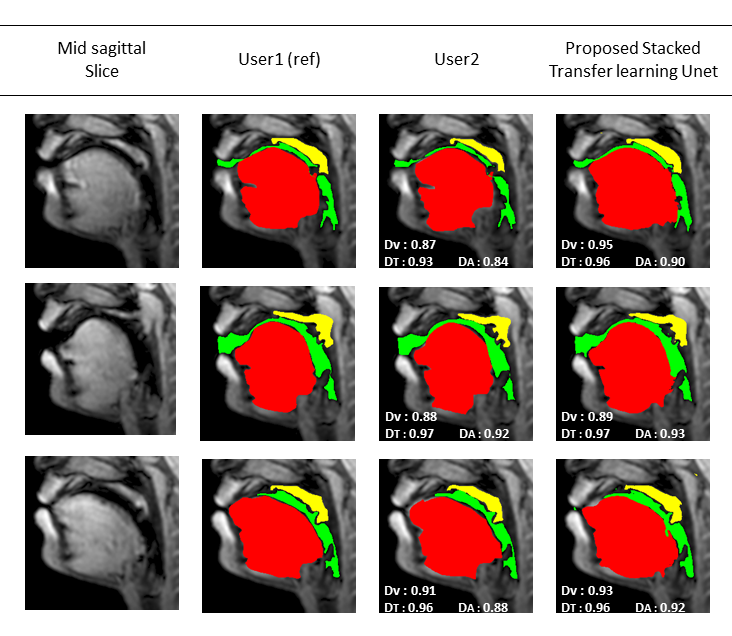
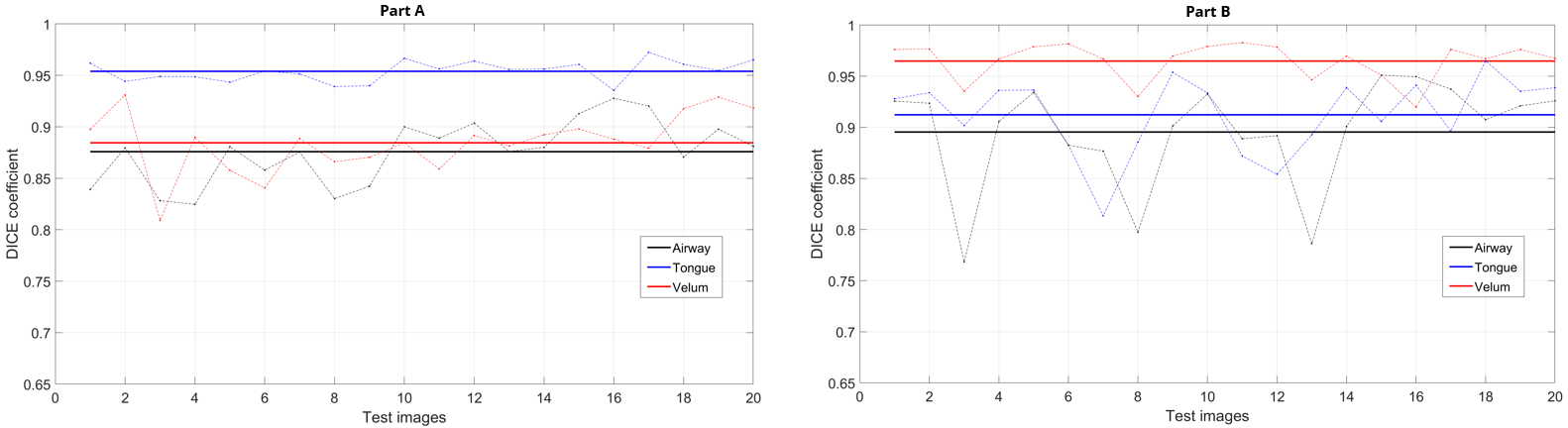
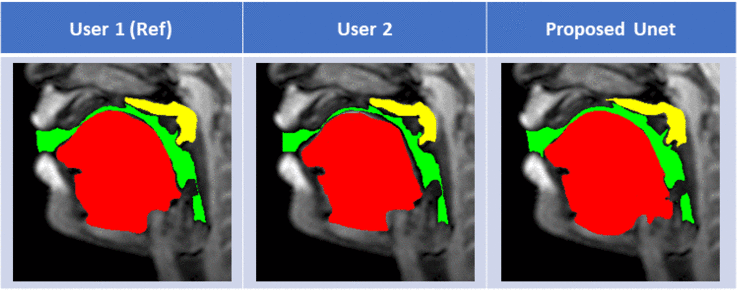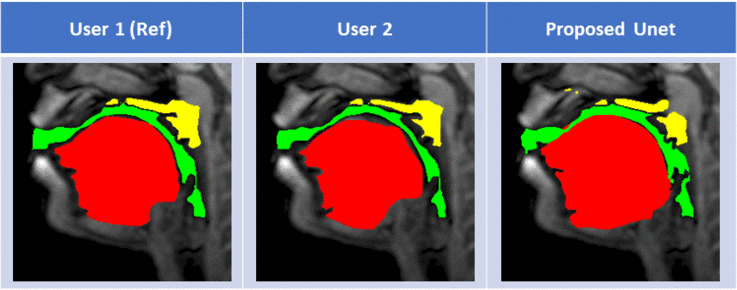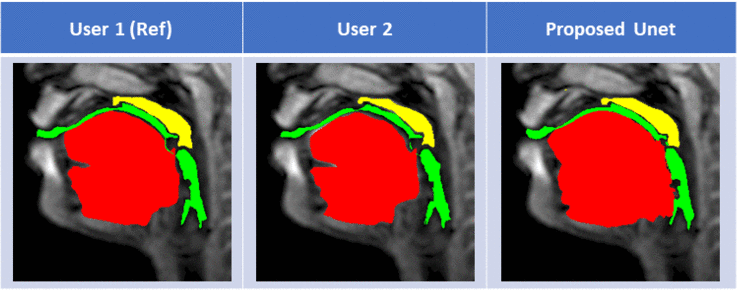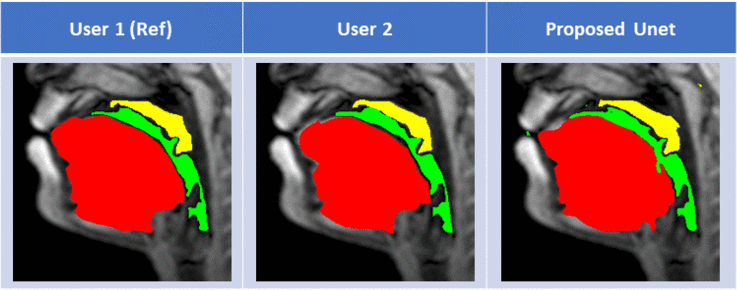
Figure 2 shows representative segmentations for a few frames with different speech postures on the testing set. We observe good segmentations with the proposed stacked U-NET with transfer learning and is comparable to segmentations from a second user. Figure 3 shows the DICE similarity numbers for the proposed net-user 1 segmentations and user1-user2 segmentations over the 20 testing images. It can be observed that different articulators have varying DICE score values depending on the complexity of segmentation. Such variations can also be observed between two of the manual annotators. We specifically observe lower DICE for airway segmentation in our model because of estimating disjoint masks, which increases the complexity of segmentation. Finally, figure 4 shows a visual animation of the segmentation between our network and manual annotator for dynamic speech. On all the test images, U-NET showed a faster processing time. The mean processing times were 0.21sec/image for U-NET, and the average processing times for user2 was ~3 mins/image.Conclusion
We successfully demonstrated multiple articulator segmentation from speech MRI images using stacked U-NET architecture which leveraged pretrained models, and only needs new manual annotations from limited samples as few as 60 images to segment the tongue and velum. The final trained network enabled us to do the end-to-end mapping between articulators within a shorter processing time of 0.21 sec/frame on a modern CPU with 12 cores.Acknowledgements
This work was conducted on an MRI instrument funded by NIH-S10 instrumentation grant: 1S10OD025025-01.References
[1] S. G. Lingala, B. P. Sutton, M. E. Miquel, and K. S. Nayak, “Recommendations for real-time speech MRI,” Journal of Magnetic Resonance Imaging, vol. 43, no. 1. pp. 28–44, 2016.
[2] A. D. Scott, M. Wylezinska, M. J. Birch, and M. E. Miquel, “Speech MRI: Morphology and function,” Physica Medica, 2014.
[3] J. L. Perry, B. P. Sutton, D. P. Kuehn, and J. K. Gamage, “Using MRI for assessing velopharyngeal structures and function,” Cleft Palate-Craniofacial J., 2014.
[4] S. Erattakulangara and S. G. Lingala, “Airway segmentation in speech MRI using the U-net architecture,” in IEEE International Symposium on Biomedical Imaging (ISBI), 2020, p. to appear.
[5] M. Ruthven, M. E. Miquel, and A. P. King, “Deep-learning-based segmentation of the vocal tract and articulators in real-time magnetic resonance images of speech,” Comput. Methods Programs Biomed., 2021.
[6] B. H. Menze et al., “The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS),” IEEE Trans. Med. Imaging, 2015.
Figures