3264
Deep-learning-based noise reduction incorporating inhomogeneous spatial distribution of noise in parallel MRI imaging1Healthcare Business Unit, Hitachi, Ltd., Kokubunji-shi, Japan
Synopsis
To reduce inhomogeneous noise caused by parallel imaging, we developed a deep-learning-based noise reduction method that incorporates spatial distribution of noise. For noise distribution we used a g-factor map segmented into high and low g-factor regions. We reduced the noise by using a different optimized network in each region. Finally, a denoised image was generated by combining the two denoised regions. Denoised brain images demonstrated improved signal to noise ratio (SNR) and mean square error (MSE) between denoised and full sampling images throughout the brain regions. Our method was able to reduce the inhomogeneous noise proportional to the noise intensity.
Introduction
Deep-learning-based noise reduction by image postprocessing in MRI is advantageous due to the simplicity of the input and because it is less dependent on measurement systems [1]. However, recent studies related to deep-learning-based image postprocessing do not incorporate the inhomogeneous spatial distribution of noise caused by parallel imaging [2-5]. In particular, parallel imaging with a higher acceleration rate causes much higher noise in the central region of reconstructed images compared with a peripheral region, so that the optimal noise reduction throughout all regions might be difficult by a single convolutional neural network (CNN). To reduce the inhomogeneous noise, we developed a noise reduction method by using multiple CNNs optimized for noise intensity.Methods
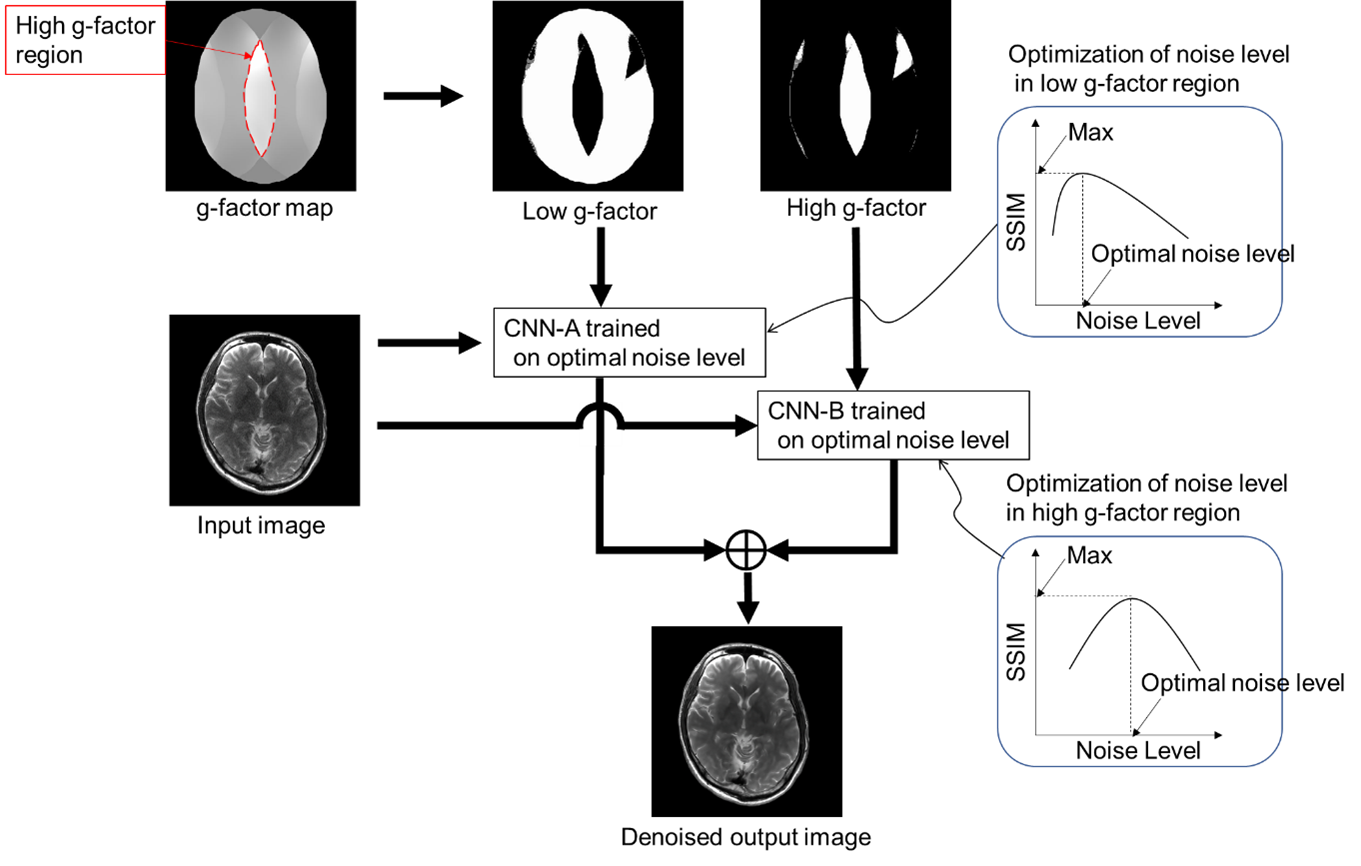
Our proposed noise reduction method, multi-adaptive CNN reconstruction (MA-CNNR), is shown in Figure 1. In parallel imaging, a geometry factor (g-factor) map is generated to reconstruct an image, and the high and low g-factor values correspond to high and low noise intensity, respectively. We used the g-factor map as the spatial distribution of noise and segmented it into two regions, high and low g-factor regions. We reduced the noise in the regions by using optimal multiple CNNs for each noise level. To optimize CNNs, we generated multiple output images denoised by a single CNN trained on a different noise level, and then we obtained optimal noise levels with which structural similarity index measures (SSIMs) between the denoised input and full sampling images in high and low g-factor regions were maximum, respectively. Finally, a denoised image was generated by combining the two regions denoised by CNN-A and CNN-B with the optimal noise levels. A super resolution CNN (SRCNN) was used as the CNN [6]. The training data set was generated from T2 and T1 weighted brain images of four volunteers measured by 3T MRI (Hitachi, Ltd). A target image was reconstructed from full sampling data, and a noisy image was generated by adding Gaussian noise to the target image. One volunteer’s image was denoised by the CNN trained on the data set of other three volunteers. Input T2 and T1 weighted brain images (512×512×19) were generated by parallel imaging reconstruction with acceleration rate (R) of 3 and 4 [7]. The human brain images were obtained in accordance with the standards of the internal review board of the Research & Development group, Hitachi, Ltd., following receipt of written informed consent.Results
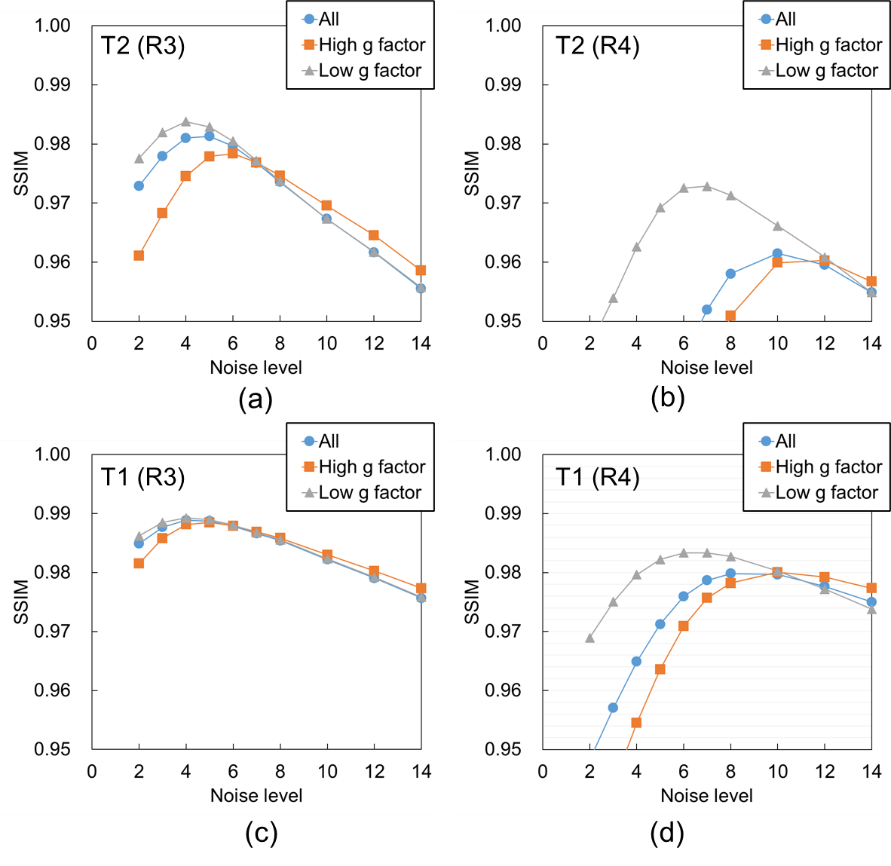
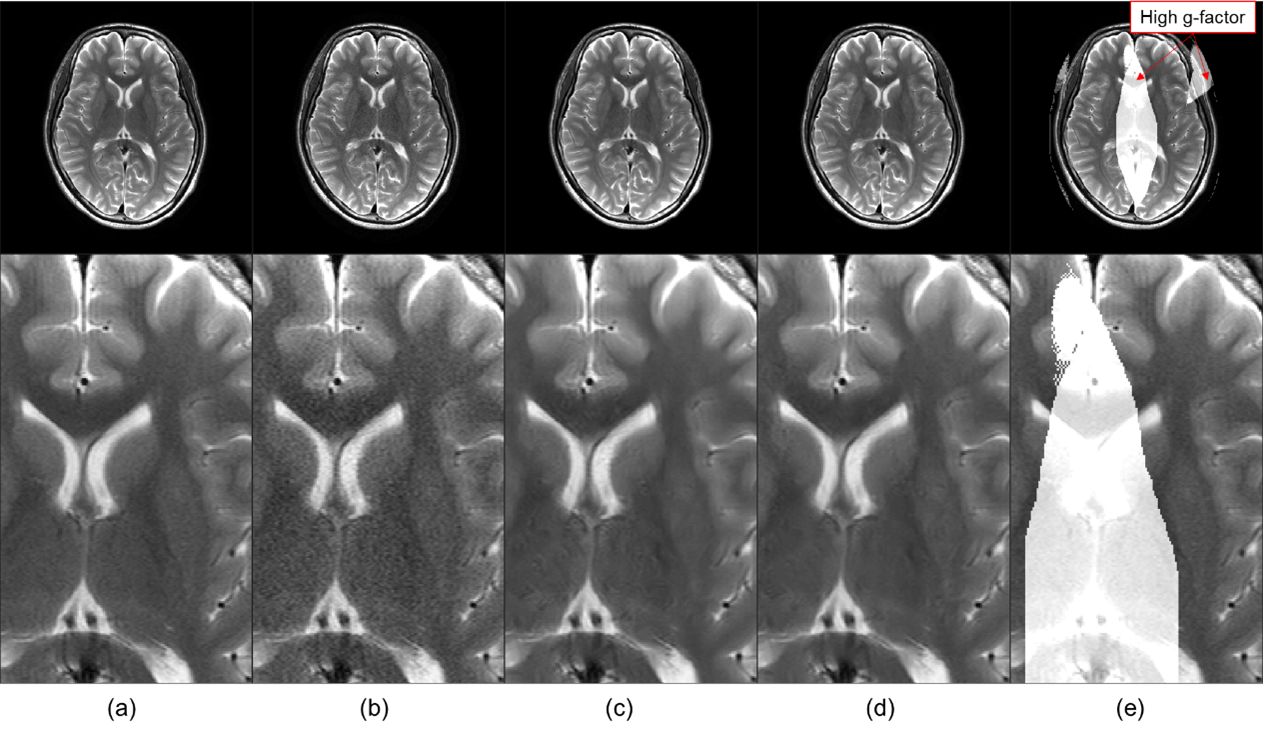
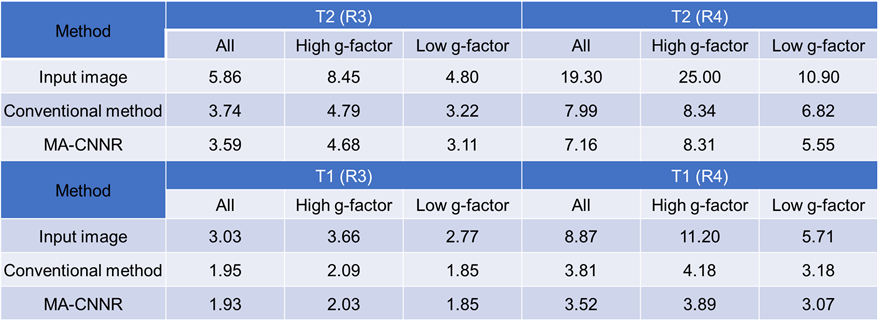
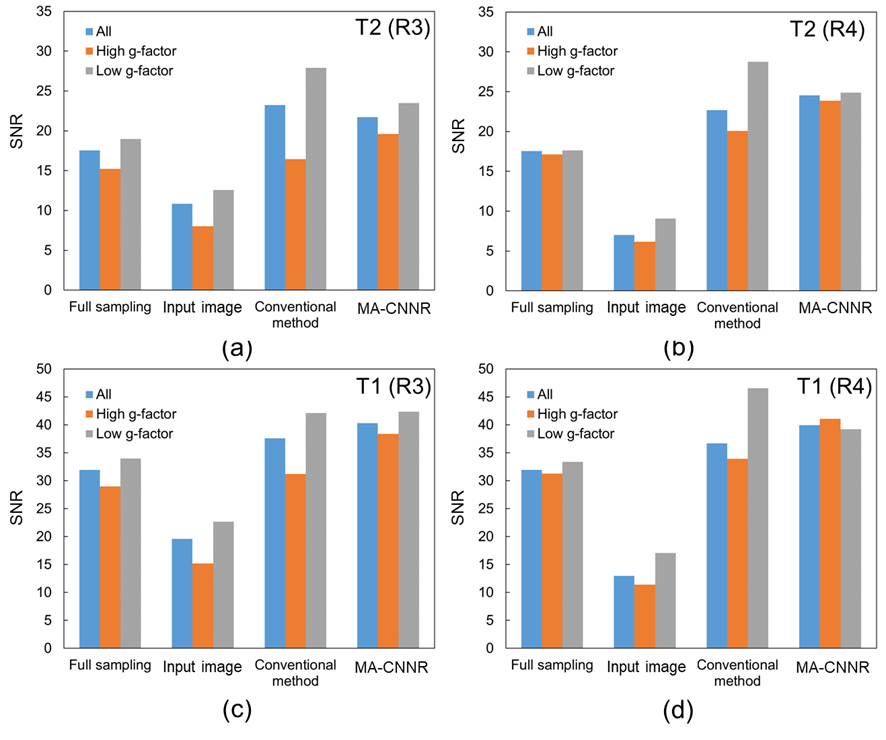
Figure 2 shows the mean SSIM for each noise level. For the T2 weighted image with R of 3, as shown in Figure 2 (a), the SSIM obtained in all regions and in the high and low g-factor regions were the highest when the noise levels were 5, 6, and 4, respectively. Thus, CNN-A and CNN-B for T2 with R of 3 were trained on noise levels 4 and 6, respectively. For comparison, we refer to noise reduction using a single CNN trained on a noise level of 5 as the conventional method below. Similarly, the noise levels for training CNN-A and CNN-B in other cases were determined for maximized SSIM from Figure 2 (b) to (d). Figure 3 shows T2 weighted brain images. The conventional method and MA-CNNR both reduced noise throughout the regions, as shown in Figure 3 (c) and (d), respectively. However, MA-CNNR further reduced the noise in the center (high g-factor region) compared with the conventional method, while MA-CNNR maintained the spatial resolution in the peripheral (low g-factor) region. Table 1 shows the mean square error (MSE) between the denoised input and full sampling images. MA-CNNR improved the MSE compared with the conventional method. The conventional method and MA-CNNR improved the signal to noise ratio (SNR) compared with the images without denoising, as shown in Figure 4. The improved ratios of SNR compared with the input image in the high g-factor regions improved from 2.0 to 3.2 with the conventional method and from 2.4 to 3.8 with MA-CNNR. Meanwhile, the improved ratios of SNR in the low g-factor regions improved from 1.8 to 3.1 with the conventional method and from 1.8 to 2.7 with MA-CNNR. A comparison of the SNRs of T2 and T1 weighted images showed that the SNRs of the T2 input image were lower than those of T1. At a higher noise condition with R of 4 in the high g-factor region, the improved ratio (3.8) of SNR with MA-CNNR for T2 was higher than that (3.5) for T1. Thus, MA-CNNR yielded a more optimal SNR in the higher noise region.Discussion
We confirmed the optimal noise levels were different between high and low g-factor regions and applied the CNNs with optimal noise levels to each region. As a result, MA-CNNR yielded more optimal MSE and SNRs in the high g-factor regions than the conventional method. On the other hand, the conventional method improved the SNRs in the low g-factor regions more than MA-CNNR. However, the improved MSE values in the low g-factor regions with MA-CNNR demonstrated that the higher SNR in the low g-factor regions oversmoothed the image when the conventional method was used.Conclusion
Brain images denoised with MA-CNNR demonstrated improved MSE and SNR throughout the brain regions.Acknowledgements
References
1. Lin DJ, Johnson PM, Knoll F, et al. Artificial Intelligence for MR Image Reconstruction: An Overview for Clinicians. J Magn Reson Imaging. 2020; 10.1002/jmri.27078.
2. Jiang D, Dou W, Vosters L, et al. Denoising of 3D magnetic resonance images with multi-channel residual learning of convolutional neural network. Jpn J Radiol. 2018; 36: 566–574.
3. Kawamura M, Tamada D, Funayama S, et al. Accelerated Acquisition of High-resolution Diffusion-weighted Imaging of the Brain with a Multi-shot Echo-planar Sequence: Deep-Learning-based Denoising. Magn Reson Med Sci. 2020; 10.2463/mrms.tn.2019-0081.
4. Rao GS, Srinivas B, et al. De-Noising of MRI Brain Tumor Image using Deep Convolutional Neural Network. Proceedings of International Conference on Sustainable Computing in Science, Technology and Management (SUSCOM). 2019.
5. Kidoh M, Shinoda K, Kitajima M, et al. Deep Learning Based Noise Reduction for Brain MR Imaging: Tests on Phantoms and Healthy Volunteers. Magn Reson Med Sci. 2020; 19 (3):195-206.
6. Dong C, Loy C, He K, et al. Image Super-Resolution Using Deep Convolutional Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2016; 38 (2): 295-307.
7. Pruessmann KP, Weiger M, Scheidegger MB, et al. SENSE: sensitivity encoding for fast MRI. Magn Reson Med. 1999; 42 (5): 952-62.
Figures