3253
Deep Image Synthesis for Extraction of Vascular and Gray Matter Metrics1Computer Science, Bishop's University, Sherbrooke, QC, Canada
Synopsis
One of the main strengths of MRI is the wide range of soft tissue contrasts which can be obtained using different sequence parameters. T1-weighted-images provide exquisite contrast between gray/white matter but fail to capture arterial vessels. Here we experiment with deep-learning for image synthesis, to synthesize a time-of-flight-(TOF) angiogram based on T1 contrast image. We then compare arterial diameters from synthesized TOF with ground-truth-TOF diameters. We also synthesize a T1 from a T2, and compare cortical metrics such as thickness, curvature etc. We show that it is possible to obtain vessel diameters from T1, and cortical thick/vol/curv measures from T2.
Introduction
Hundreds of different MRI sequences exist, which allow researchers and clinicians to generate contrast between most tissue types in the body. Typically, only a few sequences are selected per exam, due to time constraints. For example, a study investigating cortical thickness would not acquire a TOF, because arteries are of little interest to this research question. In general, almost every neuroimaging protocol includes a T1-weighted image and many also contain T2. In recent years vascular measures have received increased attention due to implication in various maladies 1, so quantifying vasculature from a large pre-existing corpus of neuroimaging data is desirable, for example, OpenNeuro 2 contains over 450 public datasets with 15,000 participants, almost all datasets have a T1 but only 2 of the 450 datasets have TOF. Deep learning methods have had good success recently in medical image synthesis 3-4,5,6 . Here we investigate the possibility of synthesizing TOF from T1, to see if we could obtain accurate arterial diameters from T1 contrast using deep learning (UNET). We also performed secondary deep learning experiments to synthesize T1 from T2 and examine freesurfer cortical metrics based on synthesized T1.Materials and methods
We used the OpenNeuro’s ‘Forrest’ dataset which contains 20 subjects, all with high-resolution 7-Tesla T1, T2, and TOF images. T1,T2 image matrix are 274×384×384 slices and resolution of 0.7×0.6×0.6 mm. TOF image matrix contains 480×640×163 slices and has 0.3×0.3×0.3 mm.Registration :
the best registration between TOF and T1 could be found by first registering the T2 to the TOF using a 6 degree of freedom (DOF) linear transform by FLIRT FSL 7 and then a second fine-tuning registration using 9 DOF (from T2_in_TOF to TOF again). This second registration input and reference were rough segmentations of arteries in T2 and TOF respectively. We then registered the T1 to the T2 and applied the above two matrices to bring T1 into TOF space.
Model :
We introduce a synthetic model by leveraging deep learning – UNET 8 architecture (Figure 1). The model was trained by feeding the 410 image slices which each slice is a 2D axial T1 image obtained from 10 subjects - and also corresponding raw TOF image slices. The model trained in 300 epochs with 2 Intel® Xeon ®CPU @2.00 GHz with Tesla V100-SXM2-16GB.
Results
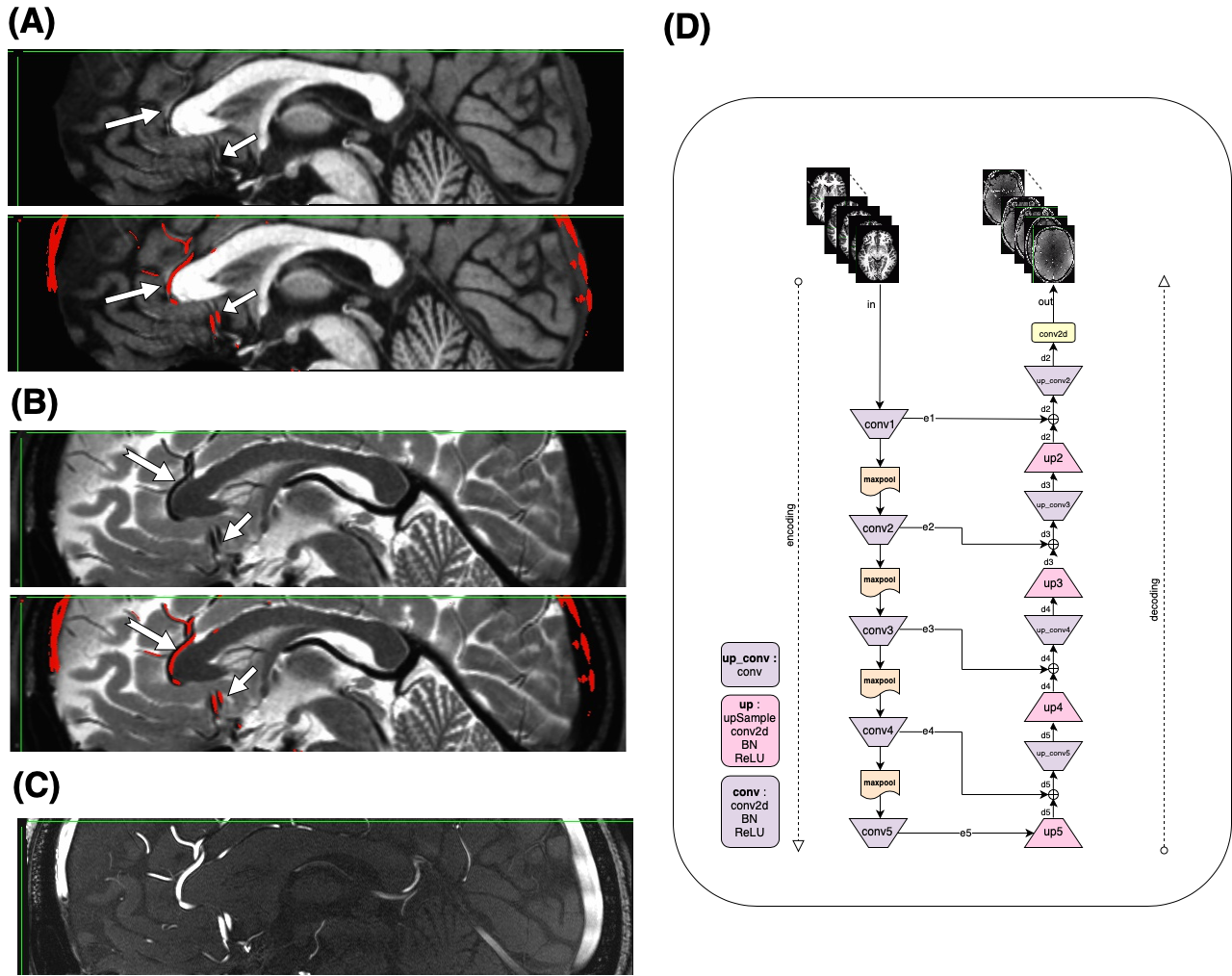
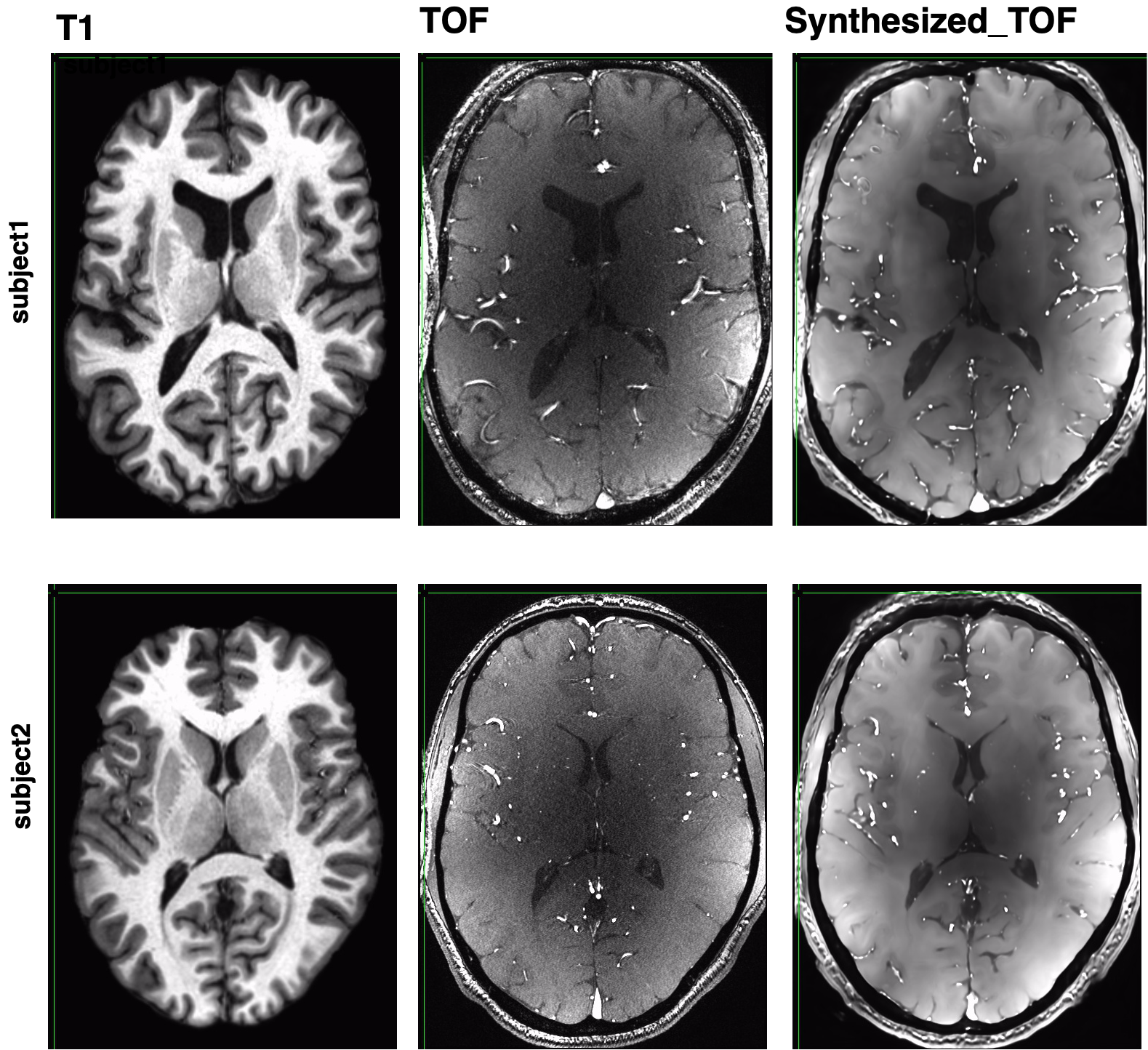
Figure1: motivation – T1 (A), T2 (B), and TOF (C) images show that while each modality highlights a specific tissue type, other features are visible to the naked eye, for example the vessels are clearly visible on both T1 and T2, and the gray/white matter boundary is visible on the TOF. Our goal is to train a deep learning model capable of enhancing these features, to allow us to generate vascular segmentations from T1 or gray matter segmentation from T2. The deep architecture is shown in (D).Figure2 - TOF synthesis results: in Figure 2 top left we show the original T1 which is the input to the network (axial view). In figure 2 middle we show the original TOF which is the ground truth. In figure 2 right we show the synthesized-TOF which is the output of the network. We show 2 representative subjects. The data of these subjects was not used for training the network.
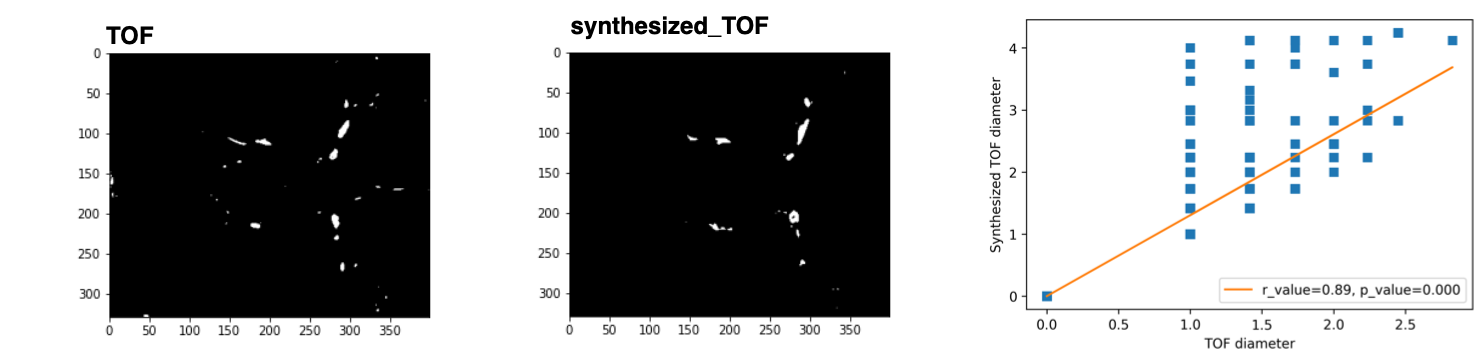
Figure3 - diameter comparison: segmentation from a single axial slice taken from ground-truth (TOF) and synthesized-TOF are shown. Extracting diameter of vessels in this segmentation showed a correlation(0.89) between diameters extracted from TOF and diameters extracted from synthesized-TOF.
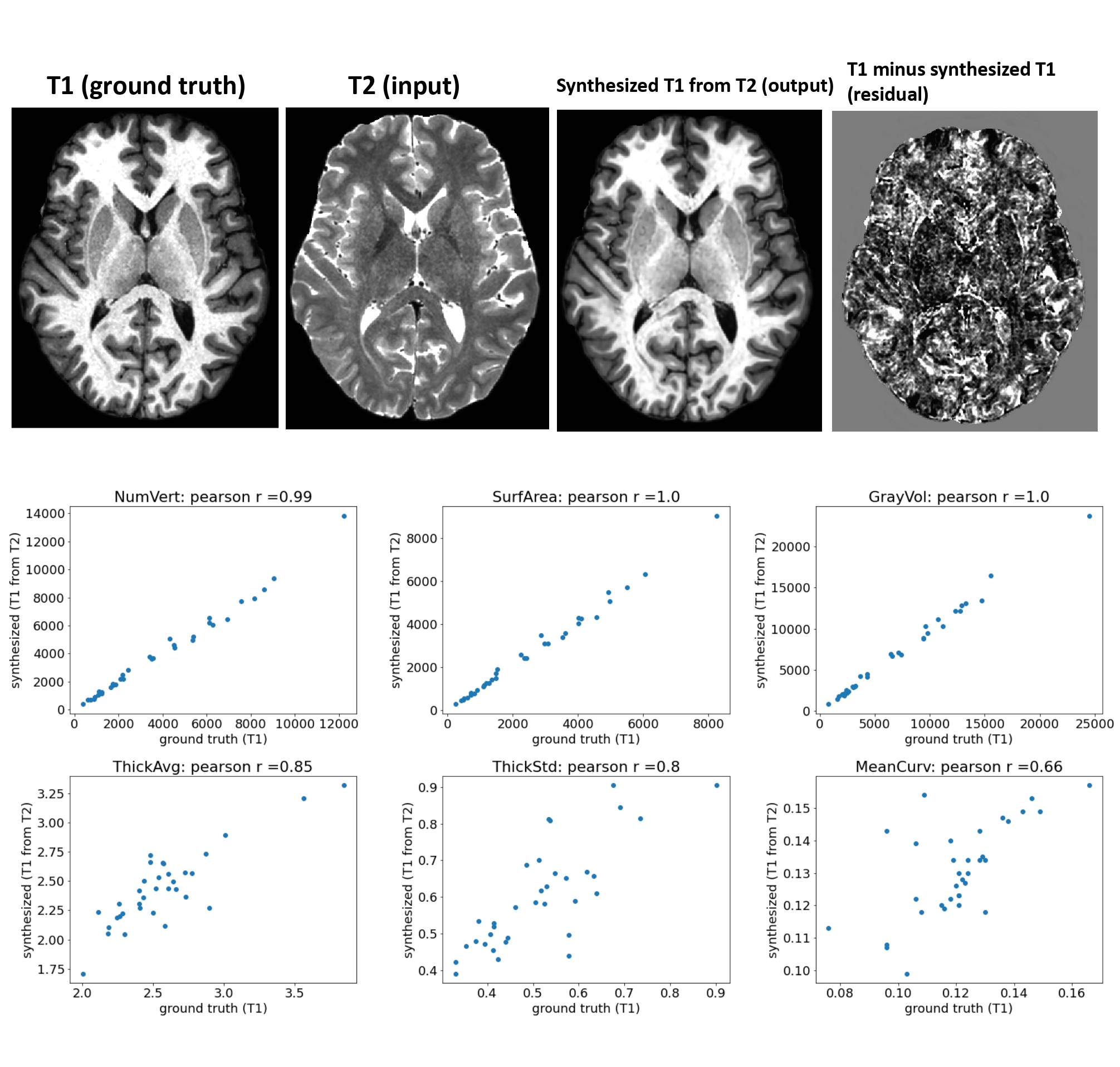
Figure 4: using a similar deep architecture and training parameters, we synthesized T1 image from T2 image. we then computed Freesurfer metrics like cortical surface area, volume, thickness and curvature across Freesurfer cortical regions. Correlating the metrics derived from ground-truth T1 with metrics derived from synthesized-T1 showed good agreement (r=0.99, r=1) for cortical surface area and volume, but poorer (r=0.85, r=0.8, r=0.66) for thickness, thickness std., and mean curvature.
Discussion
Using 2D-UNET architecture, we show it is possible to extract measures of vascular diameter from T1-weighted images and measures of gray matter from T2-weighted images. The fact that arterial diameter can be extracted from T1 image is unsurprising, because arteries are clearly visible on a T1. The details of the arteries in a T1 are different from arteries in TOF, however. Arteries appear brightly on the TOF in all brain areas, while in the T1, arteries are brighter in the brainstem/neck area, but darker and less prominent in more superior brain regions. Arteries are also visible on T2-weighted images (figure1, dark) as well as veins. This may allow for synthesis of arterial trees in pre-existing datasets, to perform additional analysis regarding vascular health. Synthesizing T1 from T2 also showed good agreement with ground-truth Freesurfer cortical metrics. This suggests that T2 contain enough information about both arteries and gray matter to replace the T1 and TOF in future iterations. We should note that the 2D UNET has limitations, here model trained on axial slices but in the future, we plan to move to 3D-UNET to obtain more accurate synthesis results, and also further work is necessary to verify how the model will perform on T1 images acquired in different settings, for example on a 3T scanner.Acknowledgements
NSERC - Natural Science and Engineering Research Council of Canada.References
[1] O’Brien JT, Thomas A. 2015. Vascular dementia. Lancet.
[2] Poldrack RA, Baker CI, Durnez J, Gorgolewski KJ, Matthews PM, Munafò MR, Nichols TE, Poline JB, Vul E, Yarkoni T. 2017. Scanning the horizon: Towards transparent and reproducible neuroimaging research. Nat Rev Neurosci. 18:115–126.
[3] Nie D, Trullo R, Lian J, Petitjean C, Ruan S, Wang Q, Shen D. 2017. Medical image synthesis with context-aware generative adversarial networks. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Springer Verlag. p. 417–425.
[4] Nie D, Trullo R, Lian J, Wang L, Petitjean C, Ruan S, Wang Q, Shen D. 2018. Medical Image Synthesis with Deep Convolutional Adversarial Networks. IEEE Trans Biomed Eng. 65:2720–2730.
[5] Liu X, Jiang D, Wang M, Song Z. 2019. Image synthesis-based multi-modal image registration framework by using deep fully convolutional networks. Med Biol Eng Comput. 57:1037–1048.
[6] Fetty L, Bylund M, Kuess P, Heilemann G, Nyholm T, Georg D, Löfstedt T. 2020. Latent Space Manipulation for High-Resolution Medical Image Synthesis via the StyleGAN. Z Med Phys. 30:305–314.
[7] Jenkinson M, Beckmann CF, Behrens TEJ, Woolrich MW, Smith SM. 2012. FSL. Neuroimage. 62:782–790.
[8] Ronneberger O., Fischer P., Brox T. (2015) U-Net: Convolutional Networks for Biomedical Image Segmentation. In: Navab N., Hornegger J., Wells W., Frangi A. (eds) Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015. MICCAI 2015. Lecture Notes in Computer Science, vol 9351. Springer, Cham. https://doi.org/10.1007/978-3-319-24574-4_28.
Figures