2873
Free-breathing High-resolution Spiral Real-time Cardiac Cine Imaging using DEep learning-based rapid Spiral Image REconstruction (DESIRE)1Biomedical Engineering, University of Virginia, Charlottesville, VA, United States, 2Medicine, University of Virginia, Charlottesville, VA, United States, 3Radiology, University of Virginia, Charlottesville, VA, United States
Synopsis
Cardiac real-time cine imaging is valuable for patients who cannot hold their breath or have irregular heart rhythms. Spiral acquisitions, which provide high acquisition efficiency, make high-resolution cardiac cine real-time imaging feasible. However, the reconstruction for under-sampled non-Cartesian real-time imaging is time-consuming, and hence cannot provide rapid feedback. We sought to develop a DEep learning-based rapid Spiral Image REconstruction technique (DESIRE) for spiral real-time cardiac cine imaging with free-breathing, to provide fast and high-quality image reconstruction and make rapid online reconstruction feasible. High image quality was demonstrated using the proposed technique for healthy volunteers and patients.
Introduction
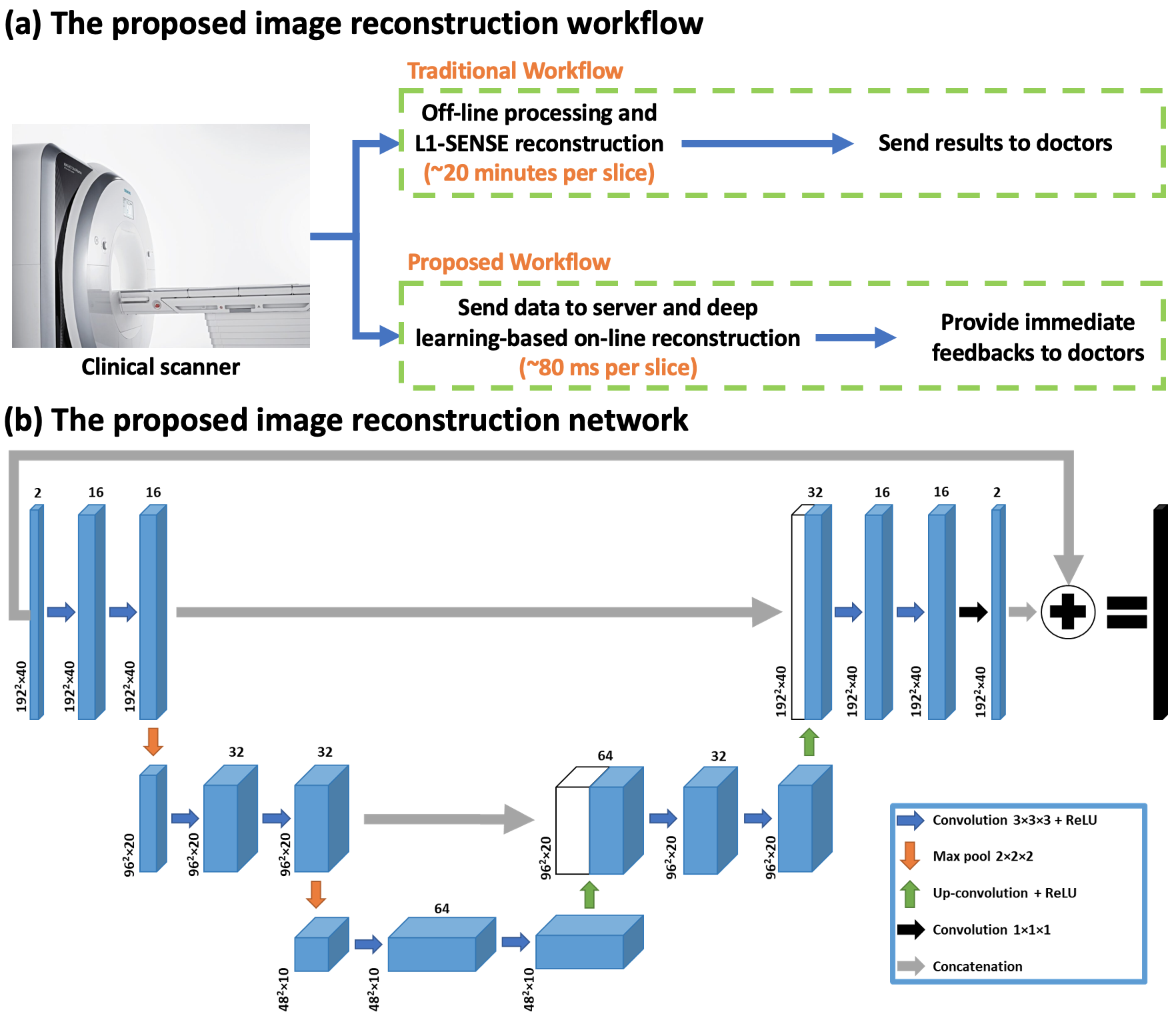
Cardiac magnetic resonance (CMR) real-time cine imaging, which doesn’t require ECG and breath-holding, is more clinically useful than breath-hold cine MRI for patients with impaired breath-hold capacity and/or arrhythmias1. Currently, clinically available real-time imaging techniques using parallel imaging suffer from reduced temporal and/or spatial resolution while techniques using compressed-sensing require long reconstruction times1. Here, we sought to develop real-time cardiac cine imaging using spiral acquisitions and deep learning-based rapid imaging reconstruction, to make high-quality and rapid online reconstruction for high-resolution free-breathing spiral real-time cardiac cine imaging feasible (Figure 1 (a)).Methods
Data Acquisition and Image Reconstruction for the Ground Truth A variable density (VD) gradient echo spiral readout trajectory that was rotated by the golden angle between subsequent TRs was previously used for free-breathing data acquisition on 3 T SIEMENS scanners (MAGNETOM Prisma or Skyra; Siemens Healthineers, Erlangen, Germany)2. The VD spiral had a Fermi‐function transition region with a k‐space density of 0.2 times Nyquist for the first 20% of the trajectory and an ending density of 0.02 times Nyquist. The in-plane resolution was 1.25 mm, with an in-plane acceleration factor of approximately 8. Each spiral readout had a length of 5 ms and the TR/TE = 7.8/1 ms. The data acquisition was free-breathing continuous acquisitions. Every 5 spirals were combined into a frame which led to a temporal resolution of 39 ms. A slice thickness of 8 mm was adopted and 2D image series was acquired.The ground truth for network training was generated using the non-Cartesian spiral L1-SENSE reconstruction3,4: $$\underset{x}{\operatorname{argmin}}\left\|F_{u} S x-y\right\|_{2}^{2}+\lambda\|\Psi x\|_{1}$$ where $$$x$$$ is the dynamic image series to be reconstructed, $$$S$$$ is the coil sensitivity map estimated from the temporal average image using a method described by Walsh et al5, $$$F_u$$$ is the inverse Fourier gridding operator that transforms the Cartesian image space to spiral k-space6, $$$y$$$ is the acquired spiral k-space data, $$$\Psi$$$ is the finite time difference sparsifying operator, $$$I$$$ is the identity matrix and balances between parallel-imaging data consistency and sparsity. $$$\lambda=0.06M_0$$$ was chosen as a tradeoff between image quality and temporal fidelity, where $$$M_0$$$ was the maximal magnitude value of the NUFFT images.
Prior to image reconstruction, coil-selection2 was performed on the NUFFT-gridded6 multi-coil image series at each slice location to reduce streaking artifacts.
Image Reconstruction Network Figure 1(b) illustrates the proposed 3D U-Net7 based image reconstruction network. The inputs to the network were single-channel complex-valued under-sampled dynamic real-time image series gridded by NUFFT from a slice location that were created using optimal coil combination5. The real and imaginary values were concatenated into two channels. The outputs were concatenated real and imaginary dynamic image series.
Experimental Setup During training, images were cropped into 192×192×40(Frames) to save GPU memory. This corresponds to 1.5 seconds of cine data which would capture a single beat for heart rate above 40 BPM. Each dynamic image series was normalized to 0-1. The training of the network was conducted using PyTorch on a single NVIDIA Tesla P100 GPU (12 GB memory) for 150 epochs with a batch size of 4 and an L1 loss (absolute error) function using an ADAM optimizer.
92 slices from 8 subjects were used for training. Another 15 slices from 15 subjects were used for testing.
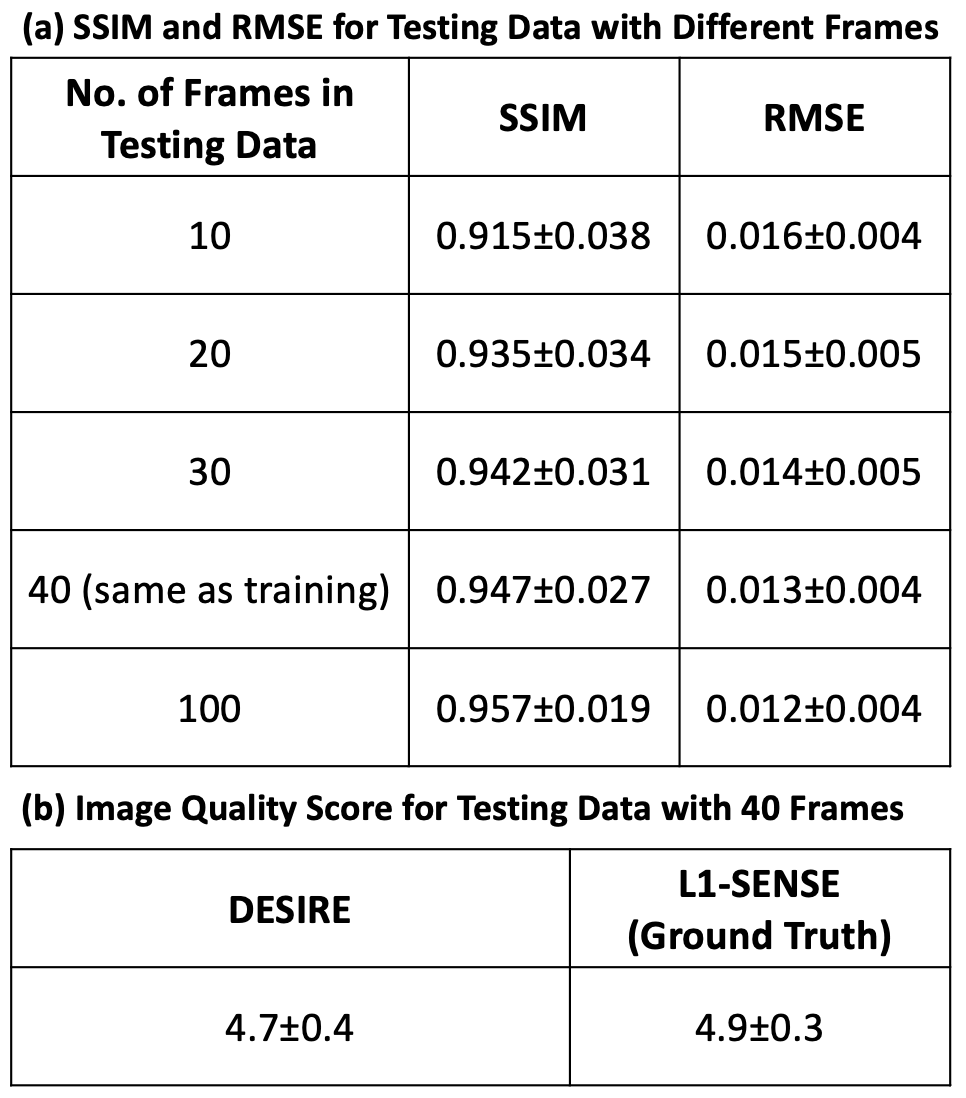
Evaluation with Varying Input Data Length To understand whether the model perform similarly for different lengths of input data, 10 frames, 20 frames, 30 frames, 40 frames (same as training data) and 100 frames were fed into the trained model. This was performed to mimic the clinical scenario where different lengths of data may be used.
Image Analysis Testing data with different number of frames was reconstructed using both DESIRE and L1-SENSE. Both structural similarity index (SSIM)8 and root mean square error (RMSE) for the images reconstructed using DESIRE were assessed with respect to the ground truth. Images with 40 frames were also blindly graded by an experienced cardiologist (5, excellent; 1, poor). As the visual scoring was graded on an ordinal scale, a non-parametric Wilcoxon signed-rank test was conducted to compare the reconstruction difference between DESIRE and the ground truth (L1-SENSE).
Results
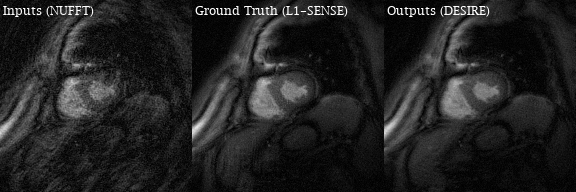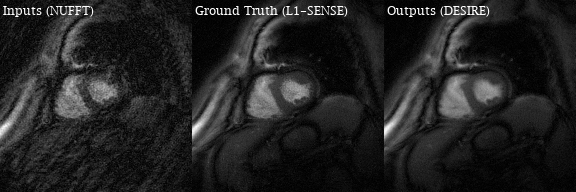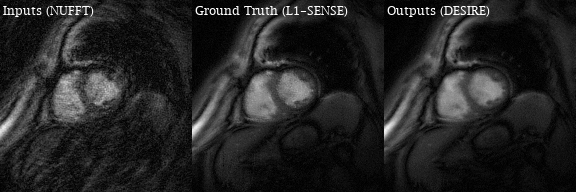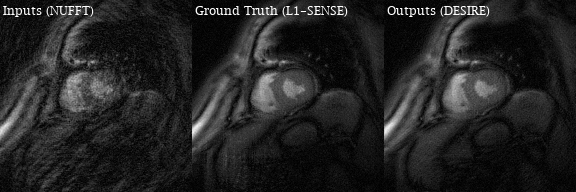
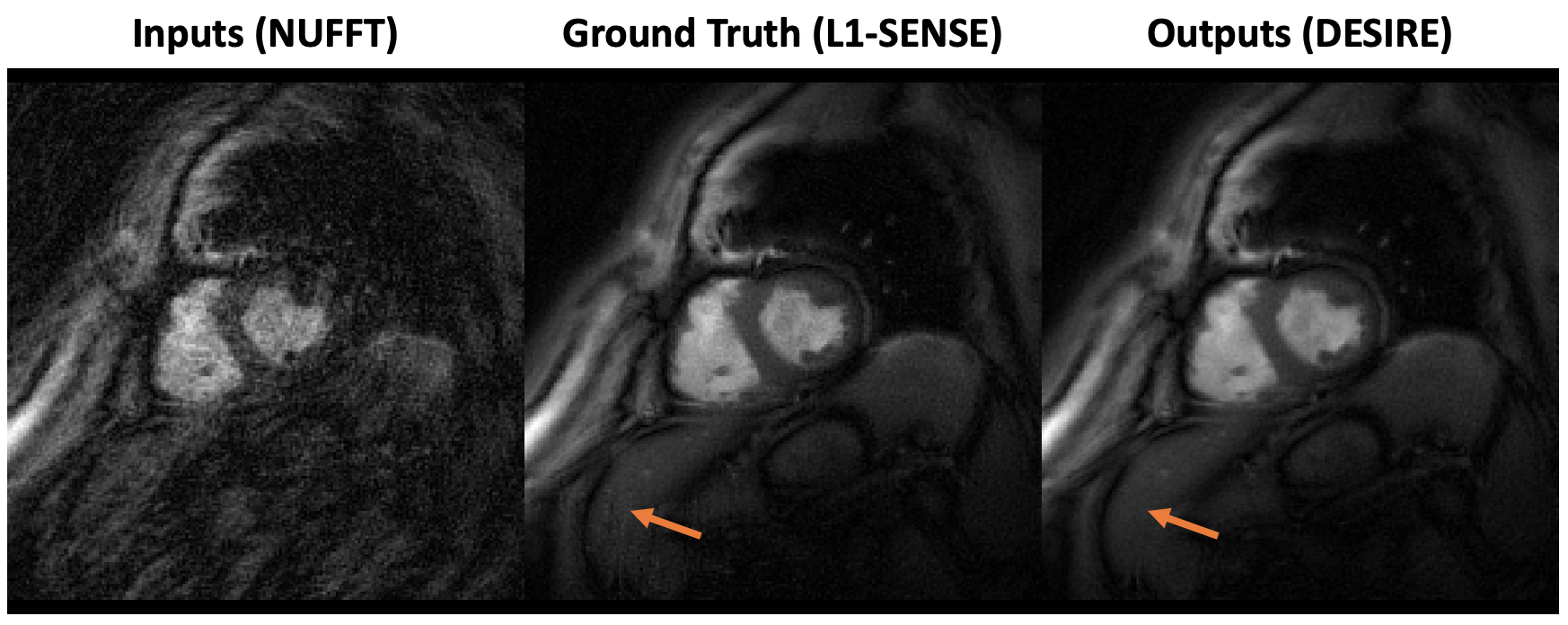
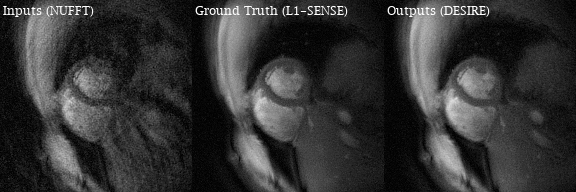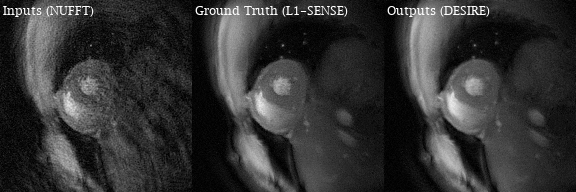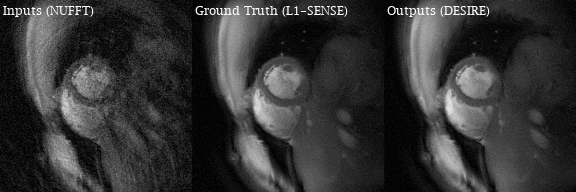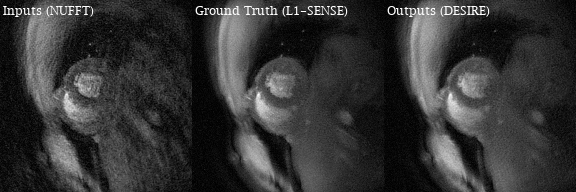
Excellent reconstruction performance using the proposed DESIRE technique was demonstrated. Video 1 shows an example case from a patient with premature ventricular contractions. Figure 2 shows one of the frames from Video 2. Video 2 shows an example case from a healthy volunteer.Table1 shows the image scores for different lengths of testing data. Although 40 frames were used for training due to GPU memory limitation, different number of frames in the testing data all show good performance. There was no difference in image quality scores between DESIRE and L1-SENSE (p=0.125).
The reconstruction time for 40 frames was ~80 ms per slice on a NVIDIA Tesla P100 GPU, while the reconstruction time of using L1-SENSE with 30 iterations on an Intel Xeon CPU (2.40 GHz) was ~20 minutes per slice.
Discussion and Conclusion
The proposed image reconstruction network (DESIRE) enabled fast and high-quality image reconstruction for high-resolution spiral real-time cardiac cine imaging. Further validation will be required. The rapid image reconstruction at scanner will advance the clinical translation and improve the diagnosis efficiency.Acknowledgements
This work was supported by Wallace H. Coulter Foundation Grant.References
1. Feng L, Srichai MB, Lim RP, et al. Highly accelerated real-time cardiac cine MRI using k–t SPARSE-SENSE. Magnetic Resonance in Medicine 2013;70:64–74.
2. Zhou R, Yang Y, Mathew RC, et al. Free-breathing cine imaging with motion-corrected reconstruction at 3T using SPiral Acquisition with Respiratory correction and Cardiac Self-gating (SPARCS). Magnetic Resonance in Medicine 2019;82:706–720.
3. Otazo R, Kim D, Axel L, Sodickson DK. Combination of compressed sensing and parallel imaging for highly accelerated first-pass cardiac perfusion MRI. Magnetic Resonance in Medicine 2010;64:767–776.
4. Feng L, Grimm R, Block KT, et al. Golden-angle radial sparse parallel MRI: Combination of compressed sensing, parallel imaging, and golden-angle radial sampling for fast and flexible dynamic volumetric MRI. Magnetic Resonance in Medicine 2014;72:707–717.
5. Walsh DO, Gmitro AF, Marcellin MW. Adaptive reconstruction of phased array MR imagery. Magnetic Resonance in Medicine 2000;43:682–690.
6. Fessler JA, Sutton BP. Nonuniform fast Fourier transforms using min-max interpolation. IEEE Transactions on Signal Processing 2003;51:560–574.
7. Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv:1505.04597 [cs] 2015.
8. Zhou Wang, Bovik AC, Sheikh HR, Simoncelli EP. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 2004;13:600–612.
Figures