2616
Fast Deep Learning Motion-Resolved Golden-Angle Radial MRI Reconstruction1Medical Physics, Memorial Sloan Kettering Cancer Center, New York, NY, United States, 2Radiology, Memorial Sloan Kettering Cancer Center, New York, NY, United States, 3GE Healthcare, Waukesha, WI, United States
Synopsis
To use deep learning to reconstruct motion-resolved dynamic images from multicoil undersampled radial data without image quality degradation and 800-fold reduction in reconstruction time compared to the iterative XD-GRASP algorithm.
INTRODUCTION
XD-GRASP sorts continuously acquired free-breathing golden-angle radial data into motion-state dimensions using the self-navigation properties of radial imaging and performs motion-resolved reconstruction using temporal compressed sensing [1, 2, 3]. The iterative XD-GRASP reconstruction is computationally expensive and clinical implementation would require significant reductions in reconstruction time [4]. This work proposes to use a deep learning approach named XD-Net to replace the iterative XD-GRASP algorithm and enable reconstruction of motion-resolved 4D images from multicoil undersampled radial data in seconds rather than tens of minutes.METHODS
Data acquisition: Free-breathing 3D abdominal imaging was performed on seven healthy volunteers (without contrast injection) and seven patients (post-contrast injection) on 3T scanners (Discovery MR750 and Signa Premier, GE Healthcare, Waukesha, WI). A prototype T1-weighted golden-angle stack-of-stars pulse sequence [5] with fat suppression was used with the following acquisition parameters: repetition time/echo time (TR/TE) = 3.2/1.4 ms, field of view (FOV) = 300×300×140 mm3 , number of readout points in each spoke = 228, flip angle= 12 °, pixel bandwidth= 651 Hz and spatial resolution =1.6×1.6×5 mm3. A total of 900 spokes were acquired, with a total scan time of approximately 2 minutes.XD-GRASP reconstruction: Ten respiratory motion-states (90 spokes in each state) were generated by sorting the continuously acquired data [1] and iterative XD-GRASP reconstruction was performed to solve the following minimization [1]:
$$ d=argmin‖F.C.d-m‖_2^2+λ‖G.d‖_1 $$,
where $$$F$$$ is non-uniform fast Fourier transform (NUFFT), $$$C$$$ is the n-element coil sensitivity maps, $$$m$$$ is the multi-coil (c coils) radial data sorted into motion states (s states), $$$d$$$ is the reconstructed images with s motion states, $$$G$$$ is the temporal difference transform along the motion dimension, and $$$λ$$$ as regularization parameter that weights the sparsity term relative to data consistency.
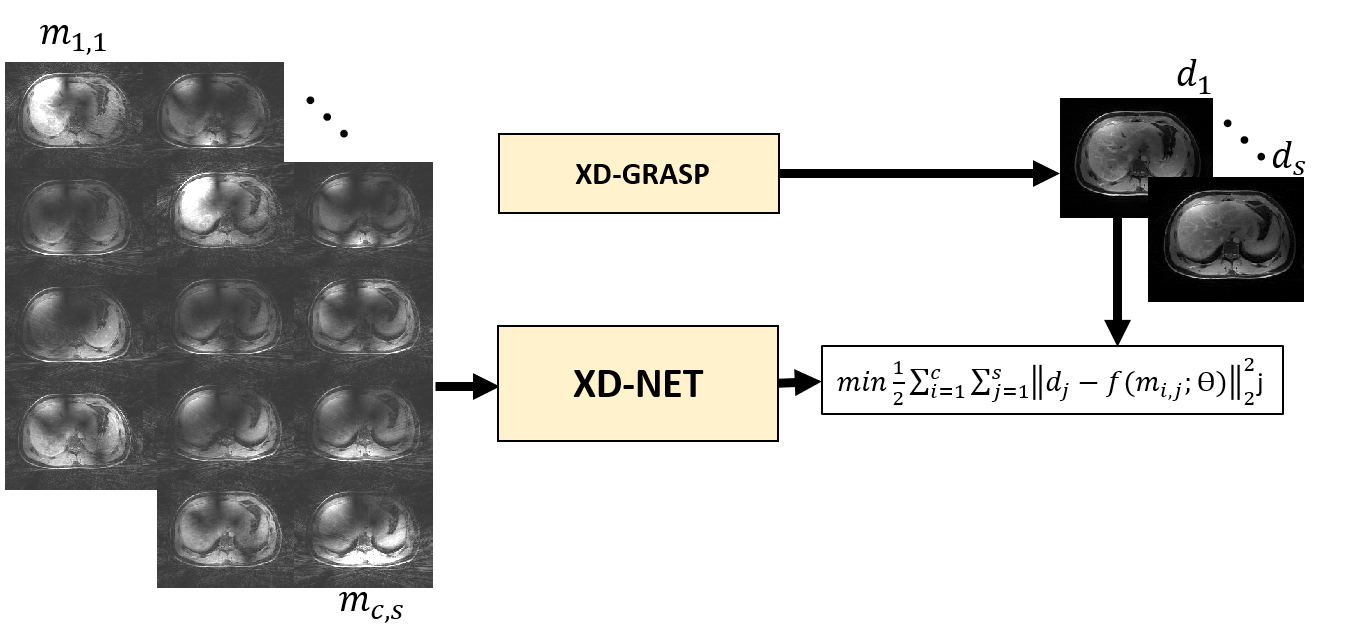
XD-Net reconstruction: A 2D convolutional neural network was designed with 10 layers. The network operates entirely in the image domain and does not use the acquisition operator. Each layer consists of convolution (2×2), activation function (Sigmoid), batch normalization, and max pooling (2×2) on the encoding path (5 layers), and identical architecture was used on the decoding path (5 layers) except max pooling was replaced with deconvolution/upsampling [6]. The network was trained using XD-GRASP reconstruction as a reference. Several runs were performed, where one subject was selected as a test set (array size = 256×256×52×80, where 80 represents the concatenation of 10 motion states and 8 coils), and the remaining cases were augmented (256×256×1696×80) and split into training (80%) and validation (20%). As shown in Figure 1, the input to the network is a multicoil aliased image resulting from applying the NUFFT to each coil and motion state. 4D coil-combined motion-resolved images (output of XD-GRASP) with 10 motion states were used as reference to minimize the training loss function (the equation shown in Figure 1). ADAM optimizer with learning rate of 0.001 was used to find the mapping ($$$f$$$) between then network input and output by updating the network weights ($$$θ$$$). Training was done on NVIDIA TESLA P40 with approximately 270 seconds training time in each epoch and a total number of 200 epochs.
Quantitative evaluation: To quantitatively compare the reference (XD-GRASP) and the proposed XD-Net in two tests cases (one healthy volunteer, one patient with metastasis), peak signal-to-noise ratio (PSNR) and structural Similarity Index (SSIM) were computed. In addition, correlation plot between the reference XD-GRASP and proposed XD-Net reconstruction was calculated.
RESULTS
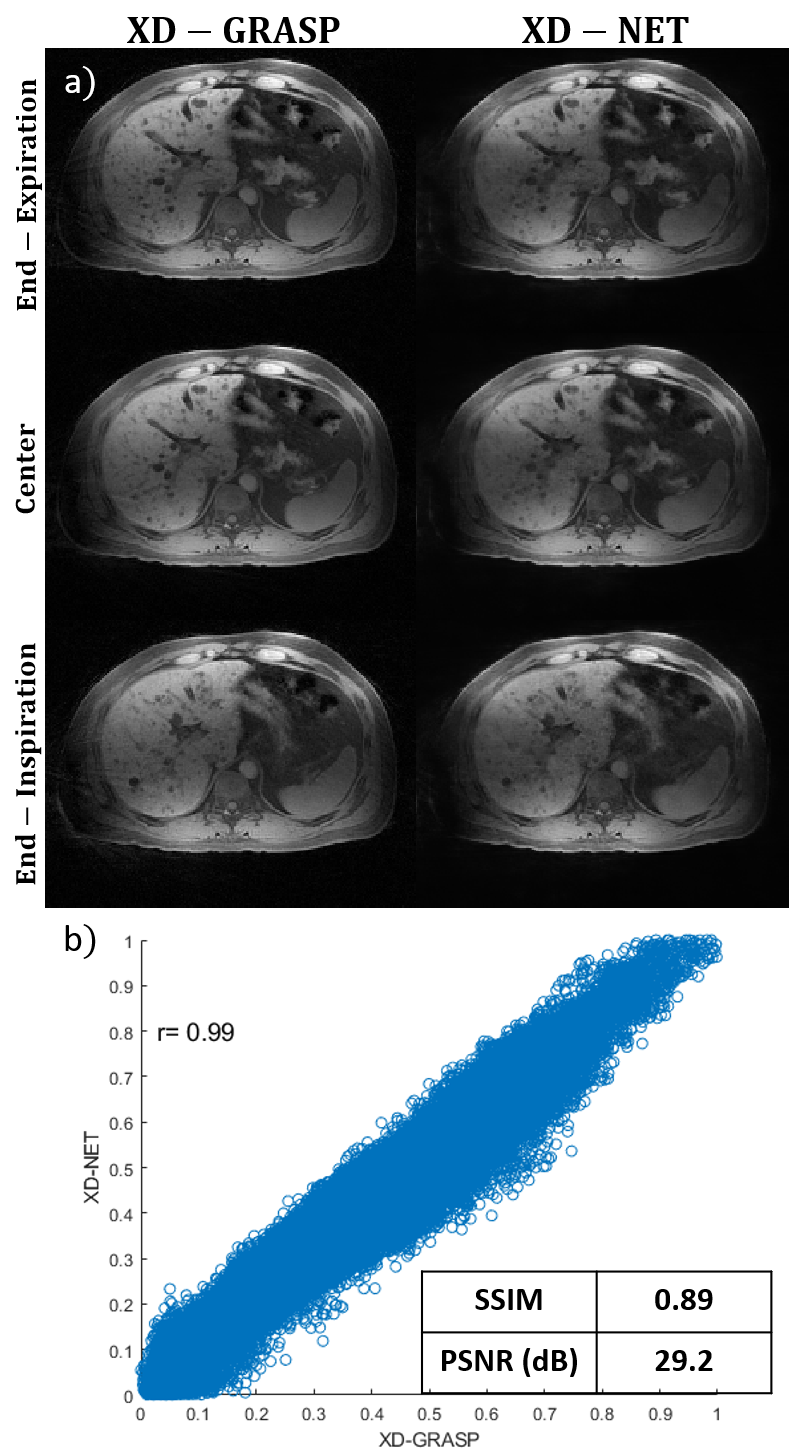
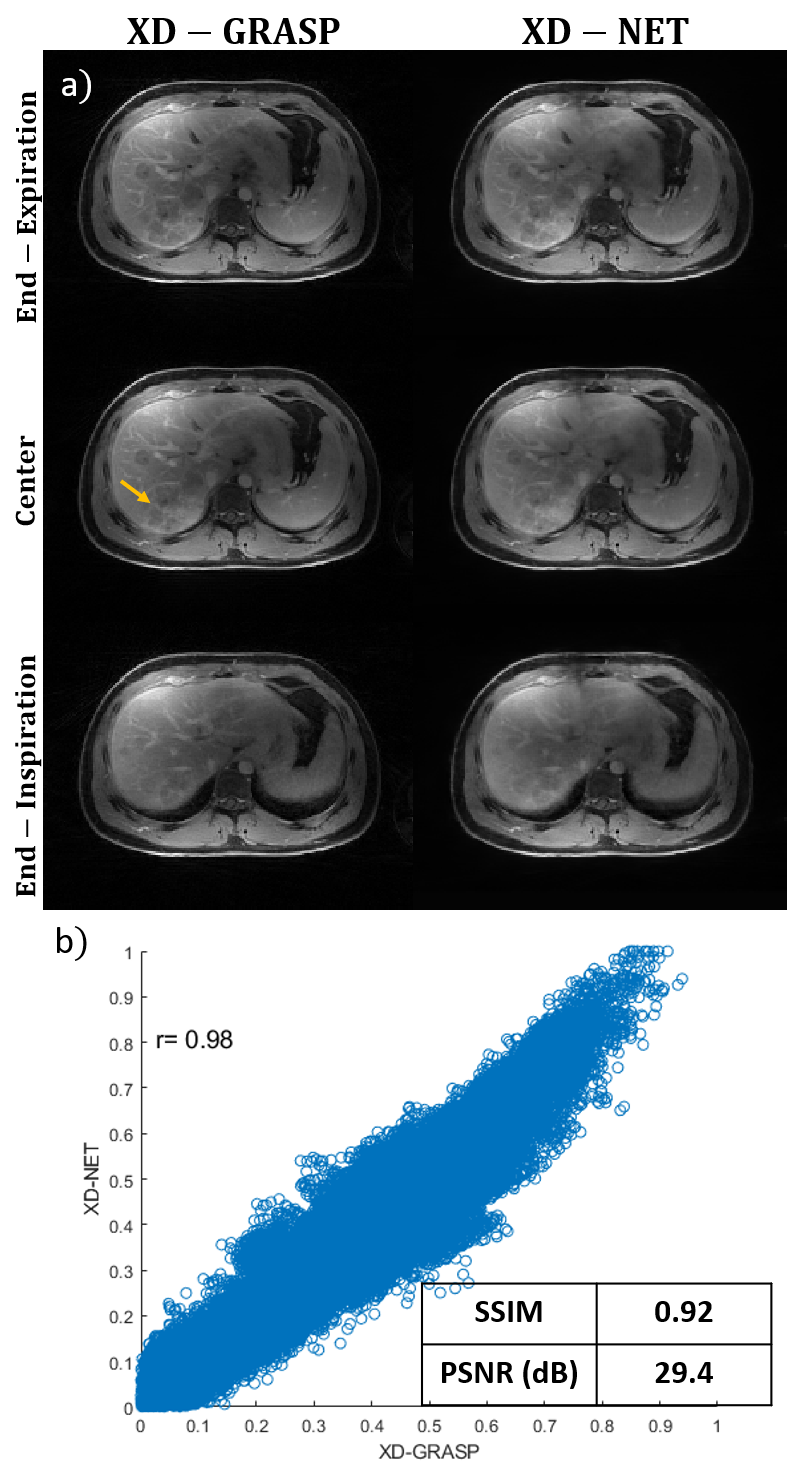
Reconstruction time for XD-GRASP (60 slices) was approximately 138 minutes. Reconstruction time for the proposed XD-Net was only 10 seconds, which represents an 800-fold reduction in reconstruction time. Figure 2 compares the proposed XD-Net with the reference XD-GRASP in a healthy subject and demonstrates good visual qualitative agreement in the three representative motion states (end-expiration, center and end-inspiration) and quantitative agreement (correlation coefficient r=0.99, SSIM= 0.89 and PSNR=29.2). Figure 3 shows a similar comparison, but in a patient case with liver metastasis. Both contrast and image details including the metastasis region (shown by yellow arrow) agree well between XD-Net and reference XDGRASP images in all three representative motion states. Correlation coefficient r=0.98, SSIM=0.92 and PSNR=29.4 also show good quantitative agreement in this patient test case.CONCLUSION
The proposed XD-Net can achieve an 800-fold reduction in reconstruction time compared to the iterative XD-GRASP reconstruction for motion-resolved 4D imaging without image quality degradation. The main reason for this significant speed up in reconstruction efficiency is the removal of the data acquisition operator during reconstruction and to limit the reconstruction process to operations in the image domain. There are a few limitations in this work including the number of training cases which can be increased to further generalize the network and improve image quality. Future work will be focused to use deep learning for the motion sorting component and clinical application of the technique to various motion prone dynamic imaging scenarios. XD-Net is a promising approach to almost real-time reconstruction of motion-resolved data, which will enable robust clinical translation in cases where MRI results are needed shortly after finishing acquisition, such as MRI-guided radiotherapy [4].Acknowledgements
No acknowledgement found.References
[1] Feng, L., Axel, L., Chandarana, H., Block, K.T., Sodickson, D.K. and Otazo, R. (2016), XD‐GRASP: Golden‐angle radial MRI with reconstruction of extra motion‐state dimensions using compressed sensing. Magn. Reson. Med., 75: 775-788. https://doi.org/10.1002/mrm.25665
[2] Chandarana H, Feng L, Ream J, Wang A, Babb JS, Block KT, Sodickson DK, Otazo R. Respiratory Motion-Resolved Compressed Sensing Reconstruction of Free-Breathing Radial Acquisition for Dynamic Liver Magnetic Resonance Imaging. Invest Radiol. 2015 Nov;50(11):749-56. doi: 10.1097/RLI.0000000000000179.
[3] Feng, L., Coppo, S., Piccini, D., Yerly, J., Lim, R.P., Masci, P.G., Stuber, M., Sodickson, D.K. and Otazo, R. (2018), 5D whole‐heart sparse MRI. Magn. Reson. Med, 79: 826-838. https://doi.org/10.1002/mrm.26745
[4] Feng, L, Tyagi, N, Otazo, R. MRSIGMA: Magnetic Resonance SIGnature MAtching for real‐time volumetric imaging. Magn Reson Med. 2020; 84: 1280– 1292. https://doi.org/10.1002/mrm.28200
[5] Zhang T, Wang K, Fisher A, Bayram E. Fast motion robust abdominal stack of stars imaging using coil compression and soft gating. ISMRM 2017, p. 1284
[6] Jafari, R, Spincemaille, P, Zhang, J, et al. Deep neural network for water/fat separation: Supervised training, unsupervised training, and no training. Magn Reson Med. 2020; 00: 1– 15. https://doi.org/10.1002/mrm.28546
Figures