2574
Ultrafast Skull Stripping of Mouse Brain Multi-Modality MR Images Using Deep Learning with Knowledge Transfer1Institute of Science and Technology for Brain-Inspired Intelligence, Fudan University, Shanghai, China
Synopsis
Skull stripping of the mouse brain on MR images is a crucial step for rodent neuroimaging preprocessing. The traditional methods for this task are time-consuming. To solve the problem, we present a deep learning model, U-Net with Nonlocal Position-aware (NPA) block using domain knowledge transfer. The results demonstrated that our end-to-end method achieves high dice scores in several MR modalities with ultrafast processing speed which is two orders of magnitude faster than atlas-based methods. To conclude, our automatic skull stripping approach may provide an alternative to previous complex preprocessing pipelines for high-throughput rodent neuroimaging applications.
Introduction
As one of the most important model organisms, the mouse serves as an irreplaceable bridge for basic research, drug discovery and preclinical translation 1. In many cases, skull stripping acts as the first and indispensable step for neuroimaging preprocessing in the MRI field. However, skull stripping manually is an exhausting and tedious task. Although the toolkits designed for human brain imaging have been well developed 2,3, the existing skull stripping methods have difficulties directly applying to the mouse brain because of the considerable differences in anatomical structure and tissue contrast of the brain between humans and mice. To date, several attempts have been made to develop automatic or semi-automatic mouse brain segmentation methods 4,5. However, these atlas- or registration-based methods are still time-consuming and the performance is not robust as they usually need several steps to complete the task. In this work, we propose an end-to-end deep learning model with knowledge transfer to address above challenges.Methods
Data and PreprocessingThree MR sequences were used to acquire multi-modality MR images, including T2-weighted imaging (T2WI), susceptibility-weighted imaging (SWI) and arterial spin labeling (ASL) with 179, 19, 58 scans covering the whole mouse brain, respectively. The in-plane (intra-slice) resolution of these scans varies from 0.070 mm × 0.070 mm to 0.167 mm × 0.167 mm. The slice thickness (inter-slice) varies between 0.3 mm and 1.0 mm. The ground truth of the brain and non-brain regions were manually annotated by an expert in the field of the anatomy of the brain. A summary of the dataset is shown in Figure 1. In the preprocessing process, each slice was resized to 256×256 matrix size and the intensity distribution was normalized into zero mean and unit variance. The neighboring slices were stacked as a batch before feeding to the model.
Network Model
We constructed a deep learning model, U-Net with Nonlocal Position-aware (NPA) block, to remove non-brain tissue and deploy domain knowledge transfer experiments. The model has an encoder to contract the original input and has a symmetrical decoder to restore the compressed feature maps to initial size 6. Skip connection brings more semantic information to deeper layers in the decoder path. Inspired by intricate yet recurrent patterns in brain tissue from MR images, we deployed the NPA block in the bottleneck of U-Net based on self-attention mechanism to encode global spatial context 7. The network structure is shown in Figure 2.
Experiment Process
We trained our model in two stages. First, we trained on T2WI as the source domain, because T2WI is the most widely used modality to show brain structure. Then we refined our network with other MR modalities as target domain and evaluated our model using the corresponding MR scans.A hybrid loss function combined binary cross-entropy and dice coefficient loss was applied to supervise our model. It can be formulated as follows:
$$Loss_{bce}(y,\hat{y})=-\sum y \cdot log \ \hat{y}+(1-y) \cdot log \ (1-\hat{y})\\Loss_{dice}(y,\hat{y})=(1-\frac{2|y\cap \hat{y}|}{|y|+|\hat{y}|})\\Loss=Loss_{bce}+Loss_{dice}$$
where $$$ \hat{y} $$$ is the labeled image and $$$ y $$$ is the segmentation result. To demonstrate the effectiveness of the knowledge transfer, we trained the model by scratch, without (w/o) transfer and with transfer on target domain. In addition, ablation experiments were performed to demonstrate the performance of NPA.
Results
To illustrate the performance of our proposed approach and how domain knowledge affects the training stage, we implemented five-fold cross-validation in each experiment. As shown in Figure 3, the skull stripping performance of our model gains a high dice score for all the target domain tasks (0.9653 and 0.9455 for SWI and ASL, respectively). Compared with the W/O knowledge transfer, our model with knowledge transfer achieves 3.11% and 8.97% increase in dice score, respectively. The significantly lower dice score in U-Net (0.8558 on without transfer group and 0.9455 on with transfer group in ASL modality) further indicates significance of reused knowledge in cross-domain segmentation tasks (Figure 4). Meanwhile, as shown in Figure 5, the ablation experiment reveals network without NPA suffers 0.48% decrease in dice score and more likely lead to mis-classification, such as false positive regions, indicating that this attention mechanism has strong spatial discrimination capacity. The results of Figure 3 and 4 demonstrated that our model has robust generalization ability on different modalities. Additionally, as shown in Figure 5, our model has ultrafast processing speed for MR images (only 4 milliseconds per slice) which is two orders of magnitude faster than atlas-based methods 4,8.Acknowledgements
This study was supported in part by grants from the Shanghai Municipal Science and Technology Major Project (2018SHZDZX01), Three-year action plan for key global partners (IDH6282008/050/001/004) and the National Natural Science Foundation of China (81873893).References
- Oh, Seung Wook, et al. "A mesoscale connectome of the mouse brain." Nature 508.7495 (2014): 207-214.
- Friston, K.J., et al.: Statistical parametric maps in functional imaging: a general linear approach. Human brain mapping 2(4), 189-210 (1994).
- Jenkinson, M., et al.: Fsl. Neuroimage 62(2), 782-790 (2012).
- Delora, A., et al.: A simple rapid process for semi-automated brain extraction from magnetic resonance images of the whole mouse head. Journal of neuroscience methods 257, 185-193 (2016).
- Pagani, M., et al.: Semi-automated registration-based anatomical labelling, voxel based morphometry and cortical thickness mapping of the mouse brain. Journal of neuroscience methods 267, 62-73 (2016).
- Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015).
- Wang, Xiaolong, et al. "Non-local neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- Eskildsen, Simon F., et al. "BEaST: brain extraction based on nonlocal segmentation technique." NeuroImage 59.3 (2012): 2362-2373.
Figures
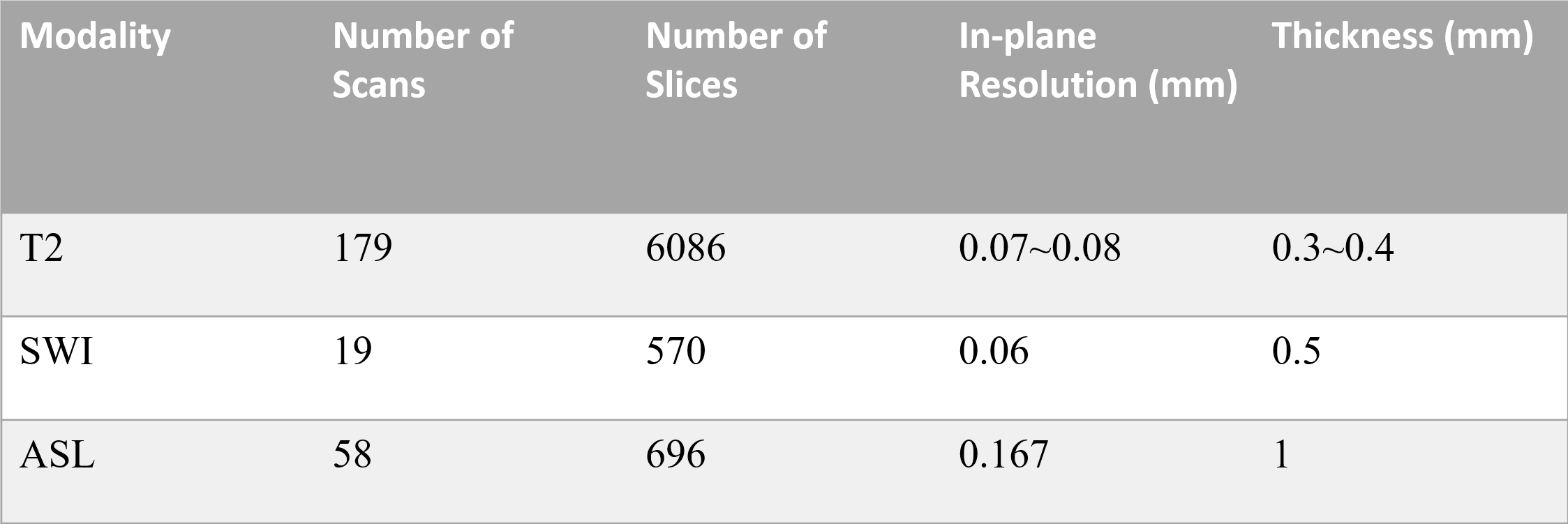
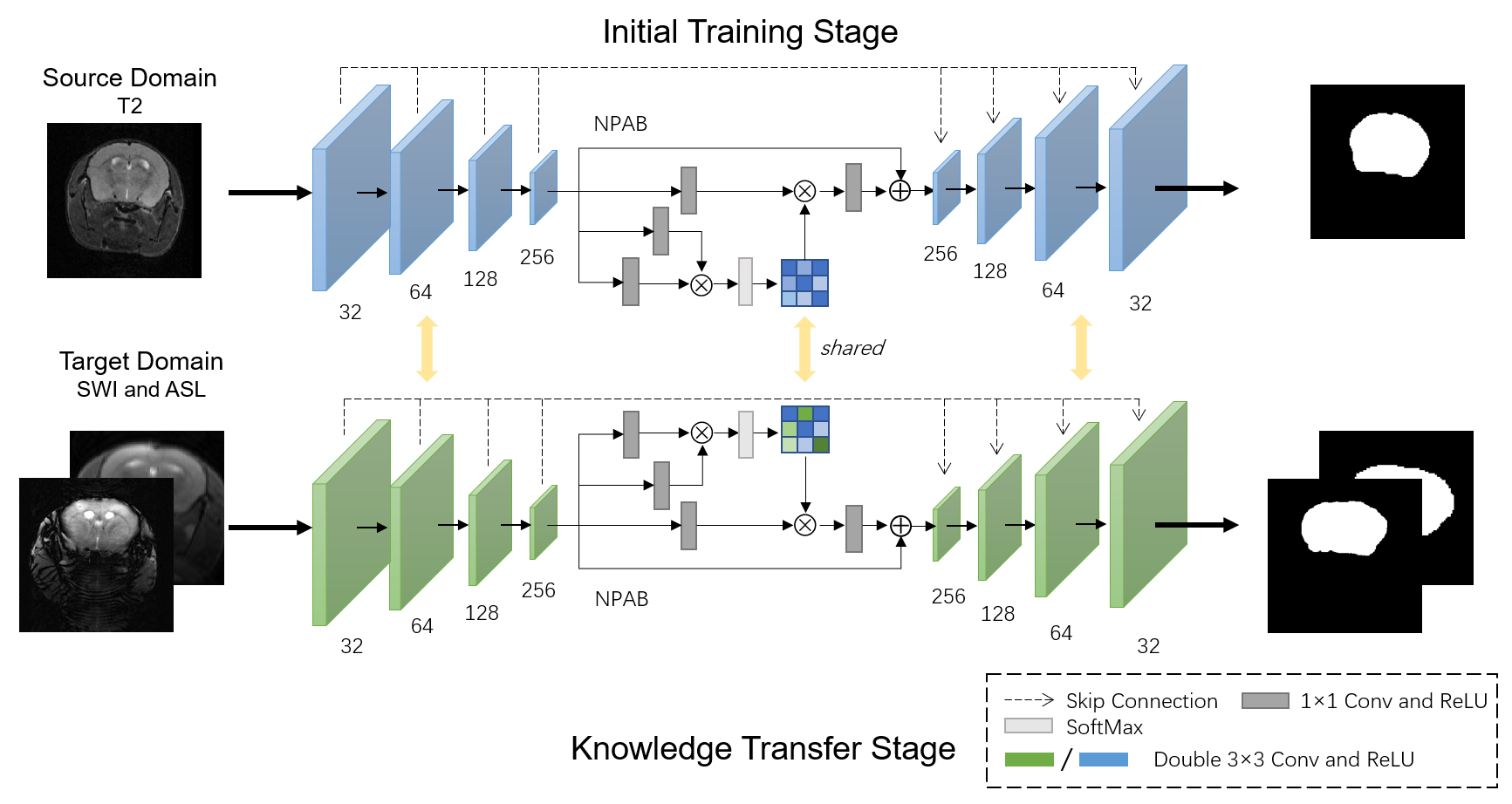
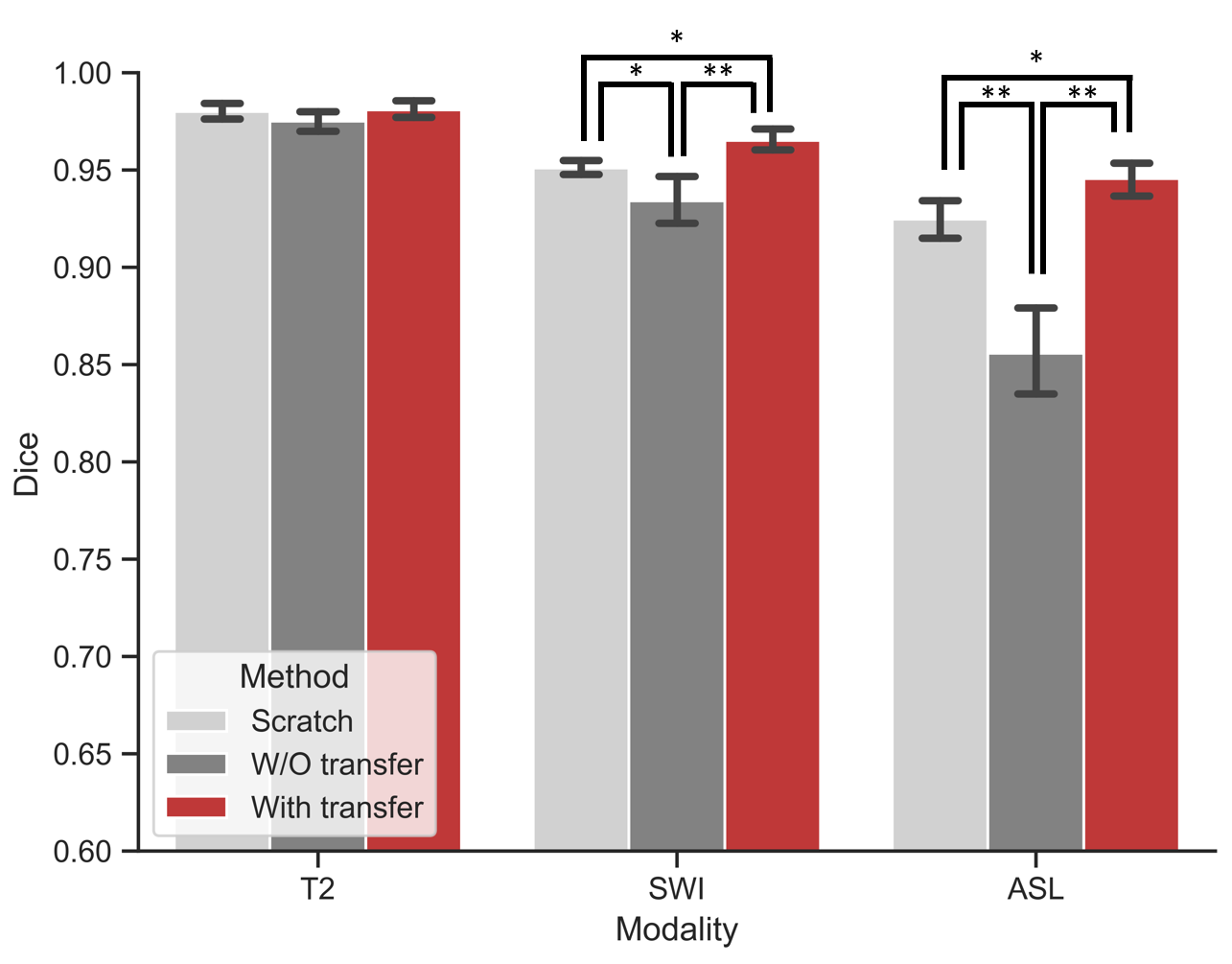
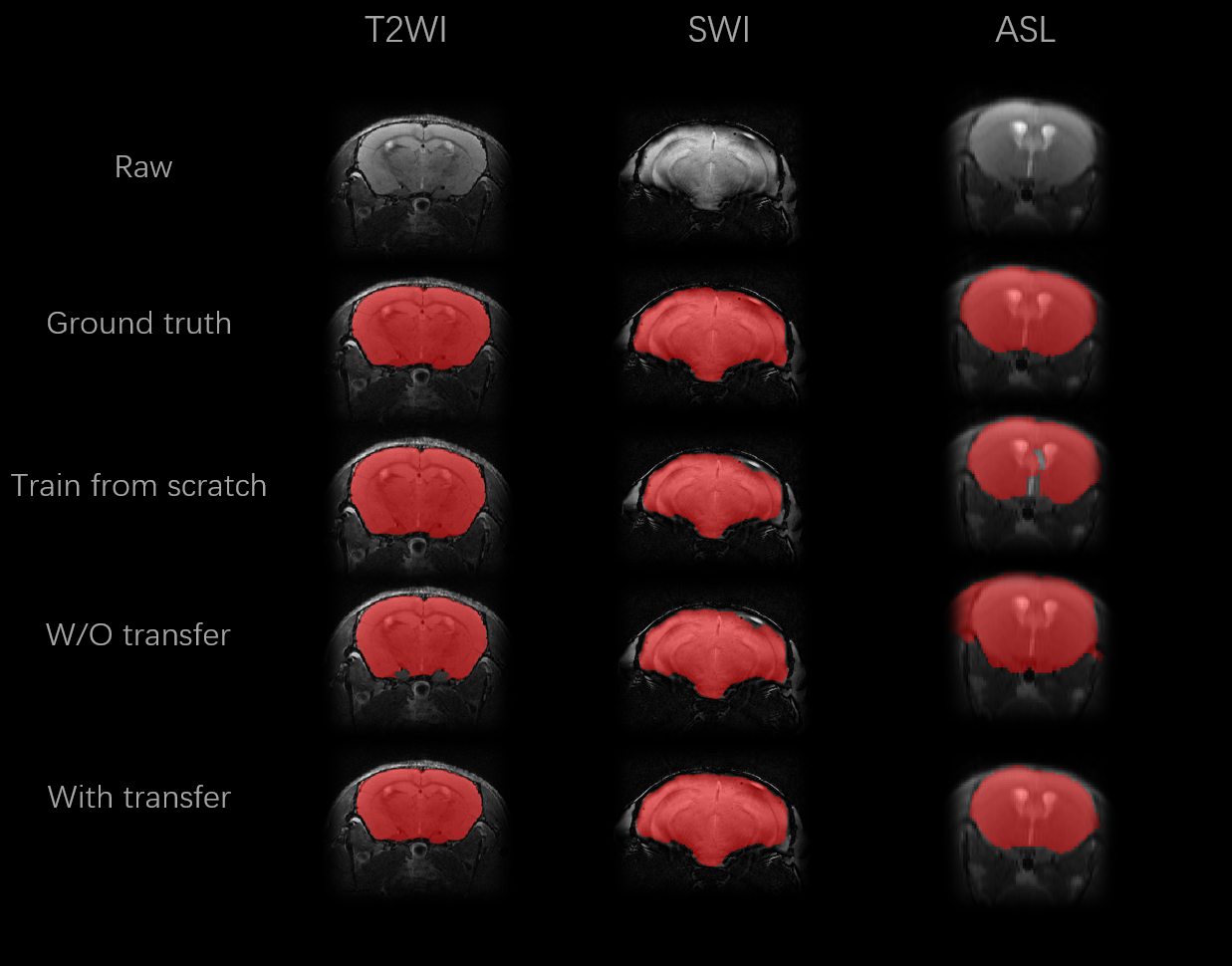
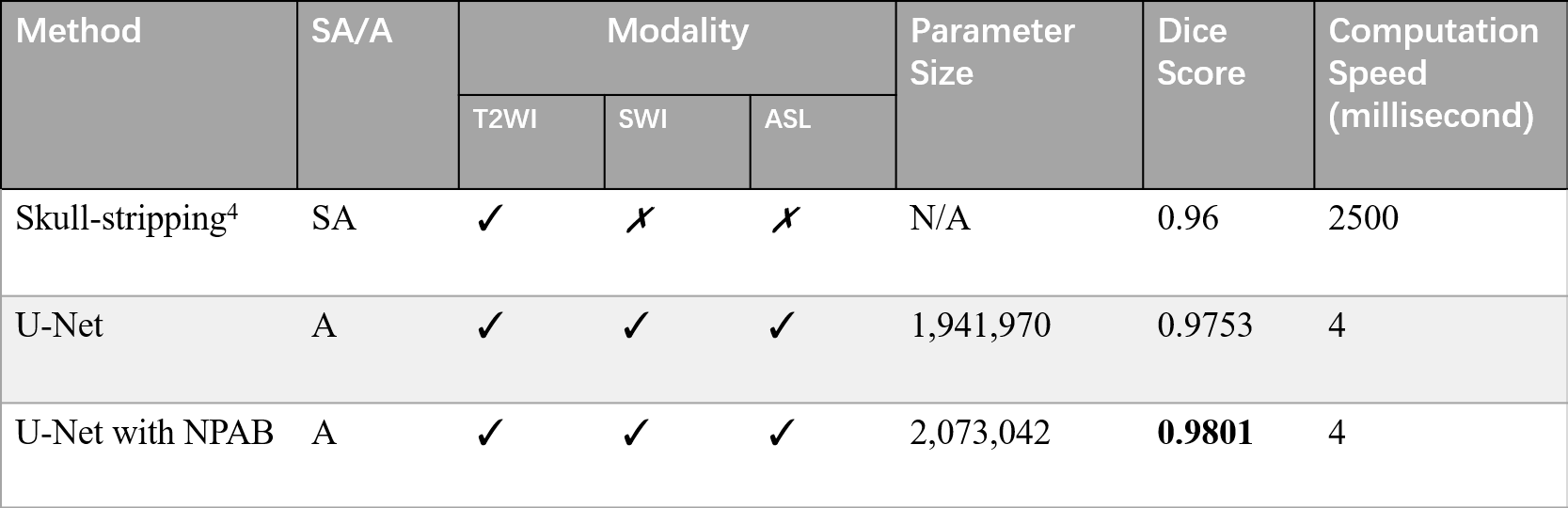
Figure 5: Number of parameters and time costs on different methods. Ablation experiment was conducted on T2 modality, with five-fold cross validation. SA: semi-automatic. A: automatic. NPAB: Nonlocal Position-aware block.