2429
Direct Synthesis of Multi-Contrast Images from MR Multitasking Spatial Factors Using Deep Learning1Biomedical Imaging Research Institute, Cedars-Sinai Medical Center, Los Angeles, CA, United States, 2Department of Bioengineering, UCLA, Los Angeles, CA, United States
Synopsis
MR Multitasking is an efficient approach for quantification of multiple parametric maps in a single scan. The Bloch equations can be used to derive conventional contrast-weighted images, which are still preferred by clinicians for diagnosis, from quantitative maps. However, due to imperfect modeling and acquisition, these synthetic images often exhibit artifacts. In this study, we developed a deep learning-based method to synthesize contrast-weighted images from Multitasking spatial factors without explicit Bloch modeling. We demonstrated that our method provided synthetic images with higher quality and fidelity than the model-based approach or a similar deep learning method using quantitative maps as input.
Introduction
Quantitative MRI enables measurements of physical parameters and provides important information about tissue properties. However, conventional weighted images are still preferred by clinicians for diagnosis. Although Bloch equation-based methods are used to synthesize conventional multi-contrast-weighted images from parametric maps,1 the synthetic images suffer from artifacts caused by partial volume effects, over-simplified models, and acquisition imperfections.2 To improve the image quality and fidelity, deep learning methods have been used for direct synthesis of clinical weighted images from multi-echo images3 or MR Fingerprinting images4. These approaches use reconstructed images as input and may not achieve the best efficiency to provide the essential information for synthesis. MR Multitasking is an efficient approach for multi-parametric mapping in a single acquisition and as a byproduct of image reconstruction, produces spatial feature maps in a low-dimensional subspace that are lossless compared to the reconstructed multiple-contrast-weighted images.5 In this study, we propose to use these Multitasking spatial factors as input to neural networks for conventional weighted image synthesis.Methods
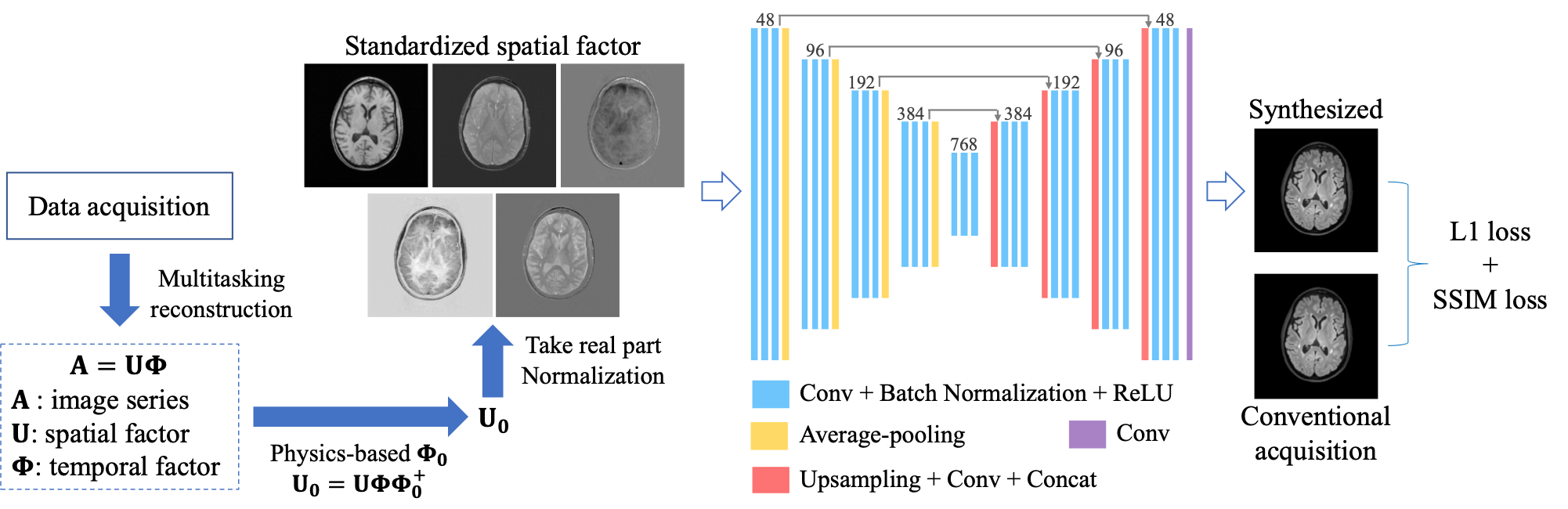
MR Multitasking subspace formulationIn MR Multitasking, images can be represented as a spatiotemporal function $$$I(\mathbf{x}, \mathbf{t})$$$, which can be discretized into a matrix representation $$$\mathbf{A} \in \mathbb{C}^{M \times N}$$$, with elements $$$A_{i j}=I\left(\mathbf{x}_{i}, \mathbf{t}_{j}\right)$$$. Due to partial separability,6 $$$\mathbf{A}$$$ is a low-rank matrix, with at most rank $$$L$$$. Therefore, $$$\mathbf{A}$$$ can be factored as $$$\mathbf{A}=\mathbf{U}\mathbf{\Phi}$$$, where $$$\mathbf{U} \in \mathbb{C}^{M \times L}$$$ has elements $$$U_{il}=u_{l}\left(\mathbf{x}_{i}\right)$$$, and $$$\mathbf{\Phi} \in \mathbb{C}^{L \times N}$$$ has elements $$$\Phi_{lj}=\phi_{l}\left(\mathbf{t}_{j}\right)$$$. The rows of temporal factor $$$\mathbf{\Phi}$$$ span a temporal subspace, and the spatial factor $$$\mathbf{U}$$$ contains the subspace coordinates for the image sequence in it. We aim to perform contrast-weighted synthesis directly from this spatial factor $$$\mathbf{U}$$$.
Data acquisition and preprocessing
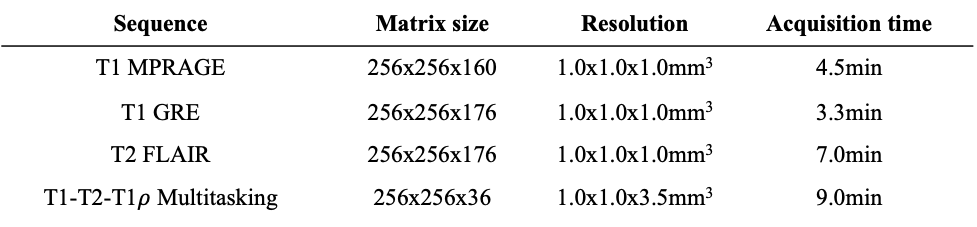
Fifteen multiple sclerosis patients were scanned on a 3T Siemens scanner. A T1-T2-T1$$$\rho$$$ Multitasking sequence7 was acquired. Multitasking spatial factors were derived with a rank $$$L=5$$$. Conventional weighted images, including T1 MPRAGE, T1 GRE, and T2 FLAIR, were acquired as targets. Imaging parameters are listed in Table 1.
For preprocessing, we standardized the spatial factors by projection onto a subject-independent temporal subspace derived from Bloch equations.7 After phase normalization by the first column of the standardized $$$\mathbf{U}$$$, the real part of this spatial factor was used as a 5-channel input for the network. Rigid registration was performed with T1 MPRAGE as fixed images. All the slices were normalized by the 95th percentile of the intensity within the brain region.
Network, training, and evaluation
We designed a convolutional neural network (CNN) based on the U-Net structure8 (Figure 1). The network took the 5-channel spatial factor as input and used the clinical weighted images as labels. Three different networks were trained to synthesize the three clinical contrasts separately. We used a combination of L1 loss and structural-similarity-index (SSIM) loss: $$$L_{total}=L_1+{\lambda}L_{SSIM}$$$, in which $$$\lambda=0.1$$$ was empirically chosen.
Twelve subjects were used for training and three for testing. The networks were trained using ADAM optimizer for 300 epochs, with a learning rate of 0.0001 and a batch size of 4. For comparison, we also trained the network with quantitative maps (i.e., T1 map, T2 map, and proton density map) as inputs. For evaluation, our network outputs were compared with the synthetic images generated by Bloch equations and the true acquisition. Normalized root mean squared error (NRMSE), peak signal-to-noise ratio (PSNR), and SSIM were calculated. A two-way repeated measures ANOVA was performed between the metrics of our method and those of the alternative approaches, using a p-value threshold of 0.05.
Results
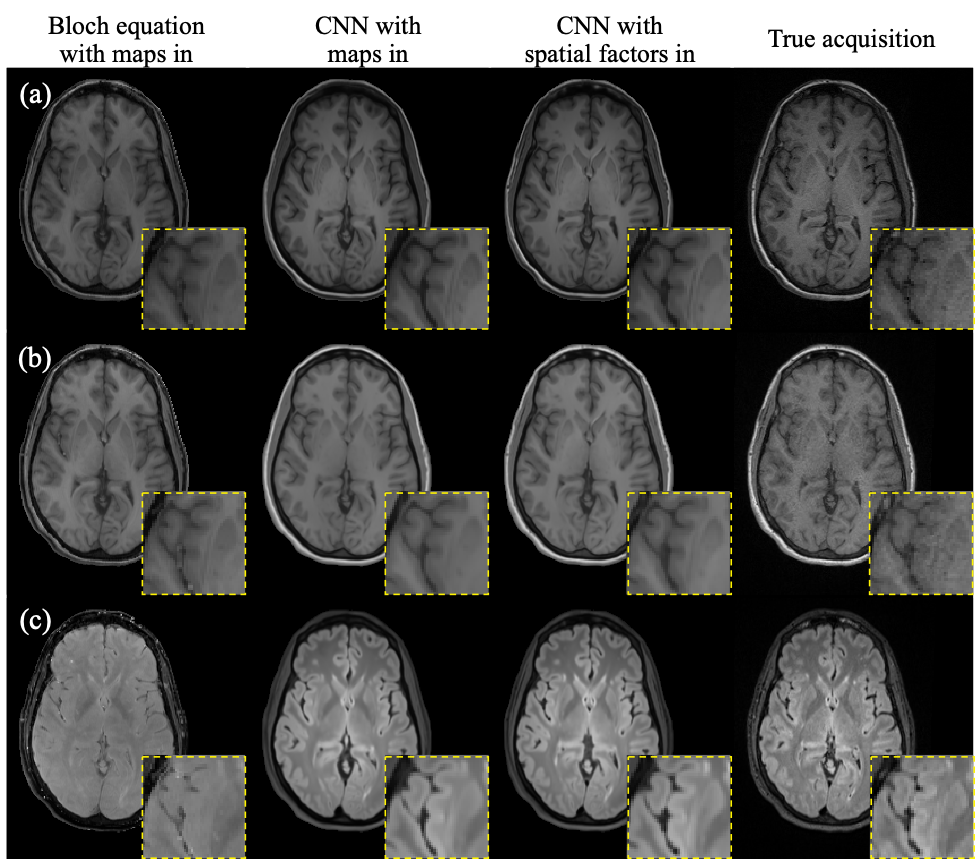
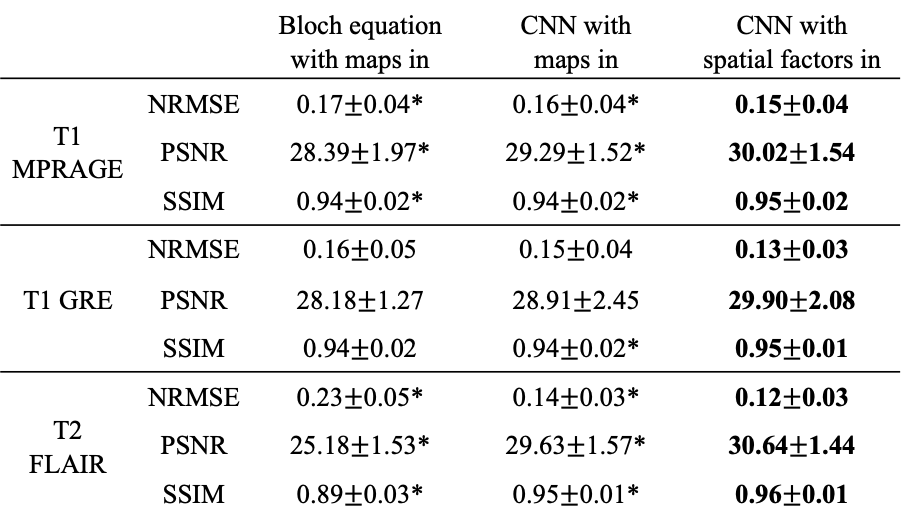
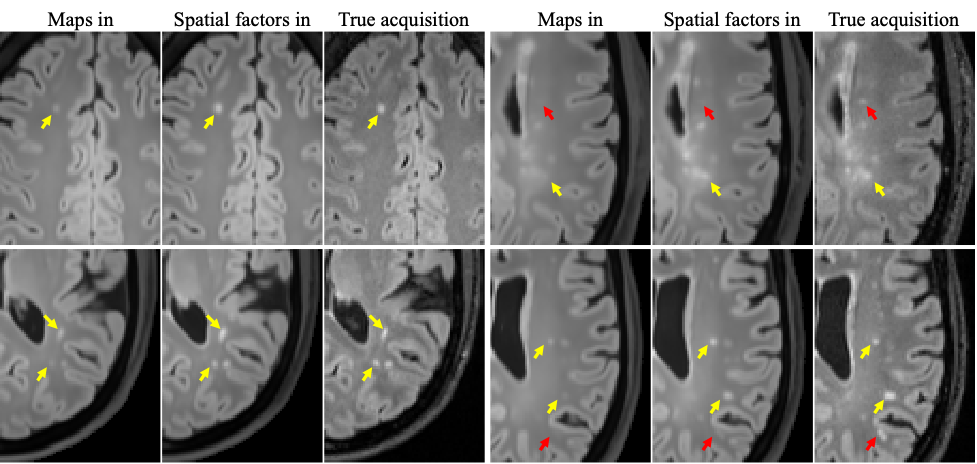
Figure 2 shows example synthetic images using different methods. CNN-based methods generated images with better contrast than those derived from Bloch equations, especially for T2 FLAIR. As shown in Table 2, our proposed method achieved significantly lower NRMSE and significantly higher PSNR and SSIM than the other two approaches on T1 MPRAGE and T2 FLAIR. In the visual inspection of lesions on T2 FLAIR, the proposed method provided better lesion delineation than using CNN with parametric maps as input (Figure 3). Our method generated good contrast for most structures and lesions, while we also found some of the lesions, mostly small ones, missing in the synthetic images (red arrows in Figure 3).Discussion
In this work, we developed a CNN-based direct contrast synthesis method using MR Multitasking spatial factors as network input, which outperformed the Bloch equation-based method as well as the CNN synthesis from quantitative map inputs. Using spatial factors as source images avoids the possible loss of information in multi-parametric map fitting such as partial-volume effects. Nevertheless, some small lesions are missing in the synthetic images. This may have resulted from the thicker slices with Multitasking acquisition (3.5 vs 1.0 mm) because of the imaging time limit as well as potential misregistration between Multitasking and conventional weighted images. With substantial reductions in Multitasking imaging time currently underway, we will in the future use a larger dataset with matched resolution and a more diverse cohort to further validate the approach.Conclusion
We demonstrated high image quality and fidelity of deep learning-based synthesis of conventional weighted images from Multitasking spatial factors. With this method, we can acquire both multi-parametric maps and multi-contrast weighted images in a single scan using MR Multitasking.Acknowledgements
This work was supported by NIH R01EB028146.References
1. Hagiwara A, Warntjes M, Hori M, Andica C, Nakazawa M, Kumamaru KK, et al. SyMRI of the Brain: Rapid Quantification of Relaxation Rates and Proton Density, With Synthetic MRI, Automatic Brain Segmentation, and Myelin Measurement. Invest Radiol. 2017;52(10):647-657.
2. Tanenbaum LN, Tsiouris AJ, Johnson AN, Naidich TP, DeLano MC, Melhem ER, et al. Synthetic MRI for Clinical Neuroimaging: Results of the Magnetic Resonance Image Compilation (MAGiC) Prospective, Multicenter, Multireader Trial. AJNR Am J Neuroradiol. 2017;38(6):1103-1110.
3. Wang G, Gong E, Banerjee S, Martin D, Tong E, Choi J, et al. Synthesize High-Quality Multi-Contrast Magnetic Resonance Imaging From Multi-Echo Acquisition Using Multi-Task Deep Generative Model. IEEE Transactions on Medical Imaging. 2020;39(10):3089-3099.
4. Wang K, Doneva M, Amthor T, Keil VC, Karasan E, Tan F, et al. High Fidelity Direct-Contrast Synthesis from Magnetic Resonance Fingerprinting in Diagnostic Imaging. In Proc ISMRM, 2020, pp. 867.
5. Christodoulou AG, Shaw JL, Nguyen C, Yang Q, Xie Y, Wang N, et al. Magnetic resonance multitasking for motion-resolved quantitative cardiovascular imaging. Nat Biomed Eng. 2018;2(4):215-226.
6. Liang ZP. Spatiotemporal imaging with partially separable functions. In Proc IEEE-ISBI, 2007, pp. 988-991.
7. Ma S, Wang N, Fan Z, Kaisey M, Sicotte NL, Christodoulou AG, et al. Three-Dimensional Whole-Brain Simultaneous T1, T2, and T1ρ Quantification using MR Multitasking: Method and Initial Clinical Experience in Tissue Characterization of Multiple Sclerosis. Magn Reson Med. 2020, in press.
8. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In Proc MICCAI, Springer, 2015, pp. 234–241.
Figures