2420
Swarm intelligence: a novel clinical strategy for improving imaging annotation accuracy, using wisdom of the crowds.1Department of Radiology and Biomedical Imaging, University of California San Francisco, San Francisco, CA, United States
Synopsis
Radiologists play a central role in image annotation for training Machine Learning models. Key challenges in this regard include low inter-reader agreement for challenging cases and concerns of interpersonal bias amongst trainers. Inspired by biological swarm intelligence, we explored the use of real time consensus labeling by three sub-specialty (MSK) trained radiologists and five radiology residents in improving training data. A second swarm session with three residents was conducted to explore the effect of swarm size. These results were validated against clinical ground truth and also compared with results from a state-of-the-art AI model tested on the same dataset.
Background
Expert (Radiologist) labelling of imaging data is an important prerequisite task of AI development, critical for building robust and accurate models. A key challenge is the low inter-reader agreement observed in complex cases or with complex imaging modalities (MRI), observed across various sub specialties1-3. Furthermore people from disadvantaged backgrounds often find it difficult to make their opinions heard in group decisions, which can translate into and amplify algorithmic biases as well4,5. To mitigate concerns of such biases and improve inter-reader agreement, we investigated a novel technique leveraging swarm intelligence. Borrowed from observations made in birds and insects6, swarm intelligence is a method to find the optimal answer in a group of autonomous agents, collaborating in real time. It has found applications in fields ranging from finance to robotics7 and recently in medical imaging8 as well. It captures the dynamics of conviction, negotiation and decision switching and is not simply a majority or an average vote of the crowds. We mimicked this natural phenomenon to form human swarms (blinded to each other). A group of MSK attendings and residents (separate cohorts) collaborated to assess knee MR scans for locating meniscal lesions and arrive at consensus decisions.Methods
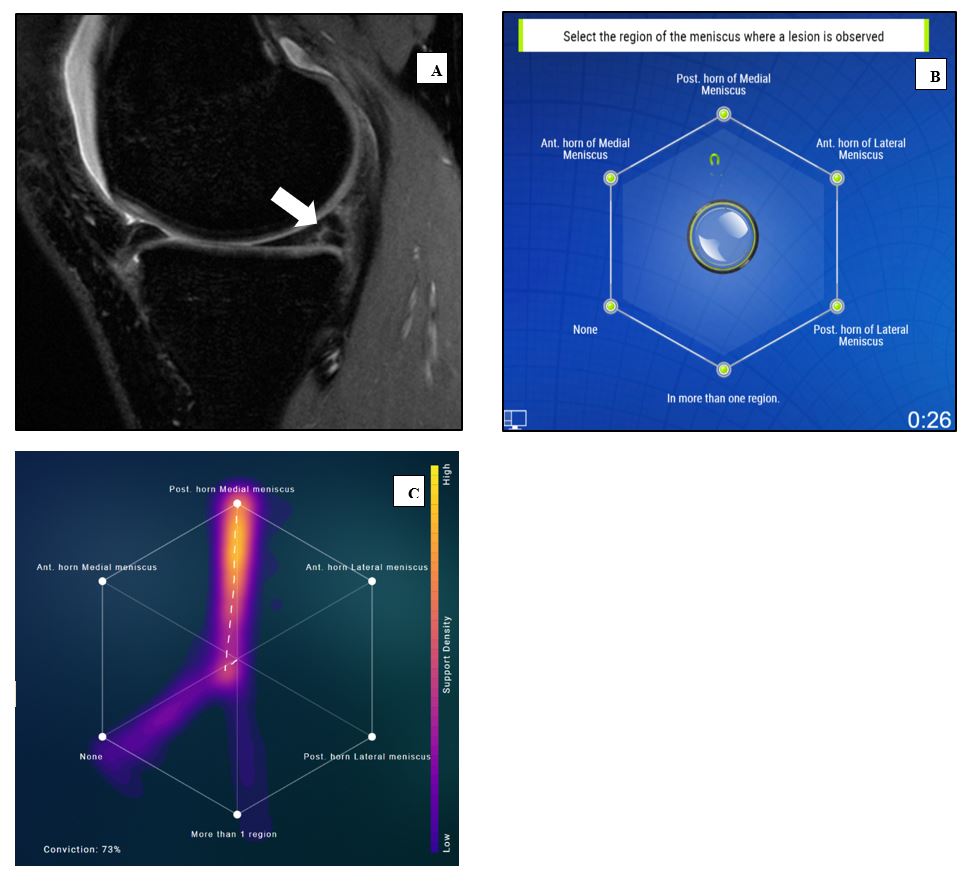
Anonymized sagittal 3D fast spin-echo CUBE sequences from 36 MR knee exams acquired at 3 sites were used for this study. Five radiology residents (TG, WF, JB, KS, AY) assessed the exams for lesion location in the four meniscal compartments (anterior and posterior medial and lateral horns) independently, on PACS. Majority vote was then tabulated and compared to ground truth (surgical notes). Post a 4-day washout period, all 36 exams were reassessed by the residents simultaneously on PACS, while participating on the swarm platform (Unanimous AI, San Francisco), in real time (Figure 1). Consensus answers for lesion location was derived and similarly compared to ground truth. A second resident swarm session was conducted later with 3 participants (TG, JB, KS) to assess effect of swarm size on accuracy as well. In order to have a bias free environment all readers were blinded to the identity of others, in both swarm sessions. Similarly, a second cohort of MSK attendings (TL, RP, KM) assessed the same knee MR scans for location of meniscal lesions. These were done first individually, and again in a blinded swarm session and compared to ground truth. Finally, an AI model developed to detect meniscal lesions on MR scans, was also tested over the same dataset of 36 exams and its predictions compared to ground truth. This model used a V-Net 9 convolutional deep learning architecture to generate segmentation masks for all four meniscus horns, that were used to crop smaller sub-volumes containing these regions of interest. These sub-volumes were used to train a 3D convolutional classifier to assess lesions on the regions of interest as normal, mild or severe10.Results
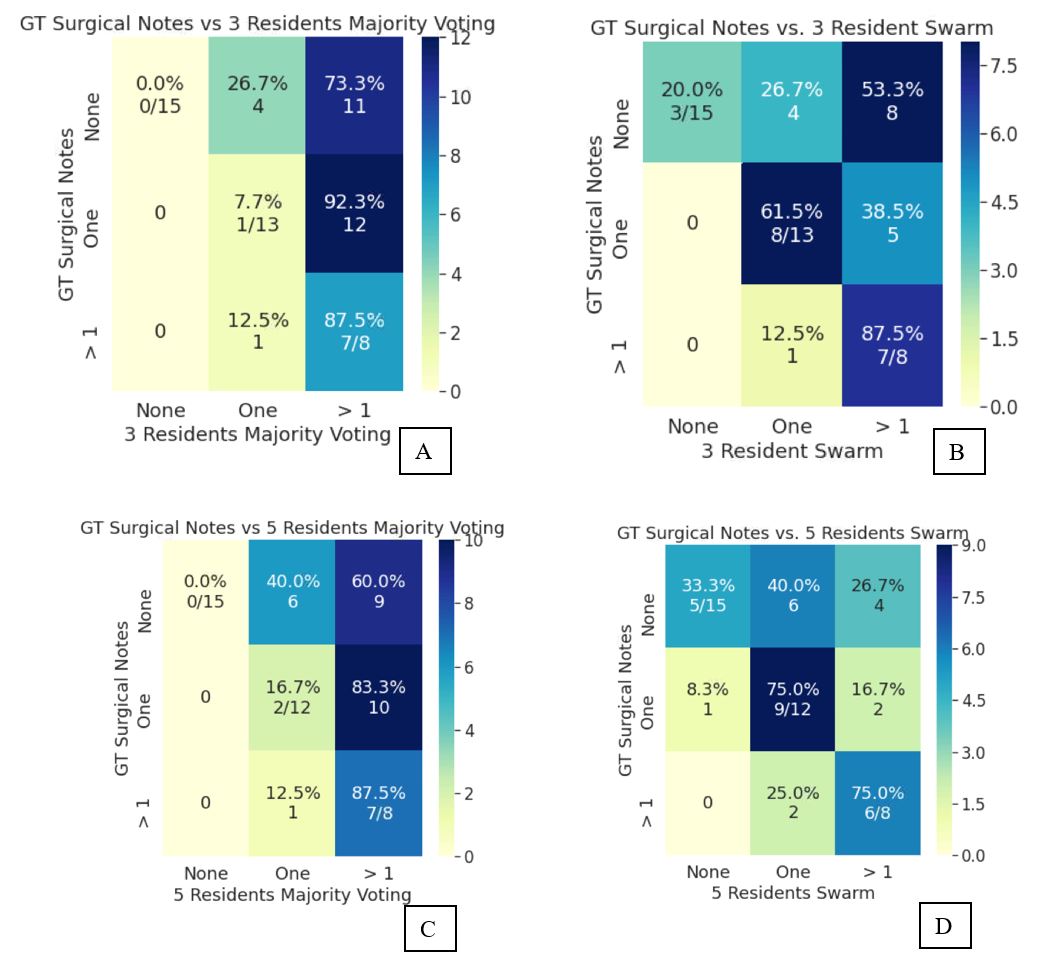
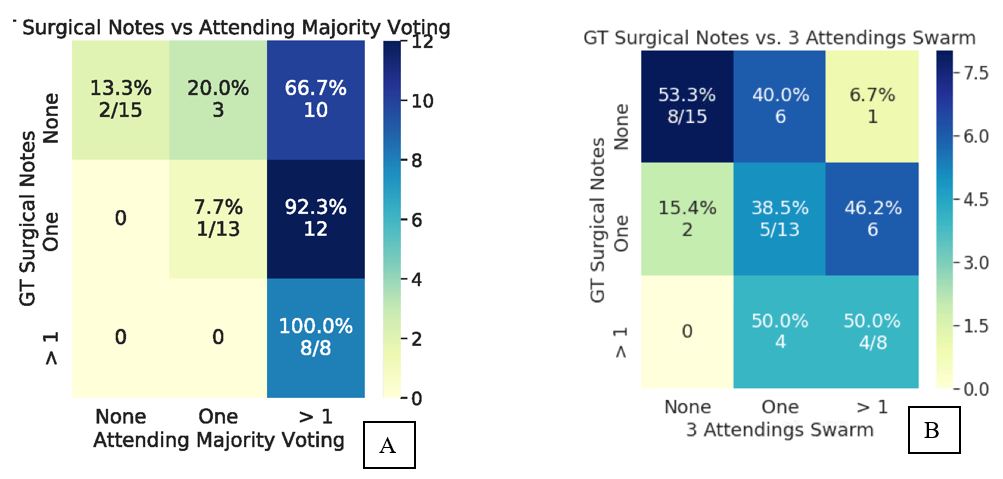
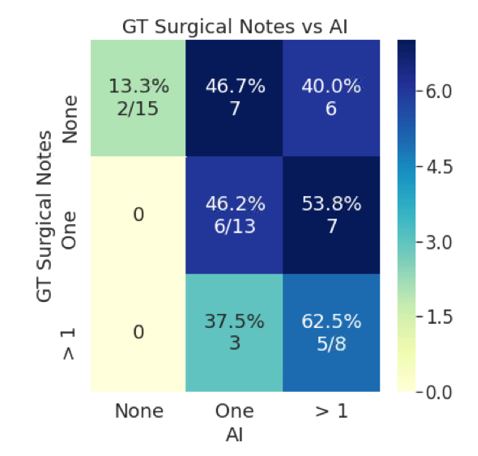
Ground truth (GT) in the individual exams was as follows: normal in n=15 exams, one lesion in one compartment in n=13 exams, more than one lesion in >1 compartment in n=8 exams. Cohen’s kappa for individual resident grades vs GT ranged from 0.01 to 0.19. The kappa for 3-resident majority vote vs GT was 0.0017 and 3-resident swarm vs GT was 0.24. The kappa for 5-resident majority vote vs GT increased to 0.05 and kappa for 5-resident swarm vs GT also increased to 0.37 (Figure 2). Cohen’s kappa for individual attending grades vs GT ranged from 0.08 to 0.29. The kappa for 3 attending majority vote vs GT was 0.12 and 3 attending swarm vs GT was 0.35 (Figure 3). AI versus GT had modest accuracy with a kappa of 0.13 (Figure 4). All individual readers were sensitive to presence of lesions as seen in the majority vote (Figures 2 and 3). The 5 resident swarm grading for normal cases (5/15) showed a significant improvement of 33% over the corresponding majority vote (0/15). Similarly, the 5 resident swarm grade for single compartment lesion (9/12) was 59% more accurate than majority vote (2/12) as compared to ground truth. Similar improvements were noticed in the attending swarm results as well. Remarkably the accuracy of the 5-resident swarm (kappa 0.37) was better than the 3-resident swarm (kappa 0.24) but also comparable to 3-attending swarm (kappa 0.35).Discussion
Swarm grading outperforms individual participants and is closer to actual clinical ground truth. As noted from our experiments, AI predictions fall in the same range of the individual gradings, but its accuracy is still significantly lower than swarm gradings. This can be explained by the fact that the AI model was trained on individual gradings from radiologists with similar level of training and experience. Additionally, the swarm platform is an excellent way to bring both geographically and demographically diverse participants for labeling and grading AI training data. Doing so in a blinded environment allows for better collaboration and reducing interpersonal biases.Conclusion
Applications of swarm intelligence hold promise for improving accuracy and overcoming individual biases. Swarm grading is especially useful in grading challenging cases with high inter-reader disagreement.Acknowledgements
We would like to thank Unanimous AI, for providing us with the swarm platform used in our study.References
1. Smith, C. P. et al. Intra- and interreader reproducibility of PI-RADSv2: A multireader study. Journal of magnetic resonance imaging : JMRI 49, 1694-1703, doi:10.1002/jmri.26555 (2019).
2. van Tilburg, C. W. J., Groeneweg, J. G., Stronks, D. L. & Huygen, F. Inter-rater reliability of diagnostic criteria for sacroiliac joint-, disc- and facet joint pain. Journal of back and musculoskeletal rehabilitation 30, 551-557, doi:10.3233/bmr-150495 (2017).
3. Melsaether, A. et al. Inter- and Intrareader Agreement for Categorization of Background Parenchymal Enhancement at Baseline and After Training. American Journal of Roentgenology 203, 209-215, doi:10.2214/AJR.13.10952 (2014).
4. Kaushal, A., Altman, R. & Langlotz, C. Geographic Distribution of US Cohorts Used to Train Deep Learning Algorithms. JAMA 324, 1212-1213, doi:10.1001/jama.2020.12067 (2020).
5. Obermeyer, Z., Powers, B., Vogeli, C. & Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 366, 447-453, doi:10.1126/science.aax2342 (2019).
6. Seeley, T. D., Visscher, P. K. & Passino, K. M. Group Decision Making in Honey Bee Swarms: When 10,000 bees go house hunting, how do they cooperatively choose their new nesting site? American Scientist 94, 220-229 (2006).
7. Slowik, A. & Kwasnicka, H. Nature Inspired Methods and Their Industry Applications—Swarm Intelligence Algorithms. IEEE Transactions on Industrial Informatics 14, 1004-1015, doi:10.1109/TII.2017.2786782 (2018).
8. Rosenberg, L. et al. in 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON). 1186-1191.
9. Milletari, F., Navab, N. & Ahmadi, S. in 2016 Fourth International Conference on 3D Vision (3DV). 565-571.
10. B.A.A. Nunes, I. Flament, R Shah et al, Deep Learning Assisted Full Knee 3D MRI-Based Lesion Severity Staging. ISMRM 28th Annual Meeting and Exhibition, July 2020
Figures