2407
Successive Subspace Learning for ALS Disease Classification Using T2-weighted MRI1Gordon Center for Medical Imaging, Department of Radiology, Massachusetts General Hospital, Harvard Medical School, Boston, MA, United States, 2Facebook AI, Boston, MA, United States, 3Department of Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, United States, 4Sean M Healey & AMG Center for ALS, Department of Neurology, Massachusetts General Hospital, Harvard Medical School, BOSTON, MA, United States, 5Sheffield Institute for Translational Neuroscience, University of Sheffield, Sheffield, United Kingdom
Synopsis
A challenge in Amyotrophic Lateral Sclerosis (ALS) research and clinical practice is to detect the disease early to ensure patients have access to therapeutic trials in a timely manner. To this end, we present a successive subspace learning model for accurate classification of ALS from T2-weighted MRI. Compared with popular CNNs, our method has modular structures with fewer parameters, so is well-suited to small dataset size and 3D data. Our approach, using 20 controls and 26 patients, achieved an accuracy of 93.48% in differentiating patients from controls, which has a potential to help aid clinicians in the decision-making process.
Introduction
The recent development of deep learning, with medical imaging data, outperformed human performance in some cases, thus showing the potential to aid clinicians in the diagnosis or decision-making process [1]. While, for neurological applications, deep learning has shown great potential for accurate detection and prediction of various disorders, including ALS, with medical imaging data, there are still several challenges in developing robust and accurate models, such as the limited data size and interpretability of the models. ALS is a neurodegenerative disorder characterized by loss of cortical and spinal motor neurons in the brain, leading to progressive muscle weakness across multiple body regions, including the bulbar region [2-3]. Magnetic resonance imaging (MRI) has been an effective tool to identify structural abnormalities in ALS, especially those in the brain and tongue. Structural MRI allows to measure the volume and shape of different parts of the brain and tongue. In this work, a lightweight and interpretable deep learning framework, termed VoxelHop, is presented for differentiating ALS patients from healthy controls using T2-weighted MRI.Method
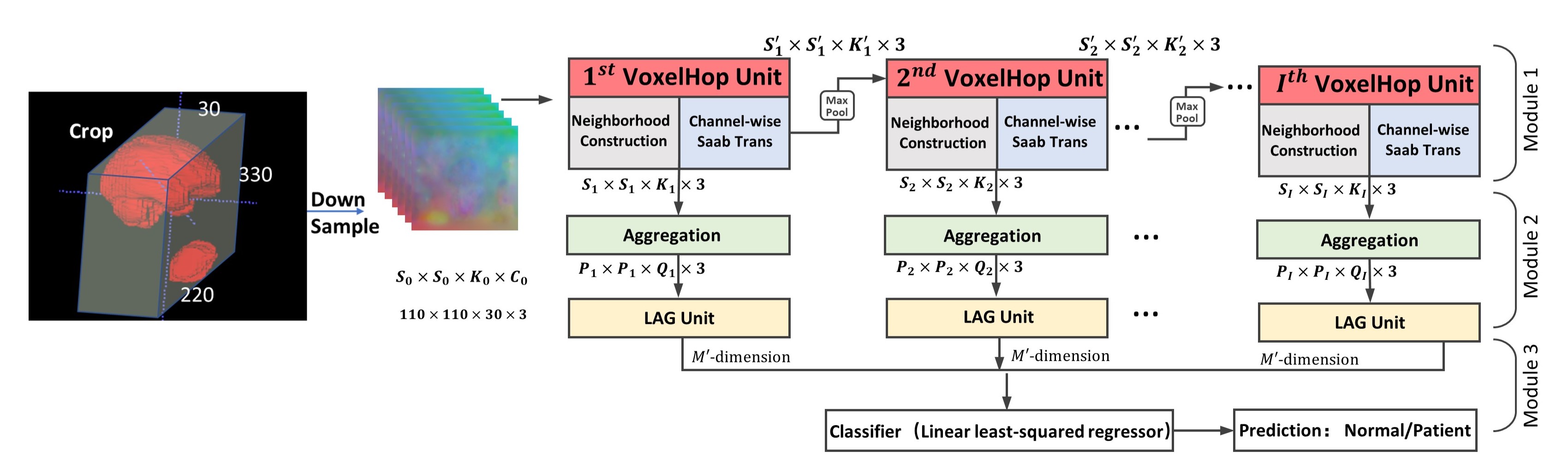
Head and neck acquisitions from 20 controls and 26 patients were performed using T2-weighted fast spin-echo MRI (Philips Ingenia, Best, Netherlands) with the following parameters: TR/TE = 1,107/80 ms, and interpolated voxel size = 0.78x0.78x5 mm3. We first construct a head and neck atlas using 20 controls from T2-weighted MRI via groupwise diffeomorphic registration [4], and carry out diffeomorphic registration of each subject with the atlas. Based on manually delineated whole brain and tongue segmentation masks, we crop the brain and tongue region as shown in Fig. 1. The deformation fields, which contain voxel expansion and contraction, are then input into our framework, since volume differences between the atlas and individual subjects, as embedded in the deformation fields, play an essential role in the classification task. In brief, our framework has four key components (see Fig. 1), including (1) sequential expansion of near-to-far neighborhood for multi-channel 3D deformation fields; (2) subspace approximation for unsupervised dimension reduction; (3) label-assisted regression for supervised dimension reduction; and (4) concatenation of features and classification between controls and patients. The dimension reduction is achieved by resorting to dominant feature subspace via Principal Component Analysis (PCA), which, in turn, discards less important features. Inspired by the recent stacked design of deep neural networks, the successive subspace learning (SSL) principle has been designed for classifying 2D images (e.g., PixelHop [5]) and point clouds (e.g., PointHop [6]). However, SSL-based PixelHop for multi-channel 3D data has not been explored previously. Also, the subspace approximation via adjusted bias (Saab) transform [7], a variant of PCA, is applied as an alternative to nonlinear activation, which helps avoid the sign confusion problem. Furthermore, the Saab transform can be more explainable than nonlinear activation functions used in convolutional neural networks (CNN) [7], since the model parameters are determined stage-by-stage in a feedforward manner, without any backpropagation. Therefore, the training of our framework can be more efficient and explainable than 3D CNNs, such as the winner models of ImageNet Large Scale Visual Recognition Challenge (e.g., AlexNet [8], VGG [9], and ResNet [10]).Results
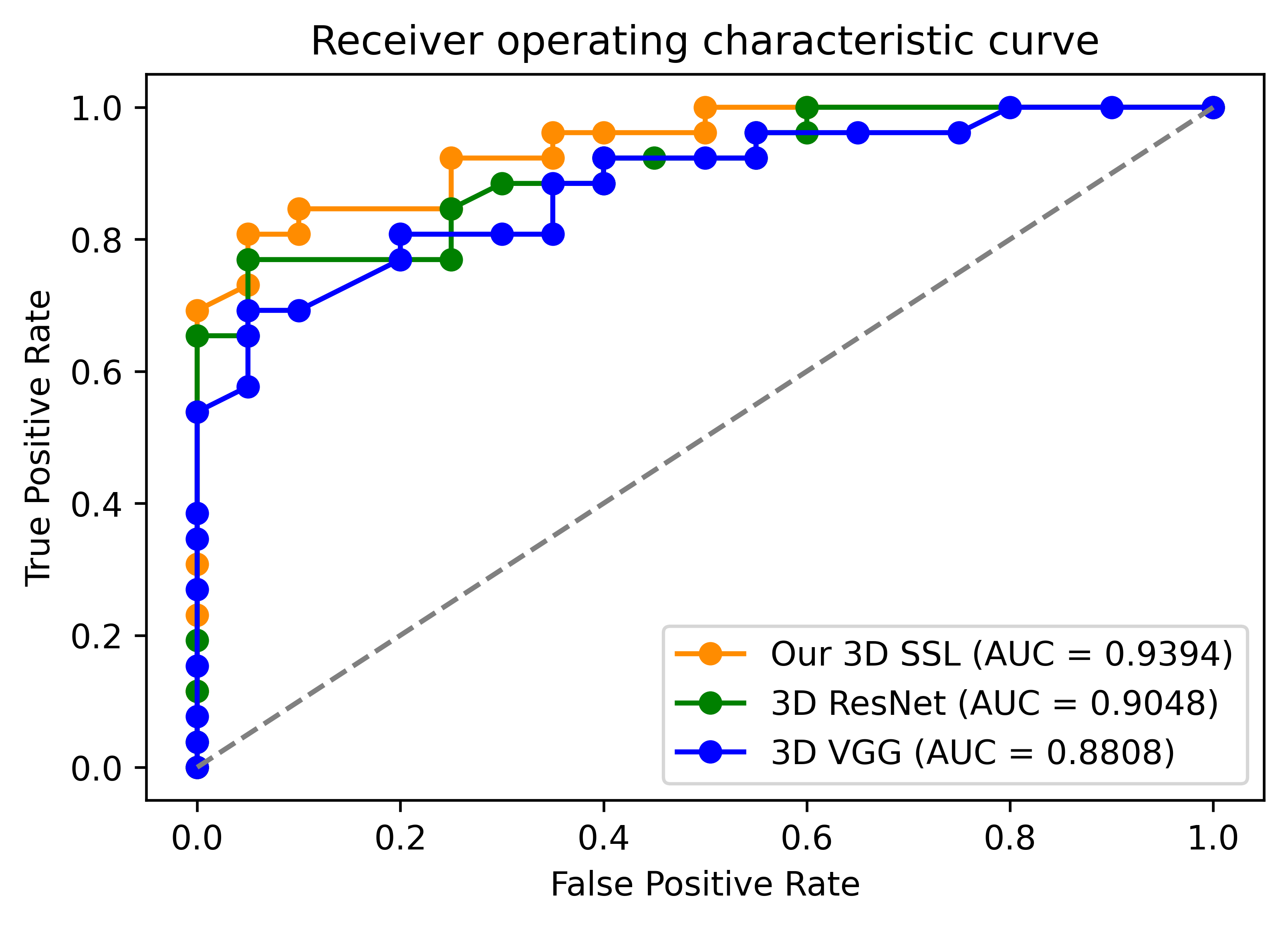
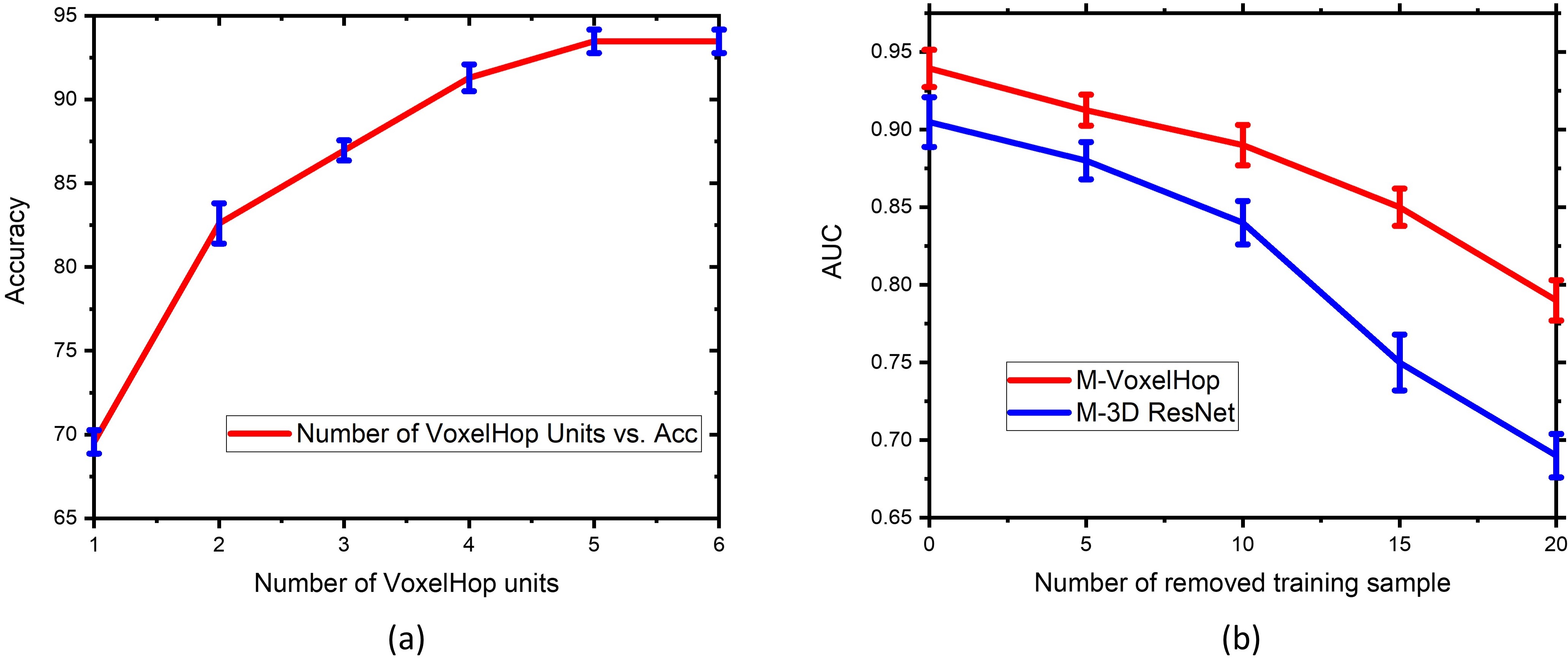
In order to evaluate our framework, we carried out leave-one-out cross-validation with the same hyperparameters across all folds and measured the classification accuracy and area under the curve (AUC) as shown in Fig. 2. Our approach surpassed the 3D CNN-based classification in terms of both the accuracy and AUC. With five SSL stages, our framework achieved an accuracy of 93.48%. As a comparison, the multi-channel version of 3D VGG and ResNet achieved an accuracy of 91.30% and 89.13%, respectively. Fig. 2 shows the comparison of the AUC between our framework and 3D VGG and ResNet. Notably, our framework had 10x fewer parameters than 3D CNNs that required over 1.2 million parameters. We also provided an ablation study of configuring different stages as in Fig. 3(a) to demonstrate the effect of cascading multiple SSL operations to improve the accuracy. We further randomly removed 5, 10, 15, and 20 training samples in each leave-one-out evaluation fold. Fig. 3(b) shows the AUC of our framework and 3D ResNet using fewer training datasets. It was observed that the performance drop of 3D ResNet was more pronounced than our framework, when removing more training data.Discussion
The architecture of our framework is based on transparent and modular structures by exploiting the near-to-far neighborhoods of selected voxels, following a one-time feedforward manner, compared with 3D CNNs. Our experimental results showed that the performance of our framework surpassed the widely used 3D CNNs with respect to the accuracy and AUC with 10x fewer parameters. Also, our framework was robust, even with relatively a small number of datasets.Conclusion
We proposed a lightweight and interpretable SSL framework to differentiate ALS patients from controls from T2-weighted MRI. To the best of our knowledge, this is the first attempt at exploring both the brain and tongue via the 3D deformation fields, which were then used for the accurate and efficient classification task. Our framework thus has the potential to help aid clinicians in the clinical decision-making process.Acknowledgements
This work was partially supported by NIH R01DC018511 and P41EB022544.References
[1] Shen, D., Wu, G. and Suk, H.I., "Deep learning in medical image analysis." Annual review of biomedical engineering, 19, pp. 221-248, 2017.
[2] Jenkins, T. M, Alix J., Fingret J., Esmail T., Hoggard N., Baster K., McDermott C. J., Wilkinson I. D., and Shaw P. J., “Longitudinal multi-modal muscle-based biomarker assessment in motor neuron disease." Journal of Neurology 267, no. 1: 244-256, 2020.
[3] Lee E., Xing F., Ahn S., Reese T. G., Wang R., Green J. R., Atassi N., Wedeen V. J., El Fakhri G., and Woo J., “Magnetic resonance imaging based anatomical assessment of tongue impairment due to amyotrophic lateral sclerosis: a preliminary study." The Journal of the Acoustical Society of America 143, no. 4, EL248-EL254, 2018.
[4] Avants, B. B., Tustison, N. J., Song, G., Cook, P. A., Klein, A., Gee, J. C., “A reproducible evaluation of ANTs similarity metric performance in brain image registration,” Neuroimage, 54(3), pp. 2033-2044, 2011.
[5] Yueru, C. and Kuo, C.-C. J., "Pixelhop: A successive subspace learning (SSL) method for object recognition." Journal of Visual Communication and Image Representation: 102749, 2020.
[6] Zhang, M., Haoxuan, Y., Pranav, K., Liu, S., and Kuo, C.-C. J., "PointHop: An Explainable Machine Learning Method for Point Cloud Classification." IEEE Transactions on Multimedia, 2020.
[7] Kuo, C.-C. J., Zhang, M., Siyang, L., Duan, J., Chen, Y., “Interpretable convolutional neural networks via feedforward design." Journal of Visual Communication and Image Representation, 60, pp. 346-359, 2019.
[8] Krizhevsky, A., Sutskever, I., and Hinton, G. E., “Imagenet classification with deep convolutional neural networks,” Communications of the ACM, vol. 60, no. 6, pp. 84–90, 2017.
[9] Simonyan, K. and Zisserman, A., “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
[10] He, K., Zhang, X., Ren, S., and Sun, J., “Identity mappings in deep residual networks,” in European conference on computer vision, pp. 630–645, 2016.
Figures