2402
Task Performance or Artifact Reduction? Evaluating the Number of Channels and Dropout based on Signal Detection on a U-Net with SSIM Loss1Mathematics Department, Manhattan College, Riverdale, NY, United States, 2Roy J. Carver Department of Biomedical Engineering, University of Iowa, Iowa City, IA, United States
Synopsis
The changes in image quality caused by varying the parameters and architecture of neural networks are difficult to predict. It is important to have an objective way to measure the image quality of these images. We propose using a task-based method based on detection of a signal by human and ideal observers. We found that choosing the number of channels and amount of dropout of a U-Net based on the simple task we considered might lead to images with artifacts which are not acceptable. Task-based optimization may not align with artifact minimization.
Purpose
Artifacts from neural network reconstructions of magnetic resonance imaging (MRI) data are hard to characterize. This leads to a challenge in choosing the network architecture and parameters. Because of this, it is particularly important to use an assessment of image quality which is connected to the task for which the image will be used1. In this work, we evaluate the effect on signal detection of changing the number of channels and the amount of dropout in a U-Net2. We measure task performance by both human and ideal observers3 and compare them to more commonly used metrics of image quality: normalized root mean squared error (NRMSE) and structural similarity (SSIM)4.Methods
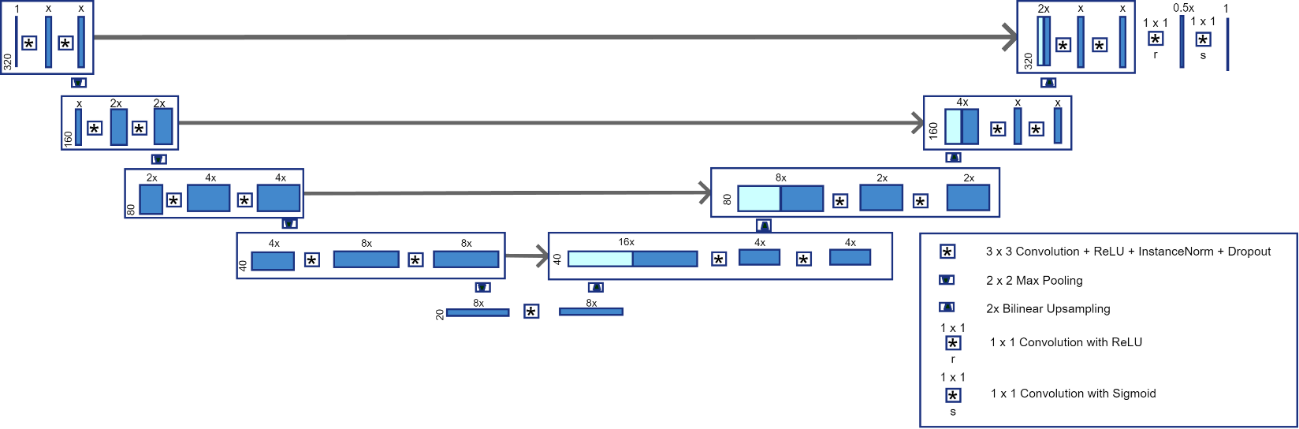
The fully sampled 320 x 320 images used in this study were generated using fluid-attenuated inversion recovery (FLAIR) images from the fastMRI dataset2 using the BART5 toolbox with no regularization, a sum of squares coil sensitivity estimate from the central 16 k-space lines and an R=1 SENSE reconstruction. To carry out the observer studies we generated fully sampled images with a small signal by adding the signal to the multi-coil data. We performed retrospective one-dimensional undersampling on fully sampled (single coil) images. We kept 16 k-space lines around the zero frequency (5% of the data) and everywhere else collected every fourth line for an effective undersampling factor of 3.48. The zero-filled undersampled magnitude images were the input to the neural network.The U-Net starts with a specified number of channels, x. In this study, we let x = 32 and 64 channels. We used dropout which is a form of regularization that randomly removes a fraction of neurons at each epoch. In this study, we let the dropout be 0, 0.1 and 0.3. Training was done using RMSProp for 150 epochs with a batch size of 16 and a loss function of 1-SSIM. The computations were done on a linux workstation using 2 Quadro P5000 16 GB CUDA GPUs. For each combination of number of channels and dropout we ran a 5-fold cross validation study with 500 images and calculated the NRMSE and SSIM. The standard deviations for these metrics were computed from the five folds.
We trained each network on all 500 background images for the observer studies and used the network to reconstruct data from 50 testing images. Four signals were placed in each background image to generate 200 sub-images (128 by 128) for the use in the observer studies. Each background and signal combination was generated separately. Four observers were trained for carrying out two-alternative forced-choice (2AFC) trials1 in which the observer determines which of two locations contains the signal (Figure 2). From a detection task-based perspective, our measure of image quality is the fraction of times that the observer correctly detects the signal, i.e. the fraction correct (FC). The signal was a small disk (radius = 0.25 pixels) blurred by a Gaussian kernel (σ=1 pixel). The signal amplitude was chosen to have approximately a 0.9 fraction correct for the human observers for the network with 64 channels and 0.1 dropout which performed best in the cross validation study. An ideal observer has the largest true-positive fraction for any false-positive fraction. We used an approximation to the ideal observer, the channelized Hotelling observer with Laguerre Gauss (LG-CHO) channels3. The standard deviation for the fraction correct for the human observer study was computed using the four observers. For the LG-CHO, the standard deviation was computed using 10,000 bootstrap samples.
Results & Discussion
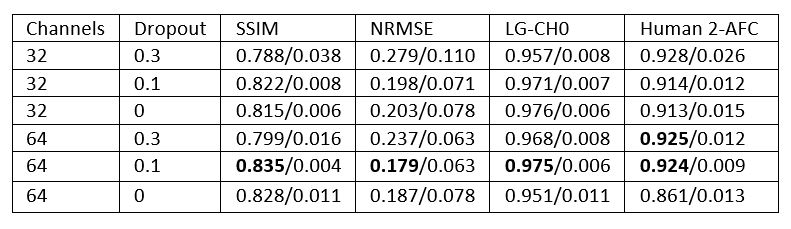
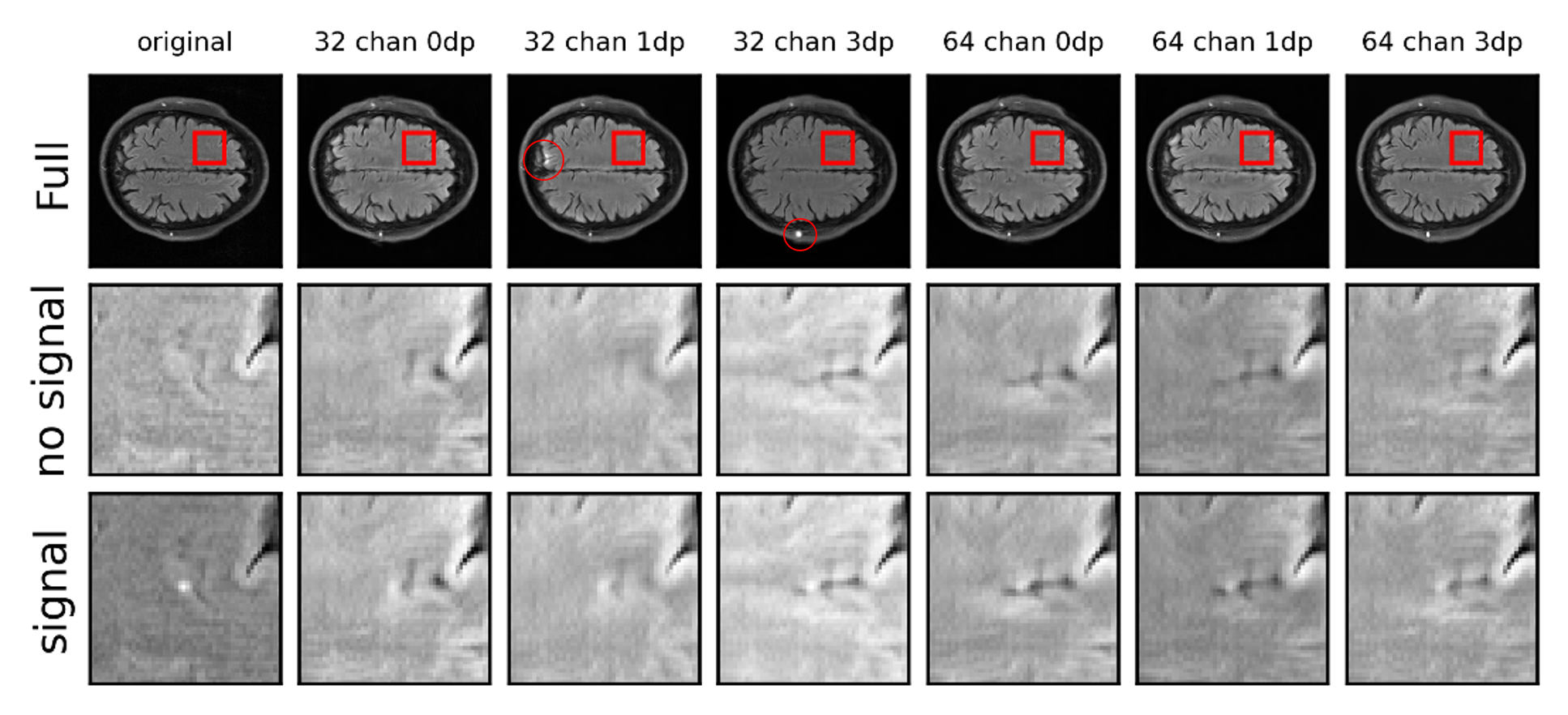
The results from the cross-validation and observer studies are summarized in Table 1. Based on the cross-validation study the channel and dropout that lead to the least error in both SSIM and NRMSE was 64 initial channels with 0.1 dropout. The story is more complicated with the human and ideal observer results. While the fraction correct for the 64 channel and 0.1 dropout is among the highest, there is not as much variability as in SSIM and NRMSE. The highest fraction correct for the human observers were for the 0.3 dropout. Figure 3 shows sample images illustrating the difficulty in assessing the image quality subjectively. There are bright spots in the reconstructions with 32 channels and 0.1 and 0.3 dropout. In the image with 0.3 dropout, the bright spot seems like an enhancement of a bright spot already in the image. This is also noticeable in the 2-AFC studies for the network with 64 channels with 0.3 dropout (Figure 4). The bright spots that appear in the images do not affect signal detection as long as they do not appear near the lesion. However, they do result in an increase in NRMSE and a decrease in SSIM. This highlights the difference between optimizing for a specific task and artifact reduction. Future work will include a larger training set, larger networks, other loss functions, networks which use the complex multi-coil data as input, and tasks which incorporate signal and location uncertainty which may better capture the bright spots appearing.Conclusion
This works highlights one of the challenges of choosing the architecture and parameters in neural networks. The networks which have highest task performance may not have the best artifact reduction.Acknowledgements
We acknowledge support NIH R15-EB029172 and thank Dr. Krishna S. Nayak, and Dr. Craig K. Abbey for their thoughtful feedback.References
1. CK Abbey, HH Barrett, "Human-and model-observer performance in ramp-spectrum noise: effects of regularization and object variability", JOSA A, 18: 1237-1242 (1994)
2. J Zbontar, F Knoll, A Sriram, et al, "fastMRI: An Open Dataset and Benchmarks for Accelerated MRI", arXiv: 1811.08839v1 (2018)
3. AR Pineda, "Laguerre-Gauss and sparse difference-of-Gaussians observer models for signal detection using constrained reconstruction in magnetic resonance imaging", Proc. SPIE 10952:53-58 (2019)
4. Z Wang, AC Bovik, HR Sheikh, et al, "Image quality assessment: from error visibility to structural similarity", IEEE TMI, 13: 600-612 (2004)
5. M Uecker, F Ong, JI Tamir, et al, "Berkeley Advanced Reconstruction Toolbox", Proc. Intl. Soc. Mag. Reson. Med, 23, 2486 (2015)
Figures