2096
Deep 2D Residual Attention U-net for Accelerated 4D Flow MRI of Aortic Valvular Flows1ECE, University of Louisville, Louisville, KY, United States, 2Department of Medicine, University of Louisville, Louisville, KY, United States
Synopsis
We propose a novel deep learning-based approach for accelerated 4D Flow MRI by reducing artifact in complex image domain from undersampled k-space. A deep 2D residual attention network is proposed which is trained independently for three velocity-sensitive encoding directions to learn the mapping of complex image from zero-filled reconstruction to complex image from fully sampled k-space. Network is trained and tested on 4D flow MRI data of aortic valvular flow in 18 human subjects. Proposed method outperforms state of the art TV regularized reconstruction method and deep learning reconstruction approach by U-net.
Introduction:
4D Flow MRI provides 3 directional blood velocity information over time and has a wide range of potential clinical applications in cardiovascular disease diagnosis. Due to high dimensionality of 4D flow, scan time can be high inhibiting clinical use. Various methods have been proposed to reduce scan time in 4D flow imaging including compressive sensing [1], k-t Sparse SENSE [2], k-t BLAST[3] etc. However, computationally expensive methods deter the possibility of real time reconstruction. Recently, deep CNN architecture’s ability to identify intricate features from data has shown great promise in medical image reconstruction [4] within seconds. Our recent study in [6] show that deep convolutional network can learn complex spatial domain feature and recover phase image and velocity information from zero filled complex image containing artifacts. In this abstract we propose a novel 2D deep network architecture for magnitude and phase recovery and a framework of 4D Flow reconstruction by the proposed architecture.Methods:
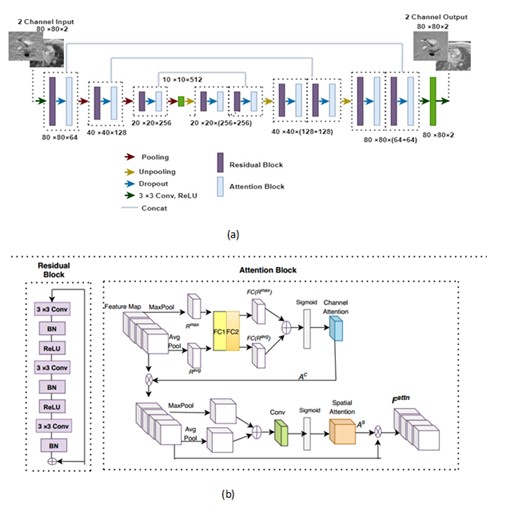
Zero-filled reconstructon of undersampled k-space in 4D Flow MRI contains 3D complex image with artifacts at each velocity encoding and temporal phase. We propose a novel 2D residual attention network which is trained separately for each encoding direction from the extracted 2D complex image from zero-filled image space at each slice location and temporal phase. Figure 1(a) shows the architecture of the reconstruction network where we propose a residual block followed by an attention block as the backbone of an encoder-decoder architecture. Figure 1(b) shows the adopted residual block. Number of convolutional layers at each residual block is 3. The convolution block consists of 3×3 filter with stride 1. Number of filters in encoder residual block are 64, 128, and 256. Residual and attention block together creates the Residual attention (RA) block. Each residual-attention block is followed by a maxpooling in encoder and average unpooling in decoder. Attention block consists of channel wise attention and spatial attention. Pixel wise mean squared error between the output and labelled image was considered as loss function. 4D flow data of blood flow through the aortic valve was collected with Cartesian readout in 18 subjects on a 1.5T Phillips Achieva scanner with a 16 channel XL Torso coil. The scan parameters for patient data were, TE= 3ms, TR= 14ms, number of frames = 15, matrix size=80×80×10, Field of View=200×200×50 (mm), slice thickness= 5mm, number of slices=10. Respiratory gating with navigators was used. The FOV included 1-2 slices proximal to the aortic valve with the remaining 8-9 slices distal to the valve. Fully sampled k-space data were acquired on the scanner and down sampled offline with 27% sampling rates. The dataset was further augmented by rotating each image in-plane between [0, 2π] in 10 degree increments. We split the dataset into training and testing sets via 9 fold cross validation on the 18 subjects. A small batch size of 32 was used to train the network. Network weights were initialized using normal distribution with standard deviation of 0.01. RMSpropoptimizer was used to minimize the loss function with a learning rate of 0.001 and epoch number of 600. We used Nvidia’s GeForce GTX 1050 Ti GPU and training took 1 day. The experiments in this study were performed using Keras with Tensorflow whose back end is Python 2.7.Results:
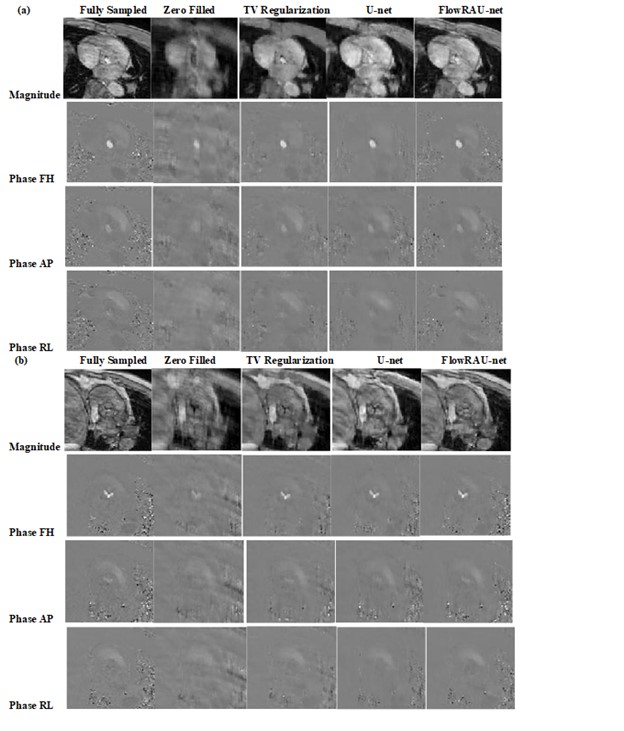
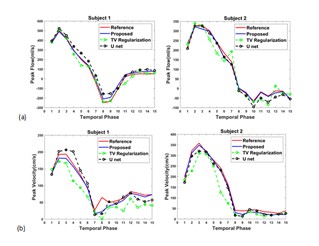
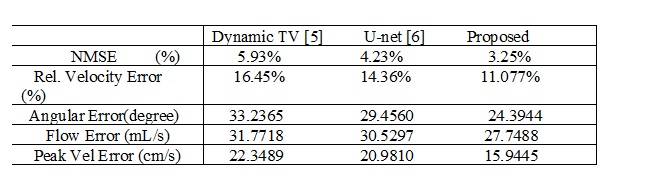
Average normalized mean square error (NMSE) of complex image is calculated as reconstruction error. 3D velocity vector in ROI from reconstructed image is compared with 3D velocity vector of phase image from fully sampled acquisition. Average Relative Error and Average Angular Error of 3D velocity are quantified in ROI. We compared the performance of the proposed architecture with a state-of-the-art TV regularization method [5] and deep learning reconstruction by U-net method [6] . Blood Flow rate in the velocity mapped image was measured by calculating mean velocity in the flow region multiplied by vessel area. Accuracy of flow rate was measured by calculating RMSE between flow rate calculated from reconstructed velocity mapped image and fully sampled velocity mapped image. Figure 2 shows reconstruction results of an image slice for 27% undersampling in 3 encoding direction- Foot to Head (FH), anterior-posterior (AP) direction and right-left (RL) directions. Results demonstrate that reconstructed magnitude and phase image by the proposed architecture can restore structural information and fine details of original image discarded by the undersampling. Figure (3) (a) shows volumetric blood flow rate at aortic valve position for two different subjects from reference image and reconstructed images. Peak Velocity-time profile for the two subjects are showed in figure (3) (b). Table 1 shows average error measure for all subjects. From average error results it is evident that the proposed network performs better than TV regularization and U-net.Discussion:
This paper presents the first end to end deep learning framework for accelerated reconstruction of 4D flow. Proposed architecture can learn recovery of both magnitude and velocity information in all velocity encoding direction with high fidelityAcknowledgements
This work was supported in part by the National Institutes of Health (grant- 1R21-HL132263).References
[1] Z.Chen, X. Zhang, C. Shi, S. Su, Z. Fan, JX. Ji, G. Xie, X. Liu., "Accelerated 3D Coronary Vessel Wall MR Imaging Based on Compressed Sensing with a Block-Weighted Total Variation Regularization", Applied Magnetic Resonance, vol. 48, no. 4, pp. 361-378, 2017. Available: 10.1007/s00723-017-0866-0
[2] D. Kim, H. Dyvorne, R. Otazo, L. Feng, D. Sodickson and V. Lee, "Accelerated phase-contrast cine MRI using k-t SPARSE-SENSE", Magnetic Resonance in Medicine, vol. 67, no. 4, pp. 1054-1064, 2011. Available: 10.1002/mrm.23088.
[3] M. Carlsson et al., "Quantification and visualization of cardiovascular 4D velocity mapping accelerated with parallel imaging or k-t BLAST: head to head comparison and validation at 1.5 T and 3 T", Journal of Cardiovascular Magnetic Resonance, vol. 13, no. 1, 2011. Available: 10.1186/1532-429x-13-55
[4] C. Hyun, H. Kim, S. Lee, S. Lee and J. Seo, "Deep learning for undersampled MRI reconstruction", Physics in Medicine & Biology, vol. 63, no. 13, p. 135007, 2018. Available: 10.1088/1361-6560/aac71a.
[5] P. Montesinos, J. Abascal, L. Cusso, J. Vaquero, M. Desco, "Application of the Compressed Sensing Technique to Self-gated Cardiac Cine Sequences in Small Animals", Magnetic Resonance in Medicine, 2013.
[6] R. Nath, S. Callahan, M. Stoddard, A. Amini "Accelerated Phase Contrast Magnetic Resonance Imaging via Deep Learning", IEEE International Symposium on Biomedical Imaging, IEEE;2020.
Figures