1979
A Modified Generative Adversarial Network using Spatial and Channel-wise Attention for Compressed Sensing MRI Reconstruction1School of Computer and Control Engineering, Yantai University, Yantai, China, 2Human Phenome Institute, Fudan University, Shanghai, China, 3Philips Healthcare, Shanghai, China
Synopsis
At present, many deep learning-based methods have been proposed to solve the problems of traditional CS-MRI, but the reconstruction effect under highly under-sampling has not been well resolved. We proposed a modified GAN architecture for accelerating CS-MRI reconstruction, namely RSCA-GAN. The generator in the proposed architecture is composed of two residual U-net block, in which we added spatial and channel-wise attention (SCA). Each encoding-decoding block is composed of two residual blocks with short skip connections. SCA are added to the decoding block and residual block.
Introduction
$$$\quad$$$RefineGAN [1] can perform CS-MRI reconstruction in a quick and accurate manner. The generator architecture cascaded two residual autoencoder U-Net together. SCA-CNN [2] added spatial and channel-wise attention to natural image processing, which can extract image details. UCA [3] added the channel-wise attention to U-Net, and used the attention mechanism in the upsampling process to improve the quality of image reconstruction. Wu et al. [4] added the attention mechanism to the residual block in the residual U-Net to show an effect superior to the traditional residual block.Purpose
$$$\quad$$$We proposed a modified GAN architecture for accelerating CS-MRI reconstruction, namely RSCA-GAN. The generator in the proposed architecture is composed of two residual U-net block, in which we added spatial and channel-wise attention (SCA). In addition, the encoding-decoding block in the residual U-Net is composed of two cascaded residual blocks including spatial attention and channel attention.Theory and Method
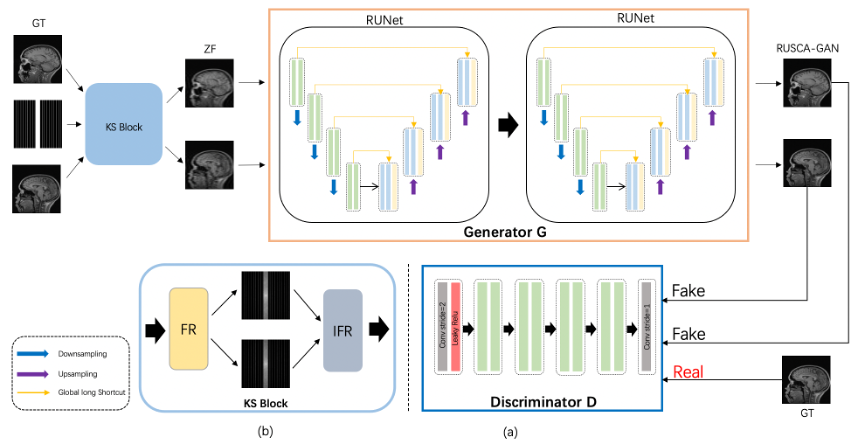
$$$\quad$$$The proposed framework is shown in Figure 1(a). We set up an under-sampling module KS-Block using accelerated sampling of ground truth (GT) images in the frequency domain to generate zero filling (ZF) images. FR and IFR are composed of two modules as shown in Figure 1(b). The FR-Block for performing Fourier transformation (FT) of GT image $$$S_{G T}$$$, uses the sampling mask $$$S_{R}$$$ as the acceleration factor.$$F_{R}=F\left(S_{G T}\right) R\qquad(1)$$
$$$\quad$$$Then we use the IFR module to convert from the frequency domain to the image, and get the ZF reconstructed image $$$S_{Z F}$$$,
$$IF_{R}=F^{*}\left(F_{R}\right)=F^{*}\left(F\left(S_{G T}\right) R\right)\qquad(2)$$
Where $$$F^{*}$$$ represents inverse Fourier transform.
$$$\quad$$$In order to make the image $$$S_{R E}$$$ reconstructed by the generator closer to the real image $$$S_{G T}$$$, the Generative Adversarial Loss and the cyclic consistency loss are used as the loss function of the network.
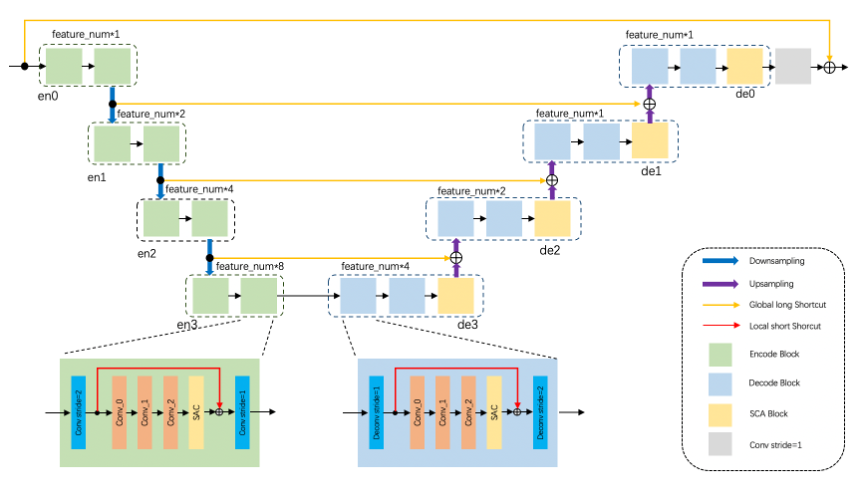
$$$\quad$$$The generator of the network is connected with two residual autoencoder U-net. Different from the traditional network, we use SCA in the U-net upsampling, and use two residual blocks between the encoder and the decoder with SCA in the residual block (Fig.2). The encode block is indicated by green, and the decode block is indicated by blue. The residual block is represented by orange, it is composed of three convolutional layers and SCA Block.SCA Block is indicated by yellow composed of spatial attention and channel attention (Fig.3).
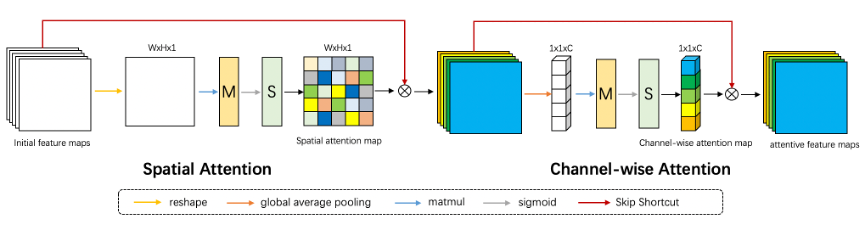
$$$\quad$$$As for spatial attention, we flattened the width and height of input feature $$$\text{F}$$$ via reshaping, and getting $$$F_{S i}$$$.We used a random weight $$$W_{S}$$$ and $$$\text{Sigmoid}$$$ activation function to complete the distribution of attention. Then we multiplied it with input feature $$$\text{F}$$$ to adjust the details. Spatial attention can be formulated as:
$$\Theta_{S A}=\operatorname{sig}\left(\operatorname{mat}\left(W_{S}, F_{S i}\right)+b_{S}\right) \otimes F\qquad(3)$$
Where $$$\text {mat}$$$ represents the multiplication of the matrix $$$W_{S}$$$ and the matrix $$$F_{S i}$$$, $$$\otimes$$$ represents the multiplication of the corresponding elements in the two matrices, $$$\text {sig}$$$ represents the sigmoid activation function.
$$$\quad$$$As for channel attention, we used global average pooling to further extract channel-wise global spital information from the feature maps obtained from $$$\Theta_{S A}$$$, indicated as $$$F_{C i}$$$. Also random weights $$$W_{C}$$$ and $$$\text{Sigmoid}$$$ activation function were used to make each channel feature gain different attention weights. Finally, the output obtained from $$$\Theta_{S A}$$$ was used to fine-tune. Channel-wise attention can be formulated as:
$$\Theta_{S C A}=\operatorname{sig}\left(\operatorname{mat}\left(W_{C}, F_{C i}\right)+b_{C}\right) \otimes \Theta_{S A}\qquad(4)$$
Experiment
$$$\quad$$$Our experimental data set comes from 35 healthy brain images, each of which is divided into 100 slices, of which 2500 are used to train the network, and the remaining are used for verification. The image size is 256x256 pixels. The training was performed on NVIDIA Tesla V100×4 GPU (each with 16GB memory). The initial learning rate of 1e−4. We used acceleration factors of 2x, 4x, 6x to test the reconstruction quality of ZF reconstruction, DAGAN, RefineGAN, RCA-GAN, and RSCA-GAN, and used Structural similarity (SSIM), peak signal-to-noise ratio (PSNR), normalized mean square error (NMSE) and significant difference to evaluate.Result
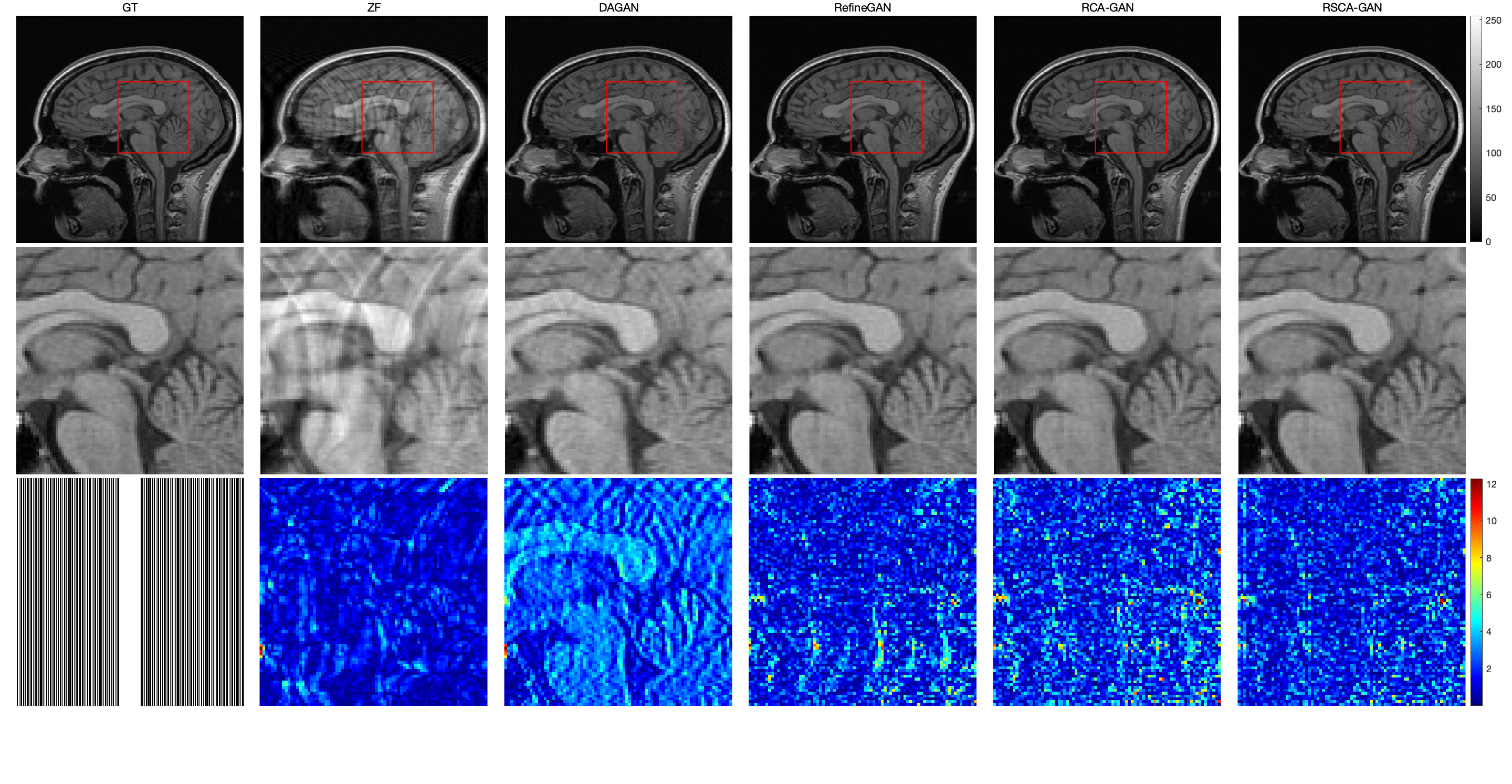
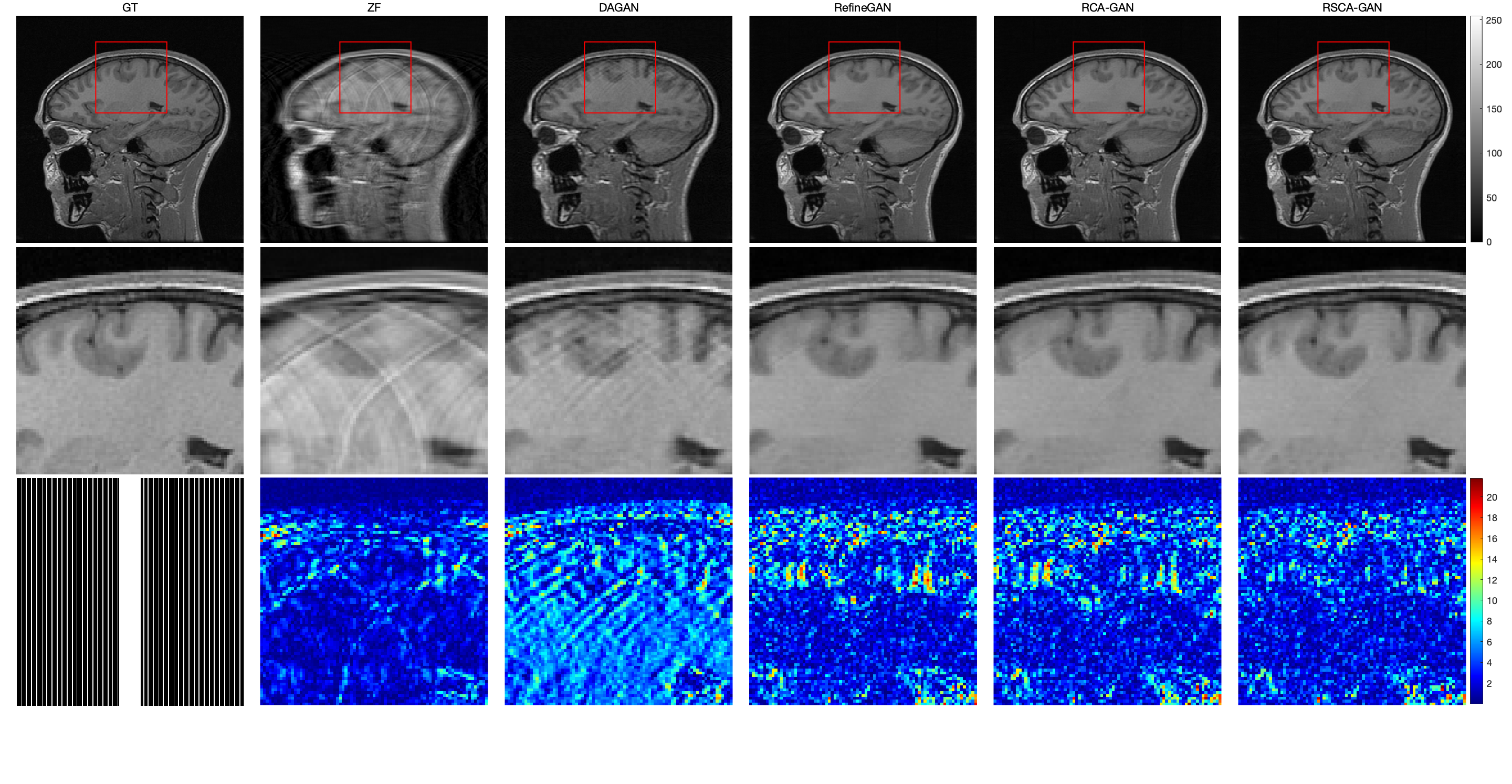
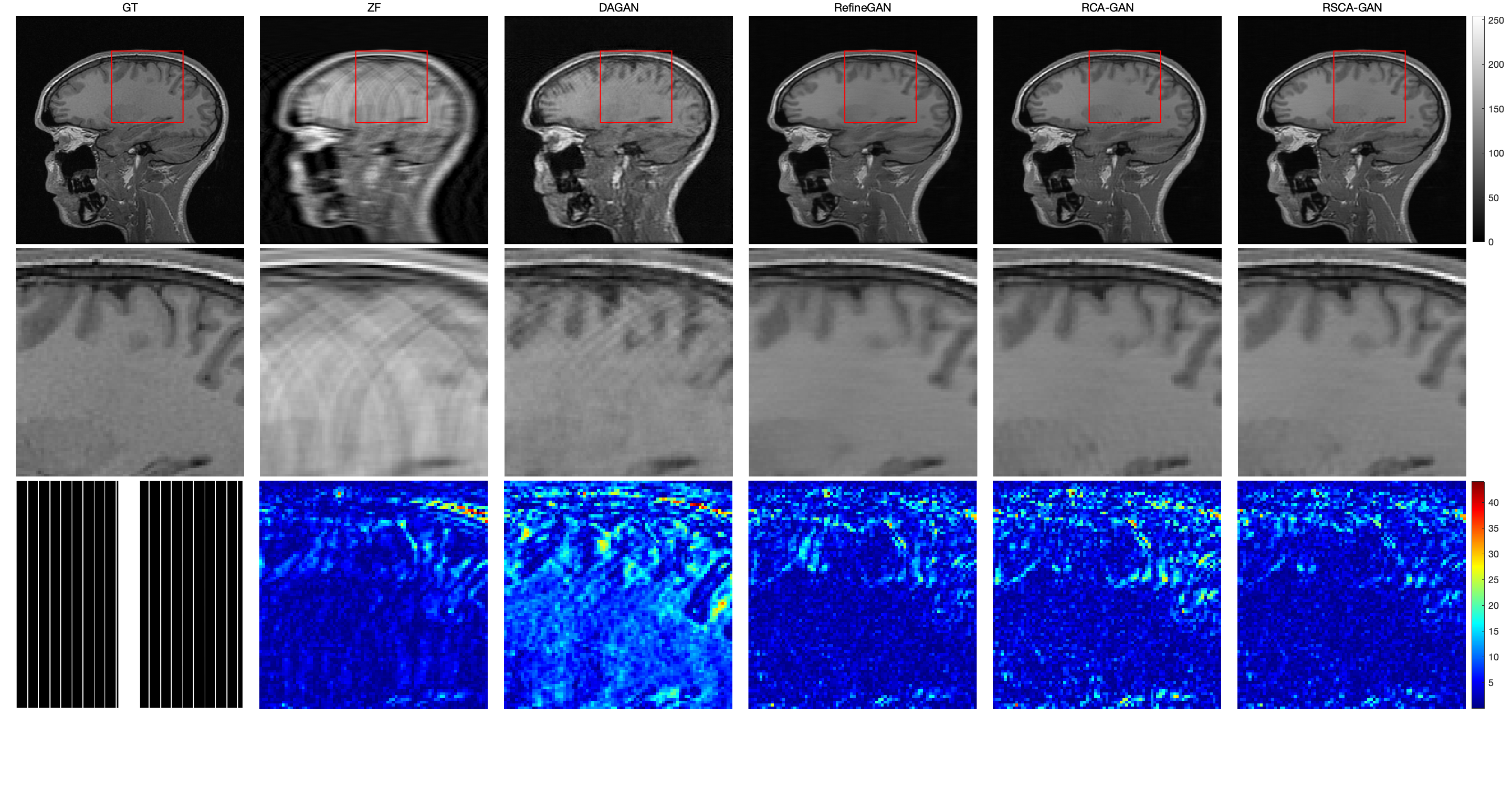
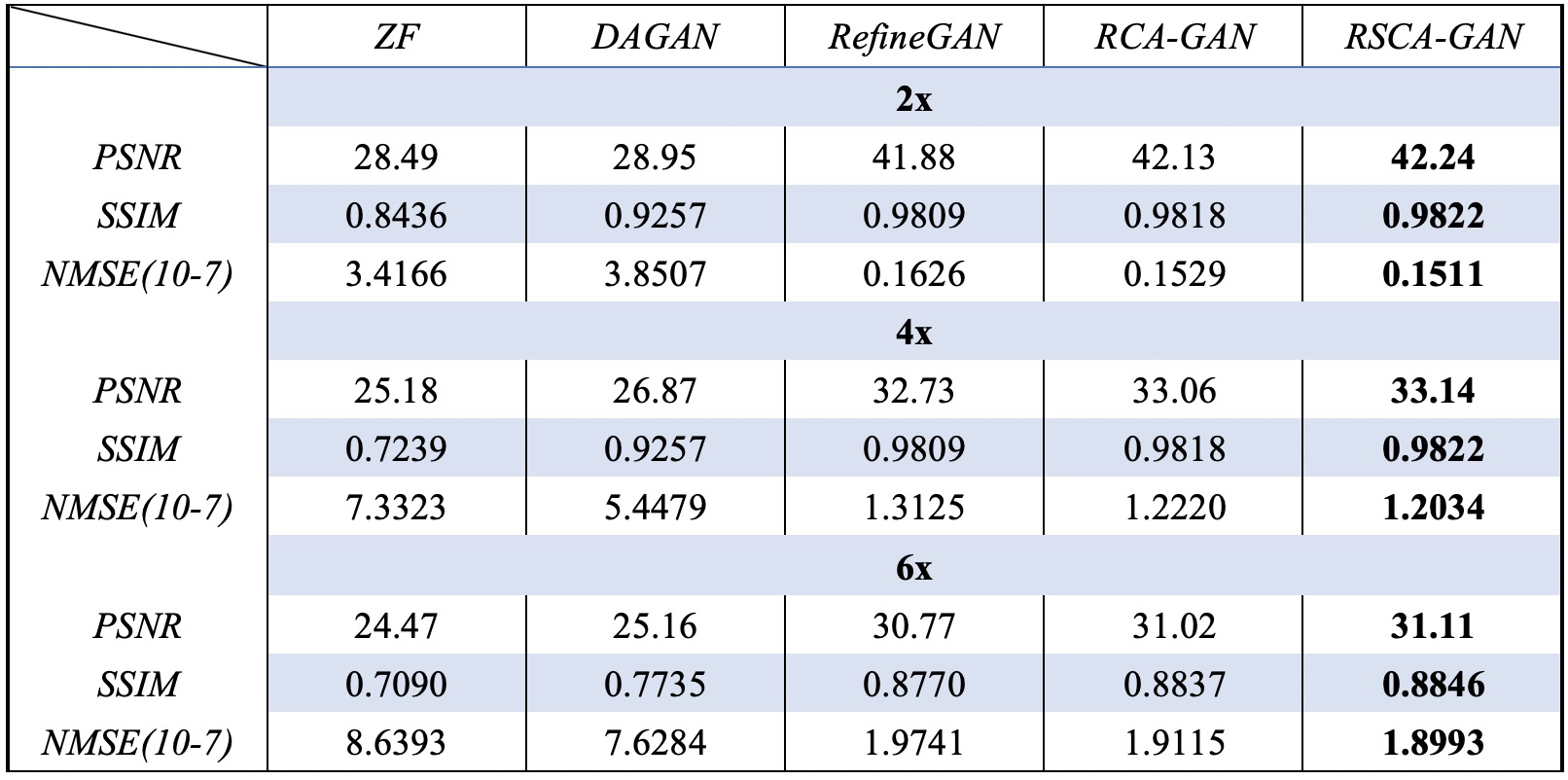
$$$\quad$$$The original image, enlarged image and error map of different reconstruction methods with an acceleration factor of 2,4,6 were recorded (Fig. 4)(Fig. 5)(Fig. 6), showing that the RSCA-GAN method was superior to other ones. The method RCA-GAN, which only uses channel-wise attention, was also compared in the previous work [3]. And they came to the conclusion that the reconstruction effect was better than the network structure without channel-wise attention. Based on that, we also listed the PSNR, SSIM, and NMSE indicators of each reconstruction method (Fig. 7), indicating that the indexes of our proposed method RSCA-GAN were better than the other methods.Furthermore, we also used the rank sum test method to make a significant difference with RefineGAN and the statistical significance was at P<0.05. The results show that the image quality after RSCA-GAN reconstruction is significantly better than RefineGAN.Conclusions
$$$\quad$$$We combined RefineGAN, spatial and channel-wise attention to propose a novel architecture for accelerating MRI reconstruction. Experimental results show that this method can generate close-to-real images from under-sampled k-space data with an acceleration factor of up to 6. According to the indicators of PSNR, SSIM, NMSE and significant difference, the reconstruction quality of the proposed method is better than that of RefineGAN method.Acknowledgements
This work was supported in part by the National Natural Science Foundation of China No.61902338.References
[1] Quan TM, Nguyen-Duc T, Jeong WK. Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss. IEEE Trans Med Imaging 2018;37:1488-97.
[2] Chen Long, Zhang Hanwang, Xiao Jun, et al. SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning. 2017 IEEE Conference on Computer Vision and Pattern Recognition.
[3] Q. Huang, D. Yang, P. Wu, et al. MRI Reconstruction Via Cascaded Channel-Wise Attention Network. 2019 IEEE 16th International Symposium on Biomedical Imaging.
[4] Yan Wua, Yajun Mab, Jing Liuc, et al. Self-attention convolutional neural network for improved MR image reconstruction. Information Sciences 490 (2019) 317–328.
Figures