1975
Progressive Volumetrization for Data-Efficient Image Recovery in Accelerated Multi-Contrast MRI1Department of Electrical and Electronics Engineering, Bilkent University, Ankara, Turkey, 2National Magnetic Resonance Research Center, Bilkent University, Ankara, Turkey, 3Department of Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, United States, 4Department of Radiology, Hacettepe University, Ankara, Turkey, 5Neuroscience Program, Aysel Sabuncu Brain Research Center, Bilkent University, Ankara, Turkey
Synopsis
The gold-standard recovery models for accelerated multi-contrast MRI either involve volumetric or cross-sectional processing. Volumetric models offer elevated capture of global context, but may yield suboptimal training due to expanded model complexity. Cross-sectional models demonstrate improved training with reduced complexity, yet may suffer from loss of global consistency in the longitudinal dimension. We propose a novel progressively volumetrized generative model (ProvoGAN) for contextual learning of image recovery in accelerated multi-contrast MRI. ProvoGAN empowers capture of global and local context while maintaining lower model complexity by performing aimed volumetric mappings via a cascade of cross-sectional mappings task-optimally ordered across rectilinear orientations.
Introduction
Magnetic resonance imaging (MRI) allows versatility to acquire volumetric images under various tissue contrasts, but prolonged data acquisitions limit the quality and diversity of the images collected. The native approach mitigating this limitation involves recovering diverse arrays of high-quality images from acquisitions undersampled across tissue contrasts1-4 or k-space5-8. The recovery methods process data either volumetrically2,3,5 or cross-sectionally1,4,6-8. Volumetric models offer advanced global consistency, yet they may manifest increased model complexity, yielding suboptimal learning. Cross-sectional models suggest reduced complexity with improved training, but they may suffer from loss of contextual consistency across the longitudinal dimension. Here we proposed a novel progressively volumetrized model9, ProvoGAN, for data-efficient image recovery in accelerated multi-contrast MRI. ProvoGAN decomposes volumetric image recovery tasks into a sequence of cross-sectional mappings optimally ordered across rectilinear orientations (Fig. 1) to effectively capture global-local details while demonstrating reduced model complexity9.Methods
Progressively Volumetrized Generative Model for MR Image RecoveryFirst Progression: Given a progression sequence of the rectilinear orientations $$$(o_1\rightarrow~o_2\rightarrow~o_3)$$$, ProvoGAN first learns a cross-sectional mapping in $$$o_1$$$ via a generator $$$(G_{o_1}:x_{o_1}^i\rightarrow\hat{y}_{p_1,\,o_1}^i)$$$ and a discriminator $$$(D:\{x_{o_1}^i,\,y_{o_1}^i\}\rightarrow[0,1]\,$$$and$$$\,\{x_{o_1}^i,\,\hat{y}_{p_1,\,o_1}^i\}\rightarrow[0,1])$$$, where $$$x_{o_1}^i-y_{o_1}^i$$$ denote the $$$i$$$th cross-sections in $$$o_1$$$ of the source$$$-$$$target volumes, and $$$\hat{y}_{p_1,\,o_1}^i$$$ denotes the $$$i$$$th cross-section of the target volume in $$$o_1$$$ recovered in the first progression. $$$G_{o_1}$$$ and $$$D_{o_1}$$$ are trained with adversarial and pixel-wise losses:$${L_{p_1}=\underbrace{\mathrm{E}_{x_{o_1}^i,y_{o_1}^i}[|y_{o_1}^i-\hat{y}_{p_1,o_1}^i|]}_{\mathrm{pixel-wise\,loss}}-\underbrace{\mathrm{E}_{x_{o_1}^i,y_{o_1}^i}[(1-D_{o_1}(x_{o_1}^i,y_{o_1}^i))^2]-\mathrm{E}_{x_{o_1}^i}[D_{o_1}(x_{o_1}^i,\hat{y}_{p_1,o_1}^i)^2]}_{\mathrm{adversarial\,loss}}}$$Once $$$L_{p_1}$$$ is optimized, $$$I$$$ cross-sections in $$$o_1$$$ are separately recovered, and then reformatted with a concatenation block $$$f$$$ to generate the target volume:$${\hat{Y}_{p_1}={f(\hat{y}_{p_1,o_1}^1,\hat{y}_{p_1,o_1}^2,\dots,\hat{y}_{p_1,o_1}^I)}}$$Second Progression: ProvoGAN then learns a separate recovery model in $$$o_2$$$ to progressively enhance global and local context: $$$\hat{y}_{p_2,o_2}^j=G_{o_2}(x_{o_2}^j,\hat{y}_{p_1,o_2}^j)$$$, where $$$x_{o_2}^j-\hat{y}_{o_2}^j$$$ denote the $$$j$$$th cross-sections of the source and recovered target volumes in $$$o_2$$$, and $$$\hat{y}_{p_1,o_2}^j$$$ denotes the $$$j$$$th cross-section in $$$o_2$$$ of the previously recovered volume incorporated to further leverage priors. $$$G_{o_2}$$$ and $$$D_{o_2}$$$ are again trained in an adversarial setup.
Third Progression: ProvoGAN lastly performs a cross-sectional mapping in $$$o_3$$$ with a third generator $$$G_{o_3}$$$ receiving as input cross-sections of the source and previously recovered target volumes: $$$\hat{y}_{p_3,o_3}^k=G_{o_3}(x_{o_3}^k,\hat{y}_{p_2,o_3}^k)$$$, where $$$x_{o_3}^k-\hat{y}_{o_3}^k$$$ denote the $$$k$$$th cross-sections of the source and recovered target volumes in $$$o_3$$$. An adversarial setup is used in this progression. The final output of ProvoGAN is then generated by concatenating the recovered $$$K$$$ separate cross-sections in $$$o_3$$$:$${\hat{Y}_{p_3}={f(\hat{y}_{p_3,o_3}^1,\hat{y}_{p_3,o_3}^2,\dots,\hat{y}_{p_3,o_3}^K)}}$$where $$$\hat{Y}_{p_3}$$$ denotes the final output volume recovered by ProvoGAN. In MRI reconstruction, consistency of the recovered and acquired k-space coefficients is ensured as follows:$$\mathcal{F}_u(\hat{Y}_{p_n}):=\mathcal{F}_u(X)$$where $$$\mathcal{F}_u$$$ denotes the Fourier operator, and $$$n$$$ denotes the ongoing progression index.
Implementation Details
Each cross-sectional model in ProvoGAN contained a generator with $$$3$$$ conv-layers, $$$9$$$ ResNet blocks, and $$$3$$$ conv-layers, and a discriminator with $$$5$$$ conv-layers in series. Trainings were continued for $$$100$$$ epochs with a batch size of $$$1$$$. Learning rate was $$$0.0002$$$ in the first $$$50$$$ epochs, and linearly decreased to $$$0$$$ in the remaining epochs with the ADAM optimizer $$$(\beta_1=0.5,\,\beta_2=0.999)$$$. Comprehensive experiments were performed on the IXI dataset10 $$$(\mathrm{T_1}-,\,\mathrm{T_2}-$$$weighted images of $$$52$$$ subjects, training: $$$37$$$, validation: $$$5$$$, test: $$$10$$$) to demonstrate recovery quality of ProvoGAN on two synthesis tasks: $$$\mathrm{T_1}\rightarrow\mathrm{T_2}$$$ and $$$\mathrm{T_2}\rightarrow\mathrm{T_1}$$$ and two reconstruction tasks: $$$\mathrm{T_1\,(R=4,8)}\rightarrow\mathrm{T_1\,(R=1)}$$$ and $$$\mathrm{T_2\,(R=4,8)}\rightarrow\mathrm{T_2\,(R=1)}$$$, $$$R$$$ denoting acceleration rate. Optimal progression sequence of ProvoGAN was determined to be $$$(C\rightarrow~A\rightarrow~S)$$$ for $$$\mathrm{T_1}\rightarrow\mathrm{T_2}$$$, $$$(S\rightarrow~A\rightarrow~C)$$$ for $$$\mathrm{T_2}\rightarrow\mathrm{T_1}$$$, $$$(C\rightarrow~A\rightarrow~S)$$$ for $$$\mathrm{T_1\,(R=4)}\rightarrow\mathrm{T_1\,(R=1)}$$$, $$$(A\rightarrow~C\rightarrow~S)$$$ for $$$\mathrm{T_1\,(R=8)}\rightarrow\mathrm{T_1\,(R=1)}$$$, $$$(C\rightarrow~S\rightarrow~A)$$$ for $$$\mathrm{T_2\,(R=4)}\rightarrow\mathrm{T_2\,(R=1)}$$$, and $$$(A\rightarrow~C\rightarrow~S)$$$ for $$$\mathrm{T_2\,(R=8)}\rightarrow\mathrm{T_2\,(R=1)}$$$, where $$$A$$$ denotes axial, $$$C$$$ coronal, and $$$S$$$ sagittal orientations. ProvoGAN was evaluated against cross-sectional sGAN and volumetric vGAN models. The network architectures and hyperparameters of these models were adopted from a previous study successfully demonstrated for MRI recovery1, where the 2D conv-layers used for sGAN were replaced with 3D ones for vGAN. Separate sGAN models were trained for each individual orientation in synthesis (sGAN-A: axial, sGAN-C: coronal, sGAN-S: sagittal), whereas a single sGAN model was trained for the transverse orientation (axial) in reconstruction.
Results
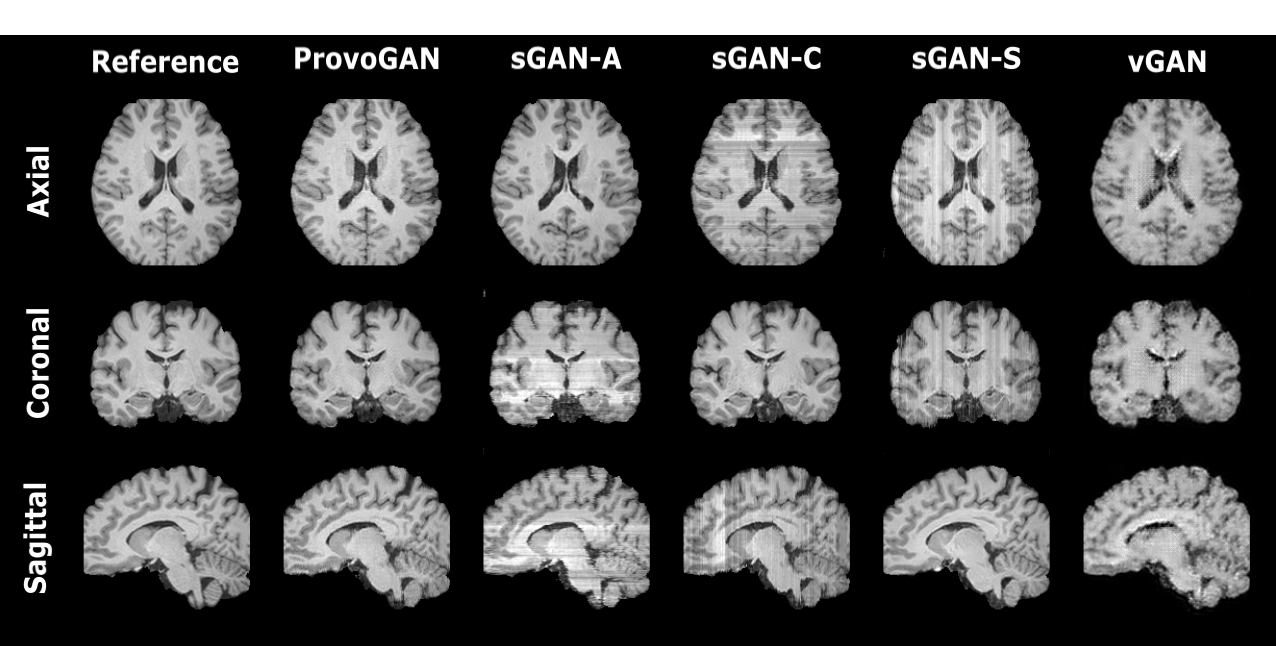
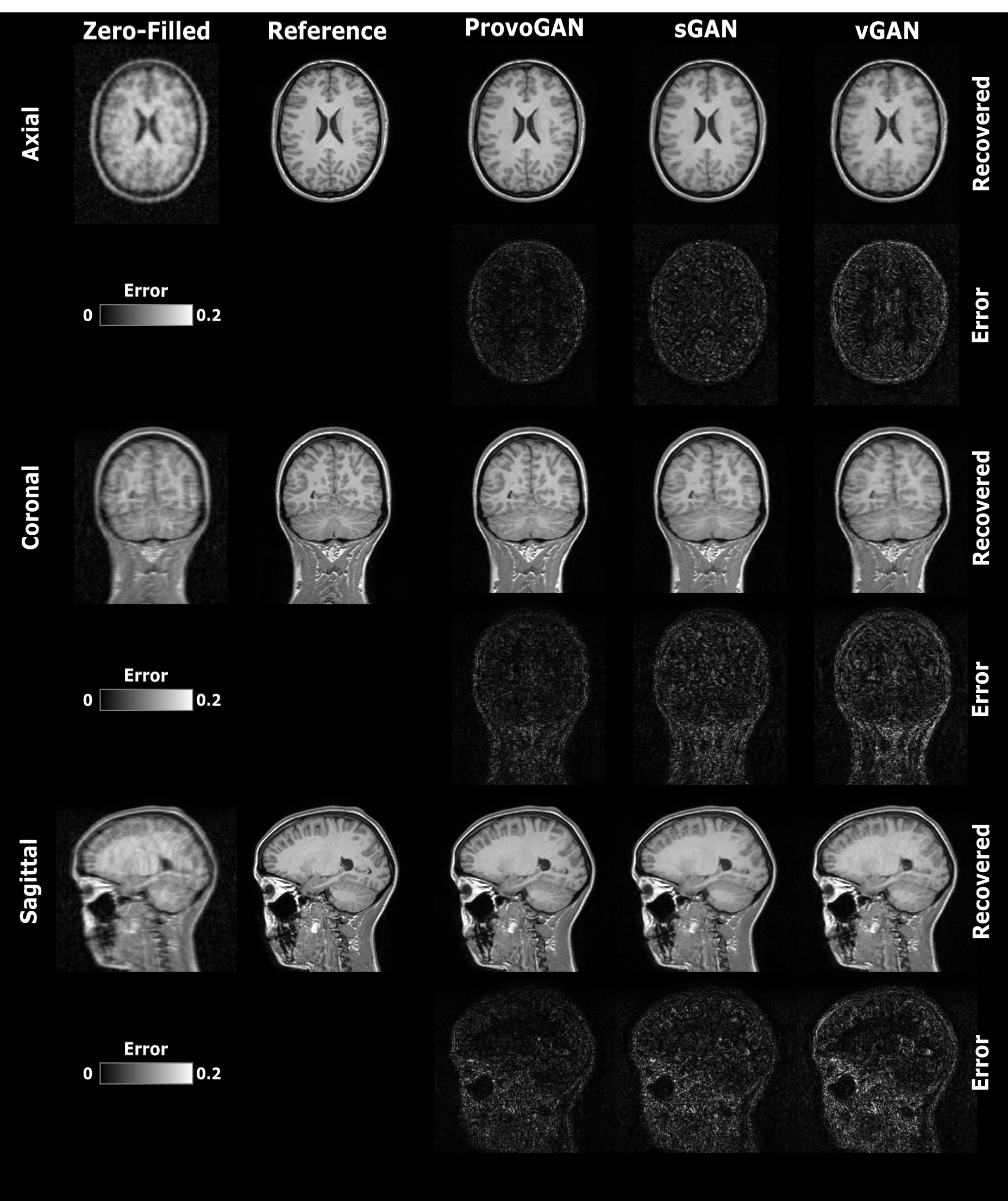
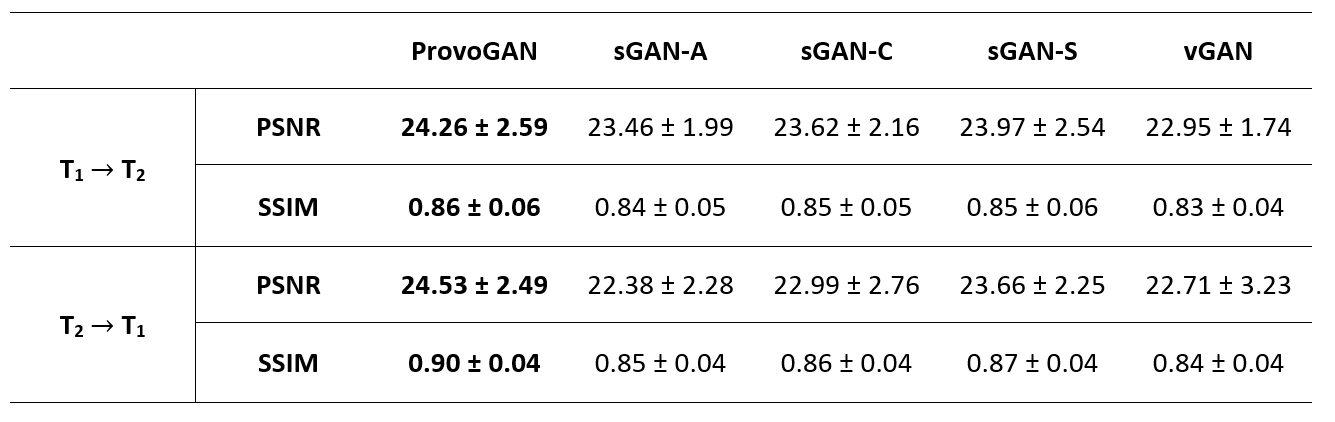
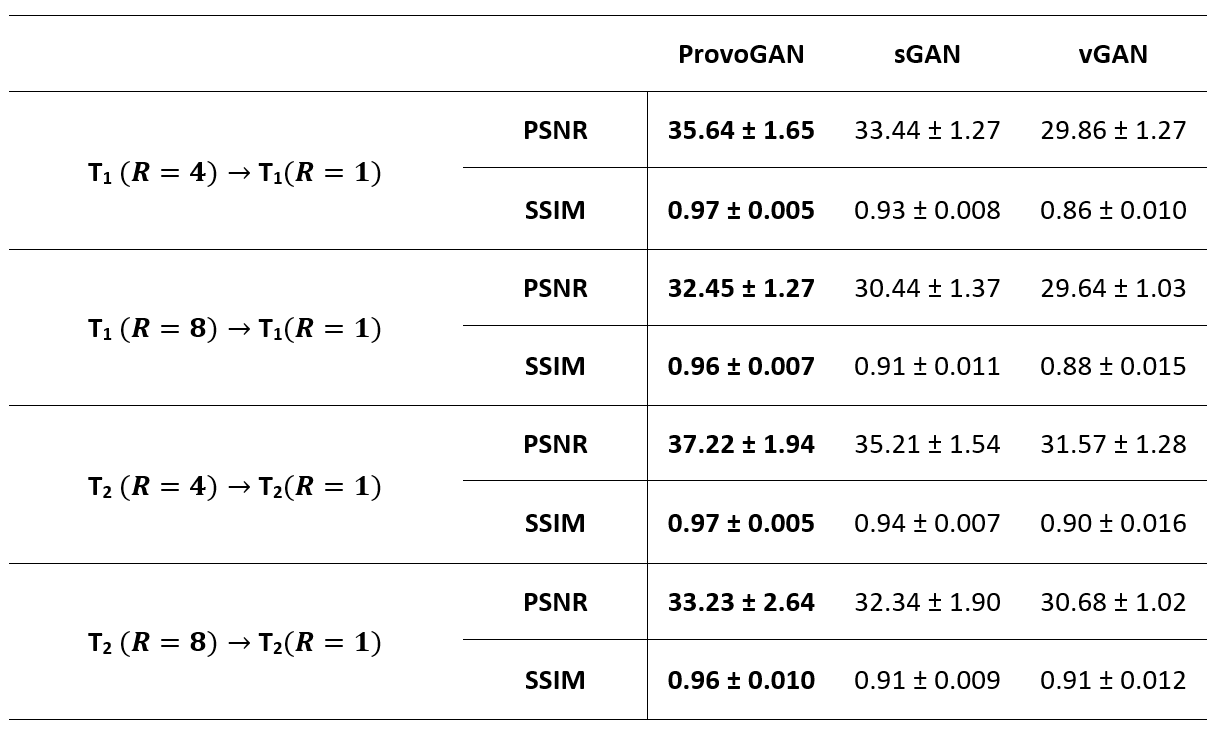
We first performed demonstrations on the synthesis tasks $$$(\mathrm{T_1}\rightarrow\mathrm{T_2}\,$$$and$$$\mathrm{T_2}\rightarrow\mathrm{T_1})\,$$$in IXI. Table 1 lists the volumetric PSNR$$$-$$$ measurements of the models under comparison, where ProvoGAN achieves $$$0.58\,dB$$$ higher PSNR and $$$\%2.32$$$ higher SSIM compared to the second-best method, on average. Representative results are displayed in Fig. 2 for $$$\mathrm{T_1}$$$-weighted image synthesis.Next, we demonstrated the reconstruction quality of ProvoGAN in IXI $$$(\mathrm{T_1\,(R=4,8)}\rightarrow\mathrm{T_1\,(R=1)}\,$$$and$$$\,\mathrm{T_2\,(R=4,8)}\rightarrow\mathrm{T_2\,(R=1)})$$$. PSNR$$$-$$$SSIM measurements reported in Table 2 for the reconstruction tasks indicate that ProvoGAN yields, on average, $$$1.78\,dB$$$ higher PSNR, and $$$\%4.61$$$ higher SSIM compared to the second-best method. Representative results are displayed in Fig. 3 for $$$\mathrm{T_1}$$$-weighted image reconstruction.
The overall results suggest that sGAN suffers from suboptimal recovery in the longitudinal dimensions due to loss of contextual consistency, whereas vGAN suffers from poor recovery of fine-structural details and deteriorated resolution due to expanded model complexity with suboptimal learning behaviour. Meanwhile, ProvoGAN advances capture of global consistency in all rectilinear orientations via progressively volumetrized cross-sectional mappings and offers enhanced recovery of fine-structural details by manifesting reduced complexity.
Discussion
Here, we introduced a progressively volumetrized model (ProvoGAN) for image recovery in MRI. ProvoGAN decomposes volumetric image recovery tasks into a task-optimally ordered series of simpler cross-sectional mappings which empowers ProvoGAN to leverage global contextual information and enhance fine-structural details in each orientation while maintaining reduced complexity.Conclusion
The proposed method holds a great promise to advance practicality and utility of MR image recovery.Acknowledgements
This work was supported in part by a TUBA GEBIP fellowship, by a TUBITAK 1001 Grant (118E256), by a BAGEP fellowship, and by NVIDIA with a GPU donation.
References
1. Dar SUH, Yurt M, Karacan L, Erdem A, Erdem E, Cukur T. Image Synthesis in Multi-Contrast MRI with Conditional Generative Adversarial Networks. IEEE Transactions on Medical Imaging. 2019;38(10):2375-2388.
2. Yu B, Zhou L, Wang L, Shi Y, Fripp J, Bourgeat P. Ea-GANs: edge-aware generative adversarial networks for cross-modality MR image synthesis. IEEE Transactions on Medical Imaging. 2019;38(7):1750–1762.
3. Yang H, Lu X, Wang SH, Lu Z, Yao J, Jiang Y, Qian P. Synthesizing multi-contrast MR images via novel 3D conditional variational auto-encoding GAN. Mobile Networks and Applications. 2020.
4. Lee D, Kim J, Moon W, Ye JC. Collagan: Collaborative GAN for missing image data imputation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019;2482–2491.
5. Malave MO, Baron CA, Koundinyan SP, Sandino CM, Ong F, Cheng JY, Nishimura DG. Reconstruction of undersampled 3D non-cartesian image-based navigators for coronary MRA using an unrolled deep learning model. Magnetic Resonance in Medicine. 2020;84(2):800–812.
6. Akcakaya M, Moeller S, Weingartner S, Ugurbil K. Scan-specific robust artificial-neural-networks for k-space interpolation (RAKI) reconstruction: Database-free deep learning for fast imaging. Magnetic Resonance in Medicine. 2019;81(1): 439–453.
7. Lee D, Yoo J, Tak S, Ye JC. Deep residual learning for accelerated MRI using magnitude and phase networks. IEEE Transactions on Biomedical Engineering. 2018;65(9):1985–1995.
8. Mardani M, Gong E, Cheng JY, Vasanawala S, Zaharchuk G, Alley M, Thakur N, Han S, Dally W, Pauly JM, Xing L. Deep generative adversarial neural networks for compressive sensing MRI. IEEE Transactions on Medical Imaging, 2019;38(1):167–179.
9. Yurt M, Ozbey M, Dar SUH, Tinaz B, Oguz KK, Cukur T. Progressively Volumetrized Deep Generative Models for Data-Efficient Contextual Learning of MR Image Recovery. arXiv:2011.13913, preprint. 2020.
10. https://brain-development.org/ixi-dataset/
Figures
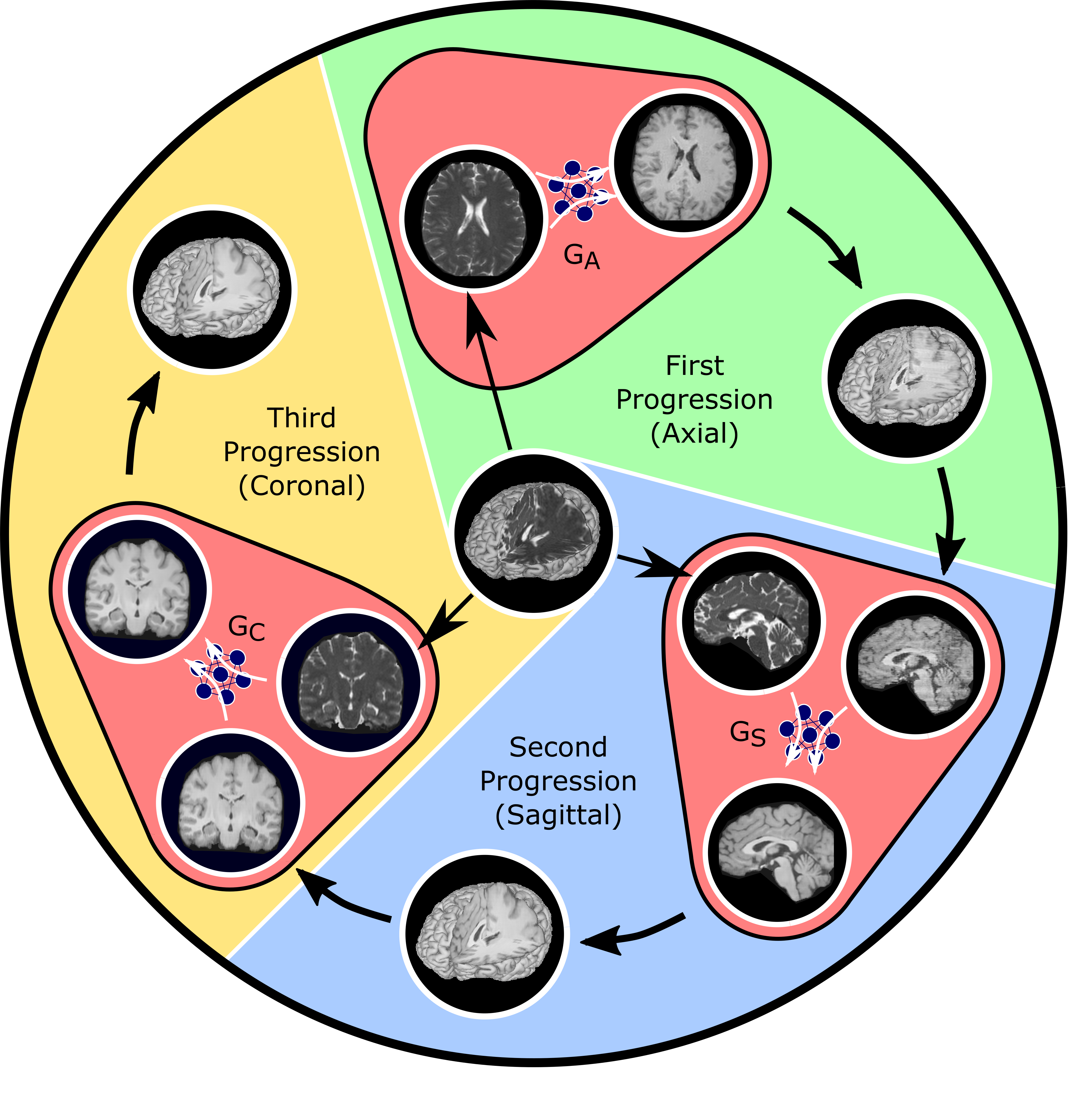
Fig. 1: ProvoGAN performs a series of cross-sectional subtasks optimally-ordered across individual rectilinear orientations (Axial$$$\rightarrow$$$Sagittal$$$\rightarrow$$$Coronal illustrated here) to handle the aimed volumetric recovery task. Within a given subtask, source-contrast volume is divided into cross-sections across the longitudinal dimension, and a cross-sectional mapping is learned to recover target cross-sections from source cross-sections, where the previous subtask's (if available) output is further incorporated to leverage contextual priors.