1968
Adaptive convolutional neural networks for accelerating magnetic resonance imaging via k-space data interpolation1Radiology, University of Pennsylvania, Philadelphia, PA, United States, 2Beijing University of Posts and Telecommunications, Beijing, China
Synopsis
Deep learning in k-space has demonstrated great potential for image reconstruction from undersampled k-space data. However, existing deep learning-based image reconstruction methods typically apply weight-sharing convolutional neural networks to k-space data without taking into consideration the k-space data’s spatial frequency properties, leading to ineffective learning of the image reconstruction models. To improve image reconstruction performance, we develop a residual Encoder-Decoder network architecture with self-attention layers to adaptively focus on k-space data at different spatial frequencies and channels for interpolating the undersampled k-space data. Experimental results demonstrate that our method achieves significantly better image reconstruction performance than current state-of-the-art techniques.
INTRODUCTION
Deep learning (DL) in k-space has demonstrated great potential for image reconstruction from undersampled k-space data with the potential to drastically reduce scan times. Existing deep learning-based reconstruction methods typically apply weight-sharing convolutional neural networks (CNNs) without taking into consideration characteristics of the k-space data. Data at the central k-space region contain most of the information of image contrast, while those more distant from the center mostly contain information about the edges and boundaries of an image. Thus, taking into account the distinctive contributions of different spatial frequencies of the k-space data to the image reconstruction can potentially lead to more effective learning of CNNs. Although a fixed weighting map can be adopted as a weighting layer to modulate the output of CNNs,1 it would be more desirable to obtain a weighting map capable of adaptively adjusting the output of CNNs to better interpolate the missing k-space samples. In addition, in multi-coil acquisitions, different coils are sensitive to different regions of the object but are often treated simply as multiple channels in existing k-space DL methods, which may be sub-optimal in achieving the best possible performance. In order to overcome the aforementioned limitations, we develop a novel k-space deep learning framework for image reconstruction from undersampled k-space data, referred to as adaptive convolutional neural networks for k-space data interpolation (ACNN-k-Space).METHODS
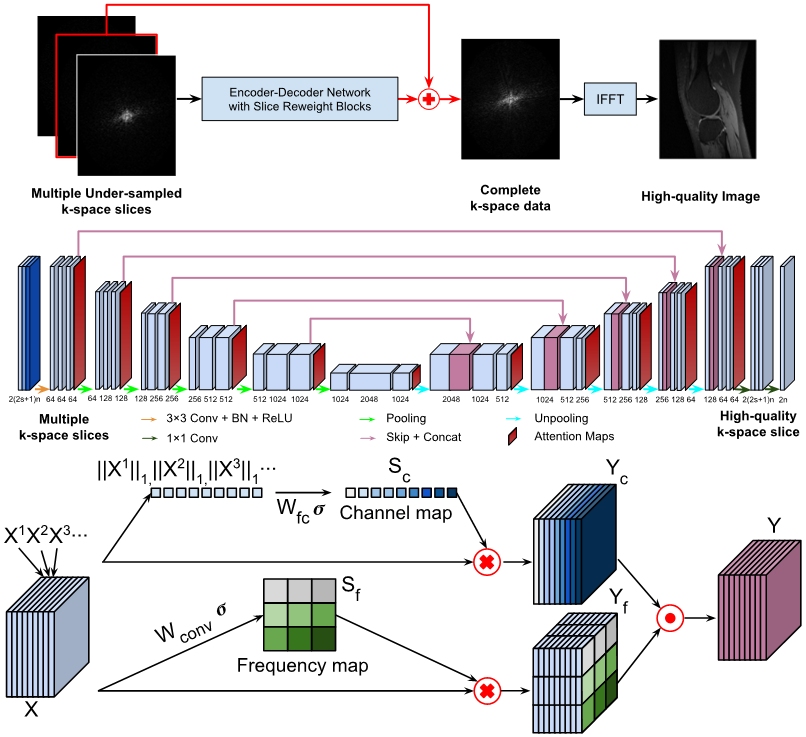
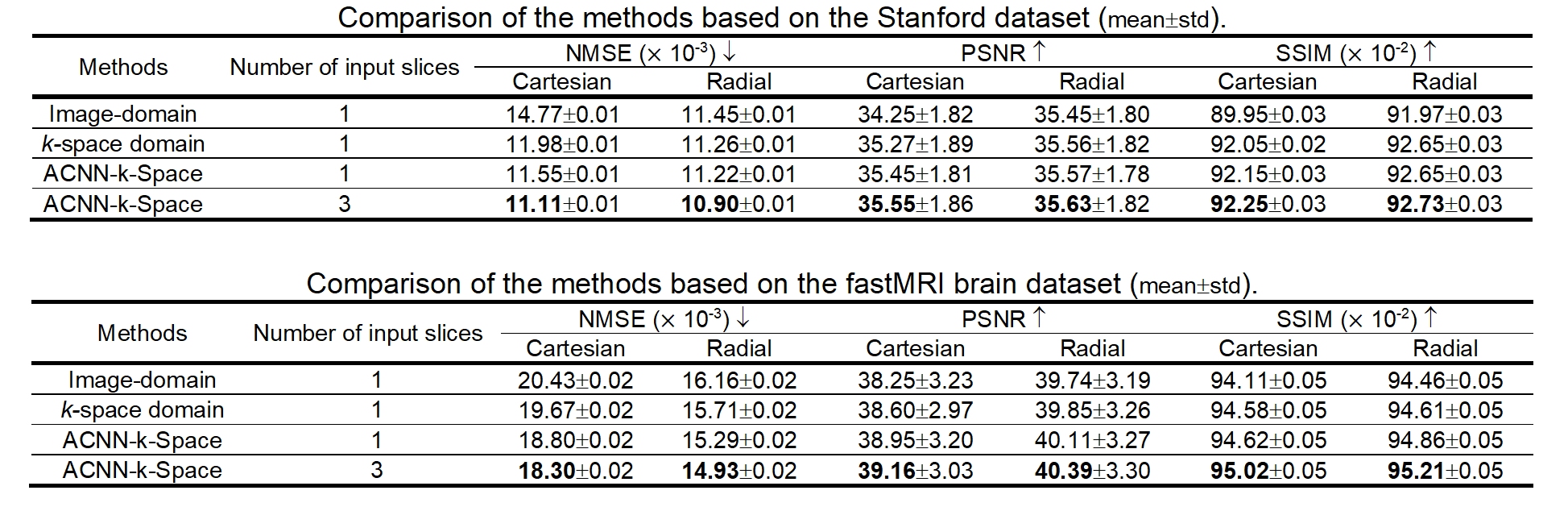
ACNN-k-Space is a residual Encoder-Decoder network architecture for interpolating undersampled k-space data with CNNs enhanced by a self-attention layer,2 referred to as frequency-attention layer, which adaptively assigns weights to features learned by CNNs for k-space samples at different spatial frequencies. Moreover, instead of independent learning of each imaging slice, our method learns an interpolation for each image slice by integrating neighboring slices as a multi-channel input, along with k-space data from multiple coils to the residual network. Since the slices may contribute to the reconstruction differently and data from different coils are sensitive to different regions of the object, we adopt another self-attention layer, referred to as channel-attention layer, to adaptively assign weights to features learned by CNNs for different channels. Similar to recent methods that adopt channel-wise attention to modulate learned features in either k-space or image domain,3, 4 the channel-attention layers are also applied to all learned features in addition to the input slices. Together, the residual Encoder-Decoder network with frequency- and channel-attention layers learns an interpolation for undersampled k-space data and reconstructs images in conjunction with inverse FFT in an end-to-end fashion. We have evaluated our method based on two publicly available datasets: Stanford Fully Sampled 3D FSE Knee k-space Dataset and fastMRI Brain Dataset.5, 6 The datasets were randomly split into training (80%), validation (10%), and testing datasets (10%) for evaluation. The images were undersampled using a Cartesian trajectory with a Gaussian random pattern and a 3x undersampling and a Radial trajectory with a 4x undersampling. We compared our method with state-of-the-art DL methods, including k-space deep learning1 and an image domain DL method.7 We adopted Structural SIMilarity (SSIM) index, peak signal-to-noise ratio (PSNR), and normalized mean square error (NMSE) to evaluate performance.RESULTS
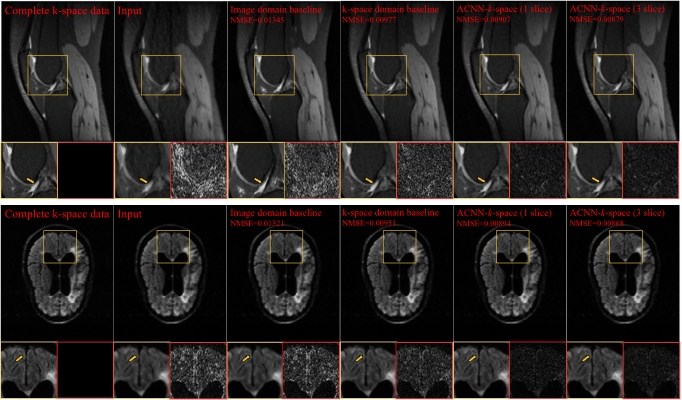
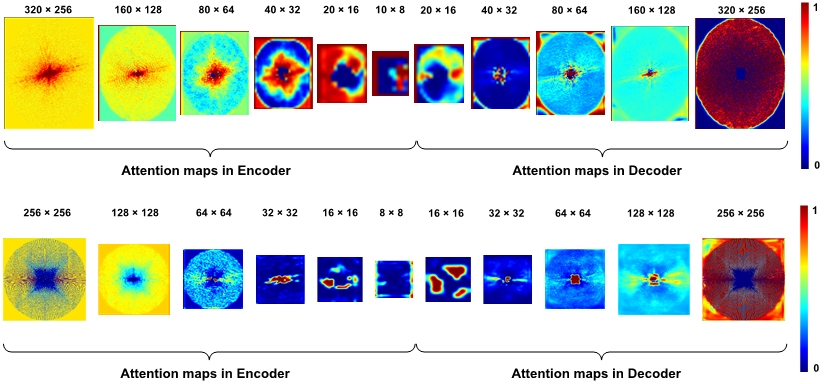
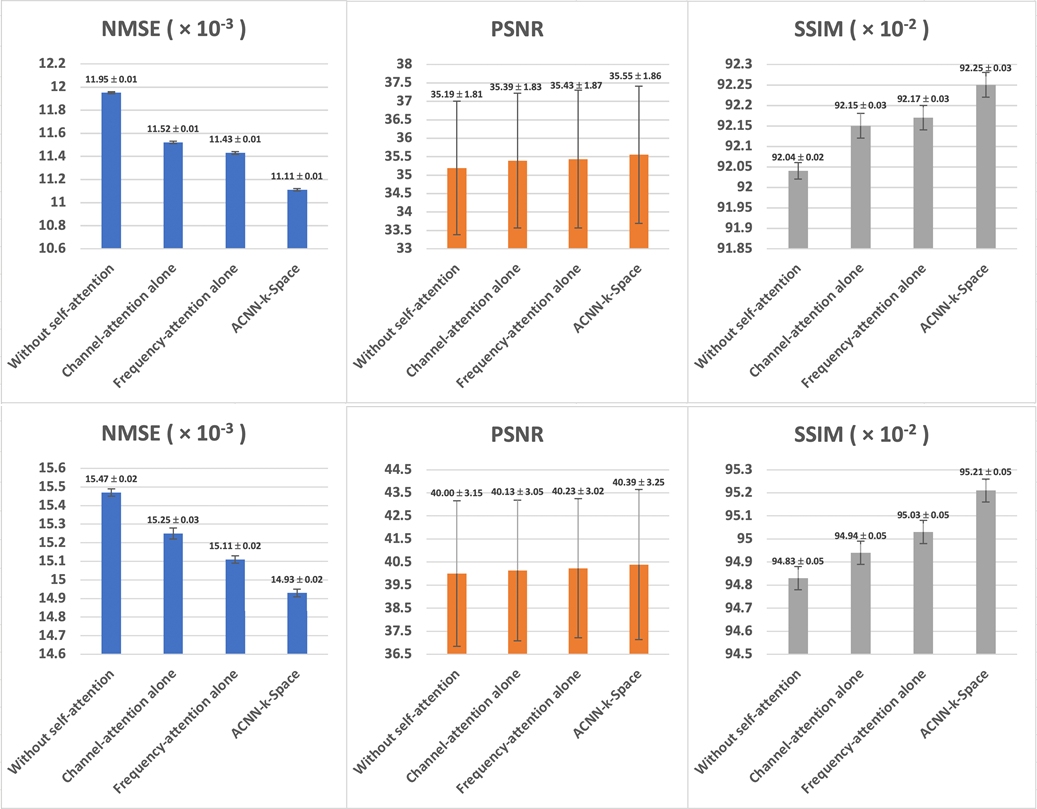
Figure-1 illustrates network architecture of ACNN-k-Space. Figure-2 shows representative results from the comparisons. Consistent with the quantitative results summarized in Figure-3, our method yielded visually better results than the existing methods. In particular, the DL model in image domain yielded a slightly oversmoothed image around the region indicated by the arrows. Further, as the difference images demonstrate, images reconstructed by ACNN-k-Space are substantially more similar to those from the complete k-space data compared with those reconstructed by the existing image domain or the k-space DL methods. Figure-4 shows representative frequency-attention maps learned by our method with the number of input slices set to three for image reconstruction from undersampled k-space data using Cartesian sampling based on the Stanford dataset (top row) and radial sampling based on the fastMRI dataset (bottom row), illustrating that k-space data at different spatial frequencies contributed differently to the image reconstruction. Figure-5 show ablation study results on both the Stanford dataset and the fastMRI brain dataset, indicating that ACNN-k-Space with both frequency- and channel-attention layers yielded the best performance measures with statistical significance, while the k-space deep learning methods utilizing one attention layer still outperformed those without the self-attention layers.DISCUSSION
Our network is built upon the standard residual Encoder-Decoder network architecture, which could be improved by adopting other network architectures, network blocks, and advanced learning strategies, such as Dense block,8 or instance normalization,9 in conjunction with advanced loss function.10 Additional evaluation results also demonstrated that the attention layers improved the image reconstruction performance of KIKI-Net and Hybrid-Net11, 12 compared with their original version with statistical significance, indicating that the attention layers might be useful as a plugin component in other k-space deep learning methods to improve the image reconstruction performance.CONCLUSION
Our method has the potential to substantially reduce MRI scan times without compromising image fidelity. Ablation studies and experimental results show that our method could effectively reconstruct images from undersampled k-space data and achieve better image reconstruction performance than existing state-of-the-art techniques.Acknowledgements
Research reported in this study was partially supported by the National Institutes of Health under award number [R01EB022573, R01MH120811, and U24CA231858]. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.References
1. Han Y, Sunwoo L, Ye JC. k -Space Deep Learning for Accelerated MRI. IEEE Trans Med Imaging. 2020;39(2):377-86. Epub 2019/07/10. doi: 10.1109/TMI.2019.2927101. PubMed PMID: 31283473.
2. Hu J, Shen L, Sun G, editors. Squeeze-and-Excitation Networks. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018 18-23 June 2018.
3. Lee J, Kim H, Chung H, Ye JC, editors. Deep Learning Fast MRI Using Channel Attention in Magnitude Domain. 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI); 2020 3-7 April 2020.
4. Huang Q, Yang D, Wu P, Qu H, Yi J, Metaxas D, editors. MRI reconstruction via cascaded channel-wise attention network. 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019); 2019: IEEE.
5. Stanford Fully Sampled 3D FSE Knee k-space Dataset, available at http://mridata.org/ 2020 [cited 2020].
6. fastMRI Brain Dataset, available at https://fastmri.org 2020 [cited 2020].
7. Han Y, Yoo J, Kim HH, Shin HJ, Sung K, Ye JC. Deep learning with domain adaptation for accelerated projection‐reconstruction MR. Magnetic resonance in medicine. 2018;80(3):1189-205.
8. Huang G, Liu Z, Maaten Lvd, Weinberger KQ. Densely connected convolutional networks. 2017 IEEE Conference on Computer Vision and Pattern Recognition, pp 4700-47082017.
9. Ulyanov D, Vedaldi A, Lempitsky V. Instance normalization: The missing ingredient for fast stylization. arXiv preprint arXiv:160708022. 2016.
10. Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken A, Tejani A, Totz J, Wang Z, editors. Photo-realistic single image super-resolution using a generative adversarial network. Proceedings of the IEEE conference on computer vision and pattern recognition; 2017.
11. Eo T, Jun Y, Kim T, Jang J, Lee HJ, Hwang D. KIKI‐net: cross‐domain convolutional neural networks for reconstructing undersampled magnetic resonance images. Magnetic resonance in medicine. 2018;80(5):2188-201.
12. Souza R, Lebel RM, Frayne R, editors. A hybrid, dual domain, cascade of convolutional neural networks for magnetic resonance image reconstruction. International Conference on Medical Imaging with Deep Learning; 2019.
Figures