1965
Zero-shot Learning for Unsupervised Reconstruction of Accelerated MRI Acquisitions1Department of Electrical and Electronics Engineering, Bilkent University, Ankara, Turkey, 2National Magnetic Resonance Research Center, Bilkent University, Ankara, Turkey, 3Neuroscience Program, Aysel Sabuncu Brain Research Center, Bilkent University, Ankara, Turkey
Synopsis
A popular framework for reconstruction of undersampled MR acquisitions is deep neural networks (DNNs). DNNs are typically trained in a supervised manner to learn mapping between undersampled and fully sampled acquisitions. However, this approach ideally requires training a separate network for each set of contrast, acceleration rate, and sampling density, which introduces practical burden. To address this limitation, we propose a style generative model that learns MR image priors given fully sampled training dataset of specific contrast. Proposed approach is then able to efficiently recover undersampled acquisitions without any training, irrespective of the image contrast, acceleration rate or undersampling pattern.
Introduction
Recent deep learning methods for accelerated MRI are generally based on supervised conditional models that are trained to recover fully-sampled ground truth given the corresponding undersampled acquisitions1-8. As these methods rest on paired datasets containing matching undersampled and fully-sampled data, a separate model has to be trained to account for potential changes in image contrast, acceleration rate or k-space sampling density which may prove impractical due to computational burden or lack of data. To address this limitation, here we propose a zero-shot learning approach for accelerated MRI reconstructions (ZSL-Net). The proposed approach leverages a style-generative model that learns latent structural priors from DICOM images available in public MRI databases. Reconstruction of undersampled acquisitions is then cast as an identification problem, where latent representations in the style-generative model are optimized on the test sample to ensure data consistency.Methods
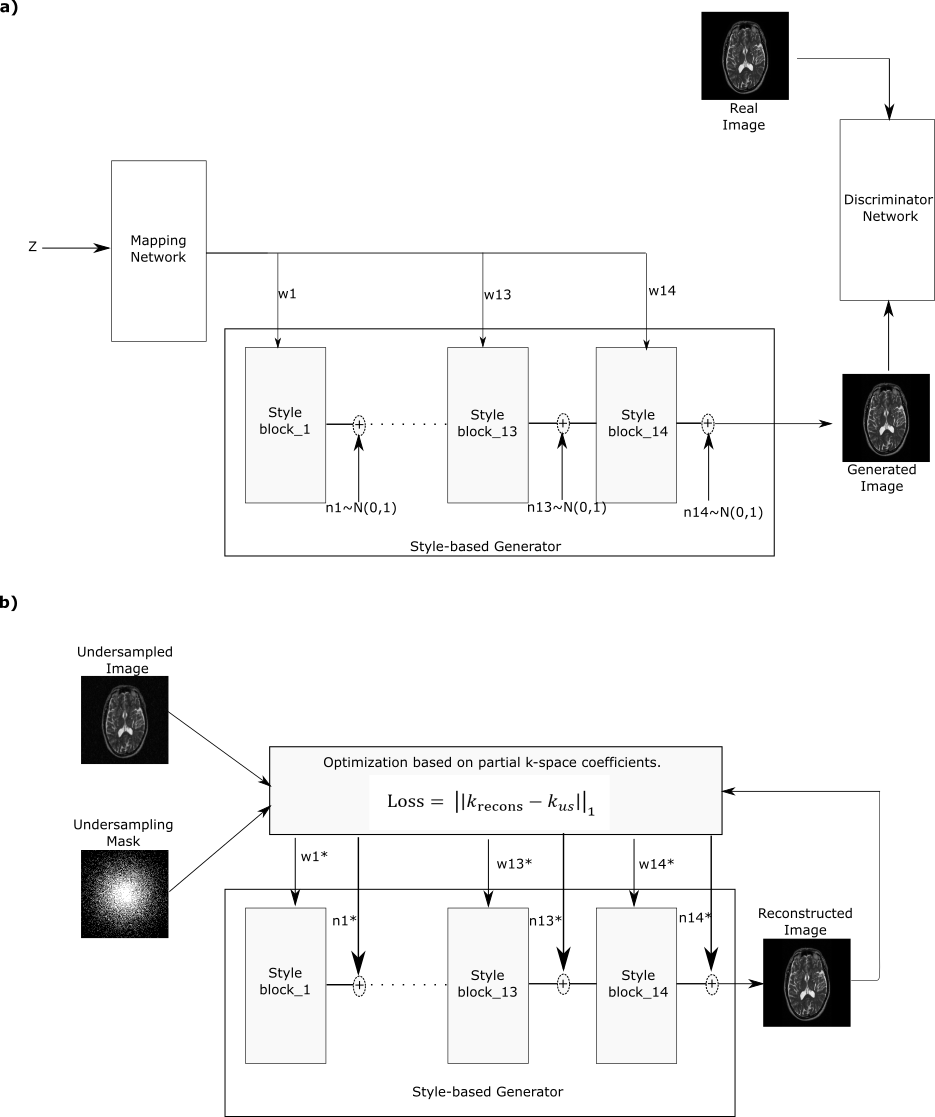
In pre-training, ZSL-Net employs a style-generative model to capture structural MRI priors (see Fig. 1). This model contains three subnetworks: a synthesizer, a mapper, and a discriminator9. The synthesizer is trained to draw random sample images from a learned distribution of fully-sampled MR images. A progressive training strategy is leveraged to increase synthesis resolution gradually. Each progression also receives a latent code w to control style at each resolution and has a noise component n that reflects information on fine details. Therefore, the network can learn coarse to fine styles and generate out-of-distribution images via style-mixing. The mapper transforms a random latent z to the intermediate latent code w to be input to the synthesizer as opposed to traditional GANs, which improves invertibility between generated image and latent space10,11. The discriminator is also trained progressively to separate synthesized from real images.In testing, ZSL-Net reconstructs undersampled MRI acquisitions without any task-specific, supervised training. To do this, it optimizes w and n of the synthesizer in the style-generative model to ensure consistency between acquired and recovered k-space coefficients in the test sample. The optimization problem can be formulated as:
$$\hat{R}\left(w,n\right)=\ arg\min_{w,\ n}{\left|\left|F_uS\left(w,n\right)-k_{us}\right|\right|_1}$$
where $$$\hat{R}$$$: reconstructed image, $$$k_{us}$$$: undersampled k-space coefficients, $$$F_u$$$: partial Fourier operator, $$$S$$$: synthesizer, $$$w$$$: latent variables and $$$n$$$: noise components.
Here, the style-generative model was trained on coil-combined magnitude brain images from public IXI database. The network architecture and training procedures were adopted from10. Each 2D cross-section along the readout direction was reconstructed by optimizing w and n for 1000 iterations using RMSProp optimizer with a learning rate starting from 0.1 and decaying with a cosine term, and a momentum rate of 0.9.
Demonstrations were performed on T1-and T2-weighted images, where (25,5,10) subjects were reserved for (training, validation, testing). ZSL-Net was compared against two methods: 1) A supervised, conditional generator adversarial network, rGAN12, that is trained to reconstruct undersampled acquisitions for specific contrast and acceleration rate. 2) An unsupervised network model where the synthesizer in ZSL-Net has randomly initialized weights to skip pre-training, an implementation of the deep image prior (DIP) approach13. Two dimensional random undersampling was performed retrospectively to achieve acceleration rates R=4X, 8X using Gaussian-distributed sampling density.
Results
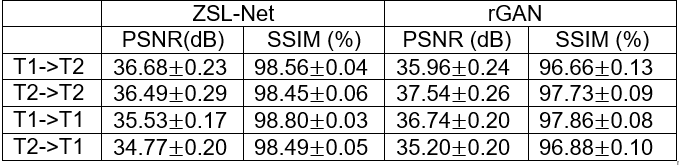
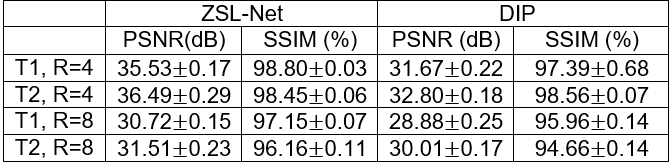
Table-1 lists average PSNR and SSIM across the test images recovered via rGAN (RT1=4x) or rGAN (RT2=4x) trained to reconstruct T1- and T2-weighted images respectively at acceleration rate R=4 and also ZSL-NetT1 and ZSL-NetT2 with structural-prior from fully-sampled T1- and T2-weighted images respectively, and tested on either T1- or T2-weighted acquisitions. Overall, ZSL-Net performs on par with the fully-supervised gold-standard rGAN. On average ZSL-Net performed 0.5 dB lower in PSNR and %1.3 higher in SSIM than rGAN.Table-2 lists average PSNR and SSIM across the test images with acceleration rate R=4 and 8 recovered via ZSL-NetT1 and ZSL-NetT2 with structural-prior from fully-sampled T1- and T2-weighted images respectively, and randomly initialized ZSL_Net (DIP) tested on either T1- or T2-weighted acquisitions. On average ZSL-Net achieved 2.72 dB higher PSNR and %0.99 higher SSIM than DIP.
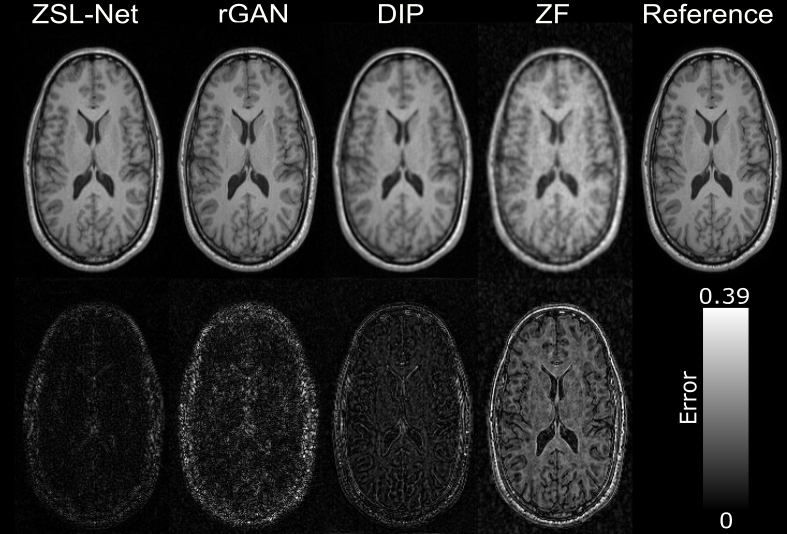
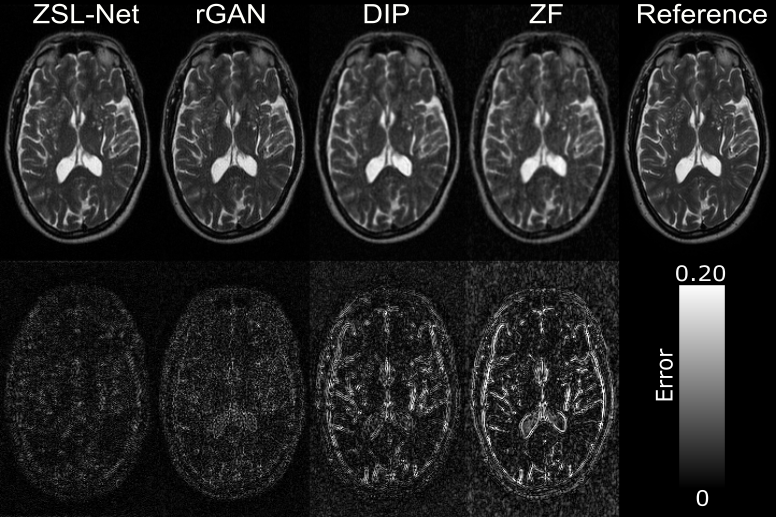
Figure-2 shows representative out-of-domain reconstructions (different training and testing domains) of T2-weighted images at R=4. Reconstructions from ZSL-NetT1, rGAN (RT1=4x), and DIP are displayed along with zero-filled Fourier reconstruction, ground-truth image, and error maps. In comparison to DIP, ZSL-Net reliably recovers high-frequency details by leveraging its structural prior. ZSL-Net more effectively generalizes to out-of-domain test samples than rGAN as its style-generative latent representations are highly adept at mixing separate tissue contrasts.
Figure-3 shows representative within-domain reconstructions (same training and testing domain) of T1-weighted images at R=8. Reconstructions from ZSL-NetT1, rGAN (RT1=8x), and DIP are displayed. DIP model suffers from loss of high-frequency structural details due to heavier undersampling of peripheral k-space at R=8. In comparison to DIP, ZSL-Net reliably recovers high-frequency details by leveraging its structural prior.
Discussion
In this study, we introduced a new zero-shot learning approach for unsupervised and unconditional reconstruction of accelerated MRI acquisitions without any prior information about reconstruction task. The style-generative latent representations in ZSL-Net capture structural MRI priors and successfully adapt them to different tissue contrasts. As such, the proposed method outperforms the unsupervised DIP model and the supervised rGAN model.Conclusion
ZSL-Net holds great promise for deep-learning reconstruction of accelerated MRI, since it achieves high reconstruction accuracy without the need for data- and time-intensive training of network architectures separately for all reconstruction tasks.Acknowledgements
This work was supported in part by a TUBA GEBIP fellowship, by a TUBITAK 1001 Grant (118E256), and by a BAGEP fellowship awarded to T. Çukur. We also gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.References
1. Hammernik K, Klatzer T, Kobler E, et al. Learning a Variational Network for Reconstruction of Accelerated MRI Data. Magn. Reson. Med. 2017;79:3055–3071.
2. Schlemper J, Caballero J, Hajnal J V., Price A, Rueckert D. A Deep Cascade of Convolutional Neural Networks for MR Image Reconstruction. In: International Conference on Information Processing in Medical Imaging. ; 2017. pp. 647–658.
3. Mardani M, Gong E, Cheng JY, et al. Deep Generative Adversarial Neural Networks for Compressive Sensing (GANCS) MRI. IEEE Trans. Med. Imaging 2018:1–1 doi: 10.1109/TMI.2018.2858752.
4. Han Y, Yoo J, Kim HH, Shin HJ, Sung K, Ye JC. Deep learning with domain adaptation for accelerated projection-reconstruction MR. Magn. Reson. Med. 2018;80:1189–1205 doi: 10.1002/mrm.27106.
5. Wang S, Su Z, Ying L, et al. Accelerating magnetic resonance imaging via deep learning. In: IEEE 13th International Symposium on Biomedical Imaging (ISBI). ; 2016. pp. 514–517. doi: 10.1109/ISBI.2016.7493320.
6. Yu S, Dong H, Yang G, et al. DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction. IEEE Trans. Med. Imaging 2018;37:1310–1321.
7. Zhu B, Liu JZ, Rosen BR, Rosen MS. Image reconstruction by domain transform manifold learning. Nature 2018;555:487–492 doi: 10.1017/CCOL052182303X.002.
8. Dar SUH, Özbey M, Çatlı AB, Çukur T. A Transfer-Learning Approach for Accelerated MRI Using Deep Neural Networks. Magn. Reson. Med. 2020;84:663–685 doi: 10.1002/mrm.28148.
9. Karras, Tero, Samuli Laine, and Timo Aila. "A style-based generator architecture for generative adversarial networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2019.
10. Karras, Tero, et al. "Analyzing and improving the image quality of stylegan." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
11. Abdal, Rameen, Yipeng Qin, and Peter Wonka. "Image2stylegan: How to embed images into the stylegan latent space?." Proceedings of the IEEE international conference on computer vision. 2019.
12. Dar, Salman UH, et al. "Prior-guided image reconstruction for accelerated multi-contrast MRI via generative adversarial networks." IEEE Journal of Selected Topics in Signal Processing 14.6 (2020): 1072-1087.
13. Ulyanov, Dmitry, Andrea Vedaldi, and Victor Lempitsky. "Deep image prior." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
Figures