1961
Influence of training data on RAKI reconstruction quality in standard 2D imaging1Department of Experimental Physics 5, University of Würzburg, Würzburg, Germany, 2Department of Internal Medicine I, University Hospital Würzburg, Würzburg, Germany, 3Magnetic Resonance and X-Ray Imaging Department, Development Center X-ray Technology EZRT, Fraunhofer Institute for Integrated Circuits IIS, Würzburg, Germany
Synopsis
The parallel imaging method GRAPPA has been generalized within the Machine Learning framework by introducing the deep-learning method RAKI, in which Convolutional Neural Networks are used for non-linear k-space interpolation. RAKI is a database-free approach that uses scan-specific calibration data. Here, we study the influence of the calibration data on the image quality of 2D imaging sequences. The results indicate that RAKI yields superior signal-to-noise ratio but introduces blurring and loss of detail for typical calibration data amounts at high accelerations. Furthermore, the contrast information in the calibration data must be similar to that of the accelerated scans.
Introduction
Parallel imaging (PI) methods are widely used to reduce MRI scan time in clinical routine. The basic PI approaches are based on uniform k-space undersampling and simultaneous signal reception with multiple receiver coils. The GRAPPA1 (GeneRalized Autocalibrating Partially Parallel Acquisitions) method interpolates missing k-space signals by linear combination of adjacent, acquired signals across all channels and can be described by a linear convolution in k-space. In GRAPPA, the convolution kernel is estimated by linear least-squares regression using fully sampled autocalibration signals (ACS). Recently, a more generalized deep-learning based method called RAKI2 was introduced. RAKI estimates missing signals non-linearly via Convolutional Neural Networks (CNNs) and has the potential to overcome limitations associated with the linearity of GRAPPA. In this work, we study the influence of the ACS used to calibrate the scan-specific CNN parameters on the image quality of 2D imaging sequences more precisely. In particular, the focus will be on the ACS amount as well as on the contrast information provided for the CNN training.Methods
RAKI implementation: The CNN architecture is depicted in Figure 1. The input layer S1 takes in the undersampled, zerofilled k-space data across all coils, mapped to real field (resulting in 2 x Nc total input channels with Nc being the number of coils). The hidden layers are then calculated through linear convolution, and a point-wise activation with the Leaky ReLU function max(0.5x, x): S2 = LReLU( S1 ∗ wC1 ) and S3 = LReLU( S2 ∗ wC2 ), with wC1 of size 3 x 2 and wC2 of size 1 x 1 in read- and phase-encoding direction, respectively. First hidden layer S2 is assigned 256 channels, while second hidden layer is assigned 128 channels. In contrast to original RAKI, the output layer predicts all missing points across all coils, thus having 2 x (R - 1) x Nc channels where R denotes the undersampling rate. The outer layer is activated with the identity function: S4 = S3 ∗ wC3 with wC3 of size 5 x 1.In Vivo imaging: 2D anatomical brain imaging with 16 coils was performed on a healthy volunteer at 3 T using TSE sequence with FOV=220 mm x 193 mm, TR/TE=500/10ms (T1-weighted) and 4500/102ms (T2-weighted). Brain imaging was also performed with 32 coils using FLASH sequence with FOV=220 mm x 193 mm, TR/TE=350/2.5ms. All datasets were fully sampled and retrospectively undersampled for reconstruction. Accelerated dynamic cardiac imaging was performed using 12 coils at FOV=360 mm x 270 mm and resolution=1.88 mm x 1.88 mm. The data were acquired under free-breathing conditions using an interleaved acquisition scheme3-5 with undersampling rate R=4. Full resolution ACS were obtained from the temporal average.
Evaluation: Image reconstruction quality of RAKI was evaluated by varying the number of total ACS lines in the range 20-40 with stepsize 5. To take the inherent stochasticity of RAKI into account, the reconstruction procedure is repeated 100 times. The root-mean-squared error (RMSE) of the fully sampled reference image to the undersampled data (R=4) was calculuated. GRAPPA reconstructions were performed for comparison. Additionally, ACS with different contrast information were used for RAKI training (e.g. T1-weighted ACS were used for RAKI training to reconstruct T2-weighted data). The ACS were not reinserted in the final images.
Results
Figure 2 depicts reconstructions of the brain dataset with 32 coils and 30 ACS (reinserted). We observe that RAKI significantly outperforms GRAPPA in terms of signal-to-noise ratio at R=4 and R=5, but introduces blurring and loss of fine details particularly at R=6. The RMSE for RAKI decreases with increasing amount of ACS (R=4, see Figure 3). In all cases, the RMSE was lower than that of GRAPPA. Consequently, when a large amount of ACS is available for calibrating a large CNN kernel, as in dynamic imaging with interleaved sampling, RAKI provides high quality reconstructions with reduced blurring artifacts (Figure 4). However, RAKI shows poor performance when the contrast in the ACS significantly differs that of the accelerated scan (Figure 5). In contrast, GRAPPA shows only few additional artifacts for the reconstruction of the T2-weighted image when the ACS is from T1-weighted signals.Discussion
RAKI shows improved image reconstruction quality in comparison with GRAPPA for 2D MRI scans at moderate accelerations (R=4 and R=5 with Nc < 32), but exhibits blurring in areas where GRAPPA suffers from severe noise amplification. However, blurring can potentially be reduced by a larger CNN kernel as indicated by the cardiac imaging experiment. However, there is always a trade-off between kernel size and effective amount of training examples. Thus, data augmentation techniques such as noise superimposition, may need further investigations in future studies. The experiments with significantly varying contrast between ACS and undersampled data indicates, that CNNs process scan-specific tissue contrast information in addition to coil sensitivity information, in a more profound way than GRAPPA.Conclusion
RAKI has the potential for providing significantly improved SNR in 2D imaging compared to GRAPPA, but may yield blurring and loss of details at high accelerations. Larger CNN kernels in combination with more ACS are useful to alleviate this problem. Furthermore, the contrast between ACS and undersampled data should be similar to prevent reconstruction artifacts.Acknowledgements
The authors thank Peter Kellman for providing cardiac imaging data and the German Federal Ministry of Education and Research (BMBF) for funding projectline VIP+ (03VP04951).References
1. Griswold, M. A., Jakob, P. M., Heidemann, R. M., Nittka, M., Jellus, V., Wang, J., Kiefer, B., and Haase, A. (2002). Generalized autocalibrating partially parallel acquisitions (GRAPPA). Magnetic Resonance in Medicine, 47(6):1202–1210.
2. Akçakaya, M., Möller, S., Weingärtner, S., and , Uğurbil K. (2019). Scan-specific robust artificial-neural-networks for k-space inter-polation (raki) reconstruction: Database-free deep learning for fast imaging.Magnetic Resonance in Medicine, 81(1):439–453.
3. Kellman, P., Epstein, F. H., and McVeigh, E. R. (2001).Adaptive sensitivity encoding incorporating temporal filtering (TSENSE). Magnetic Resonance in Medicine, 45(5):846–852.
4. Köstler, H., Beer, M., Ritter, C., Hahn, D., and Sandstede,J. (2004). Auto-sense view-sharing cine cardiac imaging. Magma (New York,N.Y.), 17(2):63–67.
5. Breuer, F. A., Kellman, P., Griswold, M. A., and Jakob,P. M. (2005). Dynamic autocalibrated parallel imaging using temporal GRAPPA (TGRAPPA). Magnetic Resonance in Medicine, 53(4):981–985.
Figures
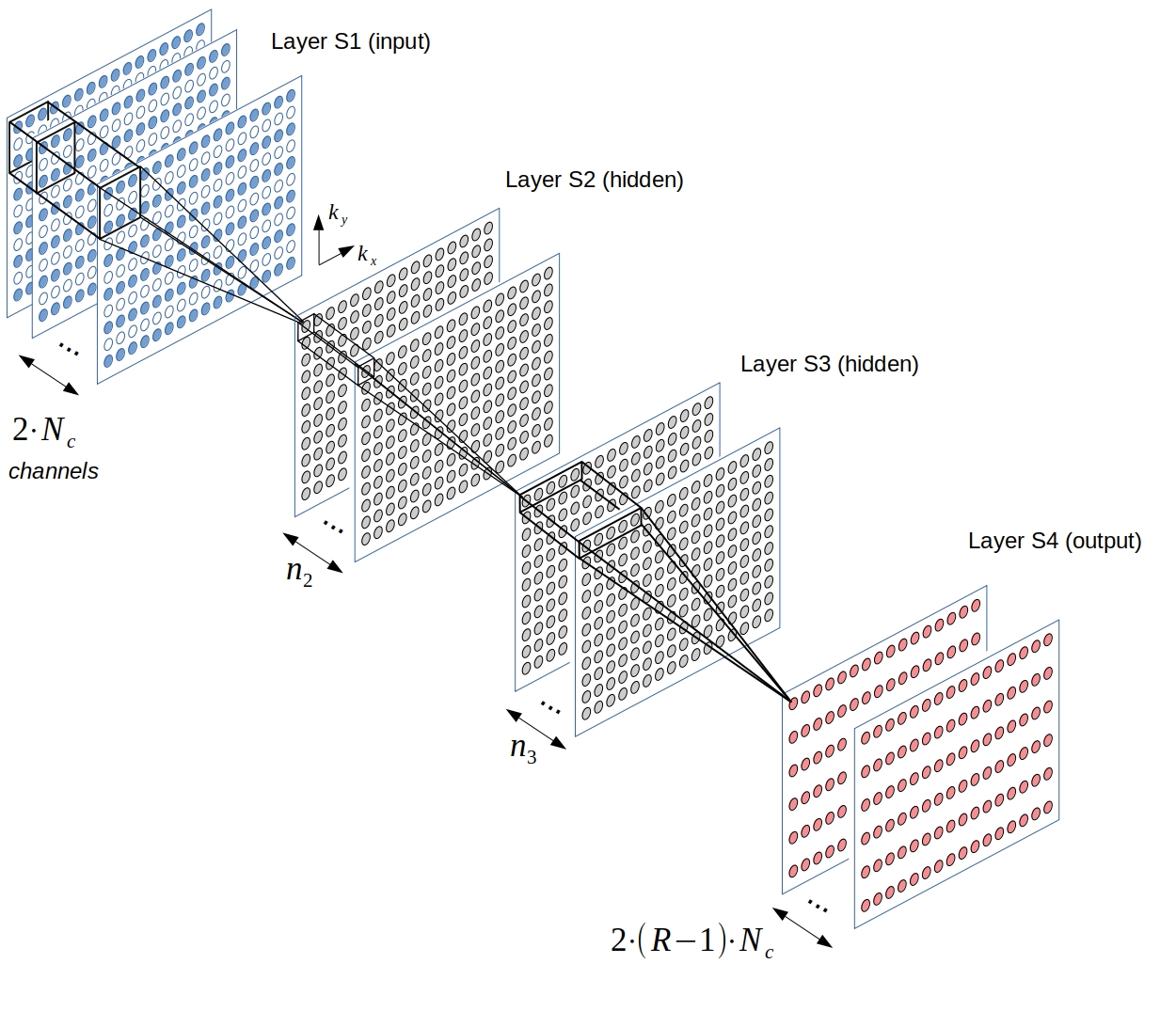
Fig. 1: The CNN architecture used in this work. The input layer takes in the subsampled, zerofilled k-space data of the coil array with Nc independent choils. Real- and imaginary part of the k-space data are passed to separate channels, resulting in 2 x Nc input-channels. Two hidden layers are assigned 256 and 128 channels, respectively (n2=256 and n3=128). The output layer predicts all missing points across all coils simultaneously, and thus has 2 x (R-1) x Nc channels, with R denoting the undersampling rate.
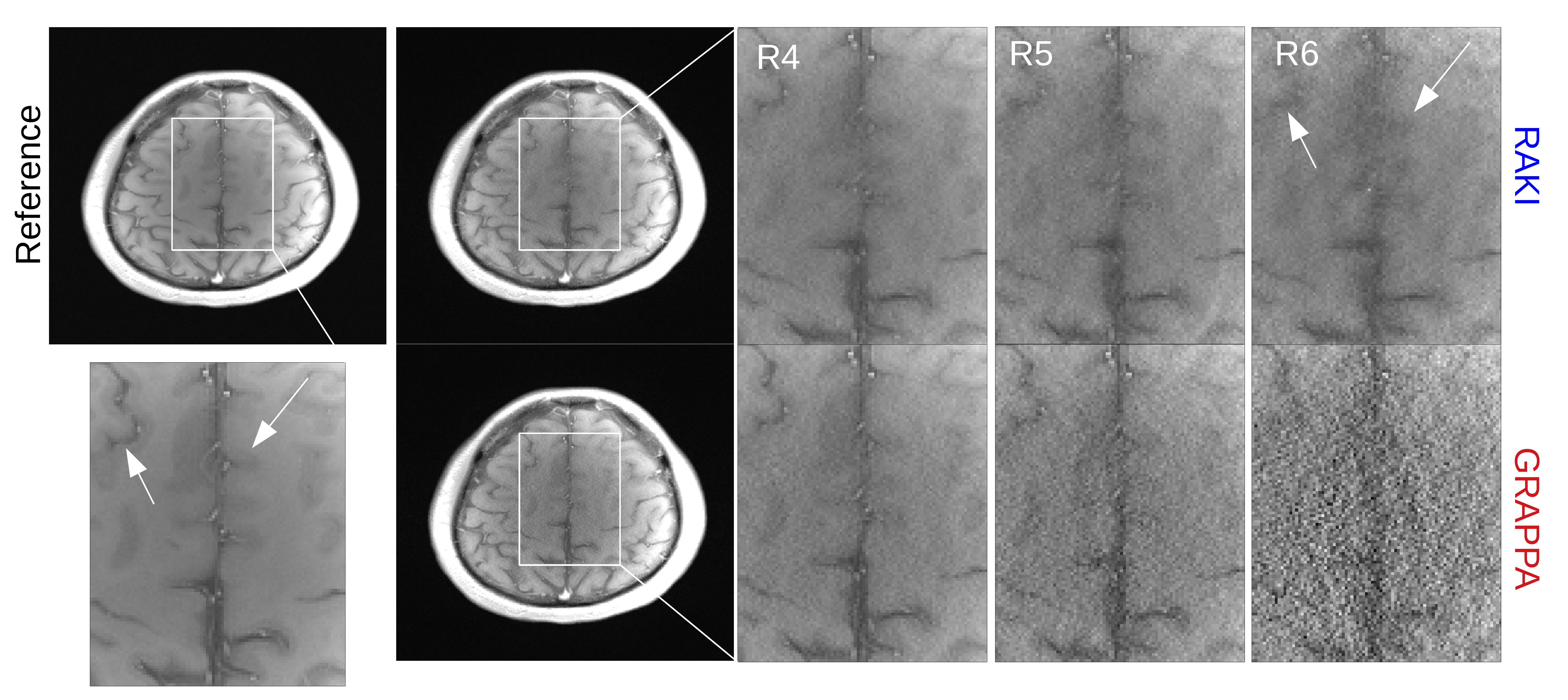
Fig. 2: 2D image reconstructions of brain dataset (32 coils, T1-weighted) for retrospective undersampling rates in range 4-6 (denoted as R4-R6). ACS data (30 central phase lines) were re-inserted into reconstructed k-spaces. GRAPPA kernel size was optimized for each undersampling rate: 11 x 4 (R4-5), and 15 x 2 (R6) in read- and phase direction. RAKI performs better than GRAPPA in terms of noise resilience, but suffers from blurring artifacts, which have pronounced appearance at 6-fold undersampling.
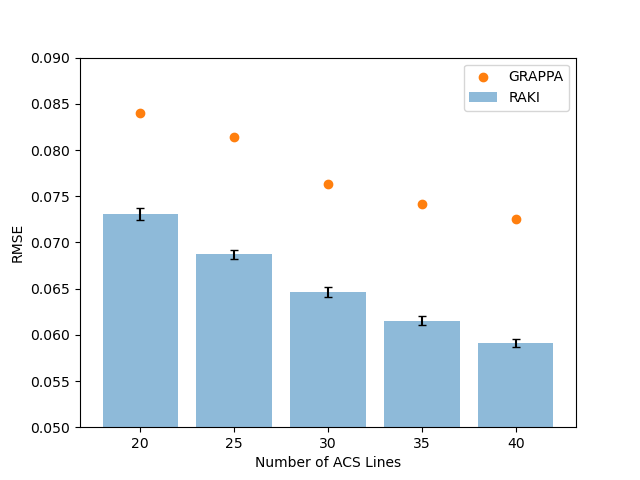
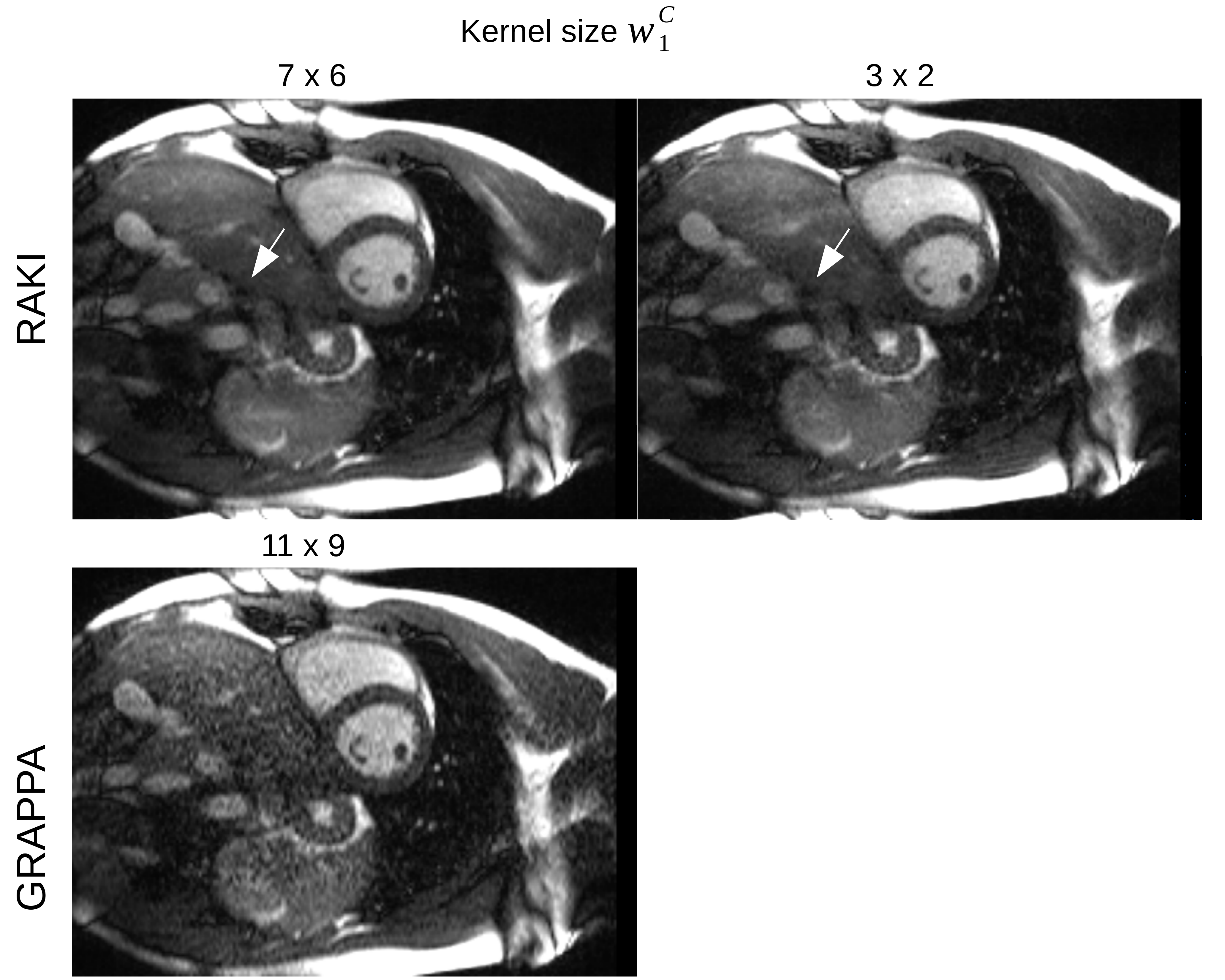
Fig. 4: Dynamic, 4-fold accelerated cardiac imaging under free-breathing conditions (8 coils). Enlarging the kernel size wC1 in the CNN leads to a reduction of blurring artifacts in RAKI (top), as indicated by the reconstruction of an exemplary time-frame (see e.g. location marked by arrow). In addition, contrast losses are reduced. For comparison, GRAPPA reconstruction with kernel size of similar extension is depicted (bottom). The pronounced noise enhancement in GRAPPA is successfully suppressed in RAKI.
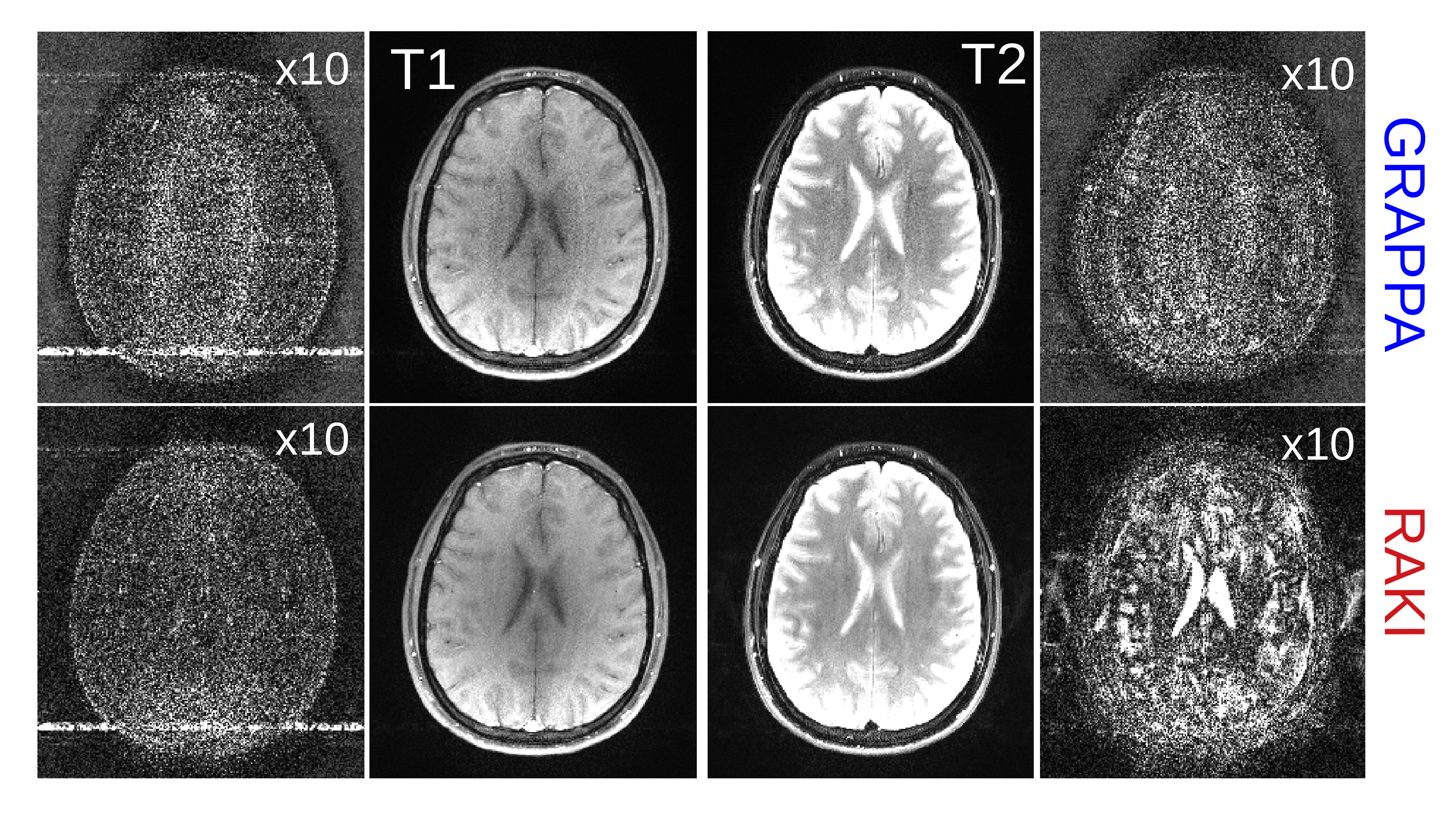
Fig. 5: T1- and T2-weighted 2D brain imaging (16 coils) using a TSE sequence without changing any other imaging parameters. Both T1- and T2-weighted datasets were retrospectively undersampled (rate 4), and reconstructed with GRAPPA and RAKI, which both were calibrated on 30 central lines of the T1-weighted dataset. While RAKI outperforms GRAPPA on the T1-weighted dataset (left), it fails to reconstruct the T2-weighted dataset (right), as it reveals severe artifacts. GRAPPA on the other hand shows fewer artifacts. ACS data were not re-inserted (difference images scaled for display)