1952
A lightweight and efficient convolutional neural network for MR image restoration1United Imaging Intelligence, Shanghai, China, 2United Imaging Healthcare, Shanghai, China
Synopsis
Many deep learning models for MR image restoration have high computational cost, which raises significant hardware cost and also restricts their usage. To address it, we propose a lightweight network based on the encoder-decoder architecture which integrates image features of different scales and levels to improve the representation capability. A novel loss function is also designed to constrain the model in both image domain and frequency domain. The experimental results show that our model efficiently reduces computational burden while maintaining high performance compared to other conventional models.
Introduction
Recently, deep learning technology has made significant progress in image denoising [1] and super-resolution [2]. On the other hand, MRI as a medical imaging modality plays an important role in clinical diagnosis. The application of deep learning in the field of MR imaging has very broad prospect. However, most deep learning models used in image restoration are computationally expensive, thus requiring powerful hardware such as high-performance GPU with large memory. This raises significant hardware cost as well as MRI reconstruction time, eventually limiting practical applications. In this paper, we propose a lightweight convolutional neural network based on the encoder and decoder architecture with a novel loss function to resolve the above challenge.Method
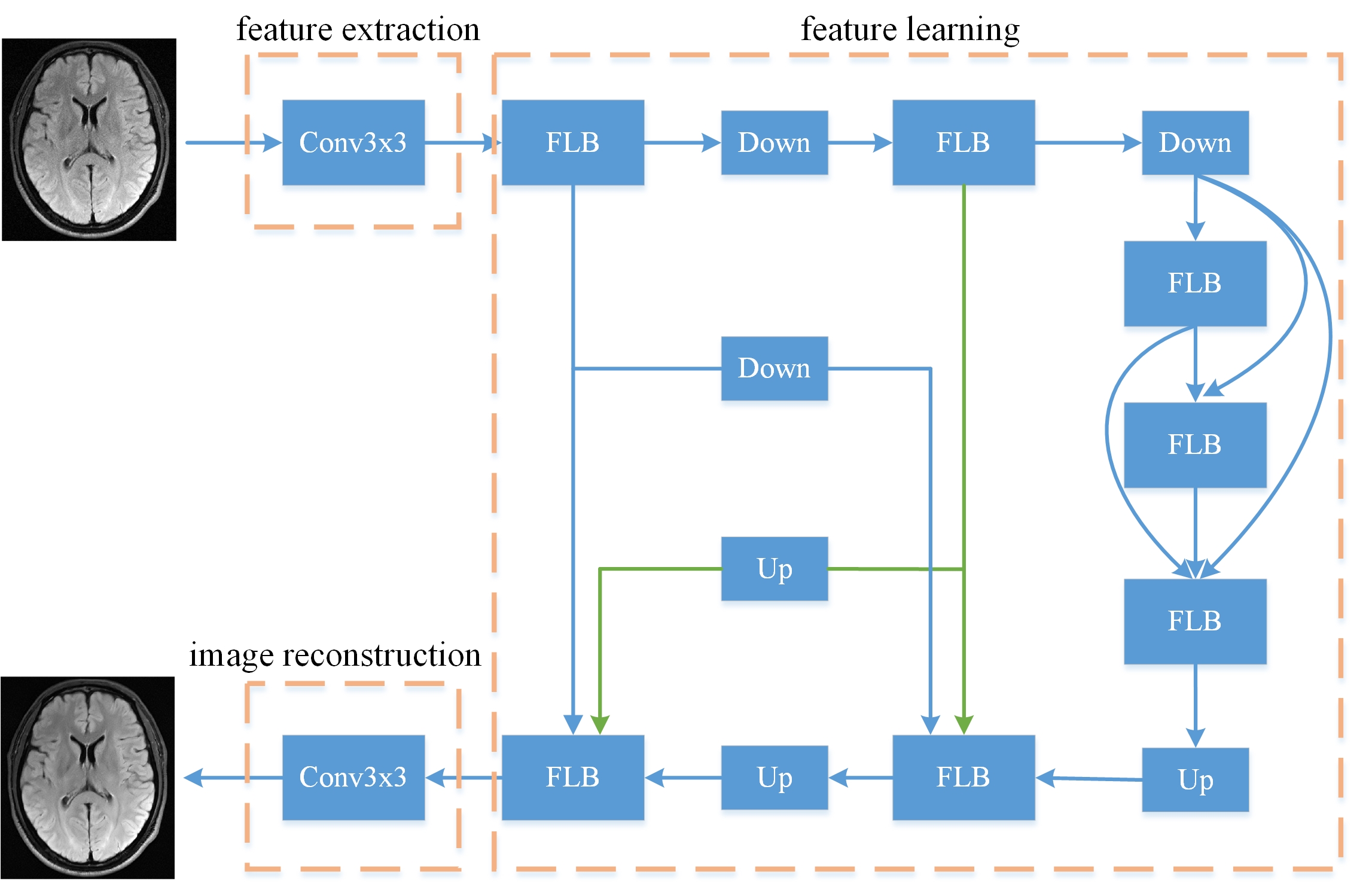
The proposed lightweight convolutional neural network, called Enhanced Encoder-Decoder Network (EEDN), as shown in Fig. 1, can be divided into three modules: feature extraction, feature learning, and image reconstruction. Each of the feature extraction module and the reconstruction module is composed of a 3x3 convolution layer, while the feature learning module is based on the encoder-decoder framework by fully integrating image features of different scales and levels to improve representation capability. Moreover, in order to enforce the consistency in both image domain and frequency domain, a novel loss function is defined as follows, which can not only alleviate the over-smoothing problem caused by L1 loss, but also suppress the artifacts produced by perceptual loss [3]. There are three terms in the novel loss function, with the first term defining the L1 loss in image domain, the second term defining the perceptual loss, and the third term defining the L1 loss in frequency domain, as given below.$$L_{loss}=\lambda_{1}\parallel I_{output}-I_{GT}\parallel_{1}+\lambda_{2}\parallel \phi_{n}(I_{output})-\phi_{n}(I_{GT}) \parallel_{1}+\lambda_{3}\parallel K_{output}^{abs}-K_{GT}^{abs} \parallel_{1}$$
where $$$\lambda_{1}, \lambda_{2}, \lambda_{3}$$$ are the weighting factors controlling the importance of each term. $$$I_{output}$$$ denotes the output image of EEDN. $$$I_{GT}$$$ denotes the ground-truth MR image with high quality. $$$\phi_{n}(.)$$$ represents the feature map of the n-th layer of the pre-trained vgg-19 model [4]. $$$K_{output}^{abs}$$$ and $$$K_{GT}^{abs}$$$ are the amplitude maps of output image and ground truth image in frequency domain. The high resolution and high SNR MR images were treated as the ground-truth image, and the low SNR images with zero-filling interpolation in k-space were used as input of the model. The 2D image dataset was divided into the training set with 4249 samples, and the testing set with 461 samples. $$$\lambda_{1}=0.1, \lambda_{2}=1, \lambda_{3}=0.01$$$ were used for the training process.
Results
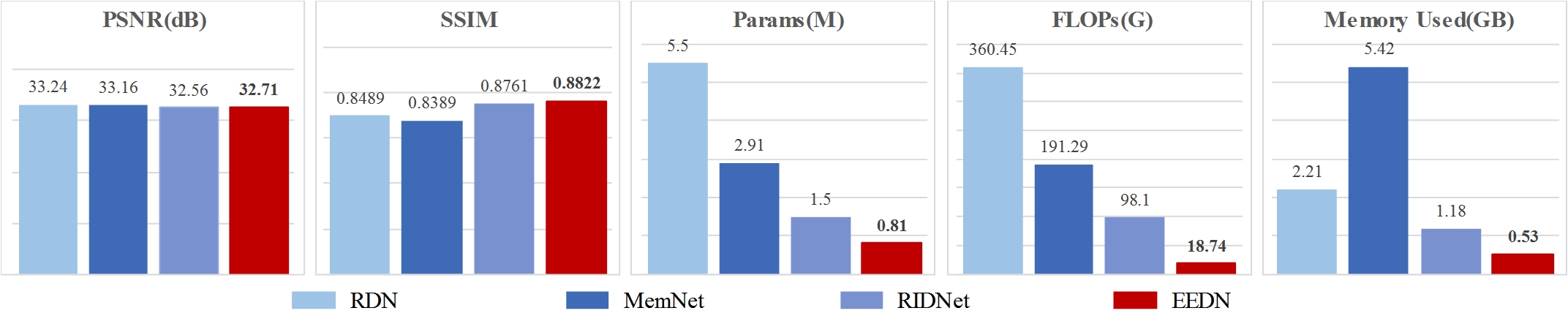
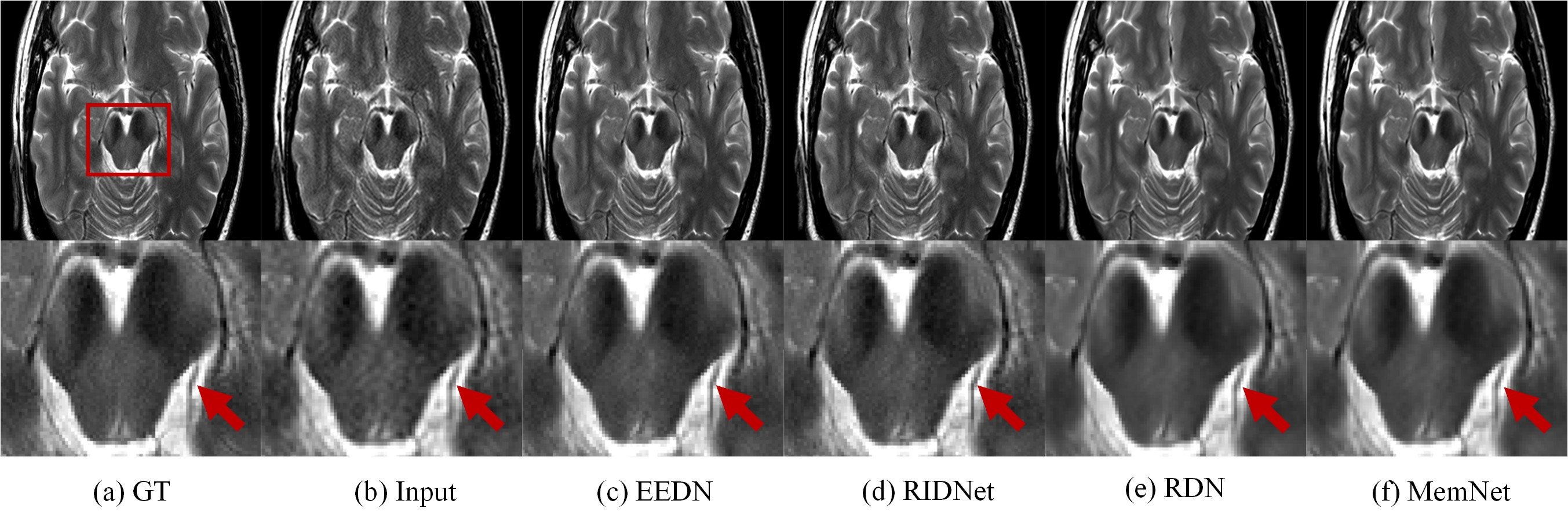
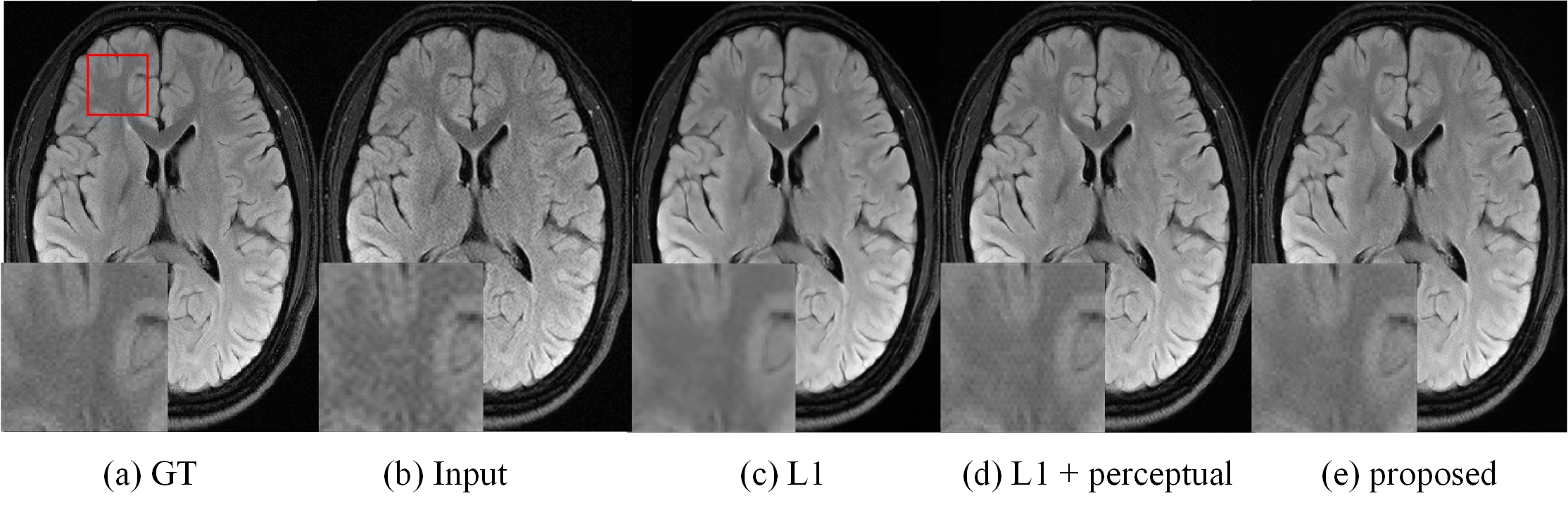
We compared our proposed model with three state-of-the-art image restoration methods, i.e., RIDNet [5], RDN [6], and MemNet [7], by using five different evaluation metrics (i.e., PSNR, SSIM [8] for image quality, network parameter scale, FLOPs and GPU memory occupation for model efficiency). The results are shown in Fig. 2. Although PSNR value of EEDN is slightly lower than PSNR values of RDN and MemNet, the SSIM value of EEDN is the highest indicating superior structural similarity to the ground truth image as demonstrated in Fig. 3. More importantly, the parameter scale, and FLOPs and GPU memory occupation are greatly reduced, which illustrates the efficiency of EEDN. Fig. 4 are output images of EEDN with different loss functions. The proposed loss function is shown to produce superior image quality.Discussion and Conclusion
An efficient and lightweight neural network EEDN with a novel loss function for MRI restoration is proposed in this paper. Compared with other models, our model can not only greatly improve network efficiency with reduced network parameters and FLOPs, but also help enhance image quality with better visualization. EEDN exemplifies that deep learning network with special and efficient design will has great potential in the field of MRI.Acknowledgements
No acknowledgement found.References
[1] Tian C , Fei L , Zheng W , et al. Deep Learning on Image Denoising: An overview[J]. 2019.
[2] Wang Z , Chen J , Hoi S C H . Deep Learning for Image Super-resolution: A Survey[J]. 2019.
[3] Johnson J , Alahi A , Fei-Fei L . Perceptual Losses for Real-Time Style Transfer and Super-Resolution[C]. European Conference on Computer Vision. Springer, Cham, 2016.
[4] Simonyan K , Zisserman A . Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer ence, 2014.
[5] Anwar S , Barnes N . Real Image Denoising With Feature Attention[C]. 2019 IEEE International Conference on Computer Vision (ICCV). IEEE, 2019.
[6] Zhang Y , Tian Y , Kong Y , et al. Residual Dense Network for Image Restoration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, PP(99):1-1.
[7] Tai Y , Yang J , Liu X , et al. MemNet: A Persistent Memory Network for Image Restoration[C]. IEEE International Conference on Computer Vision. IEEE Computer Society, 2017.
[8] Yang C Y , Ma C , Yang M H . Single-Image Super-Resolution: A Benchmark[J]. 2014.
Figures