1949
A Few-Shot Learning Approach for Accelerated MRI via Fusion of Data-Driven and Subject-Driven Priors1Department of Electrical and Electronics Engineering, Bilkent University, Ankara, Turkey, 2National Magnetic Resonance Research Center (UMRAM), Bilkent University, Ankara, Turkey, 3Neuroscience Program, Aysel Sabuncu Brain Research Center, Bilkent University, Ankara, Turkey
Synopsis
Deep neural networks (DNNs) have recently found emerging use in accelerated MRI reconstruction. DNNs typically learn data-driven priors from large datasets constituting pairs of undersampled and fully-sampled acquisitions. Acquiring such large datasets, however, might be impractical. To mitigate this limitation, we propose a few-shot learning approach for accelerated MRI that merges subject-driven priors obtained via physical signal models with data-driven priors obtained from a few training samples. Demonstrations on brain MR images indicate that the proposed approach requires just a few samples to outperform traditional parallel imaging and DNN algorithms.
Introduction
A mainstream framework for reconstruction of accelerated MR acquisitions rests on deep neural network (DNN) architectures1-9. To recover images given undersampled acquisitions, DNNs typically learn data-driven priors from large training datasets in a supervised fashion1-8. While DNNs have shown remarkable performance, compilation of large-scale datasets for each anatomy and each protocol is challenging. To mitigate this issue, here we propose a few-shot learning approach for accelerated MRI. The proposed approach consists of a composite deep neural network (COMNET) that fuses subject-driven priors obtained via a physical signal model with data-driven priors obtained from only few training samples.Methods
The reconstruction problem in COMNET can be formulated as:$$\widehat{x} = \underset{x}{\arg\min} \quad \lambda \underbrace{||F_ux-y||_2}_\text{Data consistency}+ \underbrace{(G-I)Fx}_\text{Subject-driven Prior}+ \underbrace{|| C(A^*x^u;\theta^*) - A^*x||_2}_\text{Data-driven Prior}$$
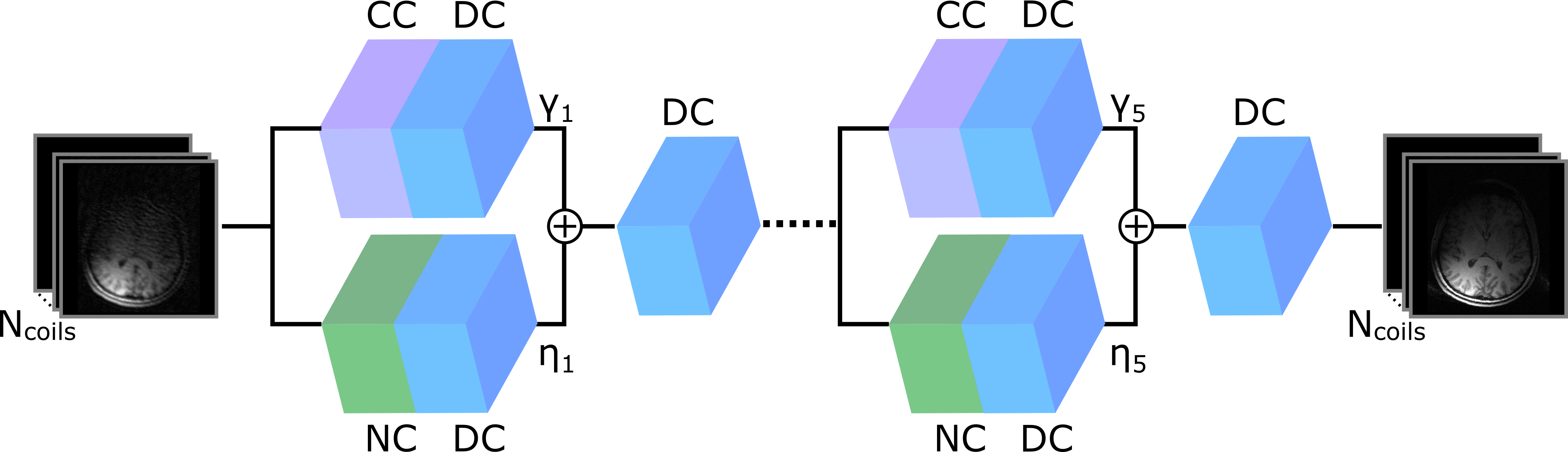
where $$$F_u$$$ is the partial Fourier operator defined at the sampled k-space locations, $$$x$$$ is the image to be reconstructed, $$$y$$$ are the acquired k-space data, $$$G$$$ is a linear operator enforcing consistency with a fully-sampled auto-calibration region, $$$C$$$ denotes the purely learning-based model for reconstruction, $$$x^u$$$ is the Fourier reconstruction of undersampled data, and $$$A$$$ and $$$A^*$$$ denote coil sensitivity maps and their conjugate obtained via ERPIRiT10. COMNET comprises three blocks to enforce data consistency (DC), to enforce subject-driven priors via calibration consistency (CC), and to enforce data-driven priors via network consistency (NC) terms in the objective. A common approach is to connect these blocks in series in an unfolded architecture, and solve the optimization problem by alternating minimization of individual terms8. However, this serial structure introduces undesirable dependency among consecutive blocks that can lead to information loss. To address this problem, here we proposed to fuse information from parallel connected NC and CC blocks (Figure 1). An unrolled cascade of subnetworks are then leveraged for image recovery, and the output of the $$$pth$$$ subnetwork receiving input from the previous subnetwork is given by:
$$\begin{align}x_p=f_{DC}(A\gamma_p A^*f_{DC}(f_{NC}(A^*x_{p-1}))+A\eta_p A^*f_{DC}(f_{CC}(x_{p-1})))\end{align}$$
where $$$f_{CC}$$$, $$$f_{NC}$$$, and $$$f_{DC}$$$ denote mappings by CC, NC and DC blocks, $$$x_p$$$ is the output of the $$$pth$$$ sub-network, $$$x_{p-1}$$$ is the output of the $$$(p-1)th$$$ sub-network, and $$$\gamma_p$$$ and $$$\eta_p$$$ are fusion parameters to combine information from the NC and CC blocks. NC block was adopted from2 where each network consisted of 1 input layer, 4 convolutional layers each containing 64 channels, and 1 output layer. Real and imaginary parts were recovered using separate network branches. The CC block was implemented via SPIRiT11 where 5 CC projections were performed within each block. The network was trained in an end-to-end manner, where parameters of each sub-network was identical except for the weighing parameters ($$$\gamma$$$ and $$$\eta$$$) that were different for each sub-network. ADAM optimizer12 was used with a learning rate of $$$10^{-4}$$$, and parameters $$$\beta_1$$$=0.90 and $$$\beta_2$$$=0.99. Network was trained to minimize $$$\ell_1$$$ and $$$\ell_2$$$ norm difference between reconstructed and ground-truth images. Number of epochs was set to 200.
Demonstrations were performed on contrast enhanced T1-weighted (cT1), T2-weighted and FLAIR images from the fastMRI dataset13. 30 subjects were reserved for training, 10 for validation and 40 for testing. For a systematic evaluation, cT1 and FLAIR images were cropped to a final size of 256x320x10 and T2 images were cropped to 288x384x10 when necessary. Geometric coil compression14 was utilized to ensure that all MRI data had 5 coils. Acquisitions were retrospectively undersampled at R=4x via random sampling masks generated using normal sampling density. COMNET was compared against a regular DNN consisting of only data-driven priors, and L1-SPIRiT consisting of subject-driven priors coupled with sparsity prior in the Wavelet domain. The number of samples for COMNET and DNN were varied from 2 to 300. All hyperparameters were selected via cross-validation with three-way split of data.
Results
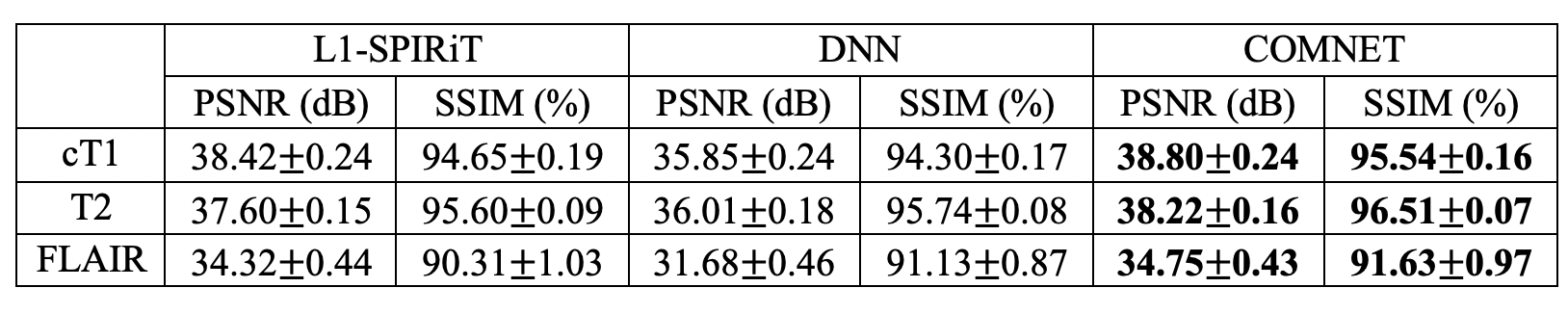
Average PSNR and SSIM values of recovered cT1- weighted, T2-weighted and FLAIR images at R=4x are listed in Table. 1. Both DNN and COMNET were trained on 6 cross-sections from a single subject. On average, COMNET achieves 0.48dB higher PSNR and 0.72% higher SSIM compared to the second-best method.Figure 2 shows PSNR values across recovered cT1- weighted, T2-weighted and FLAIR images as a function of number of training samples. DNN, on average, requires around 90 cross-sections from 9 subjects to outperform L1-SPIRiT. COMNET, on the other hand, requires 2,4, and 6 cross-sections from just a single subject to outperform L1-SPIRiT on cT1- weighted, T2-weighted and FLAIR images. Importantly, COMNET reduces the number of required samples by at least an order of magnitude compared to DNN.
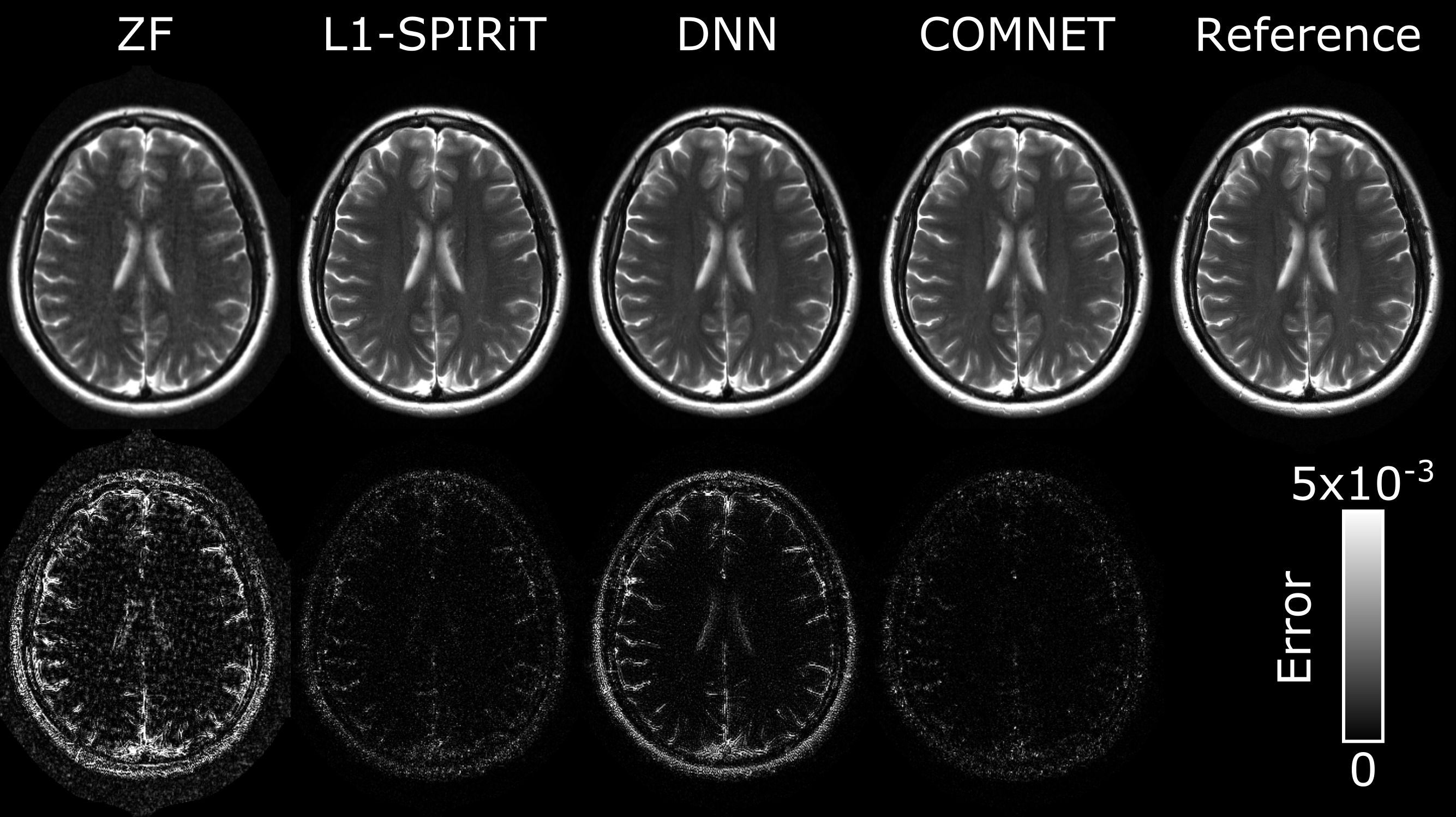
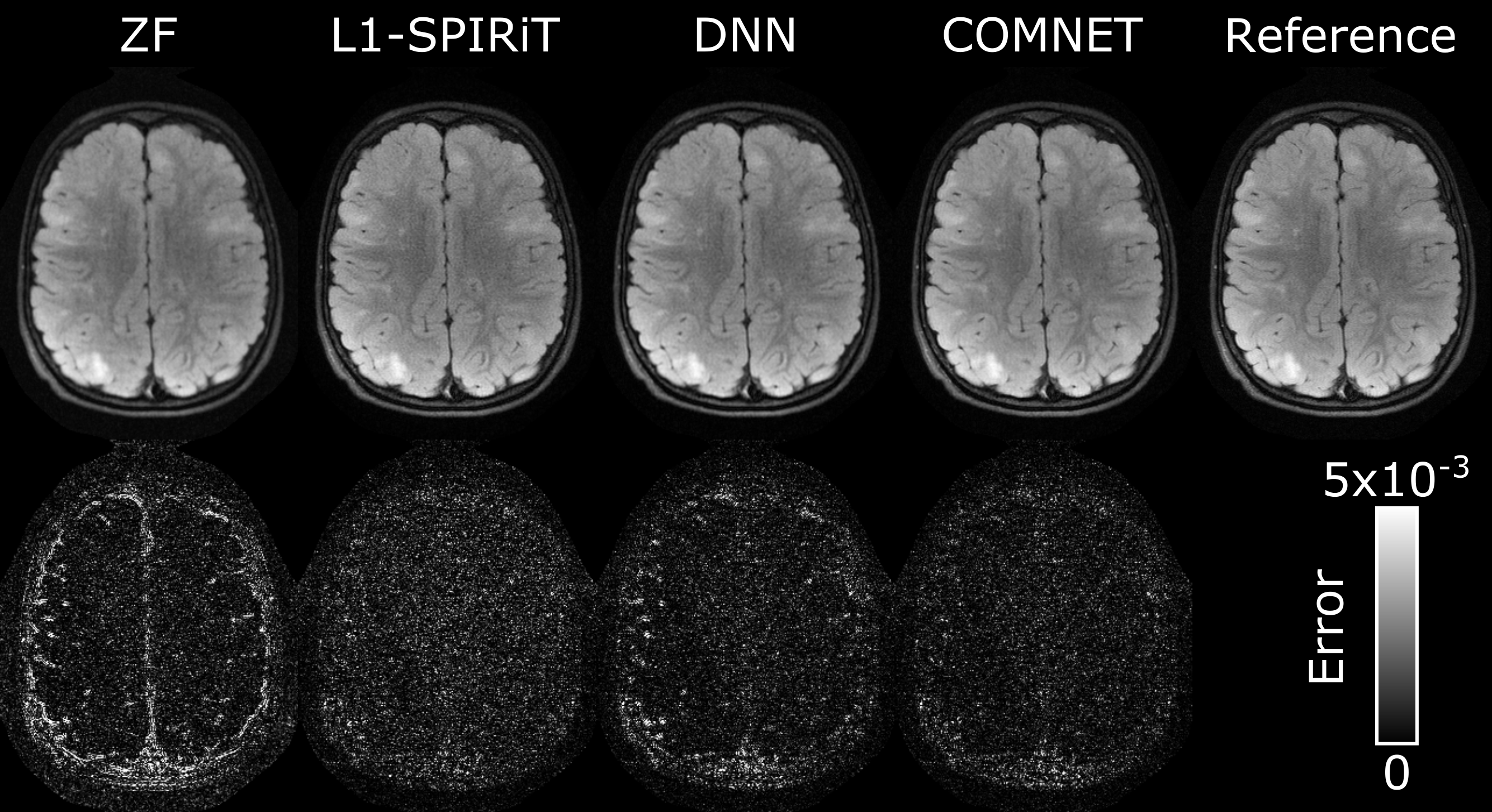
Figures 3 and 4 show representative T2-weighted and FLAIR images from L1-SPIRiT, DNN and COMNET. DNN and COMNET were trained on 6 cross-sections from a single subject. COMNET outperforms both L1-SPIRiT and DNN in terms of residual aliasing artifacts.
Discussion
Here, we propose a few-shot learning approach for MR image reconstructions using deep neural networks. The proposed approach synergistically combines subject-driven priors with data-driven priors to address the issue of data scarcity in DNNs for MR image reconstruction.Conclusion
The proposed approach enables data-efficient training of deep neural networks for MR image reconstruction. Therefore, COMNET holds great promise for improving practical use of deep learning models in accelerated MRI.Acknowledgements
This work was supported in part by a TUBA GEBIP fellowship, by a TUBITAK 1001 Grant (118E256), and by a BAGEP fellowship awarded to T. Çukur. We also gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan X Pascal GPU used for this research.References
1. Hammernik K, Klatzer T, Kobler E, et al. Learning a Variational Network for Reconstruction of Accelerated MRI Data. Magn. Reson. Med. 2017;79:3055–3071.
2. Schlemper J, Caballero J, Hajnal J V., Price A, Rueckert D. A Deep Cascade of Convolutional Neural Networks for MR Image Reconstruction. In: International Conference on Information Processing in Medical Imaging. ; 2017. pp. 647–658.
3. Mardani M, Gong E, Cheng JY, et al. Deep Generative Adversarial Neural Networks for Compressive Sensing (GANCS) MRI. IEEE Trans. Med. Imaging 2018:1–1 doi: 10.1109/TMI.2018.2858752.
4. Han Y, Yoo J, Kim HH, Shin HJ, Sung K, Ye JC. Deep learning with domain adaptation for accelerated projection-reconstruction MR. Magn. Reson. Med. 2018;80:1189–1205 doi: 10.1002/mrm.27106.
5. Wang S, Su Z, Ying L, et al. Accelerating magnetic resonance imaging via deep learning. In: IEEE 13th International Symposium on Biomedical Imaging (ISBI). ; 2016. pp. 514–517. doi: 10.1109/ISBI.2016.7493320.
6. Yu S, Dong H, Yang G, et al. DAGAN: Deep de-aliasing generative adversarial networks for fast compressed sensing MRI reconstruction. IEEE Trans. Med. Imaging 2018;37:1310–1321.
7. Zhu B, Liu JZ, Rosen BR, Rosen MS. Image reconstruction by domain transform manifold learning. Nature 2018;555:487–492 doi: 10.1017/CCOL052182303X.002.
8. Dar SUH, Özbey M, Çatlı AB, Çukur T. A Transfer-Learning Approach for Accelerated MRI Using Deep Neural Networks. Magn. Reson. Med. 2020;84:663–685 doi: 10.1002/mrm.28148.
9. Akçakaya M, Moeller S, Weingärtner S, Uğurbil K. Scan-specific robust artificial-neural-networks for k-space interpolation (RAKI) reconstruction: Database-free deep learning for fast imaging. Magn. Reson. Med. 2019;81:439–453 doi: 10.1002/mrm.27420.
10. Uecker M, Lai P, Murphy MJ, et al. ESPIRiT-an eigenvalue approach to autocalibrating parallel MRI: Where SENSE meets GRAPPA. Magn. Reson. Med. 2014;71:990–1001 doi: 10.1002/mrm.24751.
11. Lustig M, Pauly JM. SPIRiT: Iterative self-consistent parallel imaging reconstruction from arbitrary k-space. Magn. Reson. Med. 2010;64:457–71 doi: 10.1002/mrm.22428.
12. Kingma DP, Ba JL. Adam: a Method for Stochastic Optimization. In: International Conference on Learning Representations. ; 2015. doi: http://doi.acm.org.ezproxy.lib.ucf.edu/10.1145/1830483.1830503.
13. Zbontar J, Knoll F, Sriram A, et al. fastMRI: An open dataset and benchmarks for accelerated MRI. arXiv 2018.
14. Zhang T, Pauly JM, Vasanawala SS, Lustig M. Coil compression for accelerated imaging with Cartesian sampling. Magn. Reson. Med. 2013;69:571–82 doi: 10.1002/mrm.24267.
Figures