1782
Feasibility of Super Resolution Speech RT-MRI using Deep Learning1Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, United States
Synopsis
Super-resolution using deep learning has been successfully applied to camera imaging and recently to static and dynamic MRI. In this work, we apply super-resolution to the generation of high-resolution real-time MRI from low resolution counterparts in the context of human speech production. Reconstructions were performed using full (ground truth) and truncated zero-padded k-space (low resolution). The network, trained with a common 2D residual architecture, outperformed traditional interpolation based on PSNR, MSE, and SSIM metrics. Qualitatively, the network reconstructed most vocal tract segments including the velum and lips correctly but caused modest blurring of lip boundaries and the epiglottis.
Introduction
We apply super-resolution using deep learning to the generation of high-resolution real-time MRI (RT-MRI) from low-resolution RT-MRI in the context of human speech production. This work is motivated by 1) the successful application of super-resolution using deep learning to lens-based camera imaging1 and to static and dynamic MRI2–4 and 2) the prominent role of RT-MRI in the study of human vocal production5,6 often suffering from issues due to limited encoding time and/or artifacts. We utilize a very-deep super-resolution network (VDSR)1 and compare its performance to a traditional interpolation using quantitative metrics and qualitative evaluation.Methods
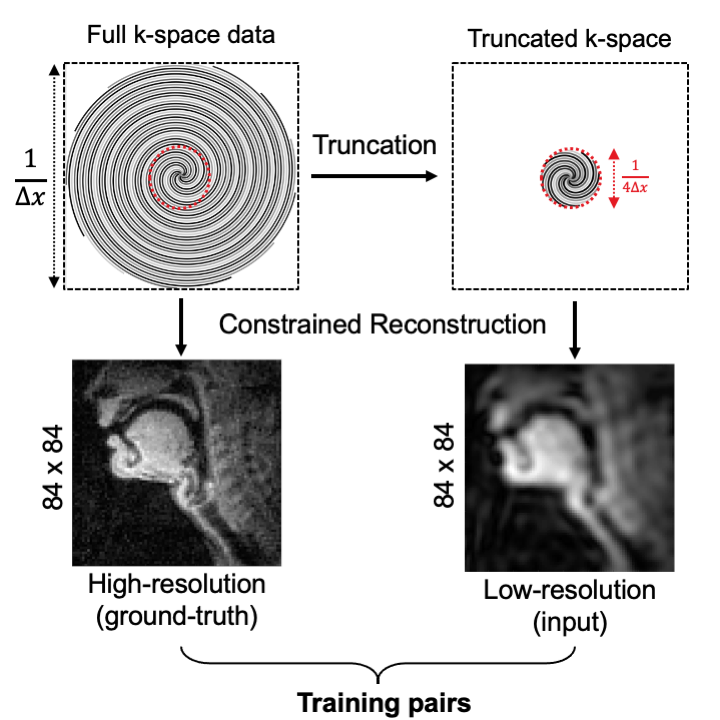
Raw k-space data from a forthcoming open dataset of speech production RT-MRI from the University of Southern California7 was used for training, validation, and testing. This dataset comprised of 58 adult subjects, 21 unique stimuli per subject, and ~16 minutes of recording per subject. Data were acquired on a 1.5T MRI scanner (Signa Excite, GE Healthcare, Waukesha, WI)8 using a 13-interleaf spiral-out spoiled gradient-echo pulse sequence.6,7 The field-of-view is 200 $$$\times$$$ 200 mm2, with a nominal spatial resolution of 2.4 $$$\times$$$ 2.4 mm2.Figure 1 shows how ground-truth and low-resolution pairs were created from the raw k-space data. A temporal finite difference constrained reconstruction6,7 was applied to the full k-space and truncated k-space data, to generate high and low-resolution image pairs while maintaining the same matrix size of 84 $$$\times$$$ 84. The low-resolution images were also taken as a ‘naïve’ sinc-interpolation comparison method.
To ensure that a neural network does not overfit to individual subjects’ vocal tract characteristics, the 58 subjects themselves were split into training (34 subjects), validation (12 subjects), and testing (12 subjects) subgroups.
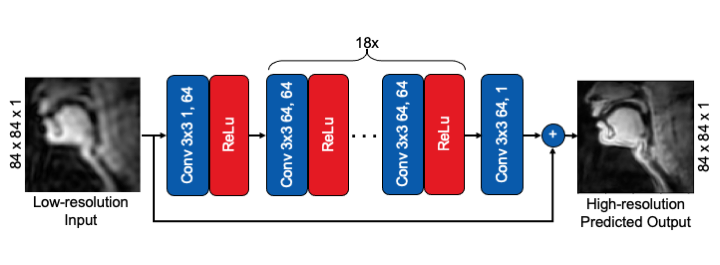
Figure 2 shows the network architecture. We used VDSR, a single image super resolution architecture, due to its simplicity and successful application in lens-based camera imaging and static musculoskeletal MRI.1,4 The network consists of 20 convolutional layers, each with 64 3 $$$\times$$$ 3 filters and a rectified linear unit (ReLU) cascaded together, except for the last layer. The network takes low-resolution image $$$L$$$ as input and predicts the residual image $$$\widehat{R}$$$. The final super-resolution image is formed by $$$\widehat{S} = L + \widehat{R}$$$. The function optimized is mean-squared-error (MSE): $$argmin_\theta||f(L;\theta) - R||_2^2$$ where $$$R$$$ is the residual $$$G - L$$$ and $$$G$$$ is the ground truth. A stochastic gradient descent algorithm was used for optimization. Additional hyperparameters, tuned by hand, include weight decay of 0.9, initial learning rate of 0.1, gradient clipping of 0.4, decay step by a factor of 10 every 25 epochs, and a batch size of 32.
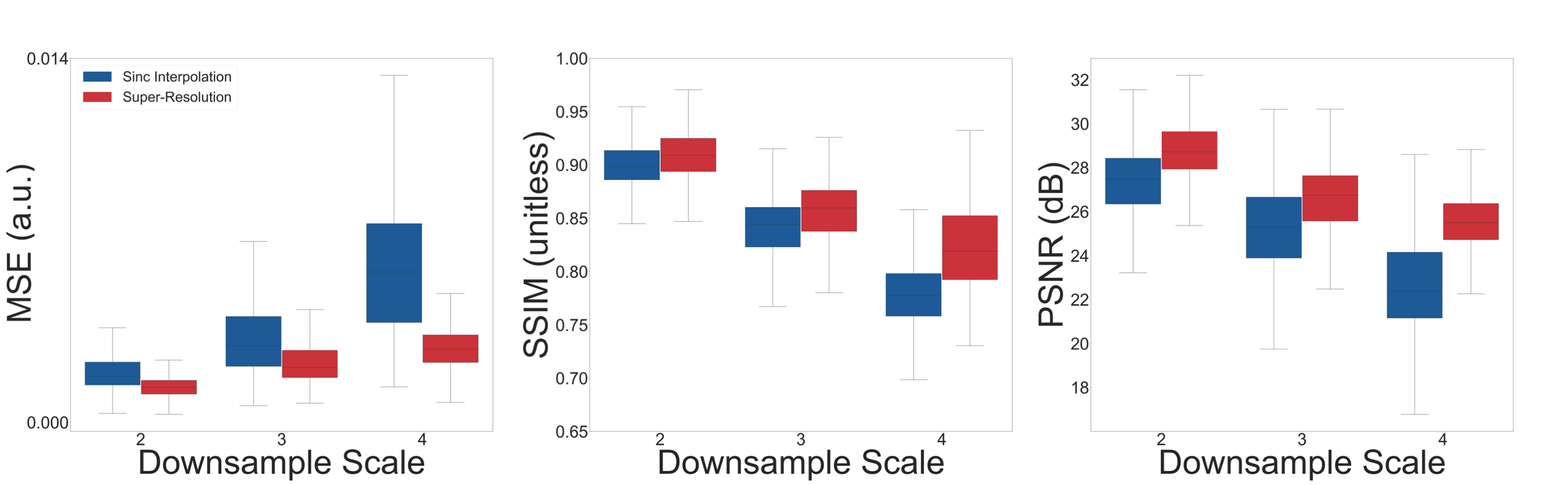
We performed the super-resolution task across 3 scale factors and measured quantitative quality results using MSE, structural similarity (SSIM), and peak signal-to-noise ratio (PSNR).
Results
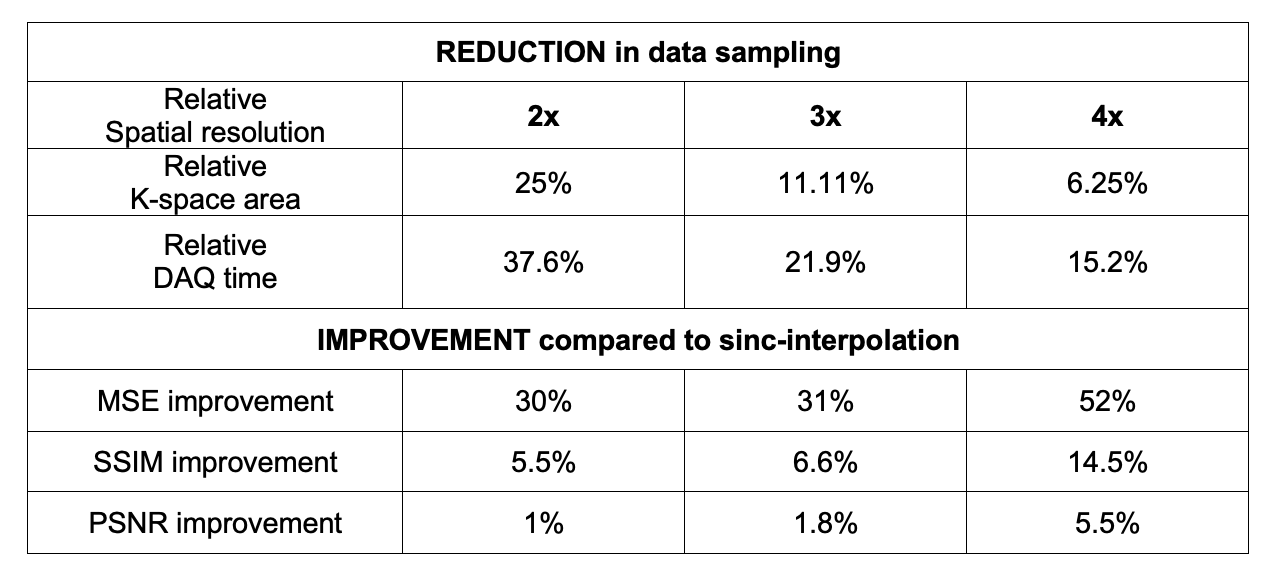
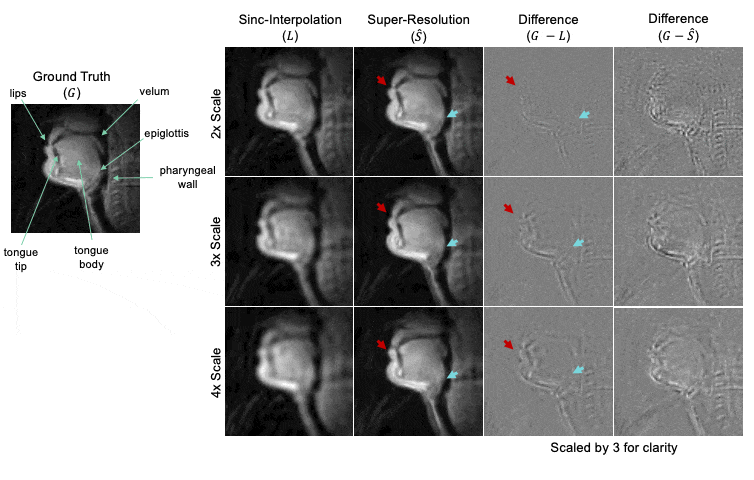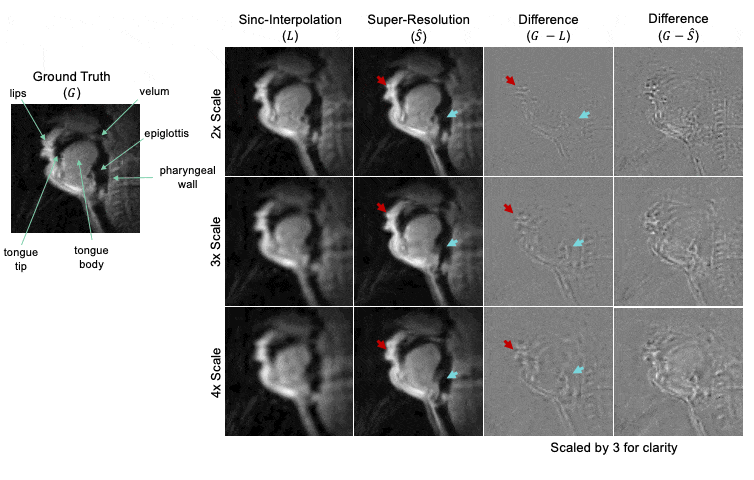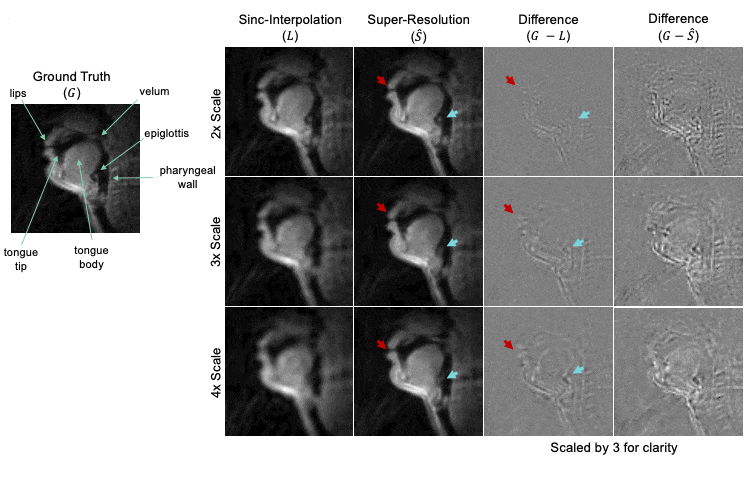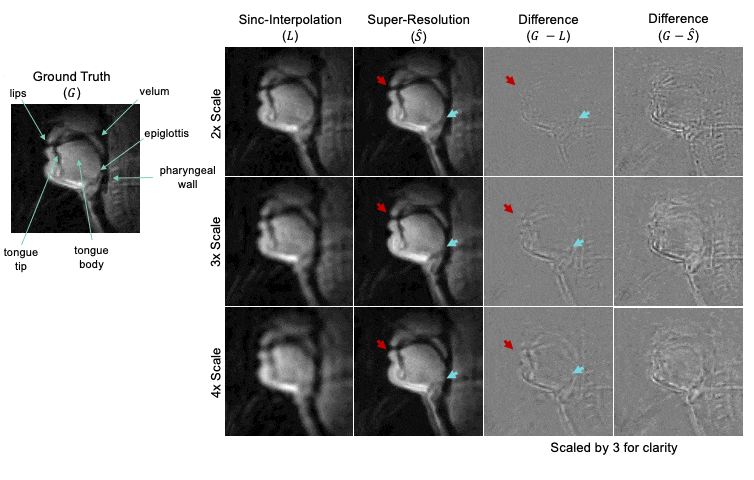
Figure 3 summarizes quantitative results over the entire test set across all scale factors. The super-resolution network decreased MSE, increased SSIM, and increased PSNR compared to sinc-interpolated input images. Table 1 shows percentage improvement for all scale factors.Figure 4 shows representative results for 2x, 3x, and 4x scales from one female 24-year-old native English speaker from the test set. The network outputs improve upon their low-resolution counterparts by providing more clear boundaries of the velum and tongue. The low-resolution input has considerable detail-smoothing, which causes blurring of the lips upon closure and the epiglottis in all time frames. The network was unable to compensate for this blurring, as the epiglottis is correctly reconstructed in the 2x case but is lost in the 4x case.
Training one epoch took approximately 1 hour and 25 minutes on an Nvidia Tesla p100 GPU. The network converged quickly after approximately 10 epochs. Execution of the network took ~56 milliseconds per timeframe.
Discussion
The deep neural network provided improved MSE, SSIM, and PSNR compared to sinc-interpolated input images, indicating that deep learning approaches to super-resolution in speech RT-MRI are feasible. Super-resolution could allow us to collect fewer k-space samples and shorter readouts as shown in Table 1. Shorter readouts can potentially improve temporal resolution and off-resonance corruption, which is a major limitation especially at 3T.8 Increased temporal resolution could allow us to reduce motion blurring for faster speech events such as closures of alveolar trills and consonant constriction.5This work has several limitations. Among them, we did not: 1) compare performance against non-DL approaches for super-resolution, 2) utilize newer super-resolution architectures such as EDSR or SrGAN9,10, 3) leverage the dynamic information and for simplicity, performed SR frame-by-frame11, or 4) apply this to prospectively applied low-resolution data. Furthermore, we speculate that a different loss function, such as L1 or SSIM loss could deal with some of the detail-smoothing issues. These remain future work.
Conclusion
We have demonstrated the feasibility of deep learning super-resolution to generate high-resolution speech RT-MRI. Results show quantitative and qualitative improvements in vocal tract articulator depiction when compared to standard sinc-interpolation. Super-resolution was unable to reach the same quality as traditional high-resolution counterparts but can open up new opportunities for RT-MRI with finer temporal resolution, which is important when imaging rapid speech including alveolar trills.Acknowledgements
This work was supported by NSF Grant 1514544 and NIH Grant R01-DC007124. We acknowledge the support and collaboration of the Speech Production and Articulation kNowledge (SPAN) group at the University of Southern California, Los Angeles, CA, USA.References
1. Kim J, Lee JK, Lee KM. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2015;1:1646-1654. Accessed October 18, 2020. http://arxiv.org/abs/1511.04587
2. Masutani EM, Bahrami N, Hsiao A. Deep learning single-frame and multiframe super-resolution for cardiac MRI. Radiology. 2020;295(3):552-561.
3. Steeden JA, Quail M, Gotschy A, et al. Rapid whole-heart CMR with single volume super-resolution. Journal of Cardiovascular Magnetic Resonance. 2020;22(1):56. doi:10.1186/s12968-020-00651-x
4. Chaudhari AS, Fang Z, Kogan F, et al. Super‐resolution musculoskeletal MRI using deep learning. Magnetic Resonance in Medicine. 2018;80(5):2139-2154. doi:10.1002/mrm.27178
5. Lingala SG, Sutton BP, Miquel ME, Nayak KS. Recommendations for real-time speech MRI. Journal of Magnetic Resonance Imaging. 2016;43(1):28-44. doi:10.1002/jmri.24997
6. Lingala SG, Zhu Y, Kim YC, Toutios A, Narayanan S, Nayak KS. A fast and flexible MRI system for the study of dynamic vocal tract shaping. Magnetic Resonance in Medicine. 2017;77(1):112-125. doi:10.1002/mrm.26090
7. Lingala SG, Toutios A, Toger J, et al. State-of-the-art MRI Protocol for Comprehensive Assessment of Vocal Tract Structure and Function. Published online 2016. doi:10.21437/Interspeech.2016-559
8. Lim Y, Lingala SG, Narayanan SS, Nayak KS. Dynamic off-resonance correction for spiral real-time MRI of speech. Magnetic Resonance in Medicine. 2019;81(1):234-246. doi:10.1002/mrm.27373
9. Lim B, Son S, Kim H, Nah S, Lee KM. Enhanced Deep Residual Networks for Single Image Super-Resolution. IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. 2017;2017-July:1132-1140. Accessed November 1, 2020. http://arxiv.org/abs/1707.02921
10. W. Yang, X. Zhang, Y. Tian, W. Wang, J. Xue and Q. Liao, “Deep Learning for Single Image Super-Resolution: A Brief Review,” IEEE Transactionson Multimedia. 2019;21(12):3106-3121. doi: 10.1109/TMM.2019.2919431
11. Sajjadi MSM, Vemulapalli R, Brown M. Frame-Recurrent Video Super-Resolution. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Published online January 14, 2018:6626-6634. Accessed October 19, 2020. http://arxiv.org/abs/1801.04590
Figures