1781
Enhancing the Reconstruction quality of Physics-Guided Deep Learning via Holdout Multi-Masking1University of Minnesota, Minneapolis, MN, United States, 2Center for Magnetic Resonance Research, Minneapolis, MN, United States
Synopsis
Physics-guided deep learning (PG-DL) approaches unroll conventional iterative algorithms consisting of data consistency (DC) and regularizers, and typically perform training on a fully-sampled database. Although supervised training has been incredibly successful, there is still room for further removing residual and banding artifacts. To improve reconstruction quality and robustness of supervised PG-DL, we propose to use multiple subsets of acquired measurements in the DC units during training by applying a multi-masking operation on available sub-sampled data, unlike existing supervised PG-DL approaches that use all the available measurements in DC units. Proposed method outperforms conventional supervised PG-DL method by further reducing theartifacts.
INTRODUCTION
Conventional iterative algorithms for MRI reconstruction such as proximal gradient descent or variable splitting approaches alternate between data consistency (DC) and regularizers1. Physics-guided deep learning (PG-DL) approaches unroll these iterative algorithms for a fixed number of iterations and typically perform end-to-end training on a fully-sampled database2-7. Regardless of the unrolled iterative optimization method, DC units of all existing supervised PG-DL approaches use all available measurements to ensure consistency with acquired measurements, and the unrolled network learns to fit the rest of the measurements6. While supervised PG-DL generally provides state-of-art reconstruction quality, its reconstruction performance may show residual artifacts and banding artifacts which has been regarded as a bottleneck for translation of DL into practice5,8,9.In this work, we propose to enhance the reconstruction quality and robustness of supervised training of PG-DL by retrospectively selecting multiple random subsets of the acquired measurements for each scan, and use these in the DC units. Results on fastMRI knee dataset show that proposed multi-mask supervised PG-DL approach improves reconstruction quality by further removing residual and banding artifacts.
THEORY
Let $$$\mathbf{y}_{\Omega}$$$ denote acquired measurements with sub-sampling pattern $$$\Omega$$$ and x be the image to be recovered. MRI reconstruction from undersampled measurements is modeled as,$$\arg\min_{\bf x}\|\mathbf{y}_{\Omega}-\mathbf{E}_{\Omega}\mathbf{x}\|^2_2+\cal{R}(\mathbf{x}), (1)$$where $$$\mathbf{E}_{\Omega}$$$ is the multi-coil encoding operator, $$$\|\mathbf{y}_{\Omega}-\mathbf{E}_{\Omega}\mathbf{x}\|^2_2$$$ is DC unit and $$$\cal{R}(.)$$$ is a regularizer. PG-DL unrolls conventional iterative algorithms for solving Eq.1 for a fixed number of iterations. Let $$${\bf y}_{\textrm{ref}}^i$$$ denote the fully-sampled k-space for subject i and $$$f({\bf y}_{\Omega}^i,{\bf E}_{\Omega}^i;{\bf\theta})$$$ denotes network output with parameters θ. Supervised PG-DL performs end-to-end training by minimizing10
$$\min_{\bf\theta}\frac1N\sum_{i=1}^{N}\mathcal{L}({\bf y}_{\textrm{ref}}^i,\:{\bf E}_{full}^if({\bf y}_{\Omega}^i,{\bf E}_{\Omega}^i;{\bf\theta})), (2)$$
where N is number of datasets in the database, $$${\bf E}_{full}^i$$$ is the fully-sampled multi-coil encoding operator that transform network output to k-space, and $$$\mathcal{L}(\cdot,\cdot)$$$ is training loss.
While supervised PG-DL provides state-of-the-art reconstruction quality, we hypothesize that incorporating randomness by a holdout masking operation in the DC unit will further improve reconstruction quality. We propose to use a random subset of acquired measurements in the DC units by retrospectively masking $$$\Omega$$$ multiple times as $$$\Theta_j\subset\Omega$$$ for j=1,…,K. Hence, objective function in Eq. 4 can be reformulated for multi-mask supervised PG-DL training as $$\min_{\bf\theta}\frac1N\sum_{i=1}^{N}\mathcal{L}\Big({\bf y}_{ref}^i,\:{\bf E}_{full}^i\big(f({\bf y}_{\Theta_j}^i,{\bf E}_{\Theta_j}^i;{\bf\theta})\big)\Big). (3)$$
METHODS
Fully-sampled coronal proton density (PD) with and without fat-suppression (PD-FS) knee datasets were obtained from the NYU fastMRI database11. These were retrospectively uniformly sub-sampled at R=4, and 24 ACS lines. For both coronal PD and PD-FS, training was performed on 300 slices from 15 subjects for both coronal PD and PD-FS and testing was performed on 10 new subjects.For both conventional and proposed multi-mask supervised PG-DL approaches, networks were trained using Adam optimizer with a learning rate 5×10-4 by minimizing a mixed normalized $$$\ell_1$$$-$$$\ell_2$$$ loss function over 100 epochs using the same network architecture10. Conjugate-gradient and ResNet were used in DC and regularizer units of the unrolled network, respectively. Both supervised PG-DL approaches were also compared with CG-SENSE. Structural similarity index (SSIM) and peak signal-to-noise ratio (PSNR) was used for quantitative assessments.
RESULTS
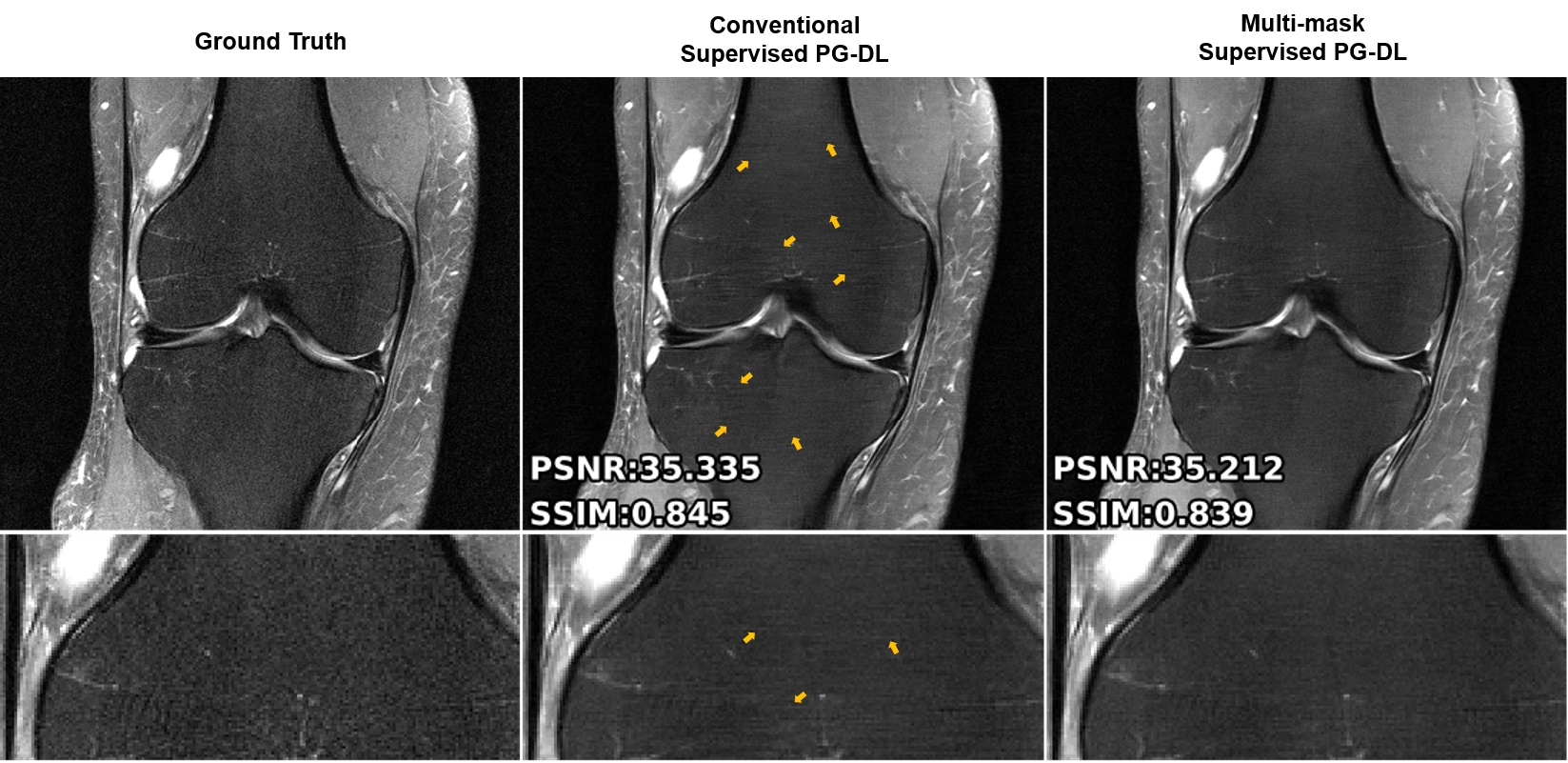
Fig. 2 shows reconstruction results for conventional supervised PG-DL and the proposed multi-mask supervised PG-DL, as well as CG-SENSE. CG-SENSE reconstruction suffers from major residual artifacts. Proposed multi-mask supervised PG-DL achieves an artifact-free and improved reconstruction quality compared to conventional supervised PG-DL, which suffers from residual artifacts shown by red arrows. Fig. 3 shows average quantitative metrics on test dataset for coronal PD dataset. Fig. 4 shows conventional and proposed multi-mask supervised PG-DL reconstruction performance for banding artifact removal for a representative test slice from the coronal PD-FS dataset. Conventional supervised PG-DL reconstruction suffers from visible banding artifacts shown with yellow arrows, whereas the proposed multi-mask supervised PG-DL considerably suppresses the banding artifacts. Interestingly, the conventional approach has better quantitative metrics despite the banding artifacts, in agreement with previous reports of the shortcomings of SSIM and NMSE9.DISCUSSION
In this study, we proposed a multi-mask supervised PG-DL training to improve reconstruction quality of conventional supervised PG-DL approaches. We showed that using multiple subsets of available measurements for each scan in DC units, as opposed to conventional supervised PG-DL that uses all available subsampled measurements in DC units, helps to remove residual artifacts while preserving overall image quality. Moreover, proposed multi-mask supervised PG-DL approach reduces banding artifacts that have been a major challenge for existing conventional supervised PG-DL approaches. Note that the multi-mask holdout approach proposed here is fundamentally different than the data augmentation strategy that uses multiple different $$$\Omega$$$ during training12, which focuses on selecting multiple subsets of $$$\Omega$$$ itself, typically for random undersampling patterns. In contrast, we concentrated on uniform undersampling, where there is only one such possible pattern. Furthermore, our approach can be used to further augment this strategy of selecting multiple $$$\Omega$$$.CONCLUSIONS
Proposed multi-mask supervised PG-DL approach provides an improved reconstruction quality by retrospectively selecting multiple random subset of measurements from available acquired subsampled data for use in DC units.Acknowledgements
Grant support:NIH P30NS076408, NIH 1S10OD017974-01, NIH R01HL153146, NIH P41EB027061, NIH U01EB025144; NSF CAREER CCF-1651825References
1. Fessler JA. Optimization Methods for Magnetic Resonance Image Reconstruction: Key Models and Optimization Algorithms. IEEE Signal Process Mag 2020;37(1):33-40.
2. Hammernik K, Klatzer T, Kobler E, Recht MP, Sodickson DK, Pock T, Knoll F. Learning a variational network for reconstruction of accelerated MRI data. Magn Reson Med 2018;79(6):3055-3071. 3. Aggarwal HK, Mani MP, Jacob M. MoDL: Model-Based Deep Learning Architecture for Inverse Problems. IEEE Trans Med Imaging 2019;38(2):394-405.
4. Mardani M, Sun Q, Donoho D, Papyan V, Monajemi H, Vasanawala S, Pauly J. Neural proximal gradient descent for compressive imaging. Advances in Neural Information Processing Systems; 2018. p 9573-9583.
5. Hosseini SAH, Yaman B, Moeller S, Hong M, Akcakaya M. Dense Recurrent Neural Networks for Inverse Problems: History-Cognizant Unrolling of Optimization Algorithms. IEEE Journal of Selected Topics in Signal Processing 2020;14(6):1280-1291.
6. Liang D, Cheng J, Ke Z, Ying L. Deep Magnetic Resonance Image Reconstruction: Inverse Problems Meet Neural Networks. IEEE Signal Processing Magazine; 2020. p 141-151.
7. Qin C, Schlemper J, Caballero J, Price AN, Hajnal JV, Rueckert D. Convolutional Recurrent Neural Networks for Dynamic MR Image Reconstruction. IEEE Trans Med Imaging 2019;38(1):280-290.
8. Defazio A, Murrell T, Recht MP. MRI Banding Removal via Adversarial Training. Advances in Neural Information Processing Systems; 2020.
9. Knoll F, Murrell T, Sriram A, Yakubova N, Zbontar J, Rabbat M, Defazio A, Muckley MJ, Sodickson DK, Zitnick CL, Recht MP. Advancing machine learning for MR image reconstruction with an open competition: Overview of the 2019 fastMRI challenge. Magn Reson Med 2020;84(6):3054-3070.
10. Yaman B, Hosseini SAH, Moeller S, Ellermann J, Uğurbil K, Akçakaya M. Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data. Magn Reson Med 2020;84(6):3172-3191.
11. Knoll F, Zbontar J, Sriram A, Muckley MJ, Bruno M, Defazio A, Parente M, Geras KJ, Katsnelson J, Chandarana H, Zhang Z, Drozdzalv M, Romero A, Rabbat M, Vincent P, Pinkerton J, Wang D, Yakubova N, Owens E, Zitnick CL, Recht MP, Sodickson DK, Lui YW. fastMRI: A Publicly Available Raw k-Space and DICOM Dataset of Knee Images for Accelerated MR Image Reconstruction Using Machine Learning. Radiol Artif Intell 2020;2(1):e190007.
12 . Muckley MJ, Riemenschneider B, Radmanesh A, Kim S, Jeong G, Ko J,Jun Y,Shin H, Hwang D, Mostapha M, Arberet S, Nickel D, Ramzi Z, Ciuciu P, Starck LJ, Teuwen J, Karkalousos D, Zhang C, Sriram A, Huang Z, Yakubova N, Lui Y, Knoll F. State-of-the-art Machine Learning MRI Reconstruction in 2020: Results of the Second fastMRI Challenge. arXiv 2012.06318.
Figures
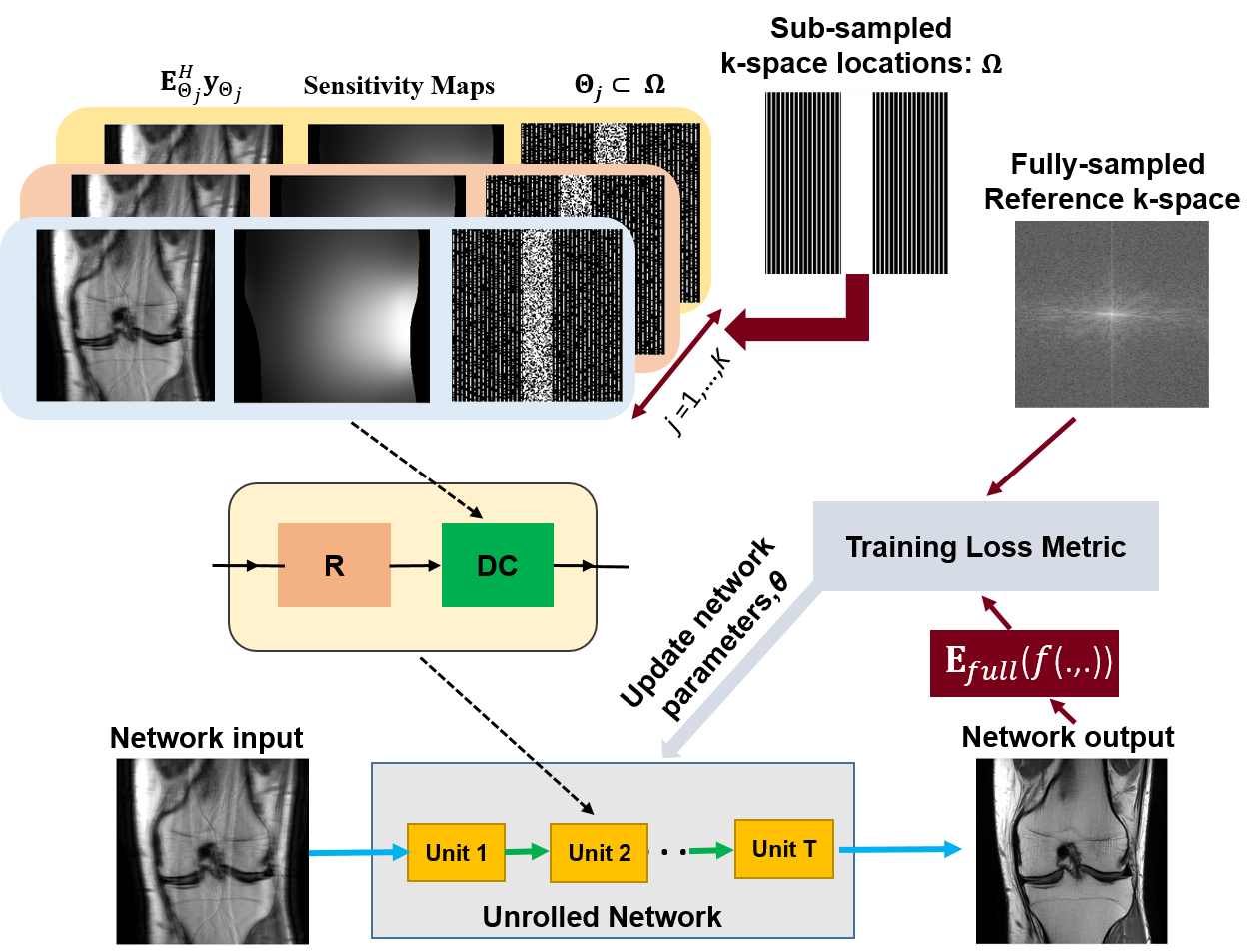
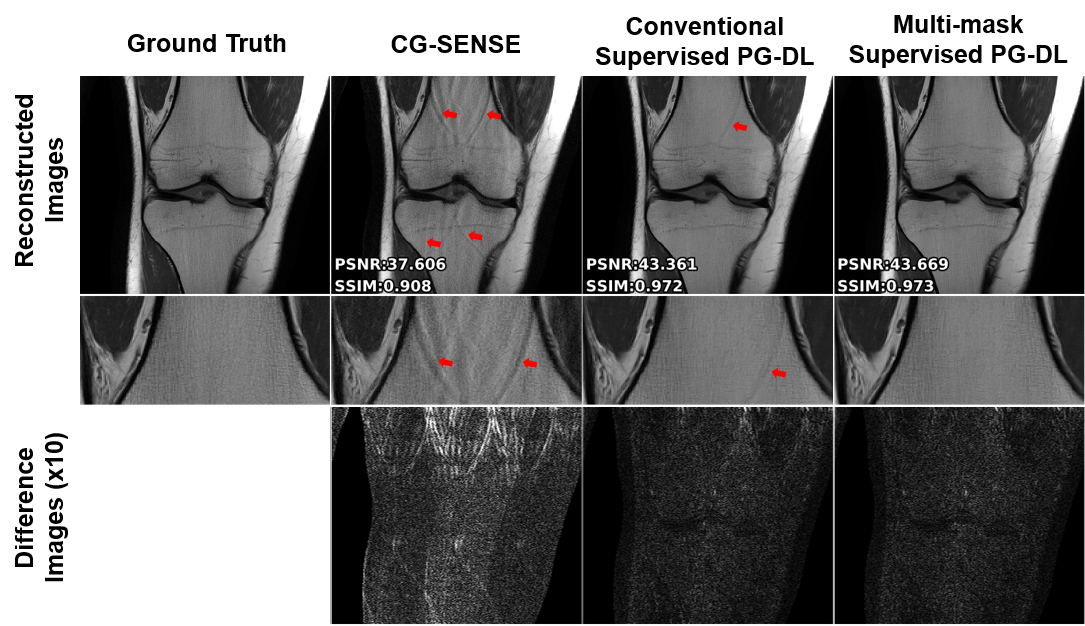
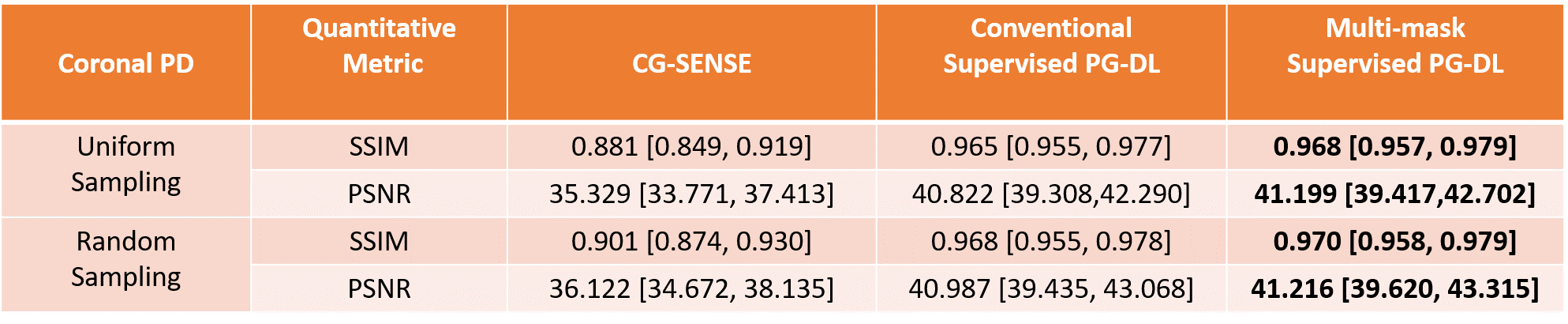
Figure 3. The median and interquartile range (25th-75th percentile) of SSIM and PSNR metrics on coronal PD test dataset. The proposed multi-mask supervised PG-DL achieves improved SSIM and PSNR metrics compared to conventional supervised PG-DL, and both PG-DL approaches outperform CG-SENSE significantly.