1779
MRI super-resolution reconstruction: A patient-specific and dataset-free deep learning approach1Harvard Medical School, Boston, MA, United States, 2Boston Children's Hospital, Boston, MA, United States
Synopsis
Spatial resolution is critically important in MRI. Unfortunately, direct high-resolution acquisition is time-consuming and suffers from reduced signal-to-noise ratio. Deep learning-based super-resolution has emerged to improve MRI resolution. However, current methods require large-scale training datasets of high-resolution images, which are difficult to obtain at suitable quality. We developed a deep learning technique that trains the model on the patient-specific low-resolution data, and achieved high-quality MRI at a resolution of 0.125 cubic mm with six minutes of imaging time. Experiments demonstrate our approach achieved superior results to state-of-the-art super-resolution methods, while reduced scan time as delivered with direct high-resolution acquisitions.
Introduction
Spatial resolution plays a critically important role in MRI. High resolution allows for precise delineation of anatomical structures and enables high-quality interpretation and analyses. However, high-resolution (HR) acquisition is time-consuming, costly, and leads to low signal-to-noise ratio (SNR)1,2. Deep learning has recently emerged to improve spatial resolution through super-resolution reconstruction (SRR)3,4,5,6,7. However, the majority of state-of-the-art deep learning methods for MRI super-resolution require large-scale training datasets of high-resolution images that are practically difficult to obtain at suitable SNR8. It is difficult to generalize these deep learned models with the images acquired from different scanners, with different intensity properties, and of variable tissue contrasts in different populations. Therefore, current training data-oriented deep SRR models, even with practically available and sufficiently large HR training datasets, do not guarantee the success or sufficient quality of SRR for every subject in a cohort, once have completed training. These limitations suggest that it is critically important to perform SRR with a patient-specific and dataset-free deep learning technique. Such a method enables high-quality SRR through powerful deep learning techniques, while, in parallel, eliminates the dependence on training datasets, and in turn, allows SRR tailored to the individual patient.We sought to develop a technique to construct images with spatial resolution higher than can be practically obtained by direct Fourier encoding while ensuring high SNR. A deep architecture is designed and learned for each individual patient on the data acquired at low resolution. We achieved high-quality MRI at a resolution of 0.125 cubic mm with six minutes of imaging time for T2 contrast. Experiments demonstrate that our approach achieved superior results to state-of-the-art SRR methods, and reduced scan time as scans delivered with direct HR acquisitions.
Methods
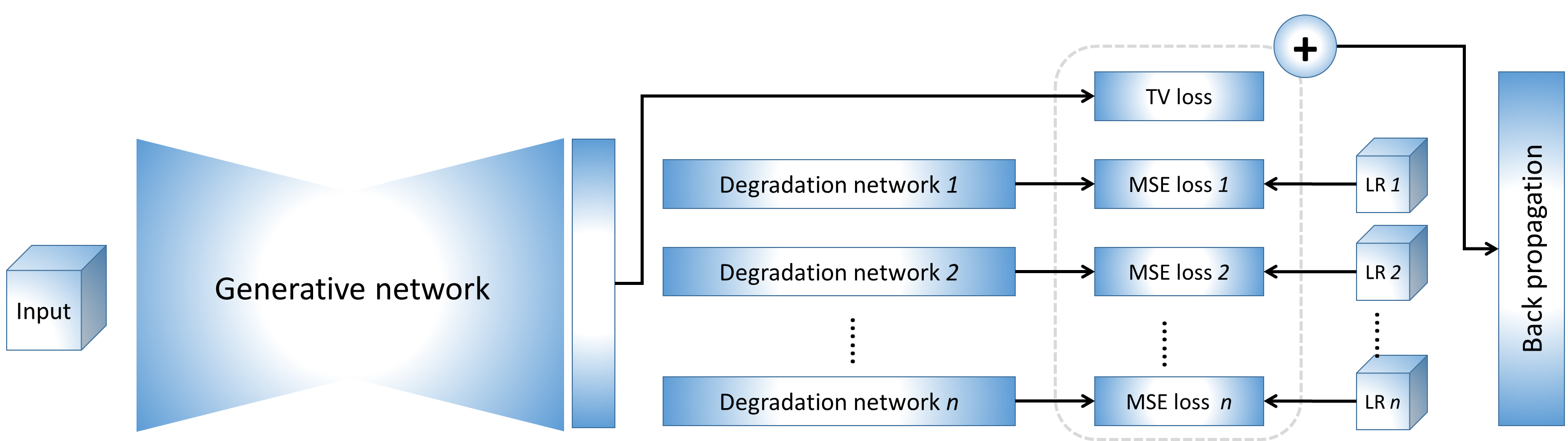
The basic idea of our approach is to generate an HR image using deep neural networks. The generation is restricted by an imaging model that implemented by the degradation networks. The networks are trained on the low-resolution (LR) image data acquired from the specific patient only, with no requirements of HR training datasets. The overview of our deep SRR model is illustrated in Figure 1.We simulated a data set based on twenty T1W and twenty T2W HR MRI scans randomly selected from the Human Connectome Project (HCP)9 to demonstrate that our approach can offer correct reconstructions while ensuring high quality. These HR scans were acquired at an isotropic resolution of 0.7mm, and used as the ground truths. We simulated three LR images from each HR image by increasing their slice thickness to 2mm in the directions x, y, and z, respectively.
We acquired a clinical data set from fifteen pediatric patients on a 3T MRI scanner to demonstrate that our approach can achieve images of diagnostic quality for clinical uses in six minutes of imaging time. For each patient, three T2W FSE LR images were acquired in three complementary planes. The in-plane resolution was 0.5mm x 0.5mm and the slice thickness was 2mm. We used TR/TE=14240/95ms with an echo train length of 16, a flip angle of 160 degrees, and a pixel bandwidth of 195Hz/pixel. It took about two minutes in acquiring a T2W FSE image with this protocol. We reconstructed the HR image at an isotropic resolution of 0.5mm.
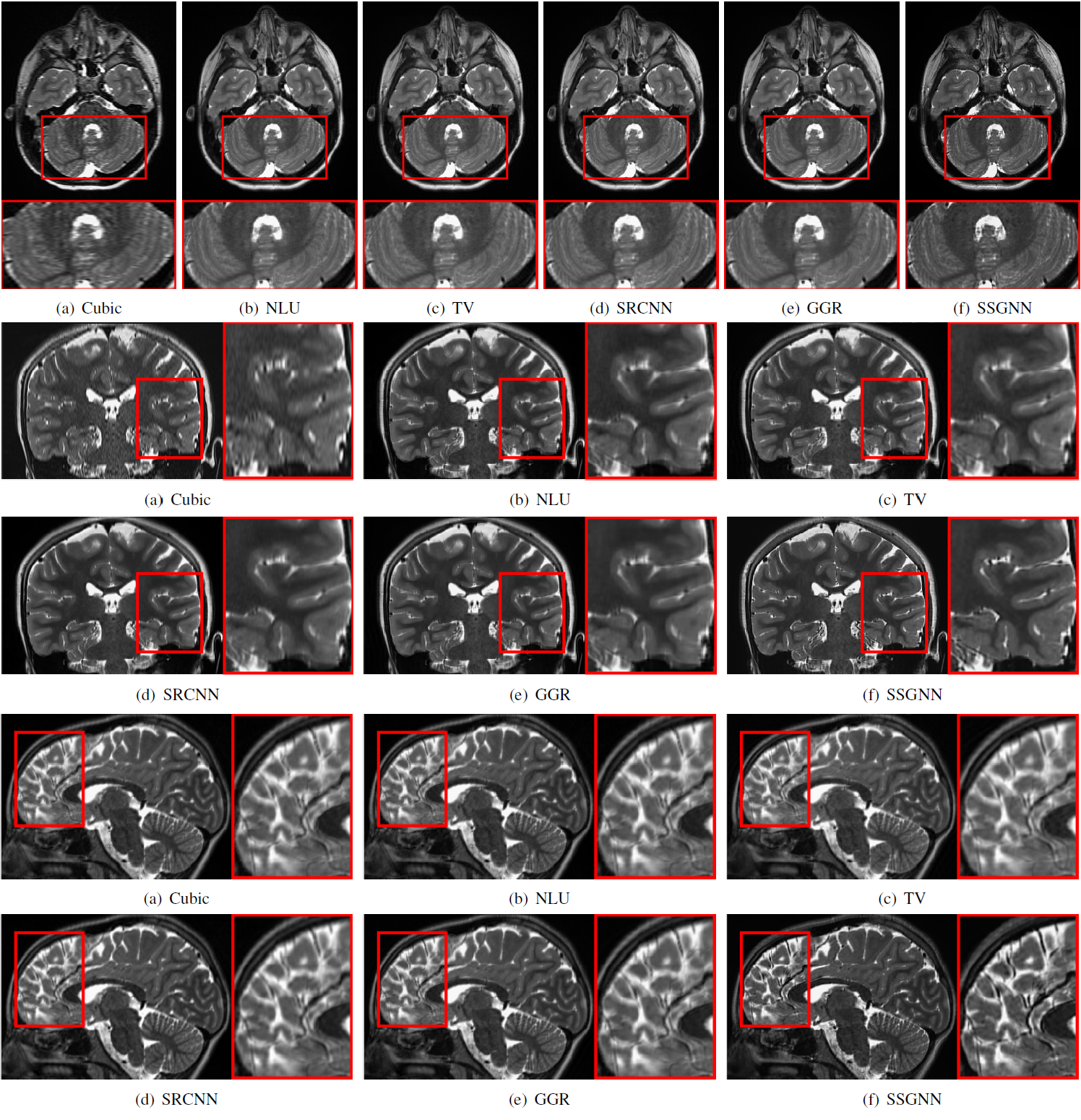
We employed five state-of-the-art methods in the same category as our approach as the baselines, including cubic interpolation, NLU10, TV1, SRCNN11, and GGR12.
Results
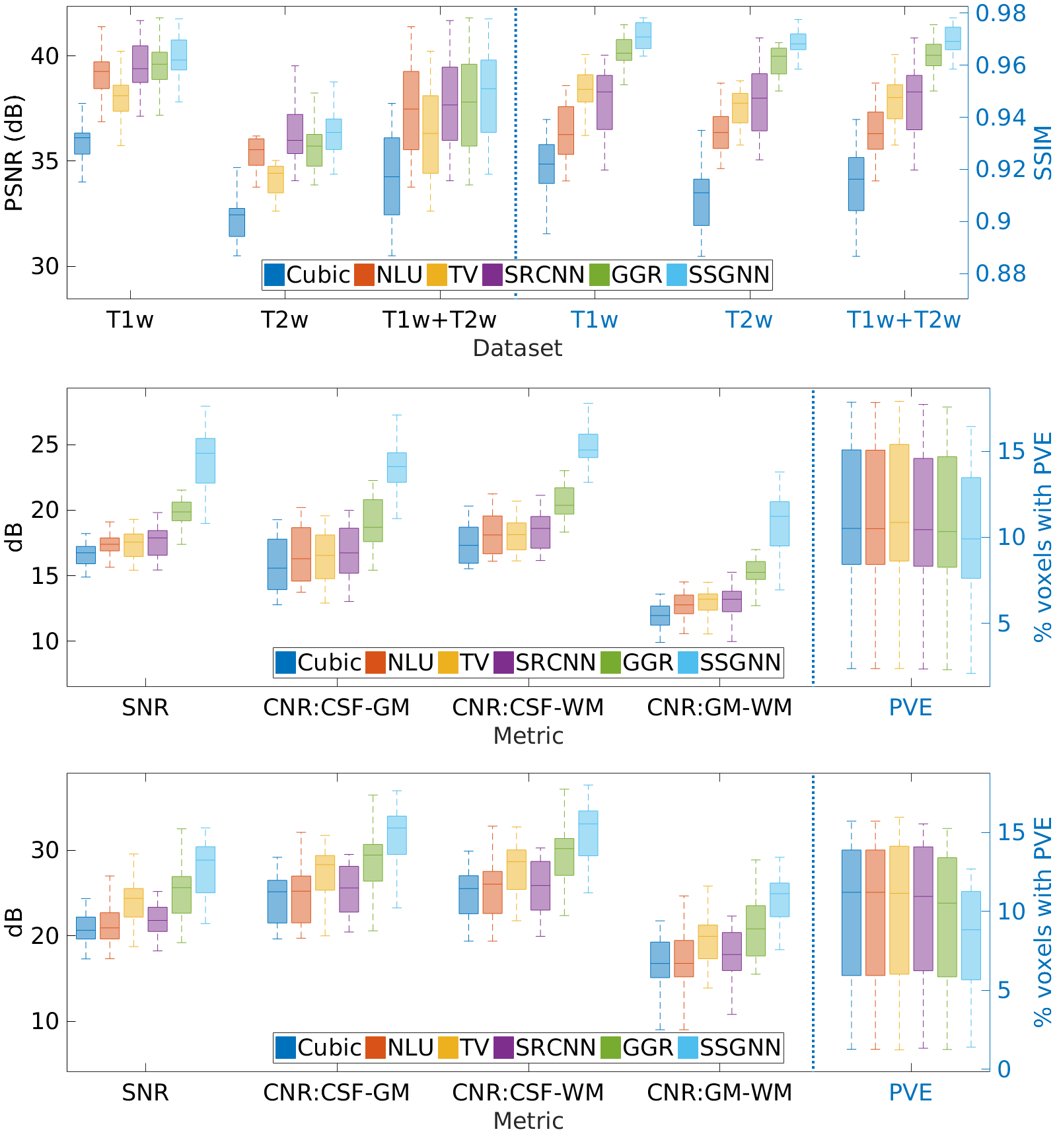
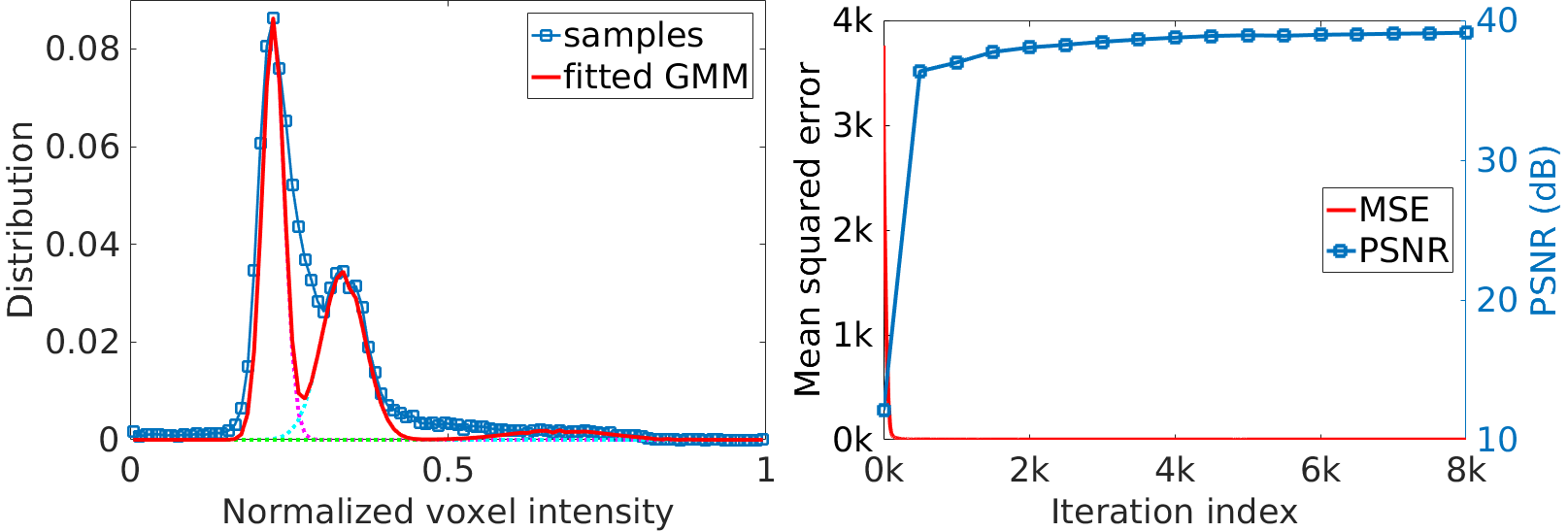
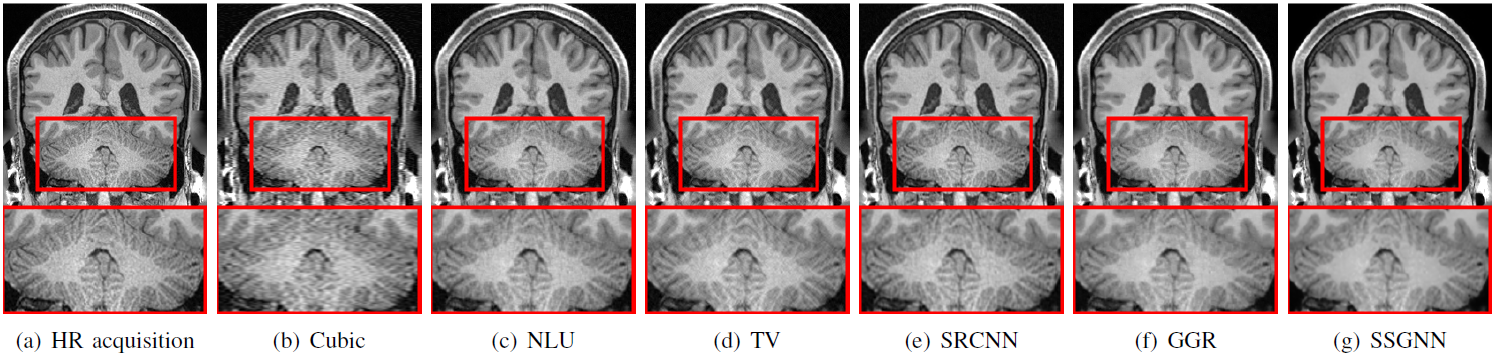
Figure 2 shows the quantitative results of our approach and the five baselines in terms of reconstruction accuracy (PSNR and SSIM), SNR, CNRs, and spatial resolution (PVE) on the HCP and clinical datasets. Our approach achieved a PSNR of 38.11±2.11dB and an SSIM of 97.0±0.005 on average on the simulated dataset. On the clinical dataset, our approach offered an average SNR of 28.1+/-3.3dB, which was 11.6% (2.9dB) higher than obtained by the second-best method, GGR, and 34.2% (7.2dB) higher than obtained by Cubic. These results show that our approach offered the most accurate reconstructions the highest spatial resolution on this data set. Figure 3 shows the estimation of PVE and the converging process of our approach. Figures 4 and 5 show the qualitative results on the clinical dataset.Discussion
We have developed a technique that allows for patient-specific and dataset-free deep learning-based SRR. We have demonstrated that our technique enables the deep SRR model tailored to the individual patient. We have demonstrated a methodology that allows for constructing considerably improved high-quality images at an isotropic resolution of 0.125 cubic mm, in comparison to state-of-the-art methods, while with dramatically reduced imaging time, as compared to direction HR acquisition.We have demonstrated that our approach correctly converged, as shown in Figure 3. We have shown in Figure 2 that our approach generated correct reconstructions, substantially improved the reconstruction accuracy in terms of PSNR and SSIM, and considerably improved the MRI quality according to SNR, CNRs, and spatial resolution (PVE). These results have demonstrated that our technique ensures the reliability and applicability of our SRR approach and offered fast and diagnostic quality MRI for resolution-critical use in both scientific research and clinical studies.
Acknowledgements
Research reported in this publication was supported in part by the National Institute of Biomedical Imaging and Bioengineering, the National Institute of Neurological Disorders and Stroke, and the National Institute of Mental Health of the National Institutes of Health (NIH) under Award Numbers R01 NS079788, R01 EB019483, R01 EB018988, R01 NS106030, IDDRC U54 HD090255; a research grant from the Boston Children's Hospital Translational Research Program; a Technological Innovations in Neuroscience Award from the McKnight Foundation; a research grant from the Thrasher Research Fund; and a pilot grant from National Multiple Sclerosis Society under Award Number PP-1905-34002. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH, the National Multiple Sclerosis Society, the Boston Children's Hospital, the Thrasher Research Fund, or the McKnight Foundation.References
- E. Plenge, D. H. J. Poot, M. Bernsen, G. Kotek, G. Houston, P. Wielopol-ski, L. van der Weerd, W. J. Niessen, and E. Meijering, “Super-resolution methods in MRI: Can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time?” Magnetic Resonance in Medicine, vol. 68, pp. 1983–1993, 2012.
- R. W. Brown, Y.-C. N. Cheng, E. M. Haacke, M. R. Thompson, and R. Venkatesan, Magnetic resonance imaging: Physical principles and sequence design, 2nd Edition. Wiley, 2014.
- A. Chaudhari, Z. Fang, F. Kogan, J. Wood, K. Stevens, E. Gibbons, J. Lee, G. Gold, and B. Hargreaves, “Super-resolution musculoskeletal MRI using deep learning,” Magnetic Resonance in Medicine, vol. 80, no. 5, pp. 2139–2154, 2018.
- Y. Chen, F. Shi, A. G. Christodoulou, Y. Xie, Z. Zhou, and D. Li, “Efficient and accurate MRI super-resolution using a generative adversarial network and 3D multi-level densely connected network,” in Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2018.
- V. Cherukuri, T. Guo, S. J. Schiff, and V. Monga, “Deep MR brain image super-resolution using spatio-structural priors,” IEEE Transactions on Image Processing, vol. 29, pp. 1368–1383, 2020.
- X. Xue, Y. Wang, J. Li, Z. Jiao, Z. Ren, and X. Gao, “Progressive sub-band residual-learning network for MR image super-resolution,” IEEE Journal of Biomedical Health Informatics, vol. 24, no. 2, pp. 377–386, 2020.
- X. Zhao, Y. Zhang, T. Zhang, and X. Zou, “Channel splitting network for single MR image super-resolution,” IEEE Transactions on Image Processing, vol. 28, no. 11, pp. 5649–5662, 2019.
- O. Afacan, B. Erem, D. P. Roby, N. Roth, A. Roth, S. P. Prabhu, and S. K. Warfield, “Evaluation of motion and its effect on brain magnetic resonance image quality in children,” Pediatric Radiology, vol. 46, no. 12, pp. 1728–1735, 2016.
- D. Essen, S. Smith, D. Barch, T. E. J. Behrens, E. Yacoub, and K. Ugurbil, “The wu-minn human connectome project: An overview,” NeuroImage, vol. 80, pp. 62–79, 2013.
- J. V. Manjon, P. Coupe, A. Buades, V. S. Fonov, D. L. Collins, and M. Robles, “Non-local MRI upsampling,” Medical Image Analysis, vol. 14, no. 6, pp. 784–792, 2010.
- C. Dong, C. C. Loy, K. He, and X. Tang, “Image Super-Resolution UsingDeep Convolutional Networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 2, pp. 295–307, 2016.
- Y. Sui, O. Afacan, A. Gholipour, and S. K. Warfield, “Isotropic MRI super-resolution reconstruction with multi-scale gradient field prior,” in Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2019.
Figures