1777
Evaluation of Super Resolution Network for Universal Resolution Improvement1Philips Research North America, Cambridge, MA, United States, 2MR Clinical Science, Philips Healthcare North America, Gainesville, FL, United States, 3MR Clinical Science, Philips Healthcare, Best, Netherlands, 4Philips Research Hamburg, Hamburg, Germany, 5Vascular Imaging Lab, University of Washington, Seattle, WA, United States
Synopsis
In this work, we investigated whether deep learning based super resolution (SR) network trained from a brain dataset can generalize well to other applications (i.e. knee and abdominal imaging). Our preliminary results imply that 1) the perceptual loss function can improve the generalization performance of SR network across different applications; 2) the multi-scale network architecture can better stabilize the SR results particularly for training dataset with lower quality. In addition, the SR improvement from increased data diversity can be saturated, indicating that a single trained SR network might be feasible for universal MR image resolution improvement.
Introduction
Deep learning (DL) based super-resolution (SR) technique1-3 allows to approximate the high-resolution (HR) image from the acquired low-resolution (LR) image, which can shorten the MR scan time and improve the signal-to-noise ratio (SNR). Therefore, it has promising potential to replace and advance the existing image interpolation/upsampling process on the scanner console. However, the diversity of training database is impossible to involve all different sequences, resolutions, applications (i.e. anatomies) and vendors. It is critical to evaluate the generalization capability of the trained SR network and identify factors to improve the SR network robustness. In this work, we aim to evaluate the impact of network structure, loss function and the diversity of training database to the generalization performance of a trained SR network from brain datasets in knee and body MR applications.Methods
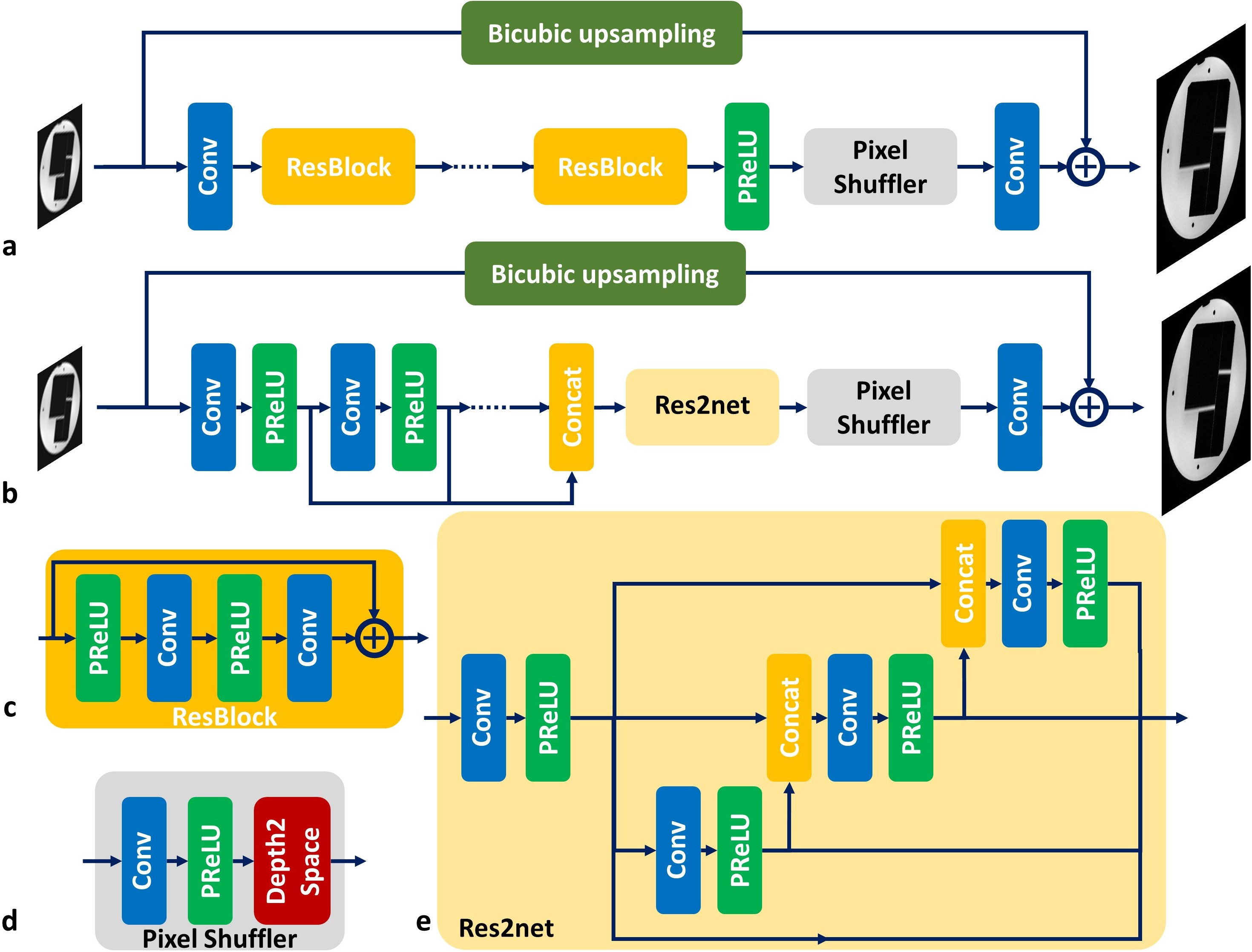
Network ArchitecturesThe generative adversarial network based SR (SRGAN)4 (Fig. 1a) was explored as the baseline model, where the generator network processes the input LR image by a cascade of residual blocks (RESNET) and upsamples the extracted features by a pixel shuffler block to combine with the bicubic upsampled image for HR image synthesis. Such processing pipeline can largely reduce the GPU memory consumption because most of feature extraction operations are processed in a smaller spatial dimension (i.e. LR image size). A variation of SRGAN network was also investigated (Fig. 1b), where the cascade of residual blocks was replaced by a multi-scale feature extraction block5 and a Res2net block6 for multi-scale feature synthesis (MSRES2NET).
Loss Functions
Three different loss functions were used to train different SR networks for comparison. The pixel-wise L1 loss was considered as the baseline loss function, and further combined with adversarial loss and perceptual loss. The adversarial loss uses a learnable discriminator network7 to evaluate the distance between generated HR image and ground truth during the training process. Such learned discriminator network can be beneficial to restore detailed structural information in the training database. In contrast, the perceptual loss uses a pre-trained VGG network8 (first several convolutional layers before the second max pooling layers) as the distance metric, where this VGG network was trained for image classification on the ImageNet database. Such fixed discriminator network may better guide the synthesis of detailed image structures within a much broader range of image variations.
MR Datasets
We downloaded a HR brain dataset9 to train the SR network and evaluate its generalization performance, which includes 2D T2* gradient echo (0.12x0.12x0.6mm3), 3D MPRAGE (isotropic 0.44mm) and 3D TOF (isotropic 0.2mm) images acquired at Siemens 7T from one subject. We down-sampled these HR images into routine clinical resolutions (0.8mm~1.2mm) at 3T, and cropped the images into 2D patches (80x80) with different orientations and resolutions for training. For SR factor of 2, the paired LR image can be cropped from the central half of the HR k-space data. In addition, 20 cases of 3D DIXON T1 turbo field echo abdominal images (0.8x0.8x1.5mm3) were acquired on a Philips Ingenia 3T scanner. Another 20 cases of 3D fast spin echo knee images (0.5x0.5x0.6mm3) acquired on a GE 3T scanner were downloaded from mridata.org. Both body and knee datasets were used to train separate SR networks as the references in comparison to direct application of trained SR network from the brain data.
Results
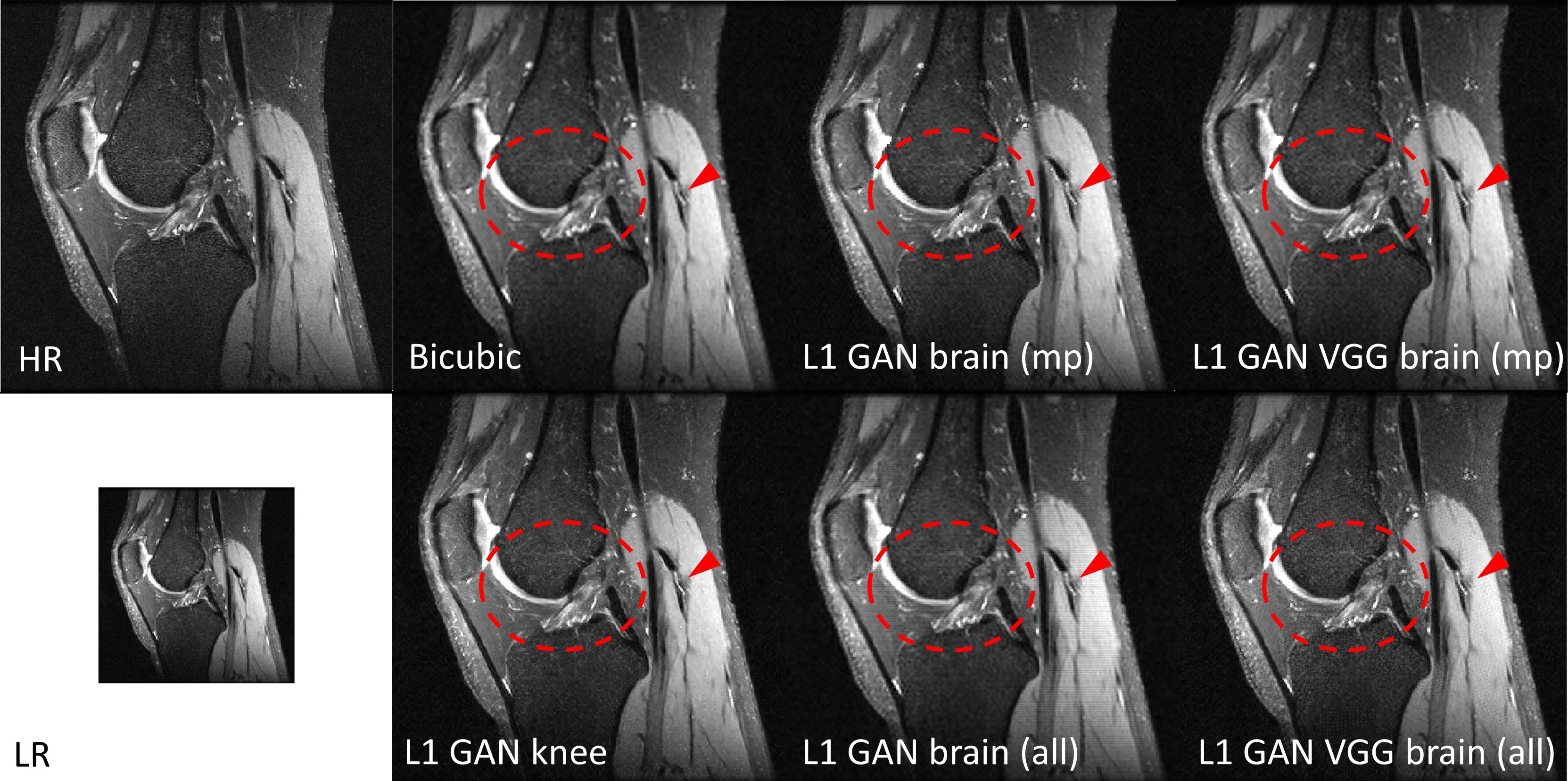
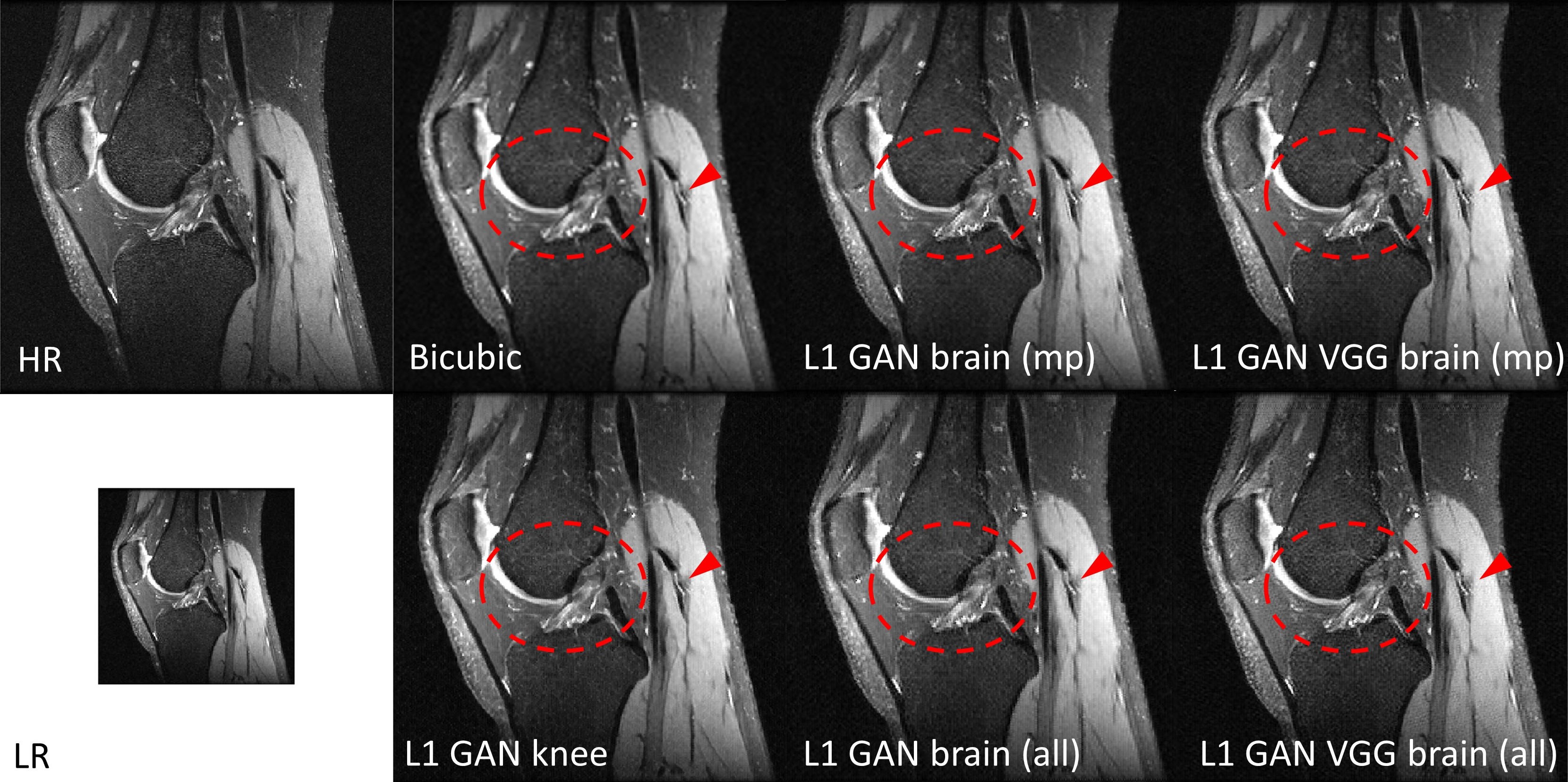
Impact of Loss Functions and Training DatasetsFigure 2 shows the SR results using the same RESNET based SRGAN but with different loss functions and training datasets in knee imaging. All DL based SR images outperformed the bicubic interpolation in terms of sharp boundary restoration (red circles and arrows). With L1+adversarial losses, the SR networks trained with high SNR MPRAGE brain images / all brain images may cause slightly blurring edges in comparison to the SR reference results using a SR network trained on this knee dataset. By adding perceptual VGG loss, the SR network trained from brain images can perform equivalently well as the reference. In addition, adding more brain images does not provide such amount of SR improvement. Similar results were also observed with the MSRES2NET based SRGAN in figure 3.
Impact of Network Architectures and Training Datasets
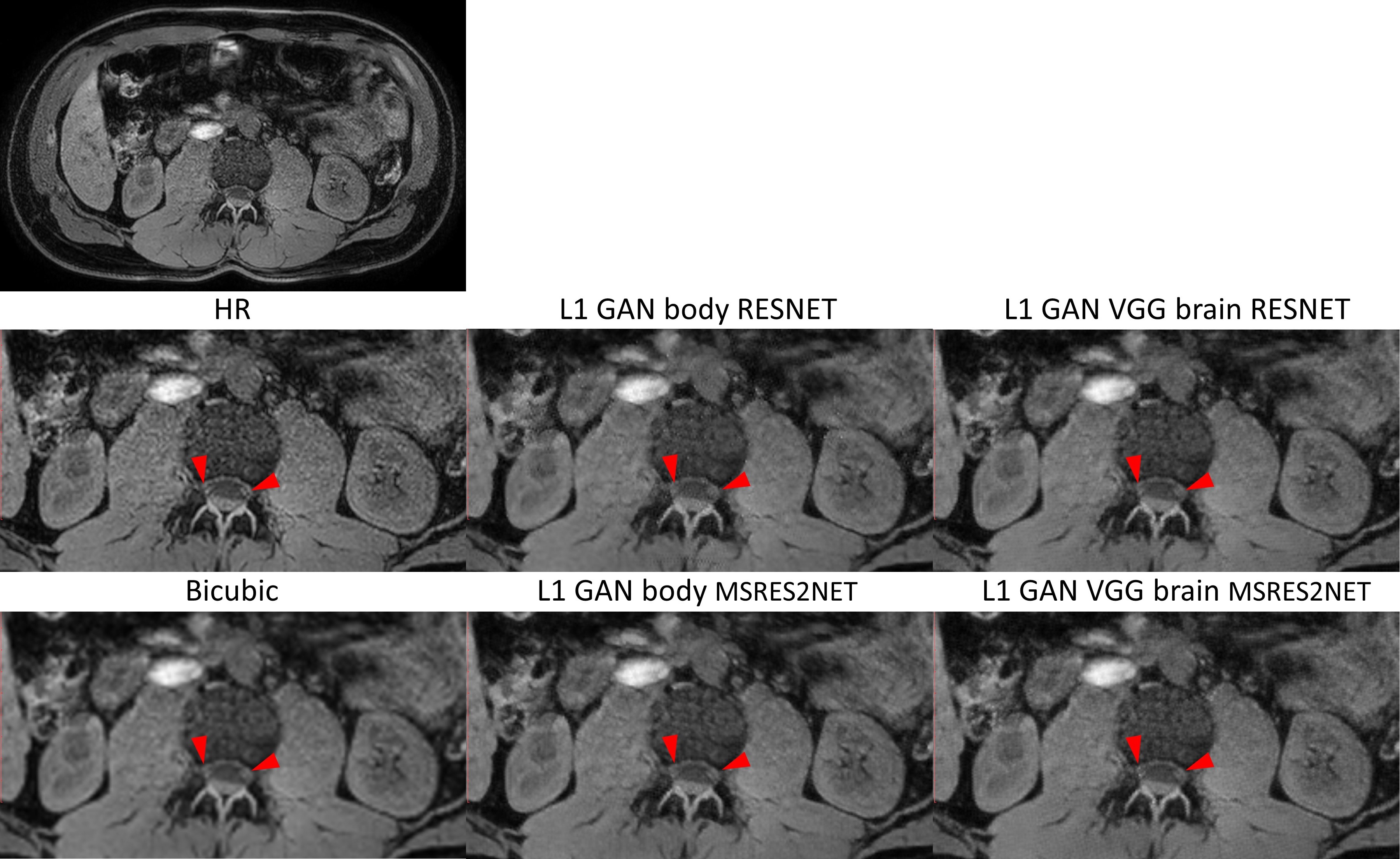
For the same network structure, figure 4 shows that SR network trained from brain datasets using L1+adversarial+VGG losses can perform equally well in body application compared to the reference SR network trained on this body data. In addition, MSRES2NET shows less blurring SR images (red arrows) and less artifacts in comparison to the RESNET structure, especially when training with the lower SNR/quality body dataset.
Discussion and Conclusion
Our preliminary results indicate that 1) the perceptual VGG loss can be a critical factor to improve the generalization performance of SR network in different applications; 2) the multi-scale network architecture can stabilize the SR results particularly when the training set has relatively low quality. In addition, the SR improvement from increased data diversity can be saturated, implying that a single SR network trained with limited data may generalize well for other different MR applications. Our current results were evaluated only based on side-by-side qualitative visual observation. More quantitative measurements of image sharpness and quality scores will be performed for statistical comparison.Acknowledgements
We would like to acknowledge the contributors of mridata.org for sharing the fully sampled 3D knee database.References
1. Anwar S, Khan S, Barnes N. A deep journey into super-resolution: A survey. ACM Computing Surveys. 2020;53(3), Article 60.
2. Chen Y, Shi F, Christodoulou AG, Xie Y, Zhou Z, Li D. Efficient and accurate MRI super-resolution using a generative adversarial network and 3D multi-level densely connected network. MICCAI 2018, pp 91-99.
3. Steeden J, Quail M, Gotschy A, Hauptmann A, Jones R, Muthurangu V. Rapid Whole-Heart CMR with Single Volume Super-Resolution. ISMRM 2020, p0769.
4. Ledig C, Theis L, Huszar F, Caballero J, Cunningham A, Acosta A, et al. Photo-realistic single image super-resolution using a generative adversarial network. CVPR 2017, pp. 4681-4690.
5. Yamanaka J, Kuwashima S, Kurita T. Fast and accurate image super resolution by deep CNN with skip connection and network in network. ICNIP 2017, pp. 217-225.
6. Gao S, Cheng M, Zhao K, Zhang X, Yang M, Torr P. Res2net: A new multi-scale backbone architecture. IEEE PAMI 2019.
7. Brock A, Donahue J, Simonyan K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. ICLR 2019.
8. Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR 2015.
9. Stucht D, Danishad K, Schulze P, Godenschweger F, Zaitsev M, Speck O. Highest Resolution In Vivo Human Brain MRI Using Prospective Motion Correction. PLoS One. 2015;10(7):e0133921.
Figures