1754
Deep, Deep Learning with BART
Moritz Blumenthal1 and Martin Uecker1,2,3,4
1Institute for Diagnostic and Interventional Radiology, University Medical Center Göttingen, Göttingen, Germany, 2DZHK (German Centre for Cardiovascular Research), Göttingen, Germany, 3Campus Institute Data Science (CIDAS), University of Göttingen, Göttingen, Germany, 4Cluster of Excellence “Multiscale Bioimaging: from Molecular Machines to Networks of Excitable Cells” (MBExC), University of Göttingen, Göttingen, Germany
1Institute for Diagnostic and Interventional Radiology, University Medical Center Göttingen, Göttingen, Germany, 2DZHK (German Centre for Cardiovascular Research), Göttingen, Germany, 3Campus Institute Data Science (CIDAS), University of Göttingen, Göttingen, Germany, 4Cluster of Excellence “Multiscale Bioimaging: from Molecular Machines to Networks of Excitable Cells” (MBExC), University of Göttingen, Göttingen, Germany
Synopsis
Deep learning offers powerful tools for enhancing image quality and acquisition speed of MR images. Standard frameworks such as TensorFlow and PyTorch provide simple access to deep learning methods. However, they lack MRI specific operations and make reproducible research and code reuse more difficult due to fast changing APIs and complicated dependencies. By integrating deep learning into the MRI reconstruction toolbox BART, we have created a reliable framework combining state-of-the-art MRI reconstruction methods with neural networks. For demonstration, we reimplemented the Variational Network and MoDL. Both implementations achieve similar performance as implementations using TensorFlow.
Introduction
In recent years, machine learning and especially neural networks have become an integral part of research on MRI image reconstruction and quantitative MRI, in large part due to public availability of deep-learning frameworks such as TensorFlow or PyTorch. Recent methods combine state-of-the-art deep learning methods for image processing with MRI specific modules for data-consistency. The rapid growth of the field has also its drawbacks: Complex dependencies on different frameworks make it difficult to maintain a reliable code base, and it is often challenging to reproduce results produced only a few years ago. Instead of integrating MRI modules into standard deep-learning frameworks, we went the opposite way and integrated deep-learning capabilities into BART1. BART is an open-source framework providing efficient implementations of various calibration and reconstruction algorithms for parallel imaging, compressed sensing and model-based quantitative reconstruction. Written in C and only depending on a few external libraries, BART is a solid basis for future research that combines deep-learning and classical image reconstruction. As an example, we re-implemented two state-of-the-art neural networks for MRI reconstruction, namely the Variational Network2 (VarNet) and MoDL3.Implementation of Neural Networks in BART
Basically, training a neural network corresponds to fitting a non-linear function $$$f(\mathbf{x};\mathbf{\theta})$$$ to a training dataset $$$(\mathbf{x}_i,\mathbf{y}_i)$$$ of paired inputs $$$\mathbf{x}_i$$$ and target outputs $$$\mathbf{y}_i$$$, i.e. the weights $$$\mathbf{\theta}$$$ are optimized to minimize the loss function $$$L$$$:$$\mathbf{\theta}^*= \text{argmin}_{\mathbf{\theta}}\left[\sum_iL\left(f(\mathbf{x}_i;\mathbf{\theta}), \mathbf{y}_i\right)\right].$$ Usually, incremental gradient methods such as stochastic gradient descent (SGD) or the Adam4 algorithm are used for fitting. From a technical perspective, three basic modules, all of them integrating seamlessly into BART (c.f. Fig. 1), are required to train a neural network:- efficient implementations of numeric operations allowing training in reasonable time;
- a framework for composing $$$f(\mathbf{x};\mathbf{\theta})$$$ of small building blocks and computing its gradients;
- implementations of training algorithms.
Non-linear operators (nlop) and automatic differentiation have been included in BART for non-linear and model-based reconstruction. An nlop consists of a forward operator $$$F$$$ and linear operators $$$\mathrm{D}_iF_o$$$ modeling the derivative and its adjoint for each pair of inputs $$$i$$$ and outputs $$$o$$$ of $$$F$$$: $$\begin{aligned}F:\mathbb{C}^{N_1+\cdots+N_I} & \to\mathbb{C}^{M_1+\dots+M_O}\\\left[{\mathbf{x}_1,\dots,\mathbf{x}_I}\right] & \mapsto\left[F_1(\mathbf{x}_1,\dots,\mathbf{x}_I), \dots, F_O(\mathbf{x}_1,\dots,\mathbf{x}_I)\right]\\\\{\left.\mathrm{D}_i{F_o}\right|}_{[{\mathbf{x}_1,\dots,\mathbf{x}_I}]}:\mathbb{C}^{N_i} & \to\mathbb{C}^{M_o}\\\mathrm{d}\mathbf{x}_i & \mapsto \left(\left.{\frac{\partial F_o}{\partial\mathbf{x}_i}}\right|_{[{\mathbf{x}_1,\dots,\mathbf{x}_I}]}\right)\mathrm{d}\mathbf{x}_i\\{\left.\mathrm{D}_i{F_o}^H\right|}_{[{\mathbf{x}_1,\dots,\mathbf{x}_I}]}:\mathbb{C}^{M_o} & \to\mathbb{C}^{N_i}\\\mathrm{d}\mathbf{y}_o & \mapsto \left(\left.{\frac{\partial F_o}{\partial\mathbf{x}_i}}\right|_{[{\mathbf{x}_1,\dots,\mathbf{x}_I}]}\right)^H\mathrm{d}\mathbf{y}_o\;.\end{aligned}\;.$$ The derivatives are always evaluated at the last inputs of $$$F$$$. Note that nlops generally do not distinguish between inputs corresponding to weights or input data. Sophisticated nlops, such as neural networks, can be composed of basic nlops by chaining or combining them and linking or duplicating their arguments as depicted in Fig. 2. The derivatives of the composed nlops are constructed automatically.
We implemented several basic nlops often used to construct neural networks such as convolutions, ReLUs and batch-normalization. Reflecting the complex nature of MRI-data, nlops act on complex numbers. To integrate data-consistency in MRI-reconstruction networks, we implemented nlops modeling a gradient update $$$A^H(A\mathbf{x} - \mathbf{k})$$$ and the regularized inversion of the normal operator $$$\left(A^HA + \lambda\right)^{-1}\mathbf{x}$$$. Here, $$$A=\mathcal{PFC}$$$ is the composition of the multiplication with $$$\mathcal{C}$$$oil sensitivity maps, the $$$\mathcal{F}$$$ourier transform and the projection to the sampling $$$\mathcal{P}$$$attern. As proposed in [3], we use the conjugate gradient algorithm to compute $$$\left(A^HA + \lambda\right)^{-1}\mathbf{x}$$$ and its derivatives with respect to $$$\mathbf{x}$$$ and $$$\lambda$$$ - already demonstrating the benefit of being able to use implementations of traditional reconstruction methods.
The training algorithms Adam4, iPALM5 and SGD have been integrated in BART's library for iterative algorithms. For deep-learning specific functions, such as initialization of weights, a new library named nn has been added which also supports convenient handling of nlops.
Results
Our implementations of the respective networks can be trained using the BART command line tools:$$\texttt{bart}\:\:\texttt{[nnvn | nnmodl]}\:\:\texttt{--initialize}\:\:\texttt{--train}\:\:\texttt{--gpu}\:\:\texttt{<kspace>}\:\:\texttt{<coils>}\:\:\texttt{<pattern>}\:\:\texttt{<weights>}\:\:\texttt{<reference>}\:\:.$$ For reconstruction, the trained weights can be applied using $$\texttt{bart}\:\:\texttt{[nnvn | nnmodl]}\:\:\texttt{--apply}\:\:\texttt{<kspace>}\:\:\texttt{<coils> <pattern>}\:\:\texttt{<weights>}\:\:\texttt{<reconstruction>}\:\:.$$ In Fig. 3, we compare the training time of our implementation and the ones using TensorFlow on different GPUs. MoDL used TensorFlow 1.15 and VarNet used a customized version TensorFlow-ICG6 compiled against CUDA8 and cuDNN7. We achieve similar performance. The TensorFlow implementation of MoDL on the Tesla V100 performs poorly for reasons unknown to us. In Fig. 4, we show reconstructions using the TensorFlow and BART implementations of MoDL and VarNet. Both methods provide equivalent results.Conclusion
By integrating deep learning into BART, we have created a reliable framework combining state-of-the-art MRI reconstruction methods with neural networks. For MoDL and VarNet, we achieve similar performance as TensorFlow. We plan to explore new deep learning methods based on the BART framework. Interested groups are welcome to contribute.Acknowledgements
We acknowledge funding by the "Niedersächsisches Vorab" initiative of the Volkswagen Foundation. Funded in part by NIH under grant U24EB029240. Supported by the DZHK (German Centre for Cardiovascular Research). We gratefully acknowledge the support of the NVIDIA Corporation with the donation of one NVIDIA TITAN Xp GPU for this research.References
- M. Uecker et al., "BART Toolbox for Computational Magnetic Resonance Imaging", Zenodo, DOI: 10.5281/zenodo.592960
- K. Hammernik et al., “Learning a variational network for reconstruction of accelerated MRI data”, Magnetic Resonance in Medicine, vol. 79, no. 6, pp. 3055–3071, 2018
- H. K. Aggarwal, M. P. Mani, and M. Jacob, “MoDL: Model-Based Deep Learning Architecture for Inverse Problems”, IEEE Transactions on Medical Imaging, vol. 38, no. 2, pp. 394–405, 2019
- T. Pock and S. Sabach, “Inertial Proximal Alternating Linearized Minimization (iPALM) for Nonconvex and Nonsmooth Problems”, SIAM Journal on Imaging Sciences, vol. 9, no. 4, pp. 1756–1787, 2016
- D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization”, 2014, arXiv:1412.6980
- Tensorflow-ICG: https://github.com/VLOGroup/tensorflow-icg (commit: a11ad61)
- MoDL implementation: https://github.com/hkaggarwal/modl (commit: 428ef84)
- Variational Network implementation: https://github.com/VLOGroup/mri-variationalnetwork (commit: 4b6855f)
Figures
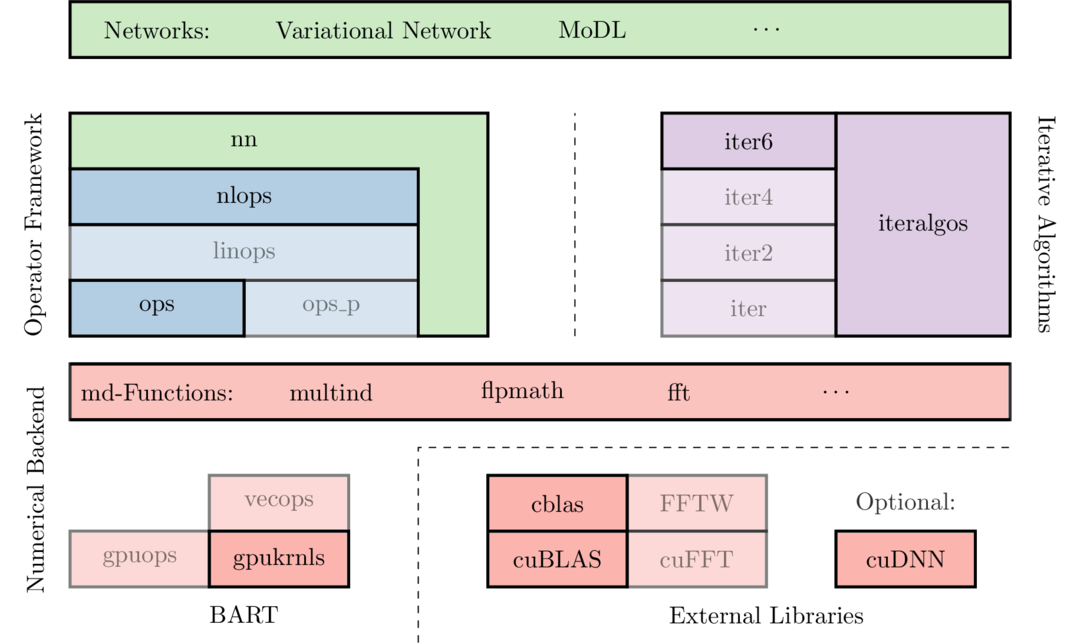
Figure 1: Basic structure of the BART-libraries used for deep learning: Networks are implemented as nlops supporting automatic differentiation. The nn-library provides deep-learning specific components such as initializers. Training algorithms have been integrated BART's library for iterative algorithms. MD-functions act as a flexible, unified interface to the numerical backend. We added many deep-learning specific nlops such as convolutions using efficient numerical implementations. Solid blocks represent major changes allowing deep learning.
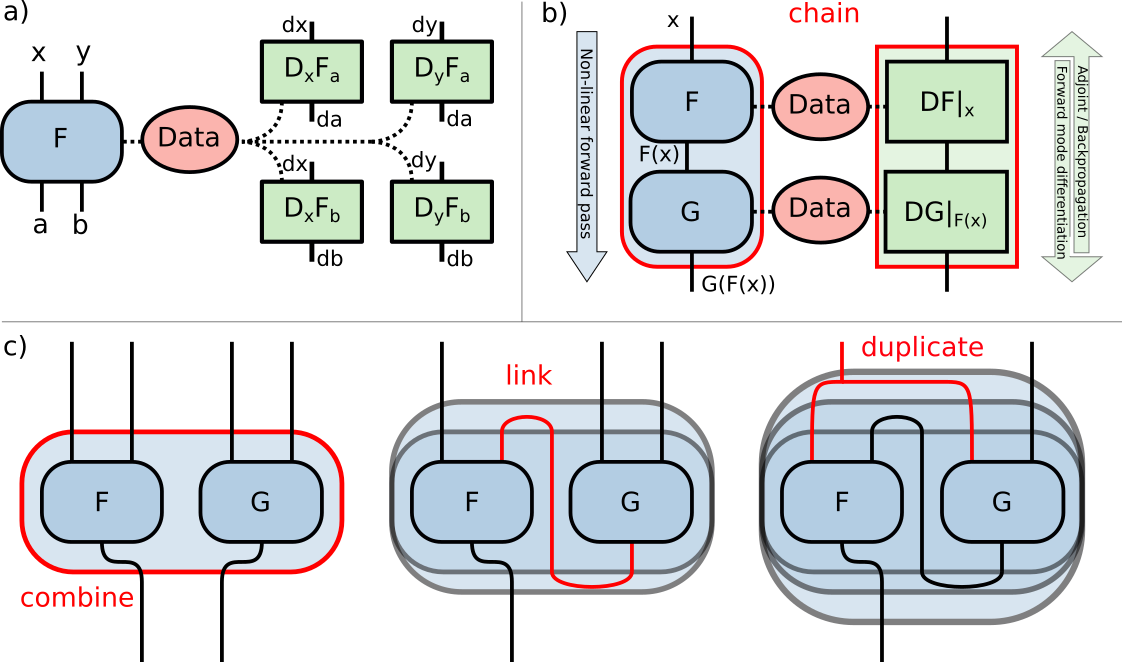
Figure 2: Nlops and automatic differentiation. a) A basic nlop modeled by the operator $$$F$$$ and derivatives $$$\mathrm{D}F$$$. When applied, $$$F$$$ stores data internally such that the $$$\mathrm{D}F$$$s are evaluated at $$$F$$$'s last inputs. b) Chaining two nlops $$$F$$$ and $$$G$$$ automatically chains their derivatives obeying the chain rule. The adjoint of the derivative can be used to compute the gradient by backpropagation. c) Composition of a residual structure $$$F(\mathbf{x}, G(\mathbf{x},\mathbf{y}))$$$ by combine, link and duplicate.
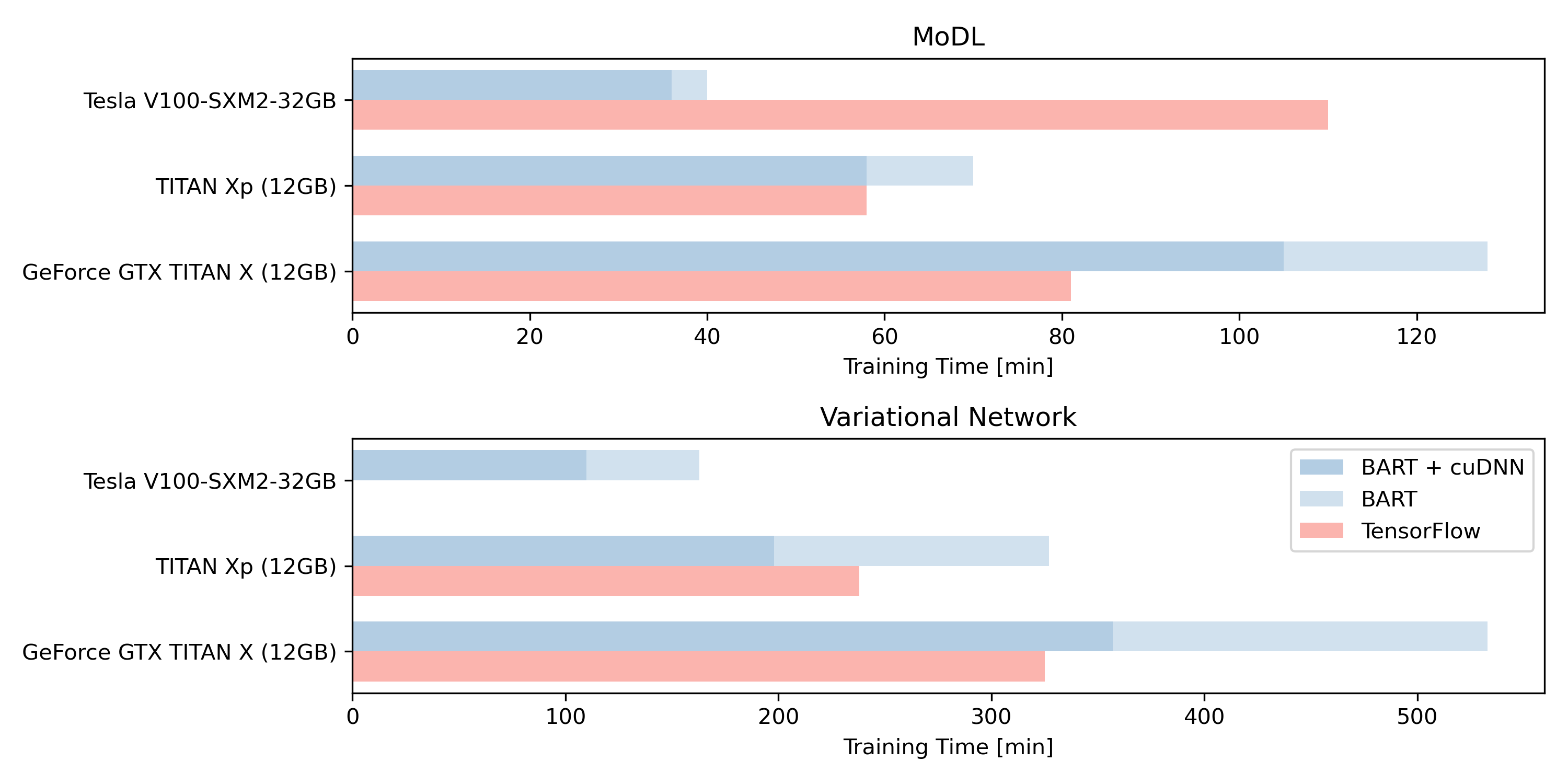
Figure 3: Training time for the BART and TensorFlow7,8 implementations of MoDL and VarNet on different GPUs. We trained MoDL with $$$K=5$$$ iterations for 50 epochs with 64 real (TensorFlow) / 32 complex (BART) convolution channels. VarNet was trained for 30 epochs on 300 slices of the coronal_pd_fs dataset. Unstated parameters are set as in the published respective TensorFlow implementations. VarNet could not be trained on the Tesla V100 as CUDA8 was not installed on this machine.
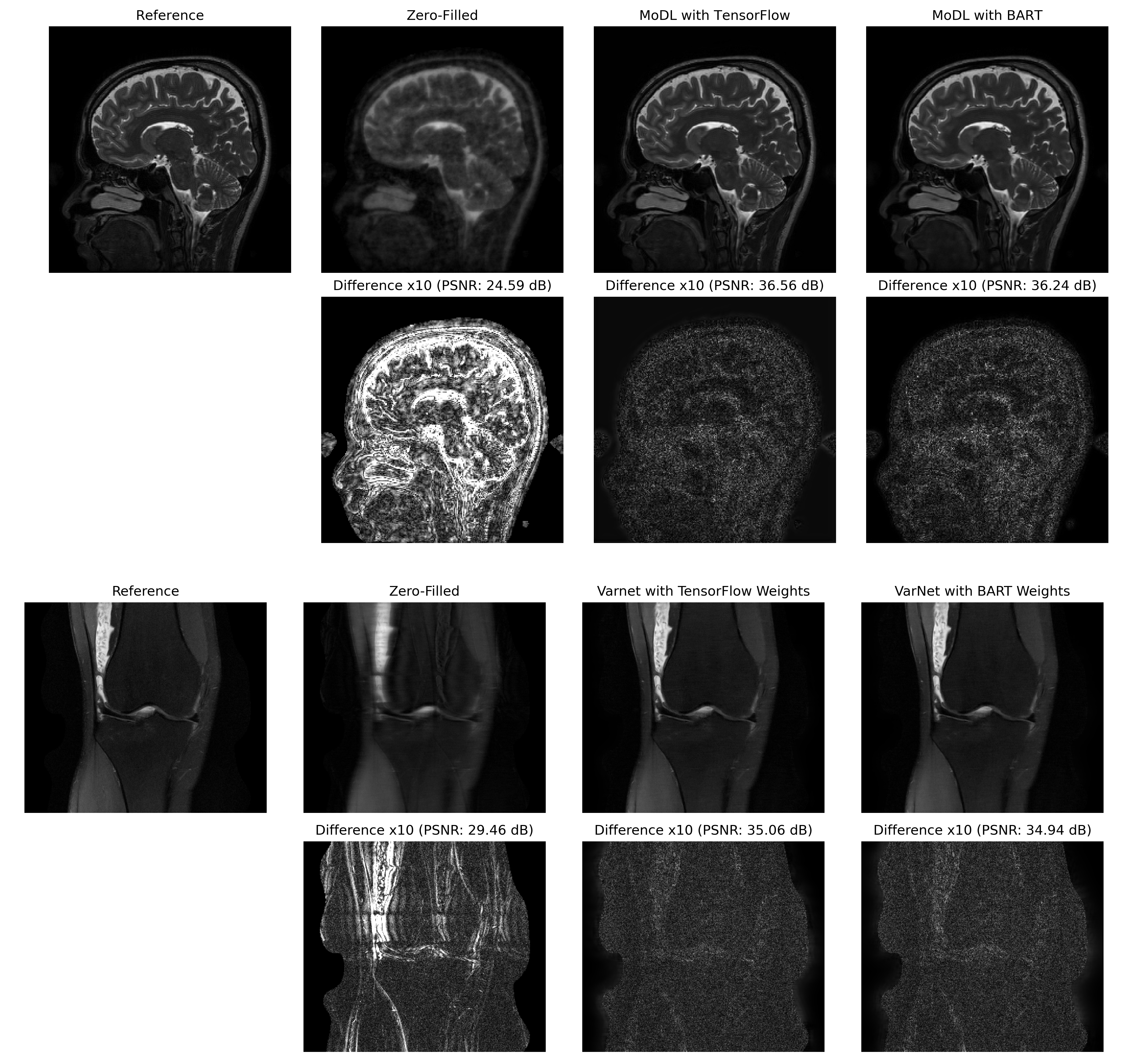
Figure 4: Example reconstructions using TensorFlow7,8 and BART implementations of MoDL and VarNet. In the case "VarNet with TensorFlow Weights", TensorFlow was only used for training, and the reconstruction was performed with BART using the exported weights. The BART reconstructions are completely independent of TensorFlow.