1558
GPU Accelerated Grouped Magnetic Resonance Fingerprinting using Clustering Techniques
Abdul Moiz Hassan1, Rana Muhammad Saad1, Irfan Ullah1, and Hammad Omer1
1Medical Image Processing Research Group (MIPRG), Department of Electrical and Computer Engineering, COMSATS University, Islamabad, Pakistan
1Medical Image Processing Research Group (MIPRG), Department of Electrical and Computer Engineering, COMSATS University, Islamabad, Pakistan
Synopsis
Magnetic Resonance Fingerprinting (MRF) has a limited use in clinics due to a considerable reconstruction time and large memory requirements. This paper utilizes clustering in MRF Dictionary to reduce the reconstruction time and memory requirements for MRF image reconstruction. The proposed method is further optimized for parallel processing to significantly reduce the pattern matching time with minimum memory usage by incorporating a multi-core GPU framework. As an outcome, the MRF reconstruction time is accelerated, keeping the SNR of the resulting images in a clinically acceptable range.
Purpose
The purpose of this research is to overcome the computational as well as memory requirements of Magnetic Resonance Fingerprinting (MRF) reconstruction. MRF is a new approach to quantitative MR imaging that allows simultaneous measurement of multiple tissue properties in a single, time-efficient acquisition. In MRF, tissue’s unique signal evolution is correlated against the pre-simulated MRF dictionary using a pattern recognition algorithm [1]. The best signal match extracts the tissue property maps of interest. Even though, scan time is much reduced in MRF than conventional MRI but still it takes considerable computation time and system memory in post-processing (due to an increase in computational complexity) [1]. In this research work, we have modified the MRF dictionary in such a way that similar signals have formed common groups. Several clustering methods are tested to create the best group size reflecting maximum signal-to-noise ratio (SNR) in the resulting image. The post-processing (pattern matching) is further accelerated by utilizing a GPU based parallel processing framework.Method
Accurate grouping of similar signals is essential for true property maps in MRF. For grouping, we exploit the inherent clustering properties of the Bloch simulated MRF dictionary. Tissues that produce similar time courses are grouped together by using a clustering algorithm and a label (mean signal) is assigned to each group. The aim of this paper is to segregate the groups with similar properties and assign different clusters. Most widely used clustering techniques such as k-mean [2], Hierarchical [3], Fuzzy c-means [4], Mean-Shift [5] and k-medoids [6] have been used in this paper to test for the best SNR of T1/T2 maps. Once the grouping is done, sorted dictionary is created which has similar signal groups piled together. Instead of iteratively correlating the acquired signal with the whole dictionary, the signal is first correlated with the mean representative of each group. The group with the maximum correlation is selected for further pattern matching. In the next stage, this acquired signal is correlated with each signal present in the selected group. As soon as the acquired signal gets matched with a signal present in the dictionary, the pre-determined T1 and T2 pixel values are assigned against that pixel location. The dataset used in our experiments is the 192x192 signal evaluations, acquired from 1.5 T Espree Siemens Healthcare scanner with a standard 32-channel head receiver coil [7]. The FOV is 300 mm×300 mm with a thickness of 5 mm. A Bloch simulated compact MRF dictionary of 5791 signal evaluations is used [7]. The GPU used is NVIDIA TITAN Xp with a memory of 12 GB.Results
Clustering was tested on different number of groups. The most optimized T1/T2 SNR values with their respective number of groups and clustering techniques are given in Table 1.Summarized results from Table-1 show that the proposed method is relatively four times faster than conventional MRF. And if we use the GPU based parallel framework (developed as part of this research) for pattern matching then this method is approximately 1035 times faster than conventional MRF (within mentioned SNR in Table-1) in our experiments.
Conclusion
Clustering of dictionary is a one-time pre-processing for a selected pulse sequence. The number of groups in which dictionary splits is a tradeoff between the time taken for pattern matching and good SNR. Higher number of groups will take less computation time, but SNR will be low (not in clinically acceptable range). On average, four groups preserve all the vital information in our experiments. Hierarchical (Spearman) clustering results are more consistent than other clustering algorithms since it uses Spearman correlation [3]. Even though the SNR in Fuzzy c-means clustering is higher and pattern matching time is lower than Hierarchical clustering, but its results will change whenever we redo the clustering. Clustering is also helpful for large MRF dictionary memory compression as it helps in loading it on GPU.Acknowledgements
No acknowledgement found.References
[1] Dan et al. Nature 495, 187–192 (2013). [2] Wang et al. IEEE, pp. 44-46 (2011). [3] Murtagh et al. WIREs Data Mining Knowl Discov, 2: 86-97 (2012). [4] Bezdek et al. Computers & Geosciences, pp. 191-203 (1984). [5] Cheng et al. IEEE, pp. 790-799 (1995). [6] Cao et al. ICCAE, pp. 132-135 (2010). [7] I. Ullah et al. U.S Patents, US20170371015A1 (2017).Figures
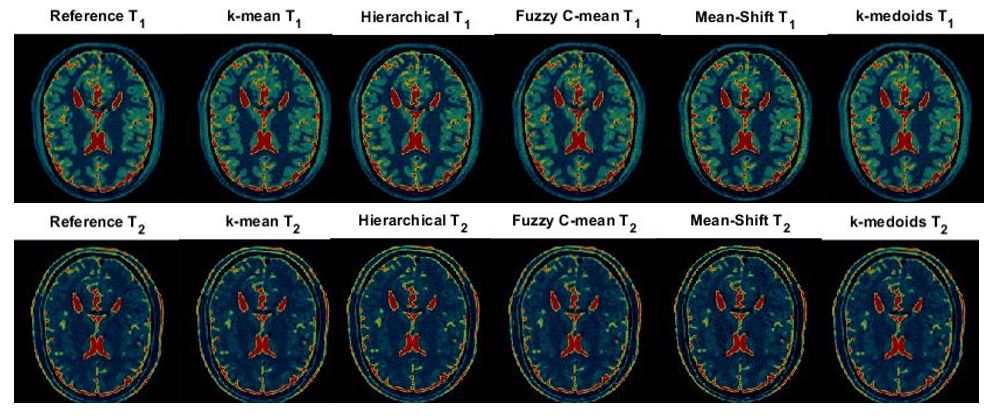
Figure-1:
Reconstructed T1/T2 Property Maps from the Reference MRF Method and Clustering
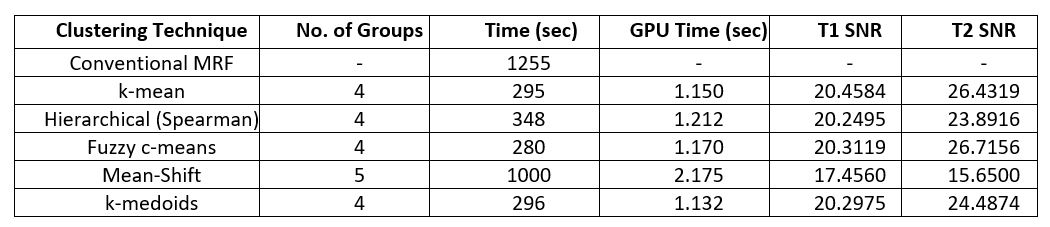
Table-1:
Results from the conventional MRF and the proposed method (i.e. MRF with
different clustering methods)