1357
Deep Learning-Based Rigid-Body Motion Correction in MRI using Multichannel Data
Miriam Hewlett1,2, Ivailo E Petrov2, and Maria Drangova1,2
1Medical Biophysics, Western University, London, ON, Canada, 2Robarts Research Institute, London, ON, Canada
1Medical Biophysics, Western University, London, ON, Canada, 2Robarts Research Institute, London, ON, Canada
Synopsis
Motion artefacts remain a common problem in MRI. Deep learning presents a solution for motion correction requiring no modifications to image acquisition. This work investigates incorporating multichannel MRI data for motion correction using a conditional generative adversarial network (cGAN). Correcting for motion artefacts in the single-channel images prior to coil combination improved performance compared to motion correction on coil-combined images. The model trained for simultaneous motion correction of multichannel data produced the worst result, likely a result of its limited modelling capacity (reduced due to memory limitations).
Introduction
Much research has been done investigating methods for motion correction in MRI.1,2 Despite these efforts, motion correction techniques are not used in a wide variety of applications – a result of limitations in their clinical implementation or difficulties in generalising their implementation to the wide variety of MR sequences that exist. As a result, 20% of patients require at least one scan be repeated due to the presence of motion artefacts.3 Over the past 5 years, deep learning using convolutional neural networks (CNNs) has been investigated for motion correction.4-7 However, these studies have been limited to healthy subjects and models trained on images acquired using a single scanner and contrast mechanism. None have performed motion correction making use of multichannel image data. This work presents a conditional generative adversarial network (cGAN) trained for motion correction using images from the NYU fastMRI dataset – a multi-centre, multi-contrast dataset containing the multichannel data from nearly 6000 brain MRIs including a variety of neurological pathologies.8 We investigate the change in performance when including multichannel data for motion correction.Methods
Motion Simulation: All models were trained and evaluated on simulated rigid motion artefacts, allowing for comparison with ground truth results. Simulated motion-corrupted images were generated using randomly generated motion traces applied in image space on a channel-by-channel basis (Figure 1).Model Architecture: The cGAN architecture shown in Figure 2 was used in this work. Each network is composed of a generator (3D U-Net), taking a motion corrupt 3D image and producing its motion free counterpart, and a discriminator (3D CNN classifier), identifying whether a given image is a ground truth or generated image.
Incorporation of Multichannel Data: To investigate whether incorporating multichannel data in the motion correction task improved performance, three cGANs were trained. The first performed motion correction on the coil-combined images. The second performed motion correction on the single channel images prior to coil combination, with no knowledge of the additional channel data from the same image. The third performed simultaneous motion correction of the multichannel data. In this case the generator was modified to have 4D inputs and outputs (3D image + channel dimension). This increased input size resulted in memory constraints during training, requiring a reduction in the number of convolutional filters in the model (and thus the number of channels at each layer), limiting its modelling capacity.
Training and Evaluation: All data from a single centre within the fastMRI dataset was set aside as an independent test set (147 3D images). The remaining images were divided into training (3654), validation (895), and testing sets (1103); no data augmentation was applied. During training, the generator was penalised for discrepancies between the generated and known ground truth images (quantified using mean absolute error, MAE), as well as failing to fool the discriminator into identifying the generated image as a ground truth image (quantified with binary cross-entropy). Likewise, the discriminator was penalised for failing to correctly identify an image as a generated or ground truth image. For all models training was performed with a batch size of 4; the Adam optimiser was used with a learning rate of 0.00005. Training was performed using a NVIDIA T4 GPU (16 GB), 32 GB RAM, and was stopped the generator loss (MAE term) ceased to improve. Total training time was model dependent (ranging from 2 days for the coil-combined model to 2 weeks for the single-channel model). Model performance was evaluated using MAE as well as structural similarity index (SSIM). Statistical tests were performed using repeated measures ANOVA. The best performing network was applied for motion correction in an image containing true motion artefacts
Results and Discussion
Motion correction with the single-channel model provided a significant (p < 0.05) improvement over the combined image model (Figure 3). Motion correction with the multichannel model provided a significant improvement compared to the uncorrected images but performed worse than the other approaches. This is likely a result of its limited modelling capacity (reduced number of convolutional filters). Similar results were observed for the independent test site, confirming the generalisability of model performance.Figure 4 shows example images for each model and contrast. Both the combined and single-channel models reduced the visual appearance of motion artefacts, but residual blurring was present in the images. While the results of motion correction with the single-channel model were significantly better in terms of MAE and SSIM, it remains to be determined whether these improvements are clinically significant. Images corrected with the multichannel model appear to have little improvement in image quality compared to their motion corrupt counterparts. Figure 5 shows the result of applying the single-channel model for motion correction in an image containing true motion artefacts. The appearance of motion artefacts is reduced; some residual ringing is present.
Conclusion
Deep learning approaches to motion correction are relatively simple to apply in practice since they are purely retrospective techniques requiring no modifications to image acquisition. When trained with large, diverse training datasets, these networks are generalisable to images acquired at unseen centres. If the multichannel data is available, motion correction prior to coil combination may provide a slight improvement in performance for certain applications.Acknowledgements
This work was performed with computing resources made available through Compute Canada. The researchers involved in this study receive support from the Natural Sciences and Engineering Research Council of Canada (NSERC).References
- Frost R, Wighton P, Karahanogli FI, et al. Markerless high‐frequency prospective motion correction for neuroanatomical MRI. Magn Res Med. 2019;82:126-144.
- Simegn GL, Van der Kouwe AJ, Robertson FC, et al. Real-time simultaneous shim and motion measurement and correction in glycoCEST MRI using double columetric navigators (DvNavs). Magn Res Med. 2019:81:2600-2613.
- Andre JB, Bresnahan BW, Mossa-Basha M, et al. Toward Quantifying the Prevalence, Severity, and Cost Associated With Patient Motion During Clinical MR Examinations. J Am Coll Radiol. 2015;12:689-695.
- Johnson PM, and Drangova M. Conditional generative adversarial network for 3D rigid-body motion correction in MRI. Magn Res Med. 2019;82:901-910.
- Haskell MW, Cauley SF, Bilgic B, et al. Network Accelerated Motion Estimation and Reduction (NAMER): Convolutional neural network guided retrospective motion correction using a separable motion model. Magn Res Med. 2019;82:1452-1461.
- Kustner T, Armanious K, Yang J, et al. Retrospective correction of motion-affected MR images using deep learning frameworks. Magn Res Med. 2019;82:1527-1540.
- Pawar K, Chen Z, Shah NJ, et al. Suppressing motion artefacts in MRI using an Inception-ResNet network with motion simulation augmentation. NMR in Biomedicine. 2019;e4225.
- Zbontar J, Knoll F, Sriram A, et al. FastMRI: An Open Dataset and Benchmarks for Accelerated MRI. Arxiv. 2019:1811.08839.v2.
Figures
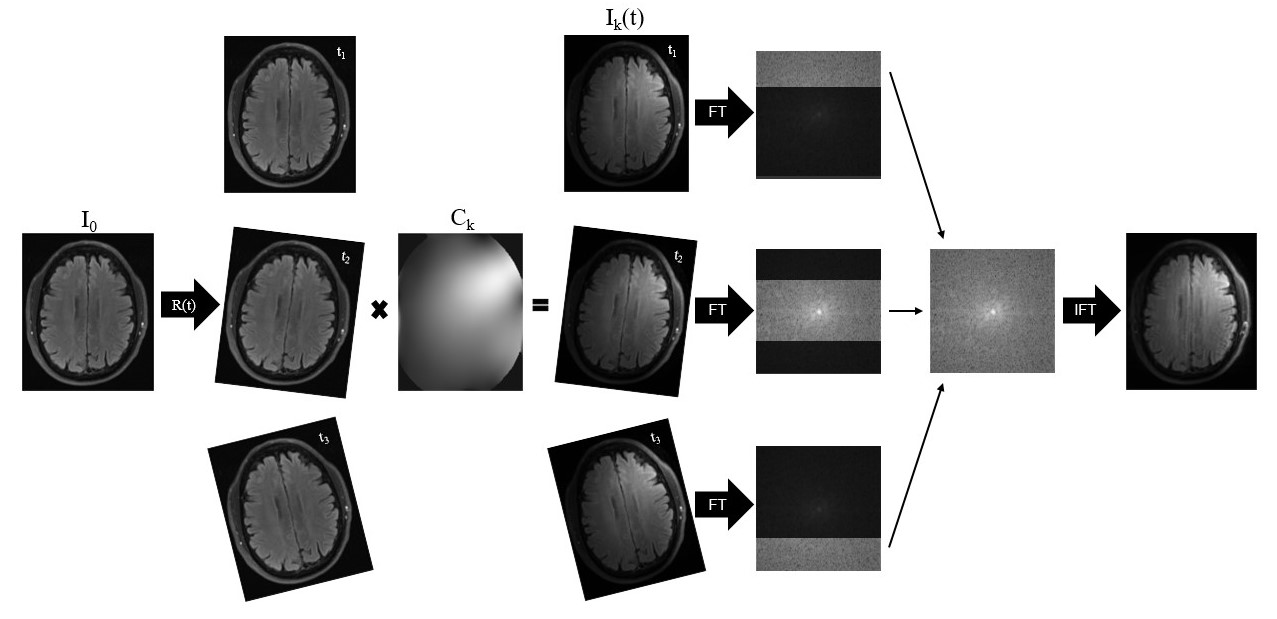
Figure 1. For each
position in the motion trace, translations and rotations were performed on the
combined image, I0, in image space. The channel specific image data for each
position, Ik(t), was generated by applying coil sensitivity maps, Ck, and
Fourier transformed to generate the corresponding k-space data. The k-space
data for the motion corrupted, single-channel image was generated by taking
k-space lines from the position corresponding to that time point during
acquisition. Cartesian acquisitions were assumed.
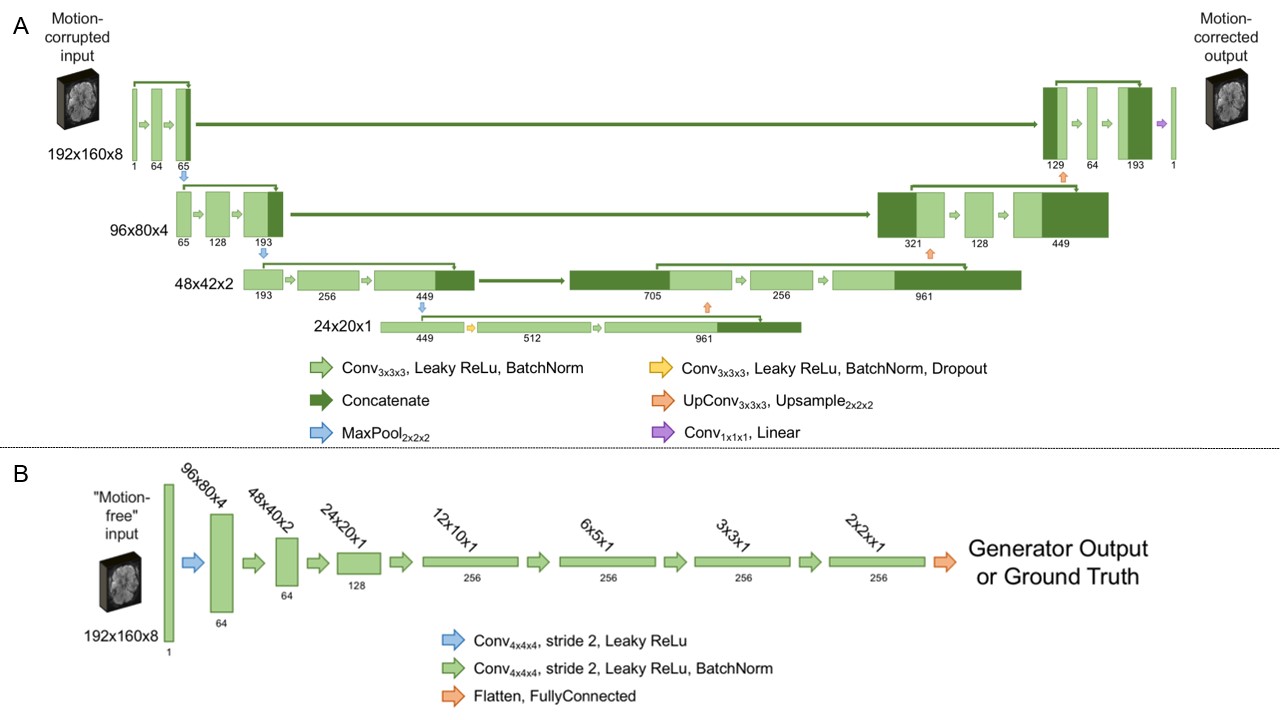
Figure 2. Model
architecture for the generator (A) and discriminator (B) making up the
conditional generative adversarial network used in this work. For the
generator, the resolution at each level of the U-Net is shown on the left. For
the discriminator, the resolution at each layer is given above the
corresponding output. In both cases, the number of channels at each layer is
indicated below the corresponding output.
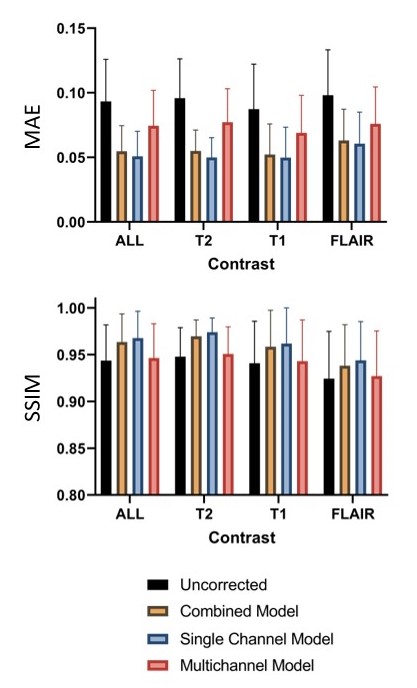
Figure 3. Mean absolute error (MAE, mean and standard deviation) and structural
similarity index (SSIM, mean and standard deviation) comparing the ground truth
results to the uncorrected images (black), as well as images corrected with the
combined (yellow), single-channel (blue), and multichannel (red) models. All
differences are significant (p < 0.05).
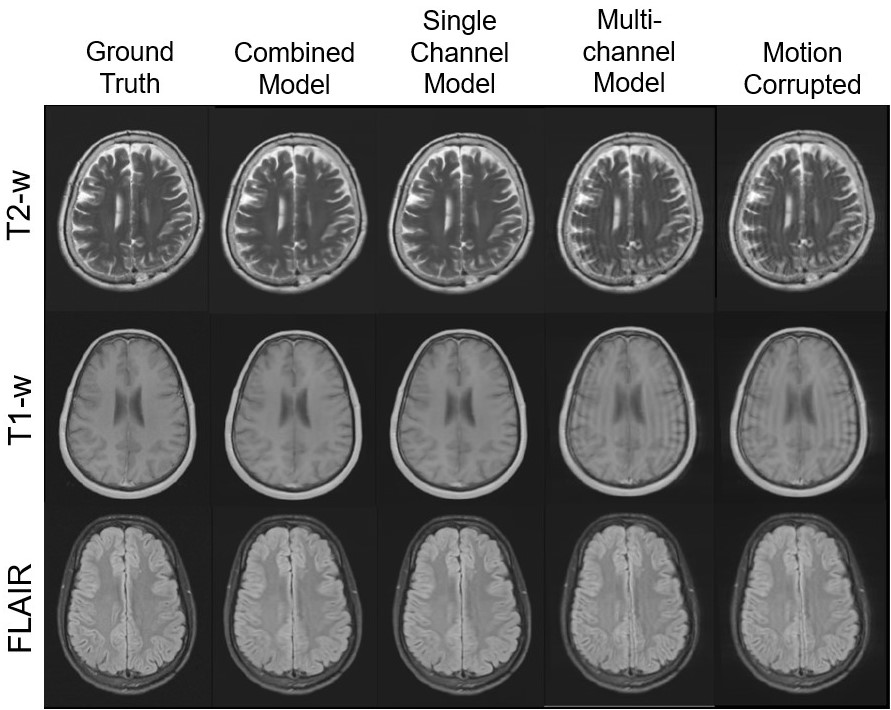
Figure 4. Example
images for each contrast; T2-weighted (top), T1-weighted (middle), and FLAIR
(bottom). On the left are the ground truth images, and on the right those
containing simulated motion artefacts. The centre three images are those
corrected with the combined, single-channel, and multichannel models (from left
to right).
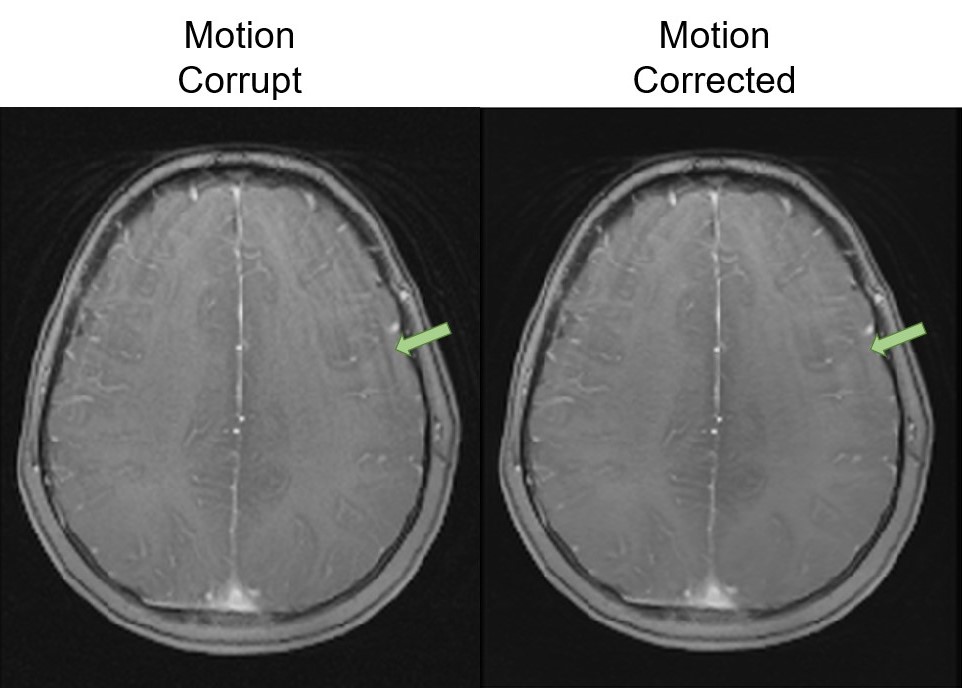
Figure 5. An
example of applying the single-channel cGAN for motion correction on an image
containing true motion artefacts.