1348
Deep Learning Based Super-resolution of Diffusion MRI Data1Center for Biomedical Imaging, Dept. of Radiology, New York University School of Medicine, NEW YORK, NY, United States
Synopsis
Deep-learning/machine-learning based super-resolution techniques have shown promises in improving the resolution of MRI without additional acquisition. In this study, we examined the capability of deep-learning based super-resolution using a newly developed network at resolutions from 0.2 mm to 0.025 mm. We also investigated whether the networks were able to enhance data acquired with a different contrast. Our results demonstrated that the enhancement of deep learning based super-resolution, although better than cubic interpolation, remained limited. In order to achieve the best performance, the network needs to be trained using data acquired at the target resolution and share similar contrasts.
Introduction
Diffusion MRI (dMRI) provides rich information on tissue microstructure and is uniquely sensitive to several neuropathology. The spatial resolution of dMRI, however, remains limited due to low SNR and length acquisition. Even with recent progress in hardware design and reconstruction techniques, high-resolution dMRI remains challenging. While conventional super-resolution imaging can improve resolution based on multiple shifted image acquisitions[1], the increased acquisition time may it impractical. Recently, deep-learning/machine-learning based super-resolution techniques have shown promises in improving the resolution of MRI without additional acquisition[2]. A recent report suggested that it can be applied to dMRI data, and the authors explored using the same method to further improve beyond the resolution of training dataset[3]. Previous reports on deep learning based super-resolution used high-resolution optical images from shared public database [4], such data are not available for dMRI. As a result, there is, however, a lack of study on the capability of the deep-learning-based approach for dMRI.Using 3D high-resolution optical imaging data, we examined the capability of deep-learning based super-resolution using a newly developed network at resolutions from 0.2 mm to 0.025 mm. We also investigated whether the networks were able to enhance data acquired with a different contrast.
Method
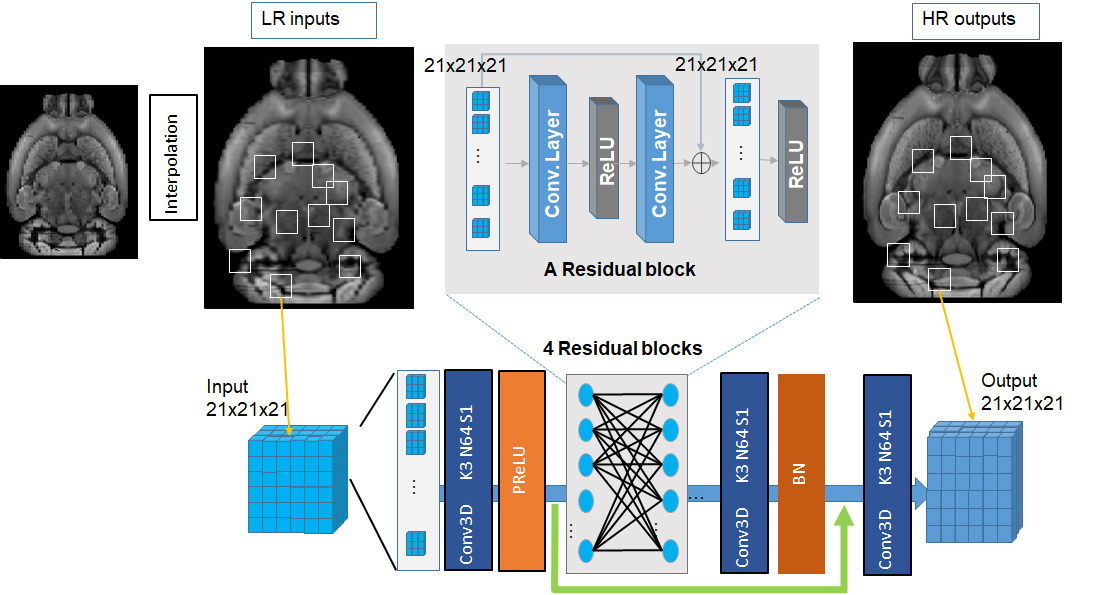
Super-resolution can be expressed by minimizing the following function [4,5]$$argmin_θ{\frac{1}{N} \sum_1^Nmse(G_θ(I_n^L ),I_n^H)}$$
Where G could be the ResNet with the numerous parameters θ to be trained from the training sample pairs $$$(I_n^L ,I_n^H)$$$. The ResNet architecture (Fig.1) is one derivative of the basic convolutional neural network (CNN). We used down-sampled 3D auto-fluorescence optical data (25 um to 2 mm) as training sets. For testing, we used optical data as well as post-mortem mouse brain T2 and diffusion MRI data at 200 um resolution with reference data at the 100 um resolution. We also tested our network on diffusion MRI data from human subjects (4 subjects 1344 gradient direction DWI volumes for training, 1 for testing, initially 2.5mm isotropic, down-sampled to 5mm isotropic, and network input/output size 61x79x58 [7]).
Results
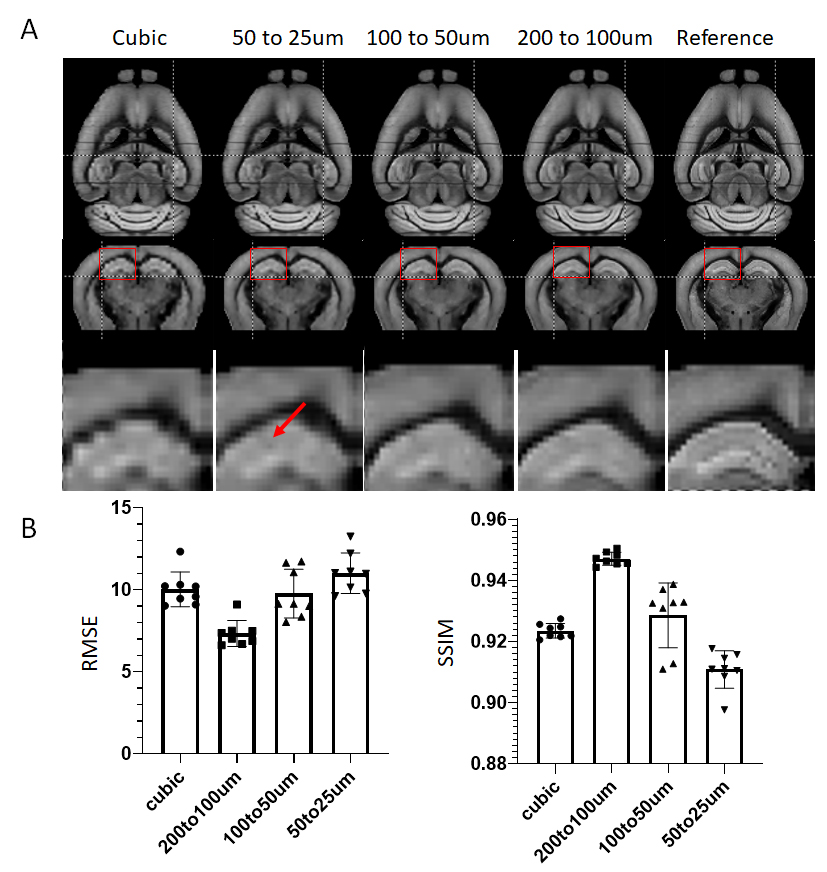
Previous reports on deep learning based super-resolution mainly used three architectures: naïve CNN, Deep ResNet, and GAN [4,5,6]. Initial tests suggested that the ResNet (Fig. 1) provided the best performance among the three (data not shown here).We trained our networks using data at 50 and 20 um resolution, 100 and 50 um resolution, and 200 and 100 um resolution and tested their performance on a separate set of data at 200 um resolution. Visual inspection of the results from cubic interpolation and ResNets trained at different resolution (the top row in Fig. 2) showed subtle improvement. Quantitative analysis using RMSE and SSIM showed that the network trained using the same resolution (200 um and 100 um) performed better than other networks and cubic interpolation.
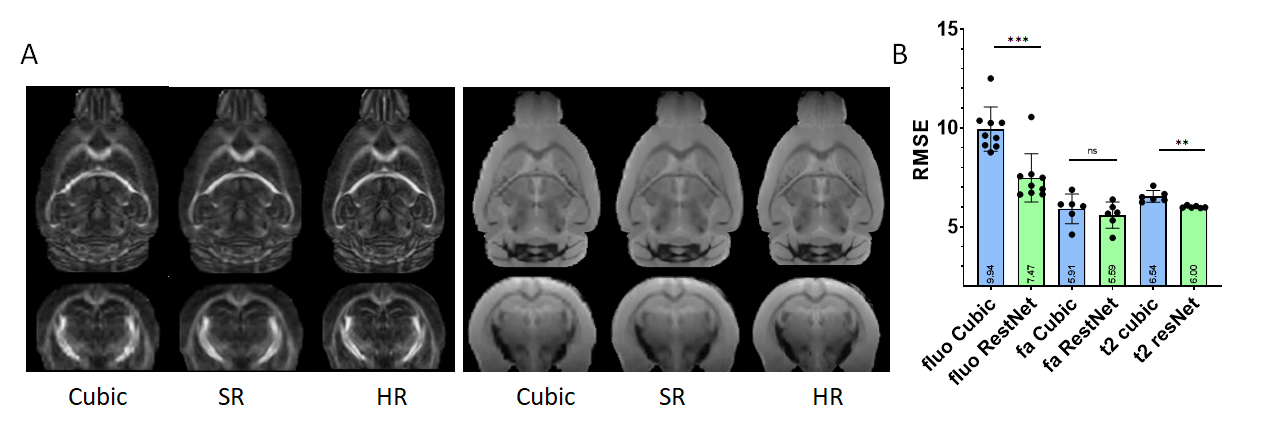
We then applied the ResNet trained using 200 and 100 um resolution optical data to T2 and fractional anisotropy (FA) images of ex vivo mouse brains at 200 um (Fig. 3). Compared to reference data at 100 um, there was significant improvement in T2 data in term of RMSE, but no significant improvement in FA data was observed. However, the degree of improvement in T2 data was less than in the native optical data, on which the ResNet was trained.
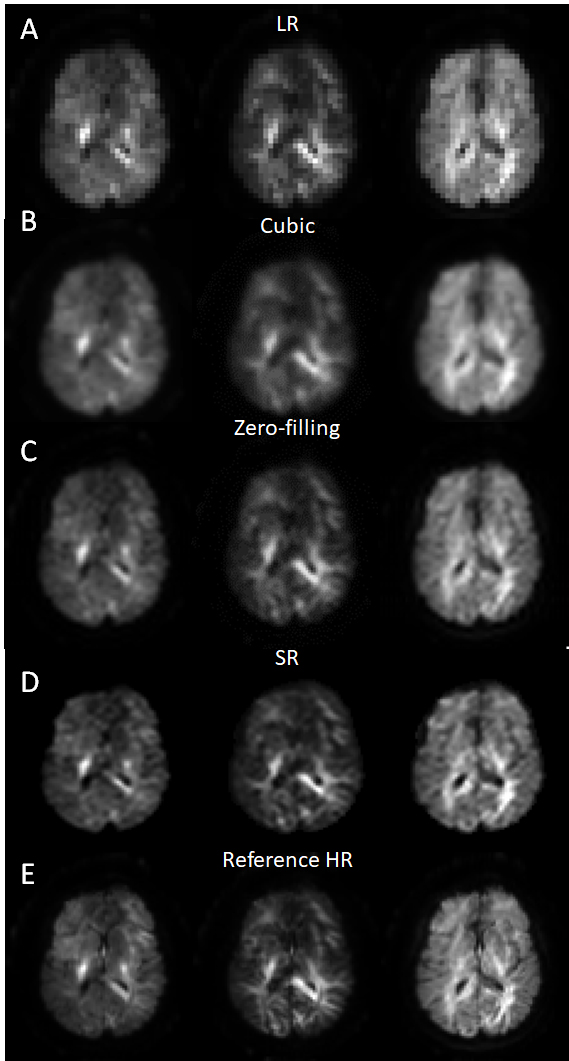
We then used human brain MRI data to train a ResNet and the results (Fig. 4) show improvement over the curbic interpolation and zero-filling results.
Discussion
In this study, we used small 21x21x21, 61x79x58 volumes or 2 dimensional patches instead of entire image as inputs to the network. This reduced the number of training dataset needed. Although deep learning based super-resolution provided visually enhanced results, quantitative measurements based on RMSE and SSIM suggested the actual improvement remained limited. Increasing the size of our training data may further improve the performance of the network.Conclusion
The study demonstrated that the enhancement of deep learning based super-resolution, although better than cubic interpolation, remained limited. In order to achieve the best performance, the network needs to be trained using data acquired at the target resolution and share similar contrasts.Acknowledgements
No acknowledgement found.References
[1]. Scherrer B, Gholipour A, Warfield SK. Super-resolution in diffusion-weighted imaging. Med Image Comput Comput Assist Interv. 14, 124-132 (2011)
[2]. Chi-HieuPham, CarlosTor-Díez, and HélèneMeunier et al. Multiscale brain MRI super-resolution using deep 3D convolutional networks. Graphics, 35, 101647. (2019).
[3]. Daniel C. Alexander, Darko Zikic, et al. Image quality transfer and applications in diffusion MRI, NeuroImage, 152, pp 283-298 (2017)
[4]. Chao Dong, Chen Change Loy and Kaiming He et al., Image Super-Resolution Using Deep Convolutional Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38, pp. 295-307 (2016).
[5]. Chi-HieuPham, CarlosTor-Díez, and HélèneMeunier et al. Multiscale brain MRI super-resolution using deep 3D convolutional networks. Graphics, 35, 101647. (2019).
[6]. Kai Zhang, Wangmeng Zuo, and Yunjin Chen et al. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE TRANSACTIONS ON IMAGE PROCESSING, 26, pp 3142-3155 (2017).
[7]. Vishwesh Nath, Marco Pizzolato and Marco Palombo, et al. Resolving to super resolution multi-dimensional diffusion imaging (Super-MUDI). ISMRM, 15-20 May 2021.
Figures