1335
SuperDTI: Superfast Deep-learned Diffusion Tensor Imaging
Hongyu Li1, Zifei Liang2, Chaoyi Zhang1, Ruiying Liu1, Jing Li3, Weihong Zhang3, Dong Liang4, Bowen Shen5, Peizhou Huang6, Sunil Kumar Gaire1, Xiaoliang Zhang6, Yulin Ge2, Jiangyang Zhang2, and Leslie Ying1,6
1Electrical Engineering, University at Buffalo, State University of New York, Buffalo, NY, United States, 2Center for Biomedical Imaging, Radiology, New York University School of Medicine, New York, NY, United States, 3Radiology, Peking Union Medical College Hospital, Peking Union Medical College and Chinese Academy of Medical Sciences, Beijing, China, 4Paul C. Lauterbur Research Center for Biomedical Imaging, Medical AI research center, SIAT, CAS, Shenzhen, China, 5Computer Science, Virginia Tech, Blacksburg, VA, United States, 6Biomedical Engineering, University at Buffalo, State University of New York, Buffalo, NY, United States
1Electrical Engineering, University at Buffalo, State University of New York, Buffalo, NY, United States, 2Center for Biomedical Imaging, Radiology, New York University School of Medicine, New York, NY, United States, 3Radiology, Peking Union Medical College Hospital, Peking Union Medical College and Chinese Academy of Medical Sciences, Beijing, China, 4Paul C. Lauterbur Research Center for Biomedical Imaging, Medical AI research center, SIAT, CAS, Shenzhen, China, 5Computer Science, Virginia Tech, Blacksburg, VA, United States, 6Biomedical Engineering, University at Buffalo, State University of New York, Buffalo, NY, United States
Synopsis
The main factor that prevents diffusion tensor imaging (DTI) from being incorporated in clinical routines is its long acquisition time of a large number of diffusion-weighted images (DWIs) required for reliable tensor estimation. This abstract presents SuperDTI to learn the nonlinear relationship between DWIs (reduced in q-space and k-space) and the corresponding tensor-derived quantitative maps as well as fiber tractography. Experimental results show that the proposed method can generate fractional anisotropy and mean diffusivity maps, as well as fiber tractography, from as few as six undersampled raw DWIs with quality comparable to results from 90 DWIs using conventional tensor fitting.
Introduction
DTI is widely used to examine the human brain white matter structures, including their microarchitecture integrity and spatial fiber tract trajectories. Although theoretically, only six diffusion directions are necessary for estimation of the diffusion tensor, much more DWIs from different directions are needed in practice due to the low SNR, resulting in a prolonged acquisition. Such prolonged scans can increase motion artifacts and discomfort of patients. Several techniques have been developed for DTI acceleration, such as parallel imaging based simultaneous multislice (SMS) acquisition [1] and compressed sensing [2-7]. However, the acceleration factor is limited to 2-3 with extensive computation power. The q-DL [8] and other subsequent studies have demonstrated the potential of using machine learning to reduce the q-space data necessary for diffusion image [9-14]. Besides multi-layer perceptrons [8, 9, 13], some used convolutional neural networks [10-12, 14-17]. Using deep learning, we demonstrate for the first time the feasibility to generate FA/MD and fiber tractography using as few as six undersampled DWIs indistinguishable from those obtained using 90 DWIs. SuperDTI is also compared against the state-of-the-art methods for diffusion map reconstruction and fiber tracking.Methods
In the deep learning network, the goal is to learn the nonlinear relationship $$$F$$$ between input $$$x$$$ and output $$$y$$$, which is represented as $$$y=F(x;Θ)$$$, where $$$Θ$$$ is the DL parameters to be learned during training. Learning of such a mapping is achieved through minimizing a loss function between the network prediction and the corresponding ground truth data based on some training data. Our goal is to obtain the mapping between DWIs (input) and the desired maps (output) using deep learning while by-passing the conventional tensor model. During training, a reduced number of DWIs $$$x_i$$$ are used as the inputs and the corresponding true maps $$$y_i$$$ (FA, MD or Eigenvectors obtained by fitting all 90 b = 1000 s/mm2 images to the tensor model) as the output. We learn deep learning network parameters $$$Θ$$$ that minimize the loss function: $$L(Θ)=\frac{1}{n} \sum_{i=1}^n ‖F(x_i;Θ)-y_i ‖^2 (1),$$ which is the mean-square error (MSE) between the network output and the ground truth maps (n is the number of training dataset). The proposed network comprises several layers of a skip-connection-based convolution-deconvolution network, which learns the residual between its input and output, as shown in Figure 1. In each layer, n64k3s1p1 (p’1) indicates 64 filters of kernel size 3 × 3 with a stride of 1 and padding of 1 (a truncation of 1). Except for the last layer, each (de)convolutional layer is followed by a ReLU unit. In testing, acquired DWIs are fed into the network with learned $$$Θ$$$ to generate the desired maps $$$F(x_t;Θ)$$$. The DTI model is not needed during testing, thus avoiding the model fitting error. Data from 40 subjects were used for training and validation, and the data from the other 10 subjects were used for testing. The subjects were randomly selected from the Human Connectome Project [18]. Each dataset includes 18 non-DWIs and 270 DWIs in three different b values: 1000, 2000, and 3000 s/mm2 and 90 diffusion directions. The reduced DWIs were uniformly selected with b=1000 s/mm2. The hardware specification is CPU i9 7980XE (18 cores 36 threads @4.2GHz); GPU 2x NVIDIA Quadro P6000 (24GB each); Memory 128 GB. The training takes around 10 hours. In contrast, it takes only 0.005 seconds to generate each desired map using the learned network.Results
Figure 1 shows the framework of SuperDTI. Figures 2 shows representative FA maps from 6 DWIs generated using the conventional tensor model fitting (MF), multi-layer perceptron (MLP) (similar to [8]), block-matching and 4D filtering (BM4D) denoising algorithm [18, 19], the proposed deep learning method (SuperDTI), and the proposed method with 2 × k-space undersampling (SuperDTI+). Figure 3 shows representative MD maps from 3 DWIs using different methods. While other results became noisy or blurry in such an extreme case, the FA maps generated by our proposed method showed no apparent degradation. The generated FA/MD maps were quantitatively evaluated using the PSNRs, SSIMs, and NMSEs, which show good performance for SuperDTI even with only 6 DWIs for FA and 3 DWIs for MD maps. It is seen that the difference between the MD maps is far less apparent than that between the FA maps because the MD calculation is less sensitive to noise. In Figure 4, fiber tracking results using the proposed method better preserve the morphology of three major white matter tracts in the brain than the others in the extreme 6 DWIs situation.Conclusion
In this abstract, we present SuperDTI for superfast diffusion tensor imaging and fiber tractography using deep learning with as few as six undersampled DWIs (up to 30-fold). Such a significant reduction in scan time will allow the inclusion of DTI into clinical routine for many potential applications. Future studies will use patient data for evaluating quantification accuracy and diagnostic performance.Acknowledgements
This work is supported in part by the National Institute of Health Brain Initiative R01EB025133.References
[1] Barth, Breuer et al. MRM. 2016 [2] Landman, Wan et al. SPIE. 2010 [3] Menzel, Tan et al. MRM. 2011 [4] Michailovich, Rathi et al. TMI. 2011 [5] Landman, Bogovic et al. NeuroImage. 2012 [6] Wu, Zhu et al. MRM. 2014 [7] Shi, Ma et al. MRM. 2015 [8] Golkov, Dosovitskiy et al. TMI. 2016 [9] Poulin, Cote et al. MICCAI. 2017 [10] Gong, He et al. ISMRM. 2018 [11] Li, Zhang et al. ISMRM. 2018 [12] Aliotta, Nourzadeh et al. ISMRM. 2019 [13] Gibbons, Hodgson et al. Medical Physics. 2019 [14] Li, Zhang et al. MRM. 2019 [15] Li, Gong et al. IEEE Access. 2019 [16] Lin, Gong et al. Medical Physics. 2019 [17] Tian, Bilgic et al. NeuroImage. 2020 [18] Van Essen, Ugurbil et al. NeuroImage. 2012 [19] Dabov, Foi et al. IEEE Trans. Image Process. 2007 [20] Maggioni, Katkovnik et al. IEEE Trans. Image Process. 2012Figures
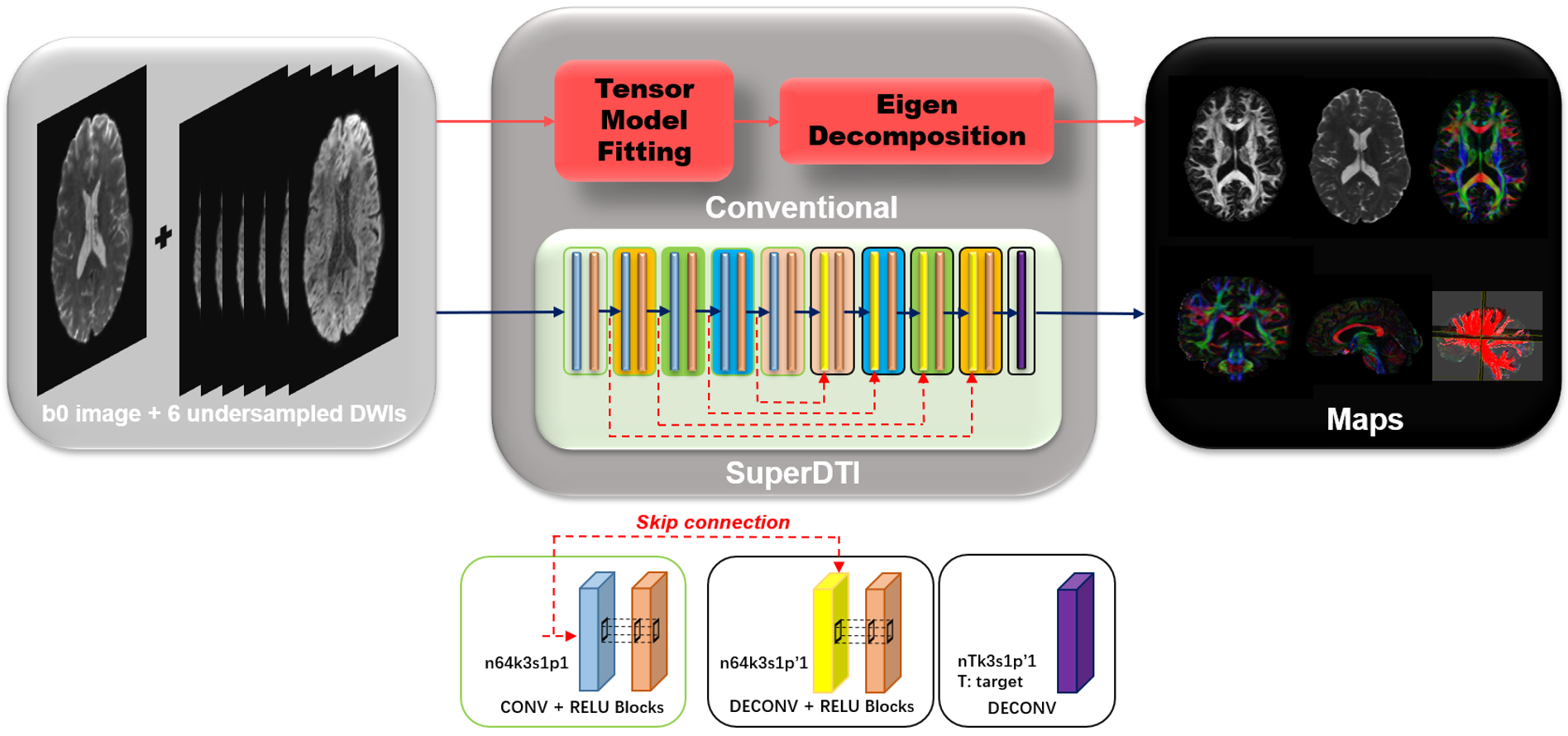
FIGURE
1. Schematic comparison of the conventional DTI model fitting and deep learning
methods SuperDTI for generating various diffusion quantification maps.
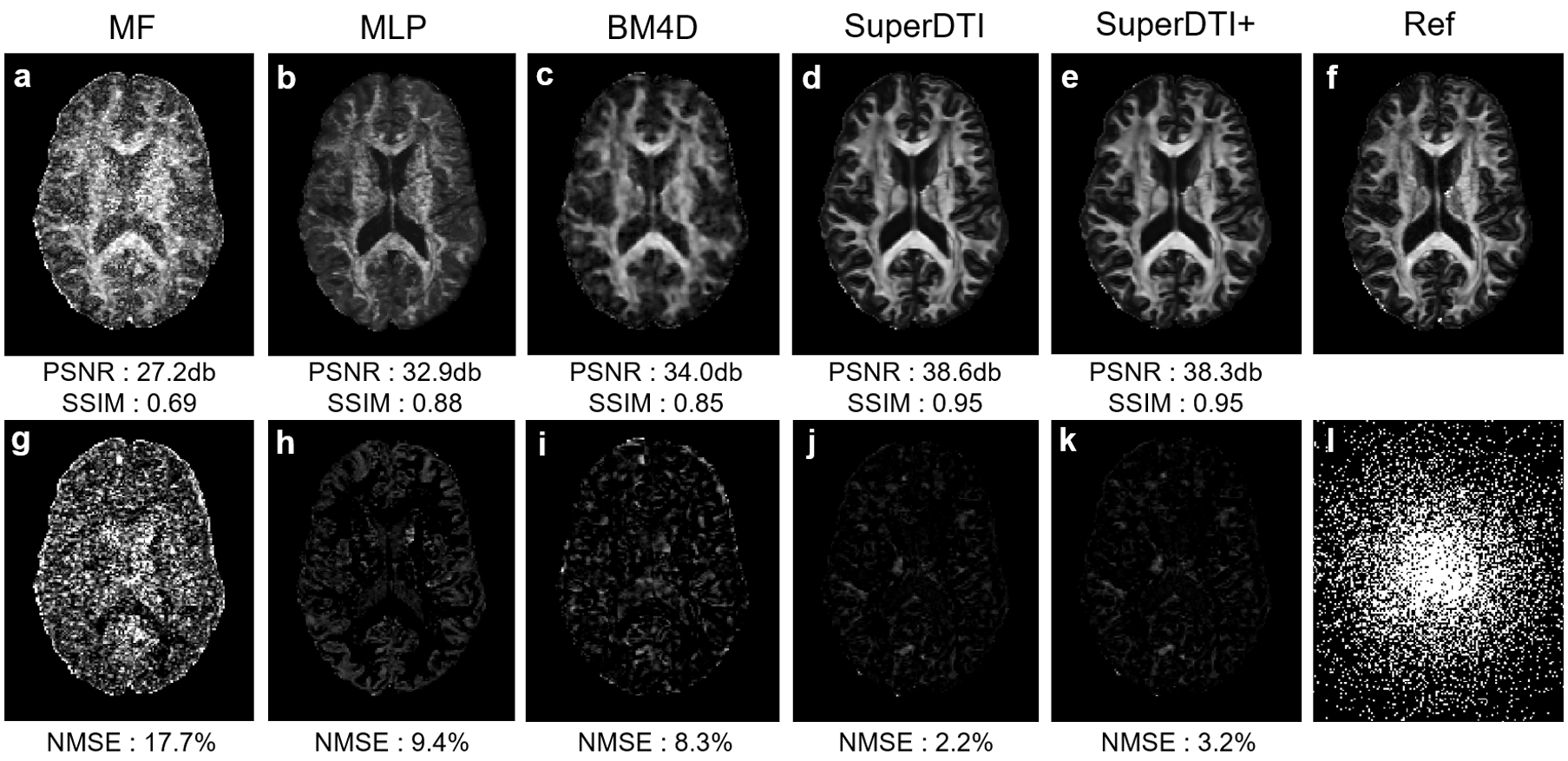
FIGURE 2.
Comparison of FA maps generated from 6 DWIs using different methods. FA maps generated by MF (a), MLP (b),
BM4D (c), proposed SuperDTI (d), proposed SuperDTI with
additional AF2 k-space reduction (l) called SuperDTI+ (e),
respectively, and the corresponding difference map (g-k) with 6 DWIs.
The PSNRs, SSIMs, and NMSEs were calculated with the model fitted FA map from
90 DWIs (f) as the reference.
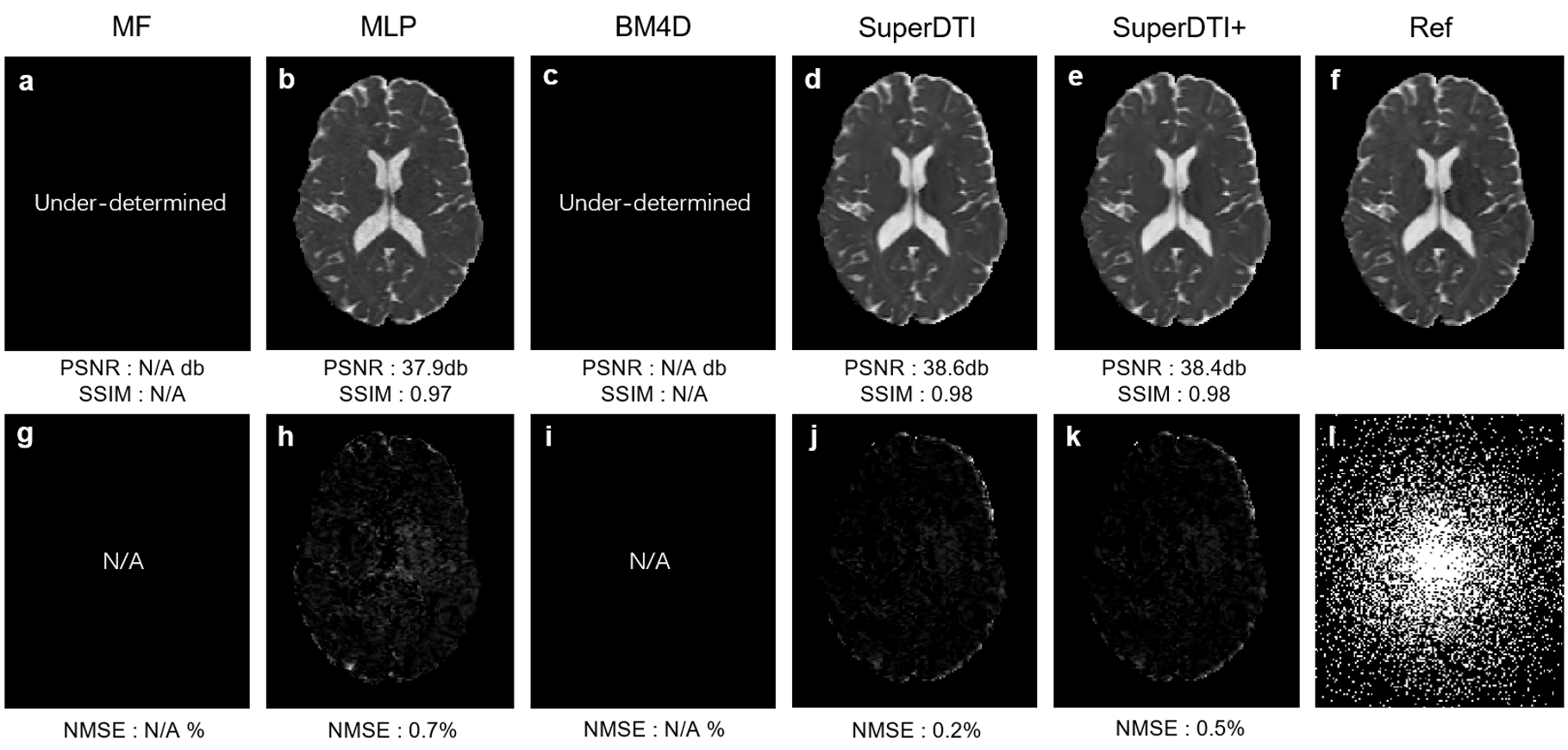
FIGURE 3.
Comparison of MD maps generated from 3 DWIs using different methods. MD maps generated by MF (a), MLP (b), BM4D
(c), proposed SuperDTI (d), proposed SuperDTI+ (e) with additional AF2 k-space
reduction (l), respectively, and the corresponding difference map (g-k) with 3
DWIs. The PSNRs, SSIMs, and NMSEs were calculated with the model fitted FA map
from 90 DWIs (f) as the reference.
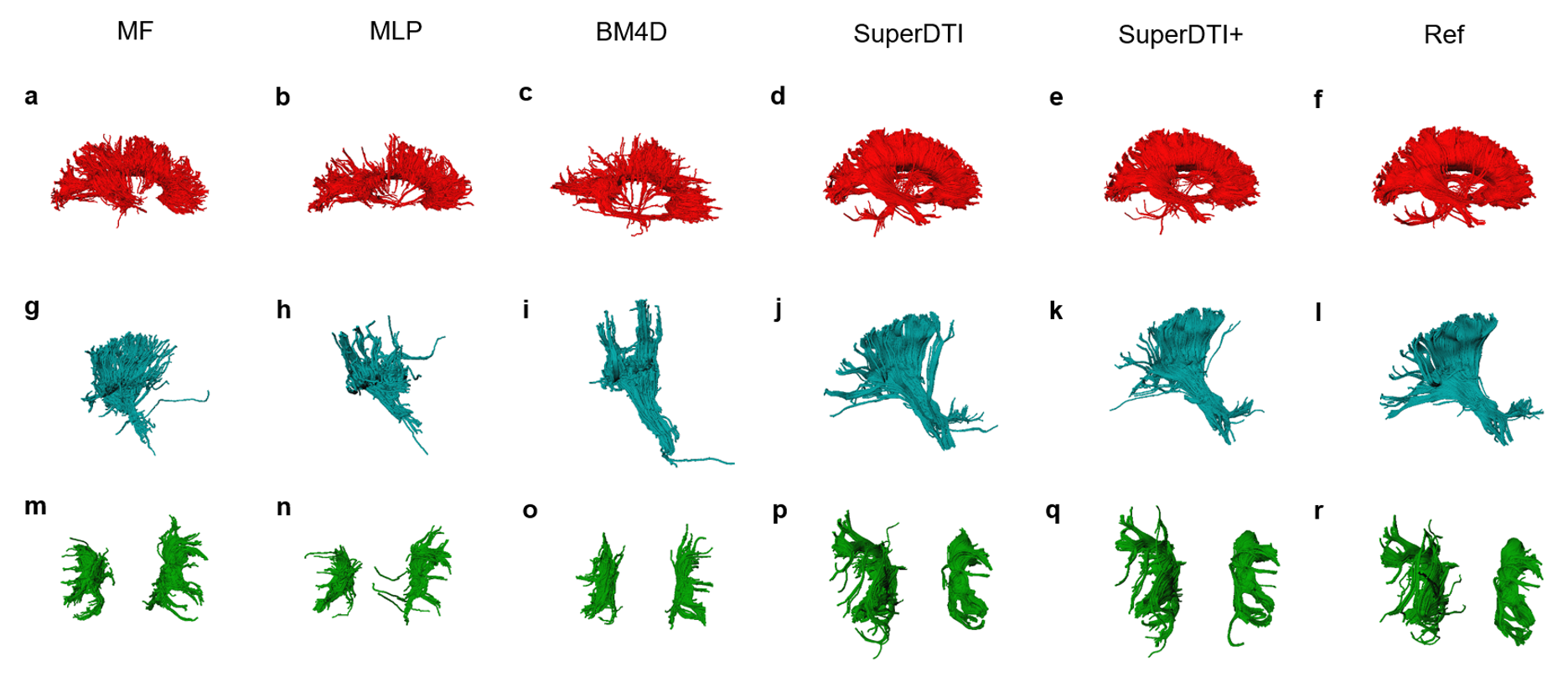
FIGURE 4. Comparison of fiber tractography generated from 6
DWIs using different methods. Corpus callosum, internal
capsule/corticospinal tract, and superior longitudinal fasciculus generated by
MF (a), MLP (b), BM4D (c), proposed SuperDTI (d), proposed SuperDTI+ (e) with
additional k-space reduction (l), respectively, and the corresponding difference
map (g-k) with 6 DWIs. The model-fitted tractography from 90 DWIs (d, k, r) is
also shown as a reference.