1329
Super-resolution and distortion-corrected diffusion-weighted imaging using 2D super-resolution generative adversarial network1GE Healthcare, Beijing, China, 2Radiology Department, The First Affiliated Hospital of Nanjing Medical University, Nanjing, China, 3Artificial Intelligence Imaging Laboratory, School of Medical Imaging, Nanjing Medical University, Nanjing, China
Synopsis
We proposed a deep learning-based method for super-resolution and distortion-corrected DWI reconstruction with a visual perception-sensitive super-resolution network SRGAN and multi-shot DWI as target. Our preliminary results demonstrated that the proposed model could produce satisfactory reconstruction of super-resolution diffusion images at b = 0 and 1000 s/mm2, and the geometric distortions in prefrontal cortex and temporal pole were well corrected. Furthermore, SRGAN reconstructed images provide comparable texture details to that of multi-shot DWI. With these findings, this developed model may be considered an effective tool for detecting subtle alterations of diffusion properties with only regular T2WI and DWI as inputs.
Introduction
Diffusion-weighted imaging (DWI)1 enables detection of tissue states by reflecting diffusion of water molecules in vivo. It has been recognized as a powerful clinical tool in evaluating varieties of diseases such as brain tumor2, stroke3, bladder cancer4, etc. Single-shot echo-planar imaging (SS-EPI) is the most commonly used sequence for DWI acquisition. However, it is characterized by low spatial resolution, blurring due to T2* decay, and susceptibility induced image distortion5. Recently, a multi-shot DWI technique, termed multiplexed sensitivity-encoding (MUSE)6, has been proposed. By segmenting k-space into partitions along phase-encoding direction per excitation and adopting sensitivity encoding (SENSE)7 reconstruction approach, MUSE provides high spatial resolution, signal-to-noise ratio (SNR), and spatial fidelity diffusion images6,8. Despite these advantages, the application of MUSE in clinical practice is still limited mainly due to long scan duration and high demand of system hardware. Recent advances in deep learning for image reconstruction allow for super-resolution diffusion images generation from regular diffusion images9,10. However, the applied target DWI data were still acquired with SS-EPI sequence, thus still suffering from image blurring and distortion as matrix size increased. In this study, a so-called super-resolution generative adversarial network (SRGAN) reported previously11 was adopted. We trained the network with conventional DWI and T2-weighted images (T2WI) as input, and high-resolution MUSE DWI images with reverse phase-encoding distortion correction12 as target. Our main goal was to investigate if super-resolution and distortion-corrected DWI images can be generated through SRGAN model with routine clinical MRI.Materials and Methods
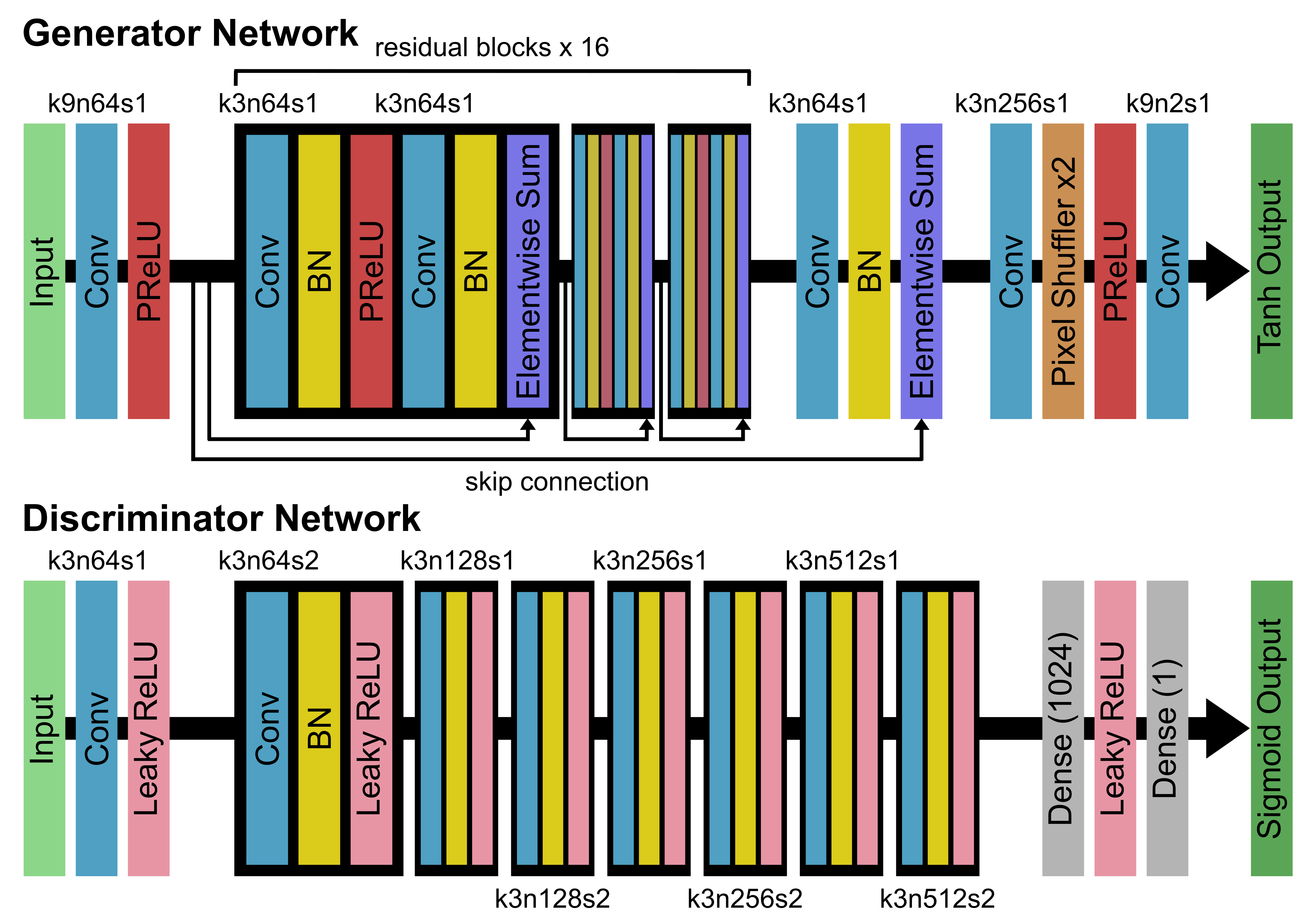
T2WI, DWI, and MUSE DWI data were acquired from 13 healthy participants on two 3T MRI scanners (SIGNA Premier and DiscoveryTM MR750w, GE Healthcare, Milwaukee, WI). The detailed acquisition parameters were as follows: (1) T2WI: TR/TE = 4750/109 ms, FOV = 240 x 240 mm, resolution = 0.58 x 0.58 x 5 mm, ETL = 30, BW = 101 kHz, NEX = 1.5; (2) DWI: TR/TE = 2200/58 ms, FOV = 240 x 240 mm, resolution = 1.88 x 1.88 x 5 mm, BW = 250 kHz, number of shots (NS) = 1, NEX = 4, b-value = 0, 1000 s/mm2; (3) MUSE DWI: TR/TE = 2620/65 ms, FOV = 240 x 240 mm, resolution = 0.94 x 0.94 x 5 mm, BW = 250 kHz, NS = 4, NEX = 4, b-value = 0, 1000 s/mm2. We randomly separated data from 13 subjects into a training group of 10 cases, a validation group of 1 case, and a testing group of 2 cases. For image preprocessing, we first performed a rigid registration between T2WI and DWI images, and all images were resampled into the same matrix size (256 x 256). Subsequently, data were augmented by random flipping and random cropping along frequency encoding direction, resulting in a total of 30000 patches (224 x 32) in the training dataset. Architecture of the SRGAN is shown in Figure 1. The input images consisted of 3 channels (T2WI, DWI b0 and DWI b1000), and target images consisted of 2 channels (MUSE b0 and MUSE b1000). For the optimization we used Adam13 with ß1 = 0.9 and ß2 = 0.999. The batch size was set at 16 and the total number of epochs was set at 100. The generator, which is a mean squared error (MSE)-based deep residual network (SRResNet)14, was trained with a learning rate of 10-4 in the first 60 epochs. The whole SRGAN was then trained with 20 epochs at a learning rate of 10-4 and another 20 epochs at a lower rate of 10-5. Image quality was evaluated by peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). The network was trained and evaluated using TensorFlow15.Results
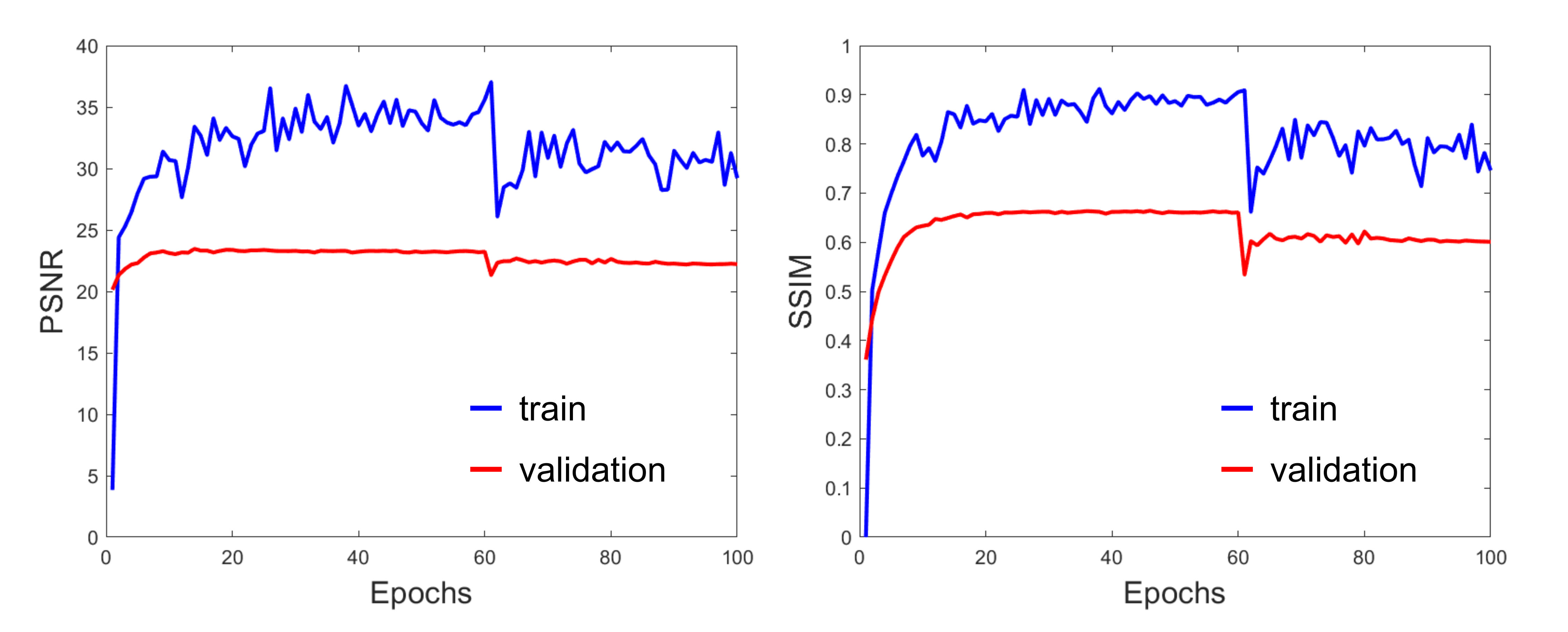
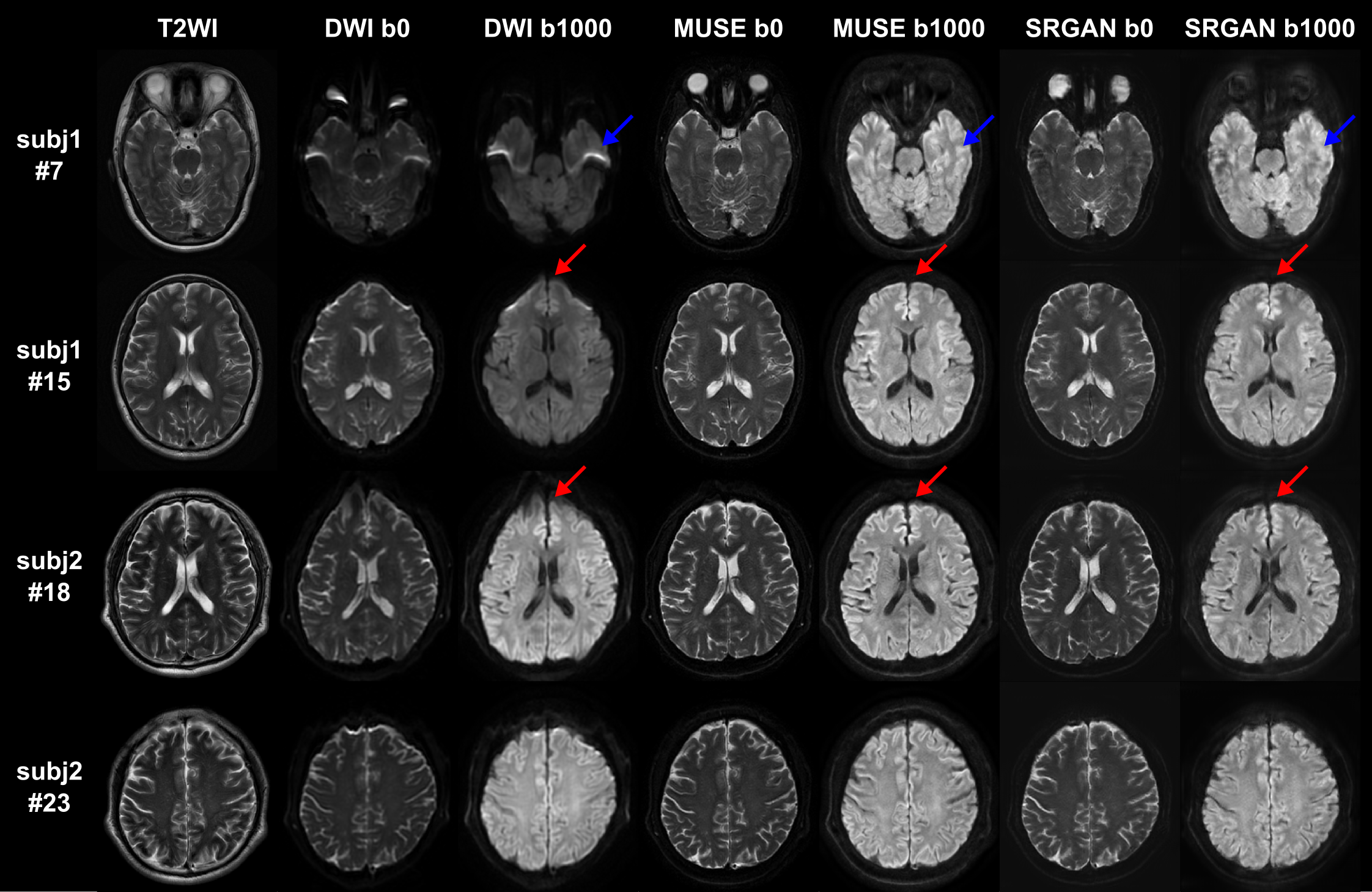
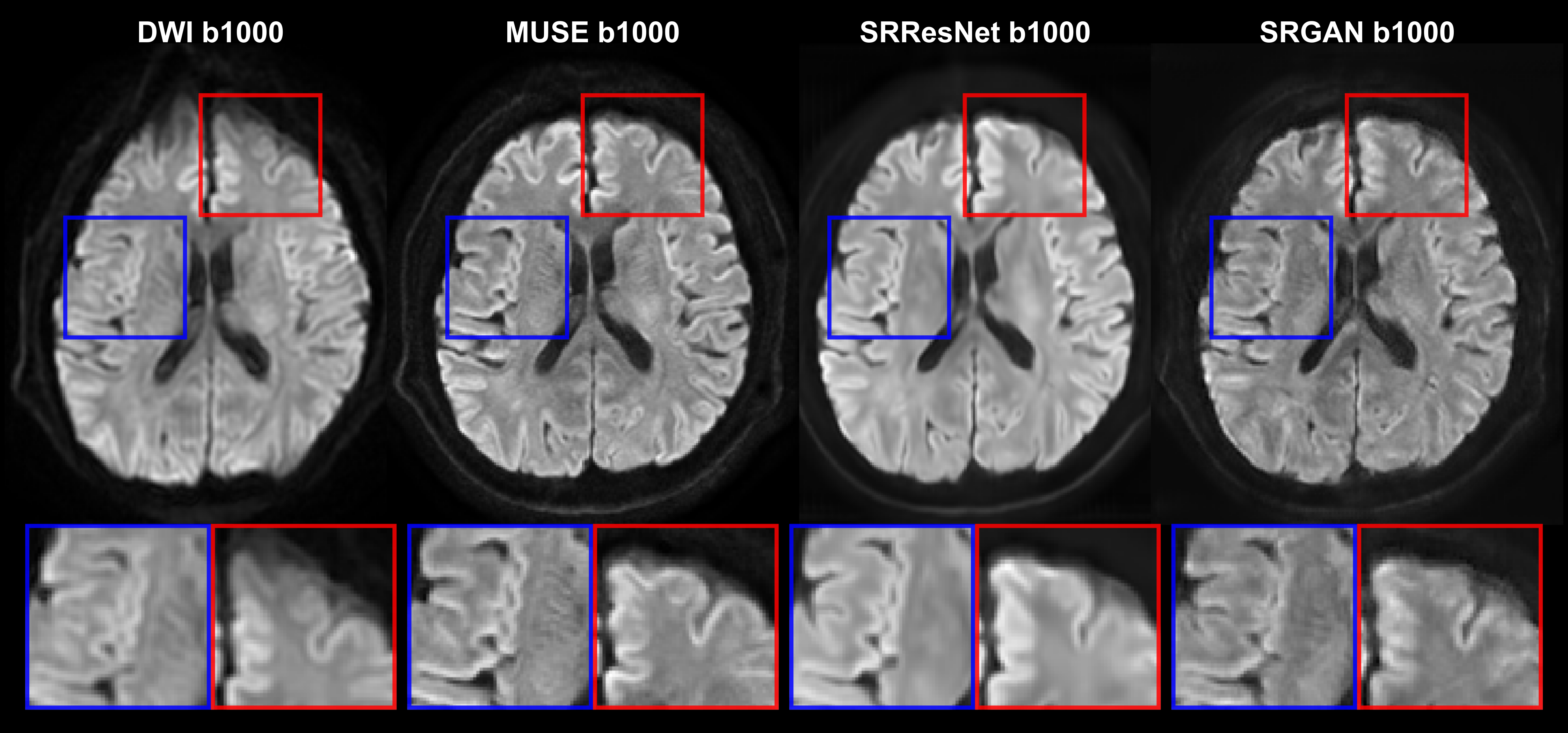
Figure 2 shows the PSNR and SSIM of the training and validation dataset during the training process. A reasonable convergence is steadily reached, and no over-fitting is observed. Finally, SRResNet achieves testing PSNR of 23.440 and SSIM of 0.696. SRGAN achieves testing PSNR of 23.191 and SSIM of 0.650. Figure 3 shows the T2WI, DWI, MUSE, and SRGAN reconstructed images from 4 representative slices in the testing dataset. The SRGAN produced satisfactory reconstruction of super-resolution diffusion images at b = 0 and 1000 s/mm2, and the geometric distortions in the prefrontal cortex (red arrow) and temporal pole (blue arrow) are well corrected. Figure 4 shows enlarged DWI, MUSE, SRResNet and SRGAN images at b = 1000 s/mm2. Although SRResNet results achieve overall higher PSNR and SSIM, they are perceptually rather smoother and less convincing than SRGAN reconstructed images. While still some artifacts occur in brain regions with severe field inhomogeneity, SRGAN reconstructed images provide comparable texture details to that of MUSE DWI.Discussion
Conventional DWI suffers from low spatial resolution, image blurring and distortion, making it difficult to finely detect the subtle diffusion characteristic changes. Here we proposed a deep learning-based approach using SRGAN with a training loss component more sensitive to visual perception, and use regular T2WI and DWI as input images. Overall, our preliminary results demonstrated that the proposed method could provide perceptually convincing super-resolution and distortion-corrected DWI images. Follow-up study with larger cohort is needed to further validate the model performance and generalize the network.Acknowledgements
No acknowledgement found.References
1. Le Bihan D, Breton E. Imagerie de diffusion in-vivo par resonance magnétique nucléaire. C R Acad Sci. 1985;93:27–34.
2. Holodny AI, Ollenschlager M. Diffusion imaging in brain tumors. Neuroimaging Clin. 2002;12:107–124.
3. Van Everdingen KJ, Van Der Grond J, Kappelle L, Ramos L, Mali W. Diffusion-weighted magnetic resonance imaging in acute stroke. Stroke. 1998;29:1783–1790.
4. Takeuchi M, Sasaki S, Ito M, Okada S, Takahashi S, Kawai T, Suzuki K, Oshima H, Hara M, Shibamoto Y. Urinary bladder cancer: diffusion-weighted MR imaging--accuracy for diagnosing T stage and estimating histologic grade. Radiology. 2009;251:112–21.
5. Turner R, Bihan DL. Single-shot diffusion imaging at 2.0 tesla. J Magn Reson. 1990;86:445–52.
6. Chen NK, Guidon A, Chang HC, Song AW. A robust multi-shot scan strategy for high-resolution diffusion weighted MRI enabled by multiplexed sensitivity-encoding (MUSE). Neuroimage. 2013;72:41–47.
7. Pruessmann KP, Weiger M, Scheidegger MB, Boesiger P. SENSE: sensitivity encoding for fast MRI. Magn Reson Med. 1999;42(5):952–962.
8. Chen X, Zhang Y, Cao Y, Sun R, Huang P, Xu Y, et al. A feasible study on using multiplexed sensitivity-encoding to reduce geometric distortion in diffusion-weighted echo planar imaging. Magn Reson Imaging. 2018;54:153–159.
9. Elsaid NMH, Wu YC. Super-resolution diffusion tensor imaging using SRCNN: A feasibility study. Annu Int Conf IEEE Eng Med Biol Soc. 2019;2019:2830–2834.
10. Albay E, Demir U, Unal G. Diffusion MRI spatial super-resolution using generative adversarial networks. In International Workshop on PRedictive Intelligence In Medicine. 2018;155–163.
11. Ledig C, Theis L, Husza ́r F, Caballero J, Cunningham A, Acosta A, et al. Photo-realistic single image super-resolution using a generative adversarial network. 2016;arXiv preprint arXiv:1609.04802.
12. Chang H, Fitzpatrick JM. A technique for accurate magnetic resonance imaging in the presence of field inhomogeneities. IEEE Trans Med Imaging. 1992;11(3):319–329.
13. Kingma D, Ba J. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR). 2015.
14. He K, Zhang X, Ren S, Sun J. Identity mappings in deep residual networks. In European Conference on Computer Vision (ECCV). 2016:630–645.
15. Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, et al. TensorFlow: Large-scale machine learning on heterogeneous systems. 2015. Software available from tensorflow.org.
Figures