1241
A Semi-Supervised Learning Framework for Jointly Accelerated Multi-Contrast MRI Synthesis without Fully-Sampled Ground-Truths1Department of Electrical and Electronics Engineering, Bilkent University, Ankara, Turkey, 2National Magnetic Resonance Research Center, Bilkent University, Ankara, Turkey, 3Department of Electrical and Computer Engineering, University of Southern California, Los Angeles, CA, United States, 4Neuroscience Program, Aysel Sabuncu Brain Research Center, Bilkent University, Ankara, Turkey
Synopsis
Current approaches for synthetic multi-contrast MRI involve deep networks trained to synthesize target-contrast images from source-contrast images in fully-supervised protocols. Yet, their performance is undesirably circumscribed to training sets of costly fully-sampled source-target images. For practically advanced multi-contrast MRI synthesis accelerated across the k-space and contrast sets, we propose a semi-supervised generative model that can be trained to synthesize fully-sampled images using only undersampled ground-truths by introducing a selective loss function expressed only on the acquired k-space coefficients randomized across training subjects. Demonstrations on multi-contrast brain images indicate that the proposed model maintains equivalent performance to the gold-standard fully-supervised model.
Introduction
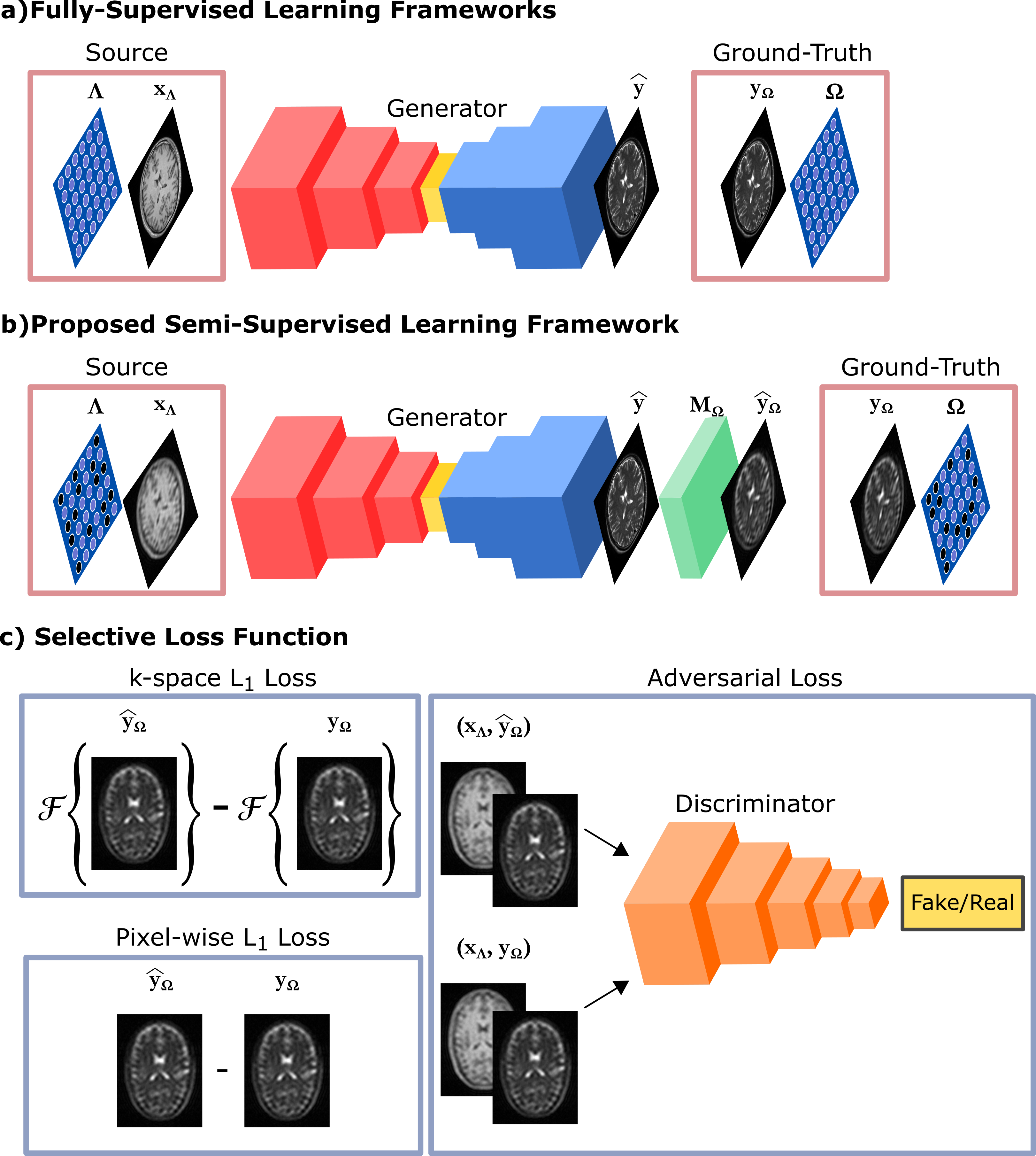
Magnetic resonance imaging (MRI) manifests a central position in clinical neuroimaging due to its nonpareil ability to produce multi-contrast images of the same underlying anatomy. These multi-contrast images offer complementary information for downstream radiological observations and image analysis tasks1, but prolonged examinations often restrain the compilation of all desired contrasts2. To recover missing target-contrast images from available source-contrast images, recent studies have successfully demonstrated deep network models that are trained in fully-supervised protocols3-8. However, these models naturally reveal undesirable reliance on training sets of fully-sampled ground-truths, which may prove impractical9,10 to acquire due to limitations induced by physical constraints, scan durations, or patient motion. To mitigate these limitations, we propose a novel semi-supervised synthesis model (ssGAN) for accelerated multi-contrast MRI that enables training using only undersampled ground-truths of the target-contrast11 (Fig. 1). To do this, ssGAN introduces a selective loss function expressing the network error only on the subset of acquired k-space samples and leverages randomized sampling masks across training subjects for learning the relationship among acquired-nonacquired k-space coefficients at all locations. ssGAN additionally allows synthesis from undersampled sources to further reduce data requirements in multi-contrast MRI undersampled across both contrast sets and k-space11.Methods
Semi-Supervised Learning of Jointly Accelerated Multi-Contrast MRIssGAN takes as input source-contrast images $$$x_{\Lambda}$$$ acquired with a sampling mask $$$\Lambda$$$, and learns a generator $$$G$$$ that synthesizes fully-sampled target-contrast images $$$\hat{y}=G(x_{\Lambda})$$$, given undersampled ground-truths $$$y_{\Omega}$$$ acquired with a sampling mask $$$\Omega$$$. Here, a semi-supervised learning framework with a selective network loss function is proposed to evaluate the synthesized fully-sampled images only on the acquired k-space coefficients of the undersampled ground-truths. First, undersampled counterparts of the synthesized images are obtained via binary masking:$$\hat{k}_{y_{\Omega}}=M(\mathcal{F}(\hat{y}),\Omega)$$$$\hat{y}_\Omega=\mathcal{F}^{-1}(\hat{k}_{y_{\Omega}})$$where $$$\mathcal{F}$$$ denotes forward and $$$\mathcal{F^{-1}}$$$ denotes inverse Fourier transform, $$$M$$$ is a masking operator, $$$\hat{k}_{y_{\Omega}}$$$ denotes masked k-space coefficients, and $$$\hat{y}_\Omega$$$ denotes undersampled counterparts of the synthesized images. The selective network loss is then expressed between the undersampled counterpart and ground-truth images in terms of image and k-space domain $$$\mathrm{L_1}$$$, and adversarial losses:$$L_{ssGAN}={\overbrace{\lambda_{i}\mathrm{E}_{x_{\Lambda},y_{\Omega}}[||\hat{y}_\Omega-y_\Omega||_1]}^{\mathrm{Image\,L_1\,Loss}}+\overbrace{\lambda_{k}\mathrm{E}_{x_{\Lambda},y_{\Omega}}[||\hat{k}_{y_\Omega}-\mathcal{F}(y_\Omega)||_1]}^{\mathrm{k-space\,L_1\,Loss}}}+\overbrace{\lambda_{adv}(-\mathrm{E}_{x_{\Lambda},y_{\Omega}}[(D(x_{\Lambda},y_{\Omega})-1)^2]-\mathrm{E}_{x_{\Lambda}}[D(x_\Lambda,\hat{y}_\Omega)^2]}^{\mathrm{Adversarial\,Loss}})$$with $$$D$$$ is a discriminator telling apart from the undersampled counterpart and ground-truth images, $$$\lambda_{i},\,\lambda_{k},\,\lambda_{adv}$$$ respectively denote the weightings of the image domain, k-space domain, and adversarial losses. Note that target-contrast sampling masks $$$\Omega$$$ are randomized across training subjects for effective learning of the relationships among acquired and non-acquired k-space coefficients at all locations to synthesize fully-sampled high-quality target images.
Competing Method and Dataset
The proposed ssGAN model was comparatively demonstrated against a gold-standard fully-supervised fsGAN model that is trained with fully-sampled ground-truths using fully-supervised image and k-space domain $$$\mathrm{L_1}$$$, and adversarial losses. The ssGAN and fsGAN models were demonstrated on the IXI dataset containing $$$\mathrm{T_1}$$$- and $$$\mathrm{T_2}$$$-weighted brain images of $$$94$$$ subjects (training: $$$64$$$, validation: $$$10$$$, test: $$$20$$$) spatially registered with FSL. From each subject, approximately $$$90$$$ artifact-free axial cross-sections were selected. Retrospective undersampling was performed on the images with three separate acceleration ratios: $$$R=2,3,4$$$. The sampling masks remained identical for all axial cross-sections within the same subject, whereas varied across distinct contrasts and subjects.
Implementation Details
The architectures-hyperparameters for ssGAN and fsGAN were mainly adopted from a previous conditional GAN model demonstrated for MRI synthesis4. The generator networks consisted of an encoder with $$$3$$$ conv-layers, $$$9$$$ ResNet blocks, and $$$3$$$ conv-layers in series, whereas the discriminator networks consisted of a convolution network of $$$4$$$ conv-layers in series. The total number of epochs was set to $$$100$$$ with a batch size of $$$1$$$. The learning rate was set to $$$0.0002$$$ in the first $$$50$$$ epochs and decayed linearly to $$$0$$$ in the remaining $$$50$$$ epochs with the Adam optimizer ($$$\beta_1=0.5\mathrm{,}\,\beta_2=0.999$$$). The optimal weightings were determined to be ($$$\lambda_{i}=1,\lambda_{k}=30,\,$$$and$$$\,\lambda_{adv}=0.01$$$) via the validation set.
Results
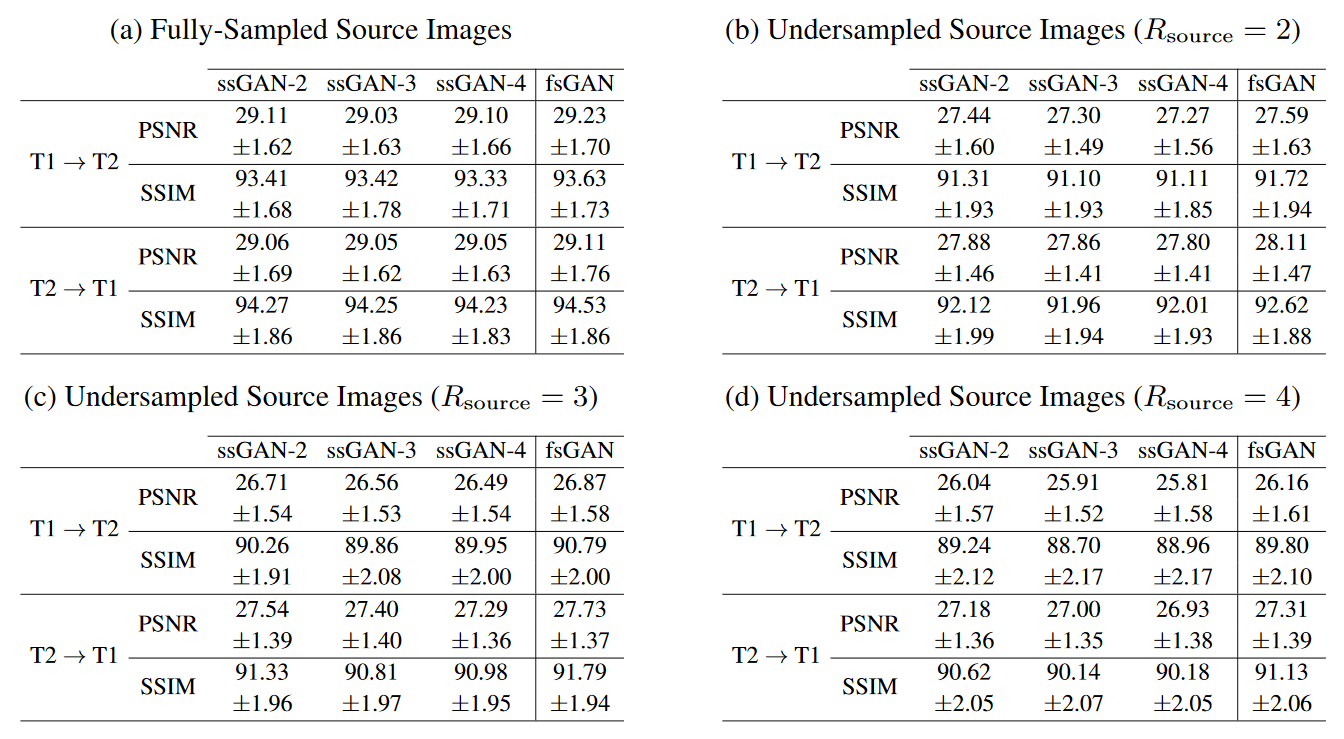
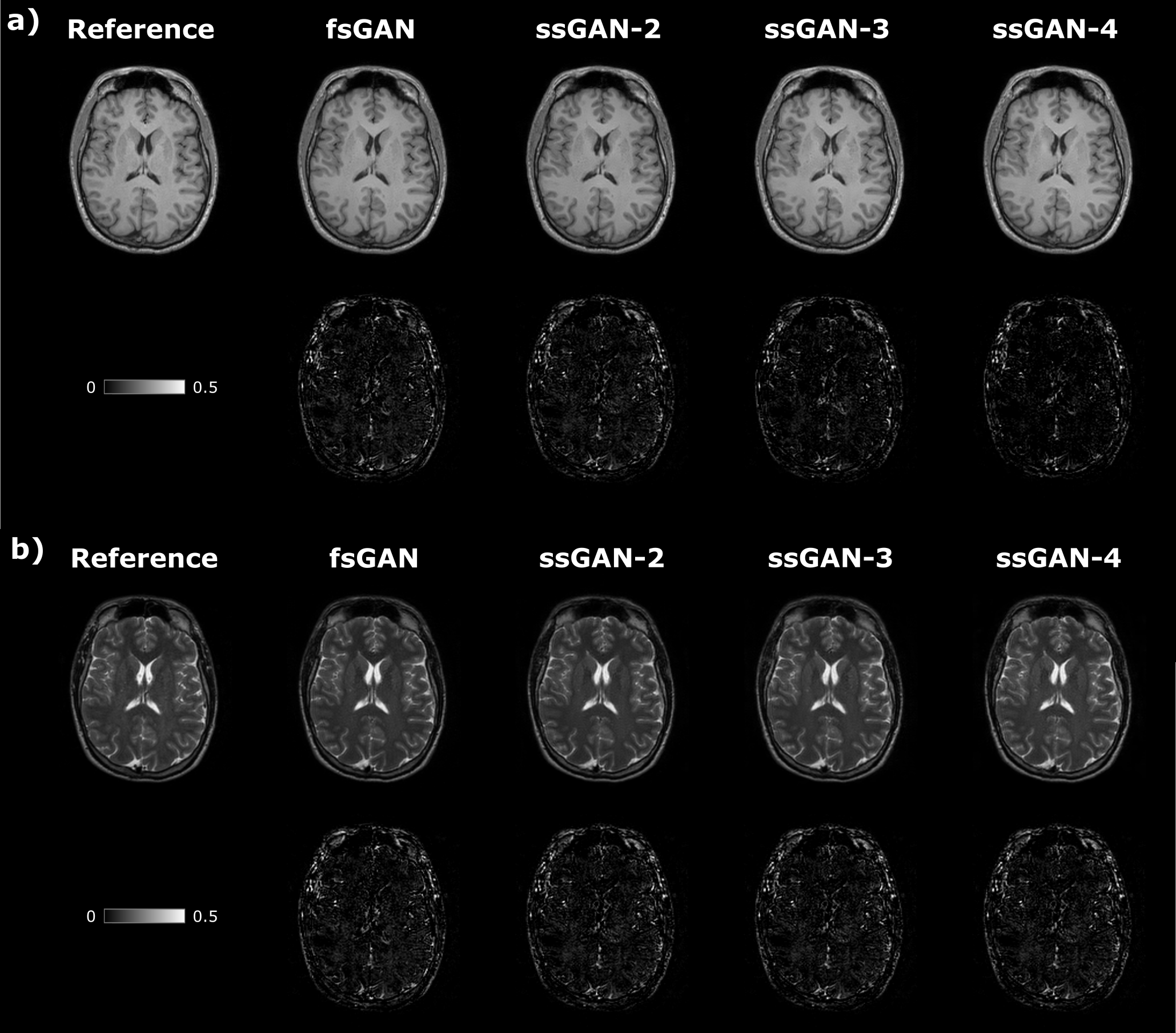
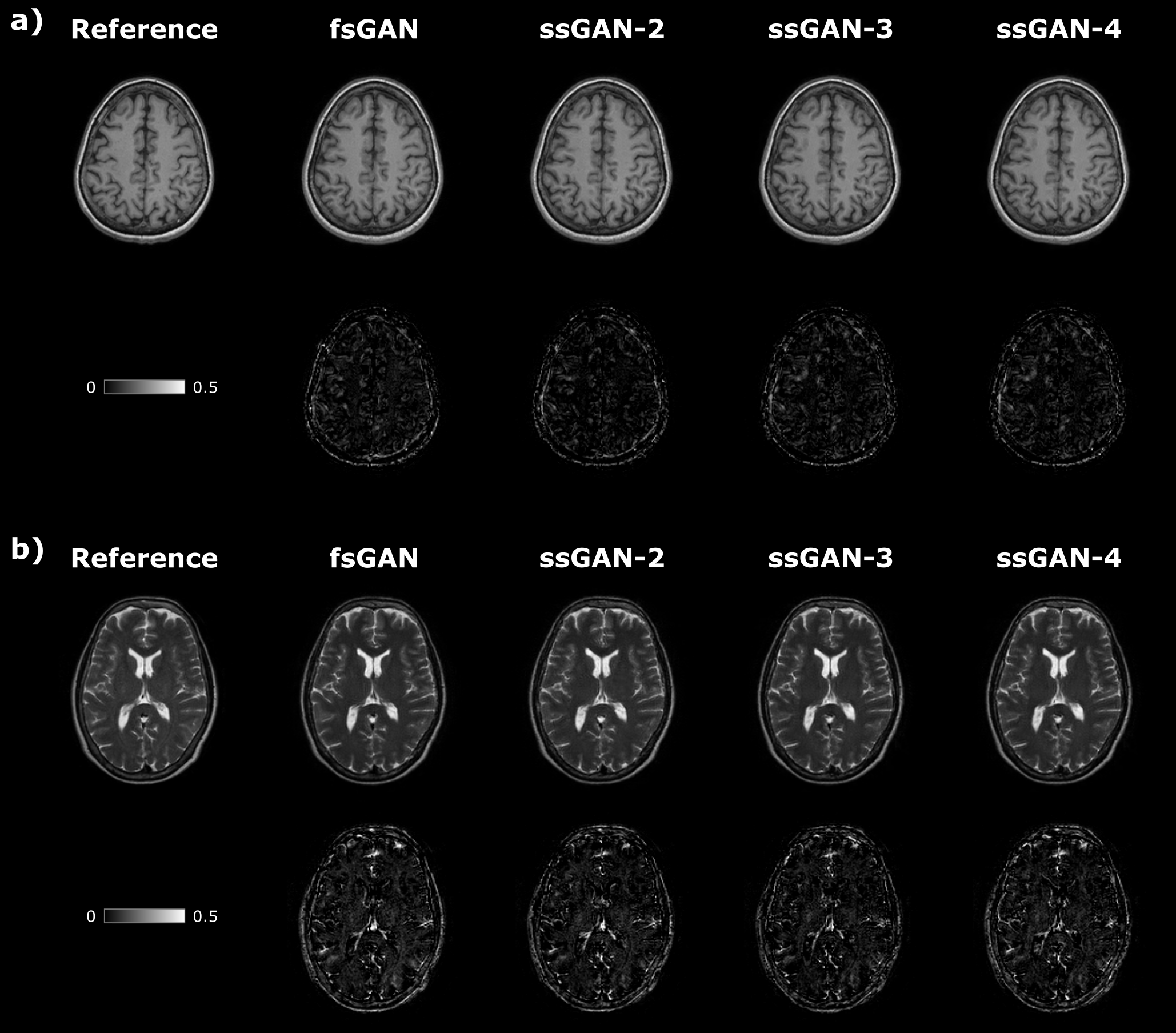
The proposed ssGAN model was demonstrated against the gold-standard fsGAN model on the IXI dataset for $$$\mathrm{T_1}\rightarrow~\mathrm{T_2}$$$ and $$$\mathrm{T_2}\rightarrow~\mathrm{T_1}$$$ synthesis tasks. In the demonstrations, a single fsGAN model was trained with fully-sampled ground-truths, whereas three independent ssGAN models were trained with undersampled ground-truths with separate acceleration ratios: ssGAN-2 with $$$R_{target}=2$$$, ssGAN-3 with $$$R_{target}=3$$$, ssGAN-4 with $$$R_{target}=4$$$. First, fully-sampled images of the source-contrast were assumed for all models. Table 1a reports synthesis quality in terms of PSNR-SSIM measurements, which suggest that ssGAN yields equivalent performance to fsGAN (Kruskal-Wallis: $$$p>0.5$$$). The equivalent performance of the ssGAN models is also visible in representative results displayed in Fig. 2.Next, undersampled images of the source-contrast were assumed for all models with acceleration ratios: ($$$R_{\mathrm{source}}=2,3,4$$$). Table 1b-d also reports synthesis quality in terms of PSNR-SSIM measurements, which again indicates equivalent performance of ssGAN to fsGAN (Kruskal-Wallis: $$$p>0.3$$$) together with the representative results displayed in Fig. 3. The overall results therefore suggest that ssGAN synthesizes fully-sampled high-quality target images without demanding large training datasets of costly fully-sampled source or ground-truth target images.
Discussion
Here, we presented a novel semi-supervised model, ssGAN, for accelerated multi-contrast MRI synthesis. ssGAN synthesizes high-quality target-contrast images without demanding large training datasets of costly fully-sampled source or ground-truth target images by introducing a selective loss function expressing network error only the acquired k-space coefficients that are randomized across training subjects.Conclusion
The proposed semi-supervised learning model offers elevated feasibility in accelerated multi-contrast MRI synthesis jointly undersampled across both contrast sets and k-space coefficients.Acknowledgements
This work was supported in part by a TUBA GEBIP fellowship, by a TUBITAK 1001 Grant (118E256), by a BAGEP fellowship, and by NVIDIA with a GPU donation.References
1. Iglesias JE, Konukoglu E, Zikic D, Glocker B, Leemput KV, Fischl B. Is synthesizing MRI contrast useful for inter-modality analysis?. Medical Image Computing and Computer-Assisted Intervention (MICCAI). 2013:631-638.
2. Thukral B. Problems and preferences in pediatric imaging. Indian Journal of Radiology and Imaging. 2015;25(11):359-364.
3. Dewey BE, Zhao C, Reinhold JC, Carass A, Fitzgerald KC, Sotirchos ES, Saidha S, Oh J, Pham DL, Calabresi PA, Zijl PC, Prince JL. DeepHarmony: A deep learning approach to contrast harmonization across scanner changes. Magnetic Resonance Imaging. 2019;64:160-170.
4. Dar SUH, Yurt M, Karacan L, Erdem A, Erdem E, Cukur T. Image Synthesis in Multi-Contrast MRI with Conditional Generative Adversarial Networks. IEEE Transactions on Medical Imaging. 2019;38(10):2375-2388.
5. Lei K, Mardani M, Pauly JM, Vasanawala SS. Wasserstein GANs for MR imaging: from paired to unpaired training. IEEE Transactions on Medical Imaging. 2020.
6. Lee D, Kim J, Moon W, Ye JC. Collagan: Collaborative GAN for missing image data imputation. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2019;2482–2491.
7. Yu B, Zhou L, Wang L, Shi Y, Fripp J, Bourgeat P. EA-GANs: edge aware generative adversarial networks for cross-modality MR image synthesis. IEEETransactions on Medical Imaging. 2019;38(7):1750-1762.
8. Sharma A, Hamarneh G. Missing MRI pulse sequence synthesis using multi-modal generative adversarial network. IEEE Transactions on Medical Imaging.2019;39(4):1170-1183.
9. Yaman B, Hosseini SAH, Moeller S, Ellermann J, Ugurbil K, Akçakaya M. Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data. Magnetic Resonance in Medicine. 2020;84(6):3172-3191.
10. Cole EK, Pauly JM, Vasanawala SS, Ong F. Unsupervised MRI reconstruction with generative adversarial networks. arXiv:2008.13065, preprint. 2020.
11. Yurt M, Dar SUH, Tinaz B, Ozbey M, Cukur T. Semi-Supervised Learning of Mutually Accelerated Multi-Contrast MRI Synthesis without Fully-Sampled Ground-Truths. arXiv:2011.14347, preprint. 2020.
12. https://brain-development.org/ixi-dataset/
Figures