1168
Is good old GRAPPA dead?1Neurospin, Gif-Sur-Yvette, France, 2Parietal team, Inria Saclay, Gif-Sur-Yvette, France, 3Cosmostat team, CEA, Gif-Sur-Yvette, France
Synopsis
We perform a qualitative analysis of performance of XPDNet, a state-of-the-art deep learning approach for MRI reconstruction, compared to GRAPPA, a classical approach. We do this in multiple settings, in particular testing the robustness of the XPDNet to unseen settings, and show that the XPDNet can to some degree generalize well.
Introduction
Deep Learning has recently overwhelmed the field of MR image reconstruction from under-sampled data. From AUTOMAP1 to the more recent unrolled neural networks2-5, all of them showed the great potential of deep learning for the field, achieving ground-breaking results in quantitative metrics such as PSNR and SSIM for high acceleration factors.However, there is a lack of comparison of these approaches to the current gold standards for periodic under-sampling, typically implemented in the MRI scanners. In this paper, we compare a state-of-the-art approach, the XPDNet5, to GRAPPA (Generalized Autocalibrating Partially Parallel Acquisitions)6 on the task of reconstructing periodically under-sampled MR images in different qualitative settings. GRAPPA is used in all the Siemens scanners, the most distributed in the world, as the default method for image reconstruction in the case of periodic under-sampling (and similar approaches for other manufacturers). However, very few deep learning papers for MRI reconstruction include a comparison to GRAPPA.Methods
Network. The XPDNet is a type of unrolled network that secured the second place in the 2020 fastMRI brain reconstruction challenge7. Very basically, it un-rolls the PDHG8 algorithm using an Multi-level Wavelet CNN (MWCNN)9 as the learned proximity operator. It has 25 unrolled iterations, and also features a sensitivity maps refinement module. Two networks were trained for acceleration factors 4 and 8, using retrospectively under-sampled data from the fastMRI dataset10 with equidistant Cartesian masks. We chose to use non fine-tuned versions of the networks (i.e. trained on the four available imaging contrasts).GRAPPA. We used the vanilla version of GRAPPA without noise handling.We use kernels that span 5 points in the readout direction and 2 in the phase direction. We manually set the regularisation parameter $$$λ >0$$$ to obtain the best compromise between quantitative and qualitative evaluation, therefore biasing the analysis towards GRAPPA. We leave the analysis of a smart setting of $$$λ$$$ for future works.
Data. We used 3 data sets to perform our comparison on:
- a brain slice from the fastMRI validation data set10 (the state-of-the-art network was trained on the training data set), with T2 contrast, retrospectively under-sampled at acceleration factors 4 and 8;
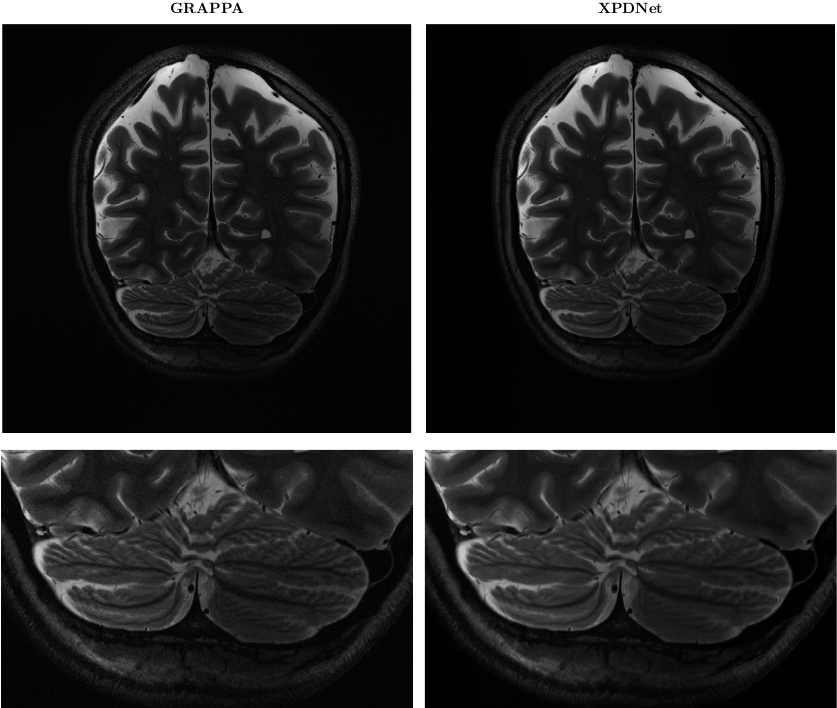
- a brain slice acquired at a different resolution $$$(0.25mm×0.25mm)$$$ using a different magnetic field strength (7T), orientation and acceleration factor than the fastMRI brain data set and featuring the cerebellum (not present in the fastMRI brain data set), with T2 contrast, prospectively under-sampled at acceleration factor 2 – this allows us to test the robustness of the network to somewhat unseen settings11;
- a NIST phantom, prospectively under-sampled at acceleration factor 8, acquired at 3T with 64 coils and a matrix size of $$$256×256$$$. All the data is periodically under-sampled with an Autocalibration Signal (ACS).
Code. We use the code linked in reference5 for the network. We used our own implementation of GRAPPA with a TensorFlow backend.
Results
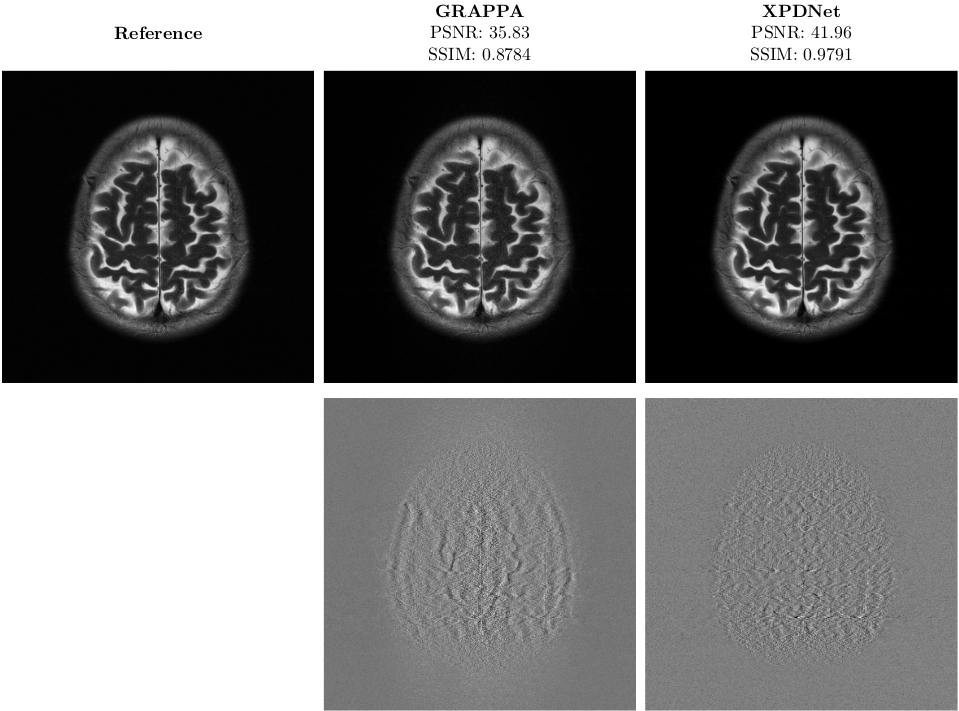
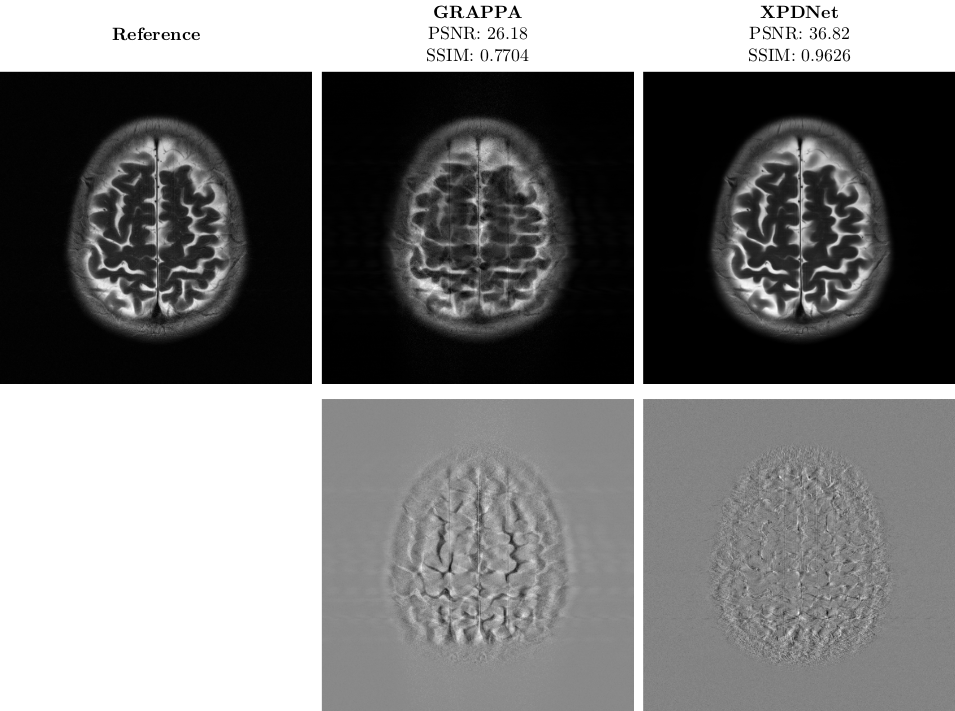
On the fastMRI brain slice. At acceleration factor 4, the quantitative results seem to show that the XPDNet has an overwhelmingly better image quality than GRAPPA. However, upon visual inspection of the images available in Fig. 1, we see that the image reconstructed by GRAPPA is only degraded by some noise not deteriorating its interpretability. At acceleration factor 8, the quantitative metrics once again show a clear advantage of the XPDNet over GRAPPA. This time, it is clearly confirmed by the visual inspection of the images presented in Fig. 2.On the out-of-distribution brain slice. The image reconstructed with the XPDNet shows some faint smoothing in the cerebellum as shown in the bottom row of Fig. 3. However, the overall image is artifacts-free and very difficult to distinguish from the GRAPPA-reconstructed one.
On the NIST phantom. The phantom reconstructed using GRAPPA and XPDNet at acceleration factor 8 are very poor. For GRAPPA, the noise completely obfuscates the signal while for XPDNet the artifacts are present everywhere as can be seen in Fig. 4.
Conclusion and discussion
The Deep Learning techniques seem ready for a substitution test at acceleration factor 4, however, they do not seem to provide an overwhelming advantage over GRAPPA visually. The acceleration factor of 8 looks like an attainable target, and it would drastically improve the image quality when compared to GRAPPA, even when using the latest noise handling techniques. We also showed that the XPDNet is robust enough to be adapted to settings relatively different from the training distribution. However, if trained on brains a network can not reconstruct objects that are too dissimilar, like phantoms. We conclude that it is therefore important to test visually the results of a reconstruction network at low acceleration factors to measure the difference compared to GRAPPA,and that the high acceleration factors are currently the real target for Deep Learning. This work demands other types of robustness and sanity tests such as (but not limited to) receiver array coil design, SNR level, contrasts, organs, and orientation.Acknowledgements
We acknowledge the financial support of the Cross-Disciplinary Program on Numerical Simulation of CEA, the French Alternative Energies and Atomic Energy Commission for the project entitled SILICOSMIC.
We also acknowledge the French Institute of development and ressources in scientific computing (IDRIS) for their AI program allowing us to use the Jean Zay supercomputers' GPU partitions.
Finally, this work received financial support from Leducq Foundation (large equipment ERPT program, NEUROVASC7T project).
References
1. Bo Zhu et al. “Image reconstruction by domain-transform manifold learn-ing”. In:Nature555.7697 (Mar. 2018), pp. 487–492.issn: 0028-0836.doi:10 . 1038 / nature25988.url:http : / / www . nature . com / articles /nature25988.
2. Jo Schlemper et al. “A Deep Cascade of Convolutional Neural Networks forMR Image Reconstruction”. In:IEEE Transactions on Medical Imaging37.2 (2018), pp. 491–503.doi:10.1109/TMI.2017.2760978.
3. Kerstin Hammernik et al. “Learning a Variational Network for Recon-struction of Accelerated MRI Data”. In:Magnetic Resonance in Medicine3071.September 2017 (2018), pp. 3055–3071.doi:10.1002/mrm.26977.
4. Anuroop Sriram et al. “End-to-End Variational Networks for AcceleratedMRI Reconstruction”. In:MICCAI. 2020.isbn: 2004.06688v1.
5. Zaccharie Ramzi, Philippe Ciuciu, and Jean-Luc Starck.XPDNet for MRIReconstruction: an Application to the fastMRI 2020 Brain Challenge. Tech.rep. 2020, pp. 1–4.url:http://arxiv.org/abs/2010.07290.
6. Mark A Griswold et al. “Generalized Autocalibrating Partially ParallelAcquisitions (GRAPPA)”. In:Magnetic Resonance in Medicine47 (2002),pp. 1202–1210.doi:10.1002/mrm.10171.url:www.interscience.wiley.com.
7. Matthew J. Muckley et al.State-of-the-art Machine Learning MRI Re-construction in 2020: Results of the Second fastMRI Challenge. Tech. rep.2020, pp. 1–16.url:http://arxiv.org/abs/2012.06318.
8. Antonin Chambolle and Thomas Pock. “A first-order primal-dual algo-rithm for convex problems with applications to imaging”. In:Journal ofMathematical Imaging and Vision40 (2011), pp. 120–145.url:https://hal.archives-ouvertes.fr/hal-00490826.
9. Pengju Liu et al. “Multi-level Wavelet-CNN for Image Restoration”. In:CVPR NTIRE Workshop. 2018.
10. Jure Zbontar et al.fastMRI: An Open Dataset and Benchmarks for Ac-celerated MRI. Tech. rep. 2018.url:https://arxiv.org/pdf/1811.08839.pdf.
11. Linda Marrakchi-Kacem et al. “Robust imaging of hippocampal innerstructure at 7T: in vivo acquisition protocol and methodological choices”.In:Magnetic Resonance Materials in Physics, Biology and Medicine29.3(2016), pp. 475–489.issn: 13528661.doi:10.1007/s10334-016-0552-5.4
Figures