1024
Deep Learning Automation for Human Brain Masking of Multi-Band MR Elastography1Beckman Institute for Advanced Science & Technology, University of Illinois at Urbana-Champaign, Urbana, IL, United States, 2Stephens Family Clinical Research Institute, Carle Foundation Hospital, Urbana, IL, United States, 3Electrical & Computer Engineering, University of Illinois at Urbana-Champaign, Urbana, IL, United States, 4Bioengineering, University of Illinois at Urbana-Champaign, Urbana, IL, United States
Synopsis
The processing steps involved in MR elastography include custom imaging sequences, image reconstruction, and material property estimation, but the most person-hours are spent on manual image masking. Manual corrections are needed because automated brain segmentation often fails near temporal lobe artifacts, which are unique for each subject. A deep learning method, specifically, a U-net architecture, is trained to map input MRE-image intensity data to corresponding manually corrected masks (N=44) with the goal of automating the masking of future MRE brain datasets. We observed the U-net-based masking maintained data quality (OSS-SNR) for all subjects.
INTRODUCTION
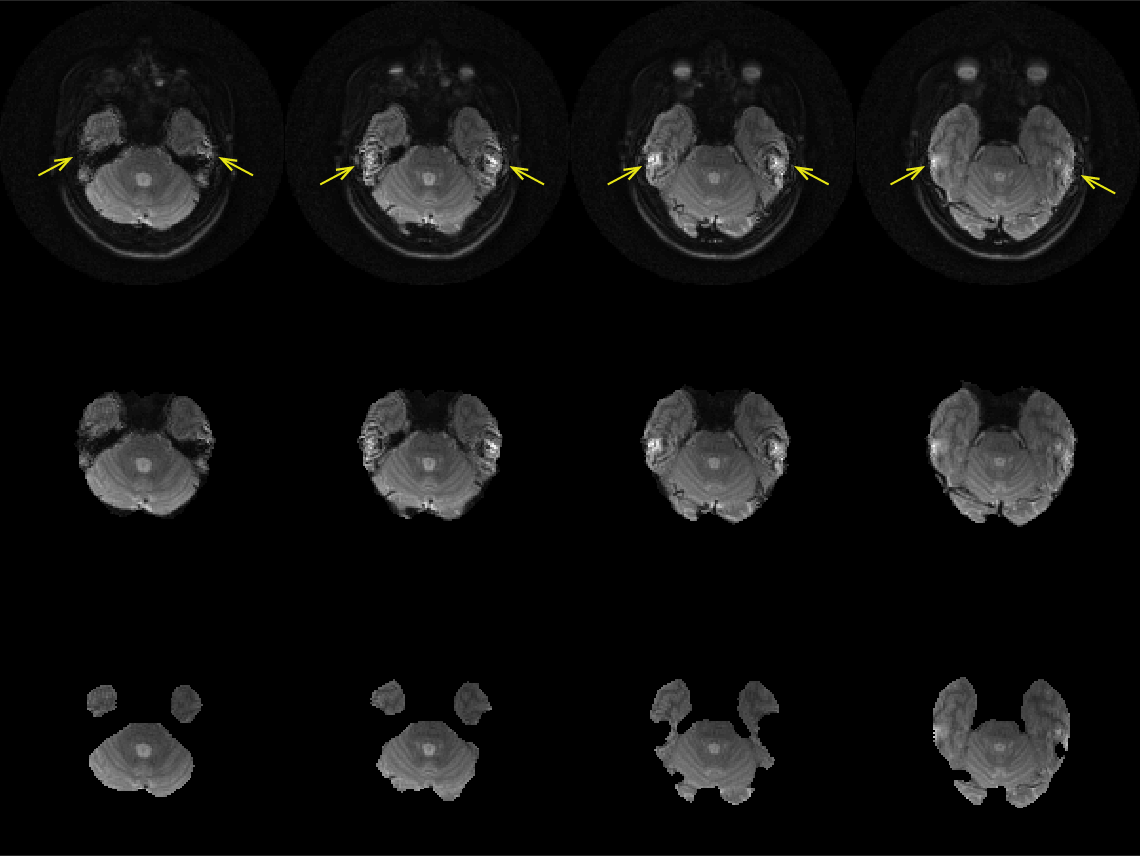
As the field of computational neuroimaging has progressed, the number of processing steps, complexity of analysis, and the need for reproducibility have steadily increased, especially as techniques become more quantitative. Magnetic resonance elastography (MRE) is inherently quantitative and requires multiple processing steps, including image reconstruction, phase unwrapping, Fourier transform, and material estimation. Due to the material estimation requiring physically consistent data in the wave fields to estimate material properties, the input wave data must only include physically valid motion by removing MR imaging artifacts, see arrows in Figure 1. Automated brain segmentation is a partial solution, but manual edits are required for subject-specific artifacts. A deep learning method with U-net architecture uses a set of manually masked magnitude images to create a deep learning network for automated segmentation without changing data quality.METHODS
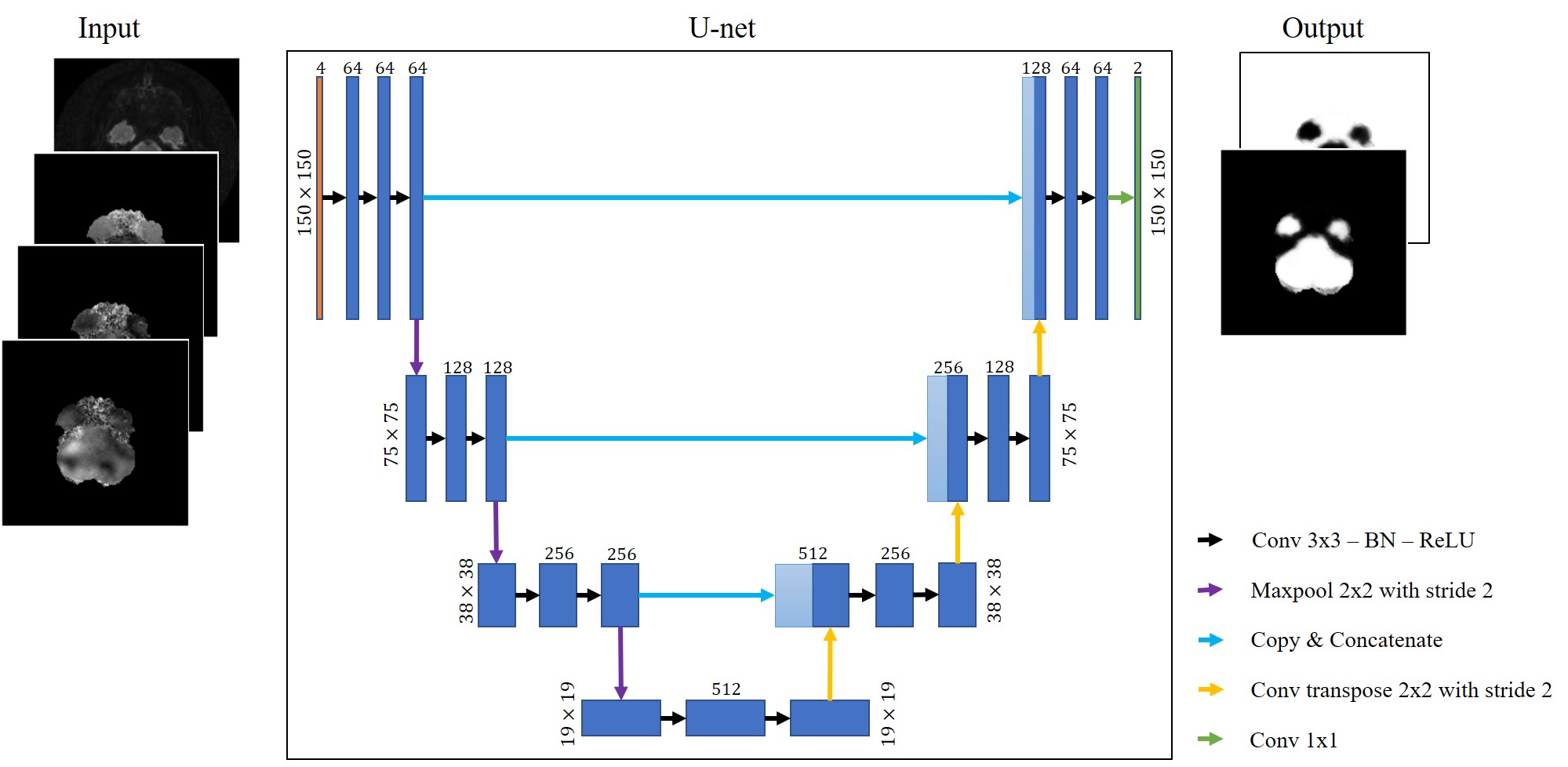
The training dataset is from a healthy aging study, approved by Institutional Review Board of the University of Illinois at Urbana-Champaign, of 26 subjects ages 18-30 years old (average age of 21.4 years ± 2.8) and 18 subjects ages 60-80 years old (average age of 70.6 years ± 5.5). MRE data was acquired on a Siemens 3T Prisma with 64-channel head coil using a multiband, multishot acquisition with nonlinear motion-induced phase error correction1. The parameters were 4 band excitation; Rxy/Rz = 2/2 undersampling; FOV = 240 mm; matrix = 150x150; TR/TE = 2520/70 ms. An active pneumatic driver (Resoundant Inc, Rochester, MN) applied 50 Hz excitation at the anterior of the head. The data quality was assessed using the octahedral shear strain signal-to-noise ratio (OSS-SNR)2 and nonlinear inversion (NLI) for material property estimation3–5. Initial masking used fsl’s brain extraction tool (BET)6 with a manual update to remove spiral imaging susceptibility artifacts.The deep learning method uses a U-net architecture7 consisting of two parts: an encoder to extract features and a decoder to enable localization coupled with long skip connections that allow for concatenating higher resolution features. The encoder and decoder follow a convolutional autoencoder approach where the final output convolution followed by a SoftMax function gives 2 channels representing the 2 classes (artifacts/no artifacts). The input to the U-net was a stack of multi-channel images (150 x 150 x 4) each comprising: a T2 magnitude image with the magnitudes of X, Y, and Z displacement fields. A diagram of the method is summarized in Figure 2. Due to limited data, k-fold cross-validation (k=5) was employed where, for each run, 38 subjects (2,432 slices) were used for training and 6 subjects (384 slices) were used for testing. The loss function used was the binary cross-entropy loss $$$L_{bce}$$$defined as
$$L_{bce} = -y \mathrm{log}(\hat{y}) - (1-y) \mathrm{log}(1-\hat{y})$$
where $$$y=\{0,1\}$$$ is the ground truth label and $$$\hat{y}$$$ is the U-net’s predicted probability of belonging to the mask. Additionally, spatial dropout was included after the encoder with a rate of 0.2 to abate overfitting. Performance of the model was measured slice-by-slice via the Dice coefficient between the predicted and manual masks.
RESULTS
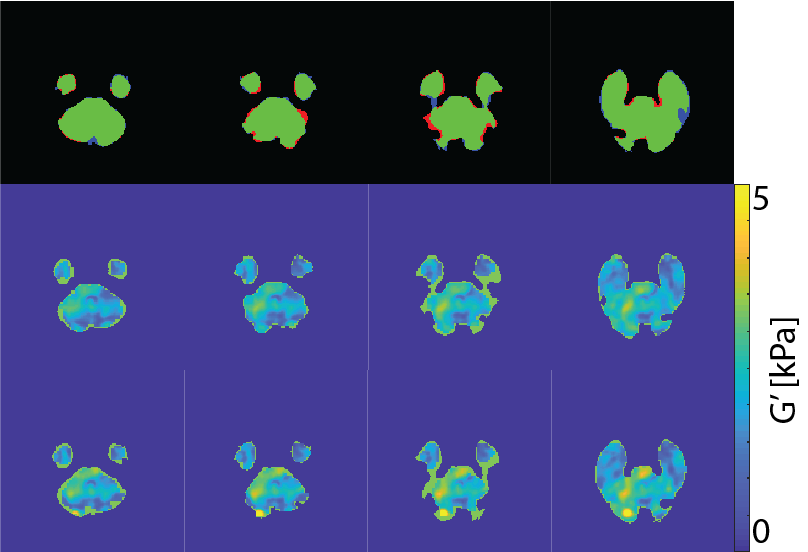
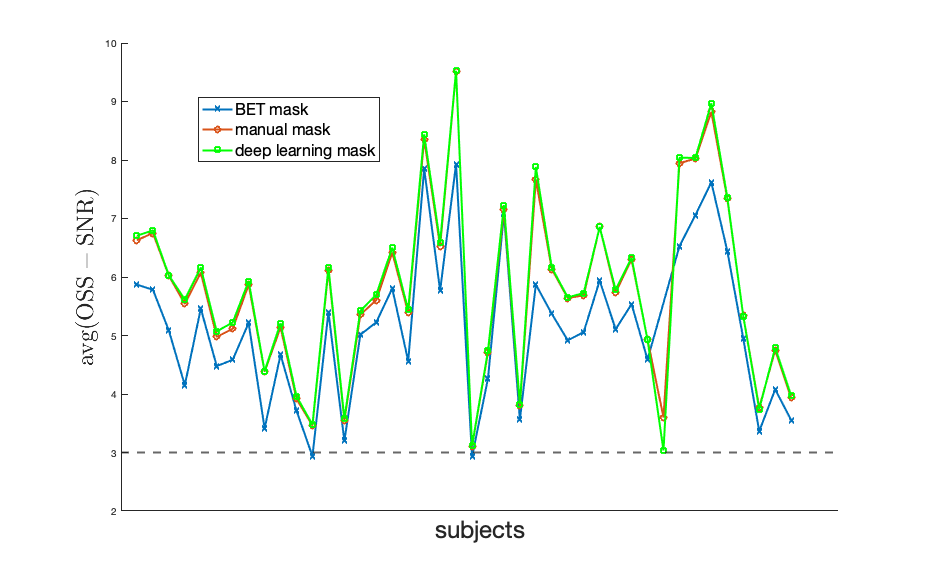
An example of MR imaging artifacts in the temporal lobes of a subject is shown in Figure 1 (top), the initial fsl BET mask (middle), and manual correction of the BET mask (bottom). Figure 3 shows an example of four slices from a subject’s inferior section of their brain where there is an agreement (green) and overshoot (blue) and undershoot (red) by the deep learning masking. The deep learning method produced masks for each subject from the collection of subjects showed good agreement. Also, Figure 3 shows the resulting elastograms from NLI material estimation for the real shear modulus (G’). The agreement of elastograms is, also, good between the two masks (light green areas are initial guess values not updated by NLI). Figure 4 shows the average OSS-SNR calculated for the manual and deep learning mask for each subject.DISCUSSION
The initial brain mask from the fsl BET command is used for automatic extraction of the brain from the skull and neck of T1- and T2-weighted images without the need for manual interaction. For specialized imaging sequences, like multiband MRE, susceptibility-induced artifacts occur in the brain and are not extracted by the fsl BET algorithm but are non-physical to the material estimation. The manual masking for MRE magnitude image takes about 1 hour per subject with a sufficiently trained rater, which is a significant amount of personnel time and results in some inter-rater variance in the masks. The deep learning method leverages previously determined manual masks and saves a significant amount of time for future studies while also potentially improving reproducibility. Given the small discrepancy in masks and the similarity in the average OSS-SNR values between deep learning masks and manual masks, the deep learning masking provides a robust automated masking approach.CONCLUSION
The performance of the deep learning masking method shows potential in automating the laborious process of manual mask editing for brain extraction from MRE images. The deep learning masking is expected to improve as more MRE data is collected with manual masks and by using the phase displacement data and OSS-SNR in the cost function.Acknowledgements
This work was supported by the NIH NIBIB under grant R01EB018107 and ATA supported by the Carle Hospital-Beckman Institute Fellowship. The work represents the views of the authors and not of the NIH.References
1. Johnson, C. L., Holtrop, J. L., Anderson, A. T. & Sutton, B. P. Brain MR elastography with multiband excitation and nonlinear motion-induced phase error correction. 22nd Annual Meeting of ISMRM (2016).
2. McGarry, M. D. J. et al. An octahedral shear strain-based measure of SNR for 3D MR elastography. Phys Med Biol 56, N153 N164 (2011).
3. Houten, E. E. W. V., Paulsen, K. D., Miga, M. I., Kennedy, F. E. & Weaver, J. B. An overlapping subzone technique for MR-based elastic property reconstruction. Magnet Reson Med 42, 779 786 (1999).
4. Houten, E. E. W. V., Miga, M. I., Weaver, J. B., Kennedy, F. E. & Paulsen, K. D. Three-dimensional subzone-based reconstruction algorithm for MR elastography. Magnet Reson Med 45, 827 837 (2001).
5. McGarry, M. D. J. et al. Multiresolution MR elastography using nonlinear inversion. Med Phys 39, 6388 6396 (2012).
6. Jenkinson, M., Beckmann, C. F., Behrens, T. E., Woolrich, M. W. & Smith, S. M. Fsl. Neuroimage 62, 782 790 (2012).
7. Ronneberger, O., Fischer, P. & Brox, T. Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III. Lect Notes Comput Sc 234–241 (2015) doi:10.1007/978-3-319-24574-4_28.
Figures