0860
Real-time deep artifact suppression using recurrent U-nets for interactive Cardiac Magnetic Resonance imaging.1Department of Computer Science, UCL, London, United Kingdom, 2Centre for Cardiovascular Imaging, UCL, London, United Kingdom, 3Department of Cardiology, Royal Free London NHS Foundation Trust, London, United Kingdom
Synopsis
MR guided catheterization requires both fast imaging and fast reconstruction techniques for interactive imaging. Recent deep learning methods outperformed classical iterative reconstructions with shorter reconstruction times. We propose a low latency framework relying on deep artefact suppression using a 2D residual U-Net with convolutional long short term memory layers trained on multiple orientations. The framework was demonstrated to reconstruct an interactively acquired bSSFP tiny golden angle radial sequence for catheter guidance. The proposed approach enabled real-time imaging (latency/network time=39/19ms) in 3 catheterized patients with promising image quality and reconstruction times.
Introduction
Various cardiac interventions can be guided through real-time low latency magnetic resonance imaging1. Magnetic resonance imaging is a relatively slow imaging method, usually leading to low spatial and temporal resolutions. Higher resolutions can be achieved by undersampling k-space, and using advanced image reconstruction strategies, however these traditionally lead to long reconstruction times. We propose a real-time deep learning reconstruction framework with low latency as proof of concept.Methods
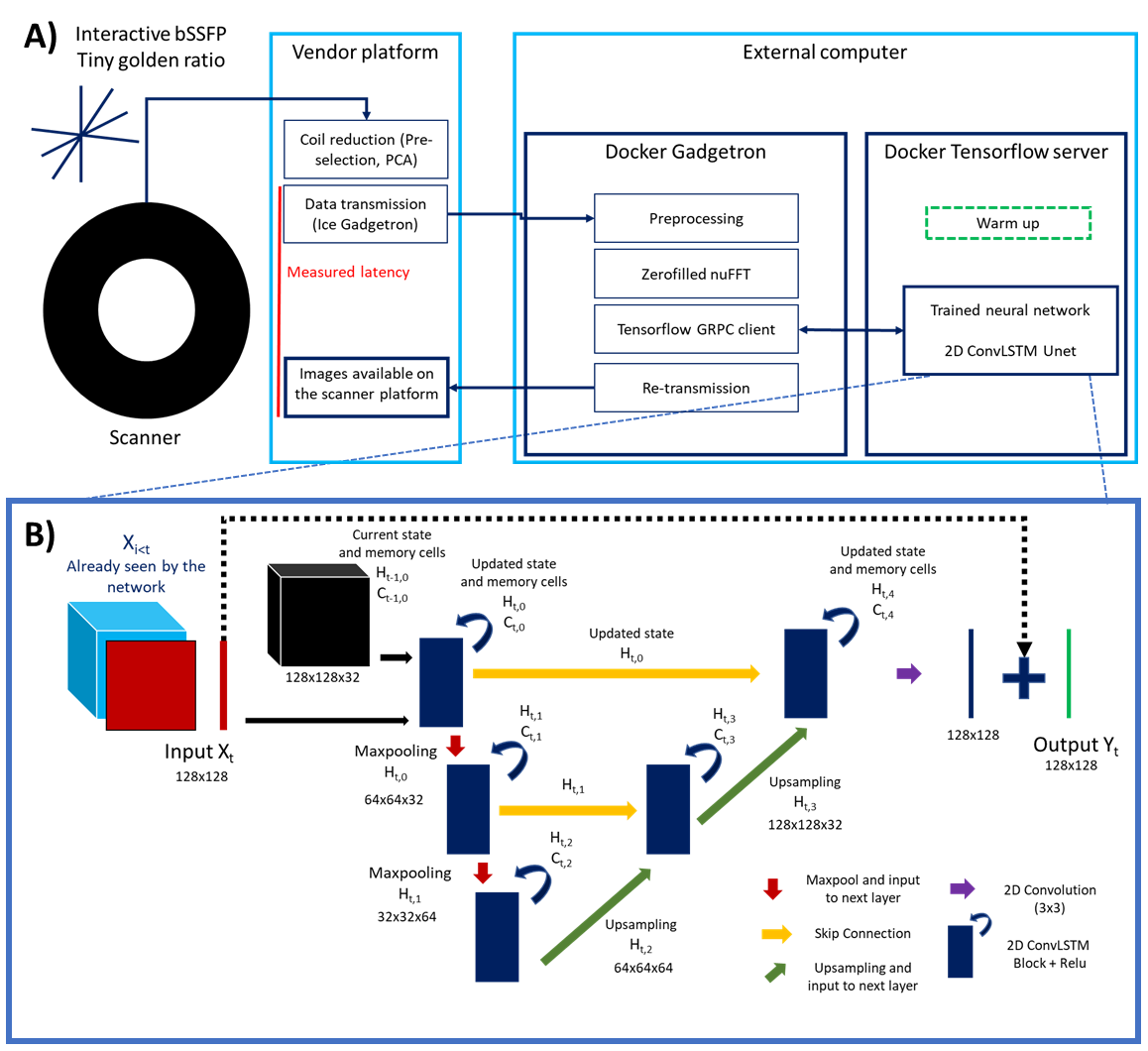
Data was acquired at 1.5T (Aera; Siemens Healthineers AG, Erlangen, Germany) with a tiny golden (23.63o) radial real-time bSSFP sequence (TR/TE=3.2/1.55ms, pixel size=1.67x1.67 mm2). Images were gridded, zero-filled and combined using sum of squares.A 2D residual U-Net2 with feed-forward Convolutional Long Short Term Memory (LSTM)3 layers is then proposed to exploit spatial and temporal redundancies to efficiently reconstruct the highly accelerated data. Timings were recorded during acquisition (including latency between data transfer and on-scanner visualization, pre-processing, gridded reconstructions and network inference time). Prospective real-time reconstructions were performed on a mid-range GPU (NVIDIA GeForce GTX 1650 Ti, 4GB memory) and laptop (Linux Ubuntu 18.08, Intel Core i7, 2.60GHz, 8GB RAM). The proposed framework is presented in Figure 1.A.
The network architecture consists of 3 different scales, includes skip connections, encoding/decoding blocks with a single convolutional LSTM layer (with 32 filters at the initial scale) and 2x2 max pool downsampling/transpose convolution upsampling (Figure 1.B) in the spatial dimensions. Training hyper parameters included mean absolute error (MAE) as loss metric, patch size of 128x128, 100 epochs, an initial learning rate of 0.001, batch size of 4 and an adaptive moment estimation algorithm (Adam)4. The network was trained using a dataset of magnitude breath-hold CINE data (including 770 time-series from 7 different orientations). These ‘ground truth’ images were retrospectively undersampled (using a tiny golden angle trajectory), regridded and Fourier transformed back to provide the aliased images. The two were center cropped and paired for supervised training of the network5.
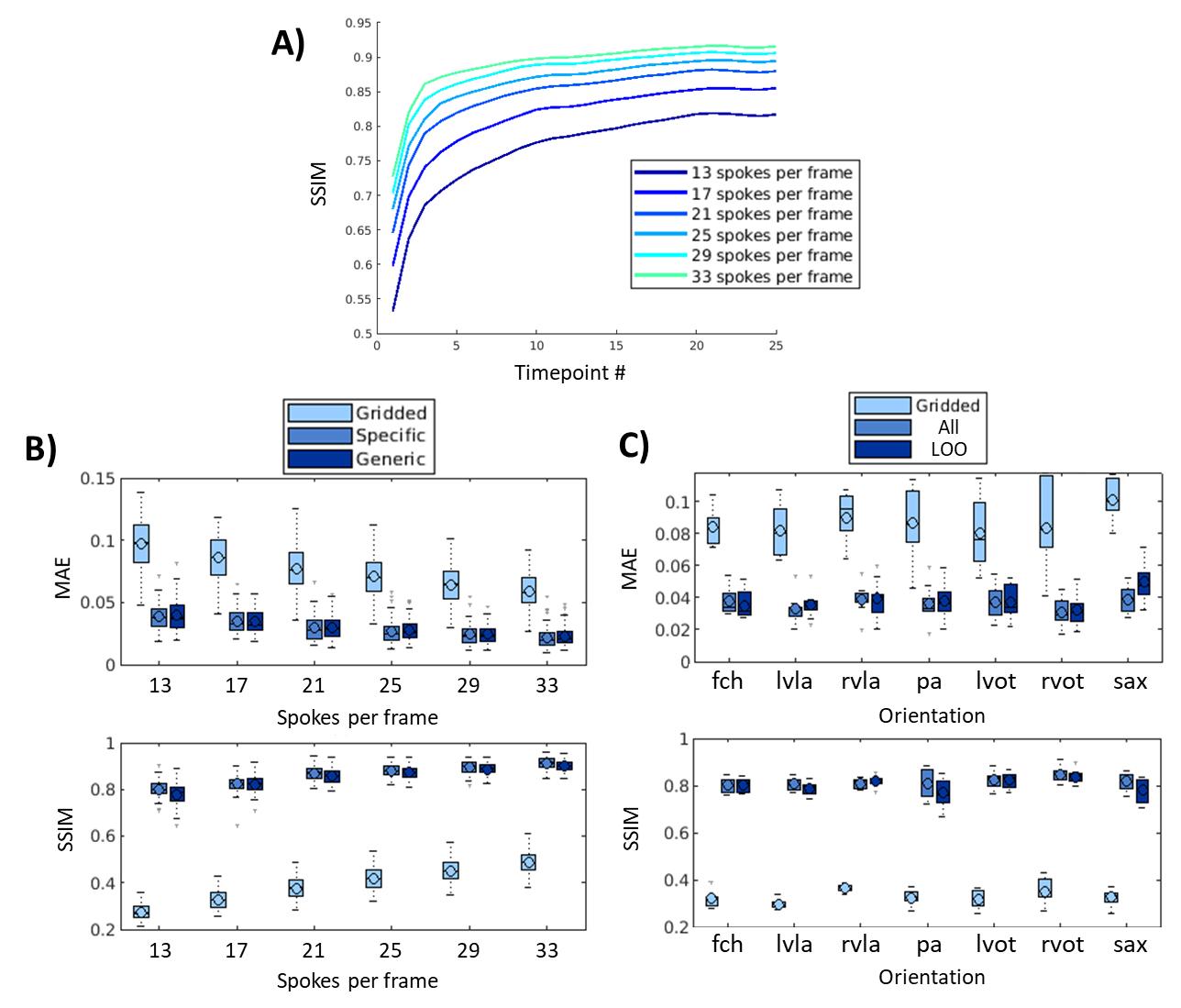
In the spirit of interventional imaging, the network was trained and tested for: 1) varying acceleration rates (six ‘specific’ networks: trained for 13, 17, 21, 25, 29 or 33 spokes per image [i.e. acceleration factors of 23.2, 17.7, 14.4, 12.1, 10.4, 9.1 respectively], one ‘generic’ network, trained with varying acceleration rates randomly picked between those previously simulated) and 2) unseen orientations (seven ‘leave-one-out’ networks: each network was trained excluding the tested orientation from the training set, one ‘all’ network which includes all orientations). The networks were compared in simulations using MAE, PSNR and SSIM (on timepoints 5 to 25).
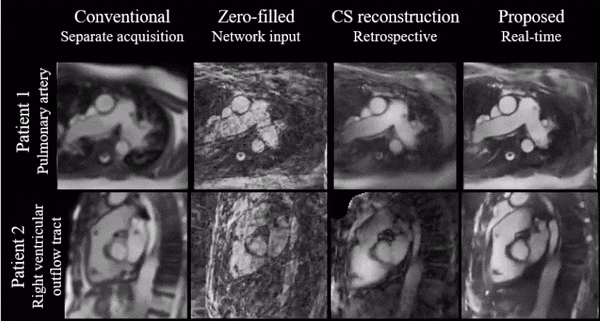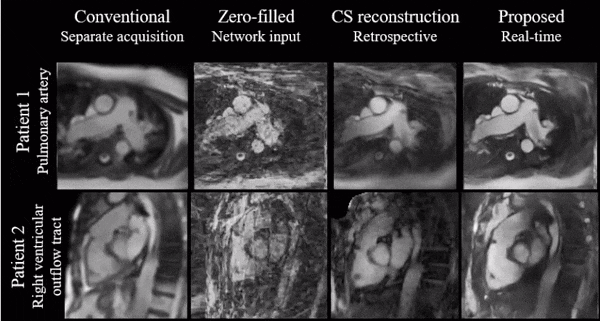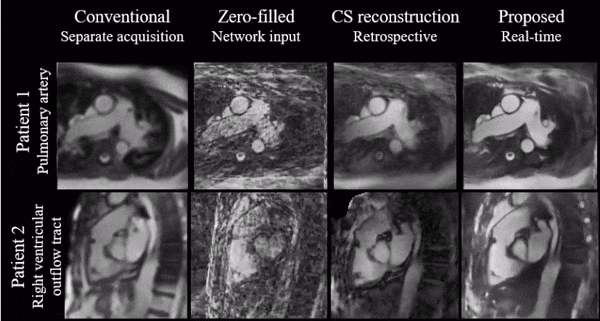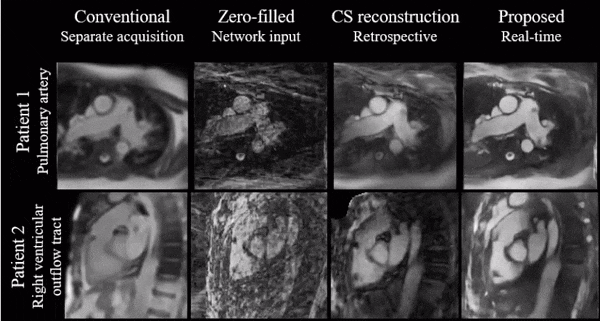
Prospective in vivo data were acquired and reconstructed in real-time with 17 spokes per image in 1 healthy subject and 3 patients which underwent catheterization. Image time-series were qualitatively compared to conventional Cartesian real-time images and to offline compressed sensing reconstruction of the same data with spatio-temporal total variation regularization6 (50 iterations of conjugate gradient, 5 iterations using alternating method of multipliers, regularization strength µ=0.01).
Results
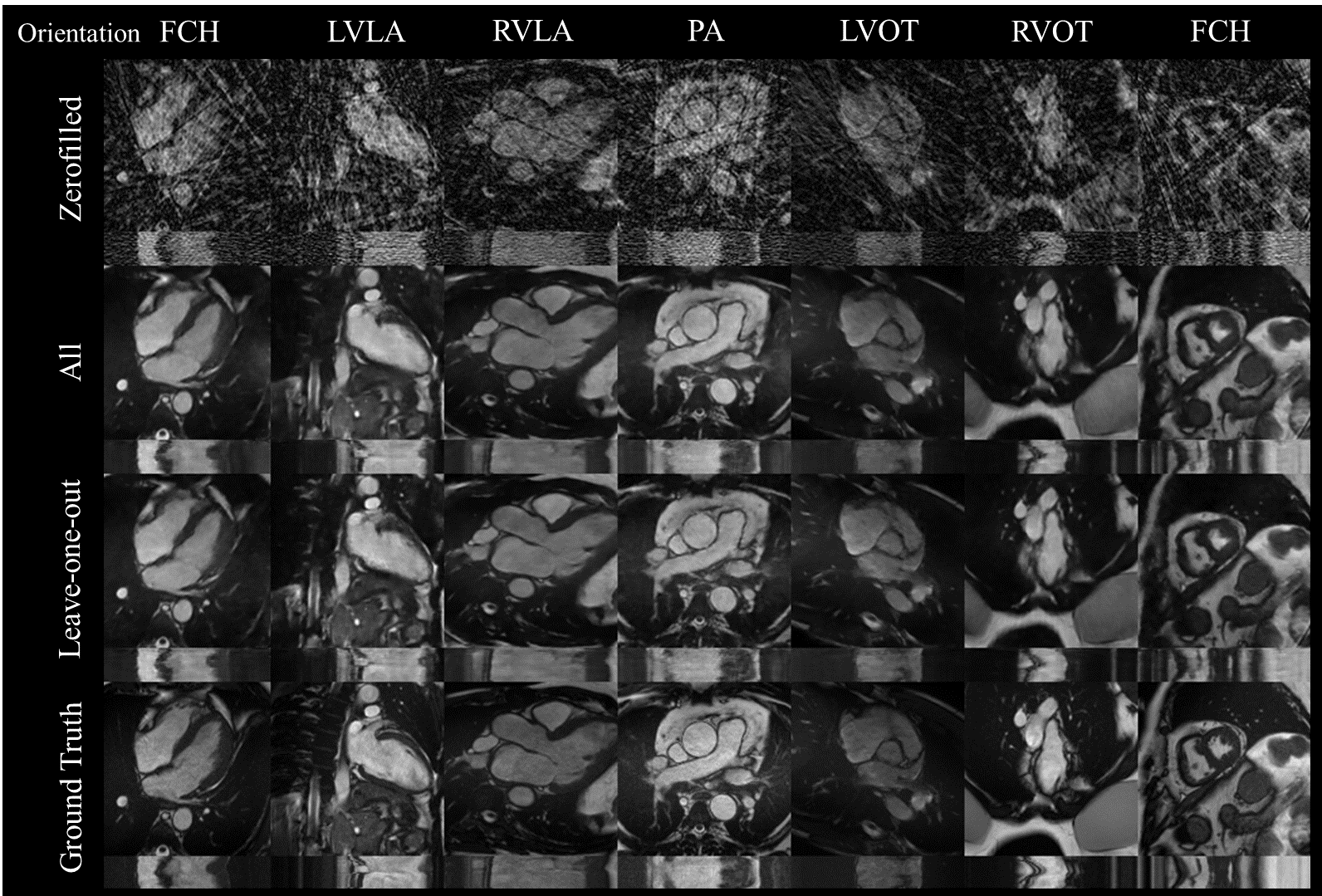
In simulated data, the proposed network showed good generalization with qualitatively low differences seen between 1) networks for ‘generic’ and ‘specific’ for acceleration rates and 2) networks for ‘all’ orientations and ‘leave-one-out’ orientation (Figure 2). The network gradually improves image reconstruction quality as data is accumulated as shown in Figure 3.A with a plateau reached within the 10 first frames. Quantitatively, boxplots comparisons for MAE and SSIM for the test sets are shown for experiment 1) in Figure 3.B and experiment 2) in Figure 3.C, with a maximum test set average loss in SSIM of 0.02 and 0.04, respectively.Latency measured using the proposed framework was 39 ms including 19 ms for deep artifact suppression, 6 ms for zero-filled reconstruction, 1 ms for data preprocessing and 13 ms for the rest (including data transfer and short post-processing functions).
Figure 4 shows a qualitative comparison of conventional Cartesian images, as well as the CS and proposed image reconstructions of the radial data in a catheterized patient.
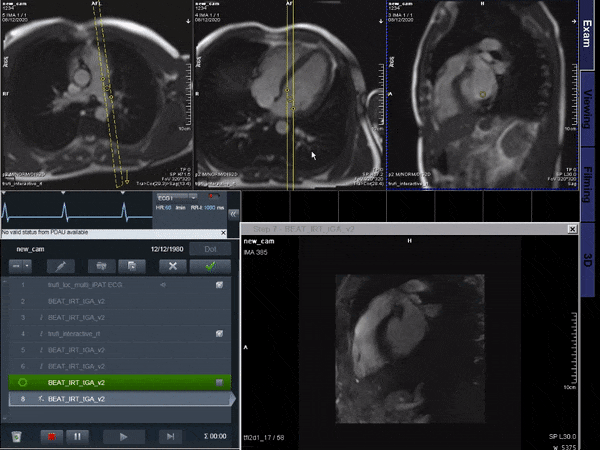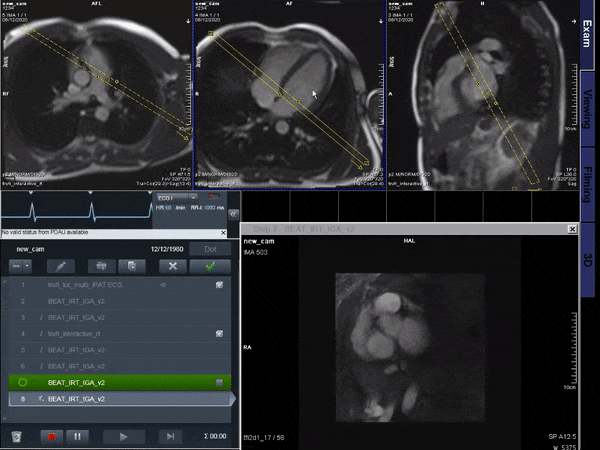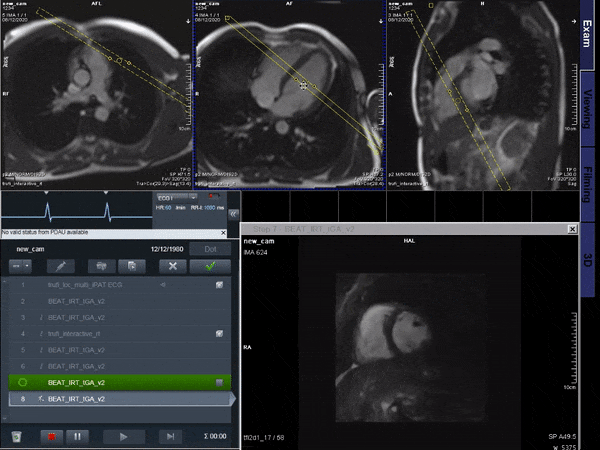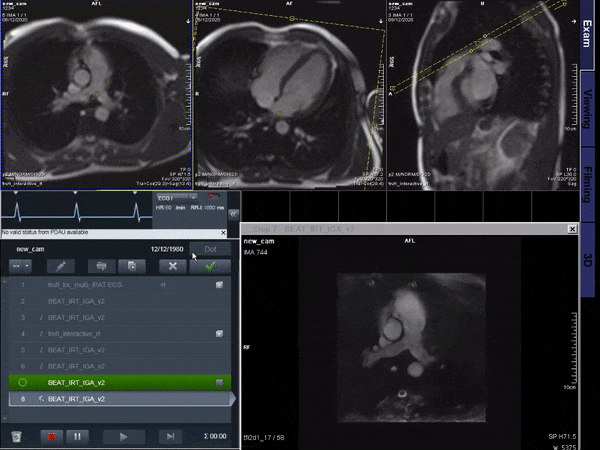
Figure 5 shows a proof of concept video of an interactive acquisition in a healthy subject.
Discussion
Simulations indicate good generalization of the proposed network to different acceleration rates and previously unseen orientations which we believe makes it a good potential candidate for interactive imaging.Videos show natural depiction of cardiac motion, fast convergence to high image quality and good quality reconstructions of unknown orientations and objects (such as the devices). In vivo data were reconstructed in real time, with no accumulation of latency when acquired at 54 ms per frame. Images compared favorably to the retrospective CS reconstruction.
The network was trained on DICOM images only which are largely available in healthcare centers meaning a larger dataset could be used to improve the model. More time for inference was still available at the proposed frame rate which could be further exploited using larger models or iterative data consistent models.
Conclusion
Deep artifact suppression was successfully demonstrated in a time critical application of non-Cartesian real time interventional cardiac MR showing promising performance in terms of image quality and reconstruction times on a mid-range laptop and GPU device.Acknowledgements
This work was supported by the British Heart Foundation (grant: NH/18/1/33511). Siemens Healthineers AG (Erlangen, Germany) provided the base code for the interactive sequence.References
1. Campbell-Washburn AE, Tavallaei MA, Pop M, et al. Real-time MRI guidance of cardiac interventions. J. Magn. Reson. Imaging 2017;46:935–950.
2. Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Vol. 9351. Springer Verlag; 2015. pp. 234–241.
3. Shi X, Chen Z, Wang H, et al. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting.; 2015.
4. Kingma DP, Ba JL. Adam: A method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings. International Conference on Learning Representations, ICLR; 2015.
5. Hauptmann A, Arridge S, Lucka F, Muthurangu V, Steeden JA. Real‐time cardiovascular MR with spatio‐temporal artifact suppression using deep learning–proof of concept in congenital heart disease. Magn. Reson. Med. 2019;81:1143–1156.
6. Feng L, Axel L, Chandarana H, Block KT, Sodickson DK, Otazo R. XD-GRASP: Golden-angle radial MRI with reconstruction of extra motion-state dimensions using compressed sensing. Magn. Reson. Med. 2016;75:775–788.
Figures